Training and Agentic Inference Strategies for LLM-based Manim Animation Generation
Pith reviewed 2026-05-10 05:01 UTC · model grok-4.3
The pith
Training open-source LLMs with GRPO and renderer-in-the-loop inference with documentation produces Manim animations that match or exceed GPT-4.1 in render success and visual similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
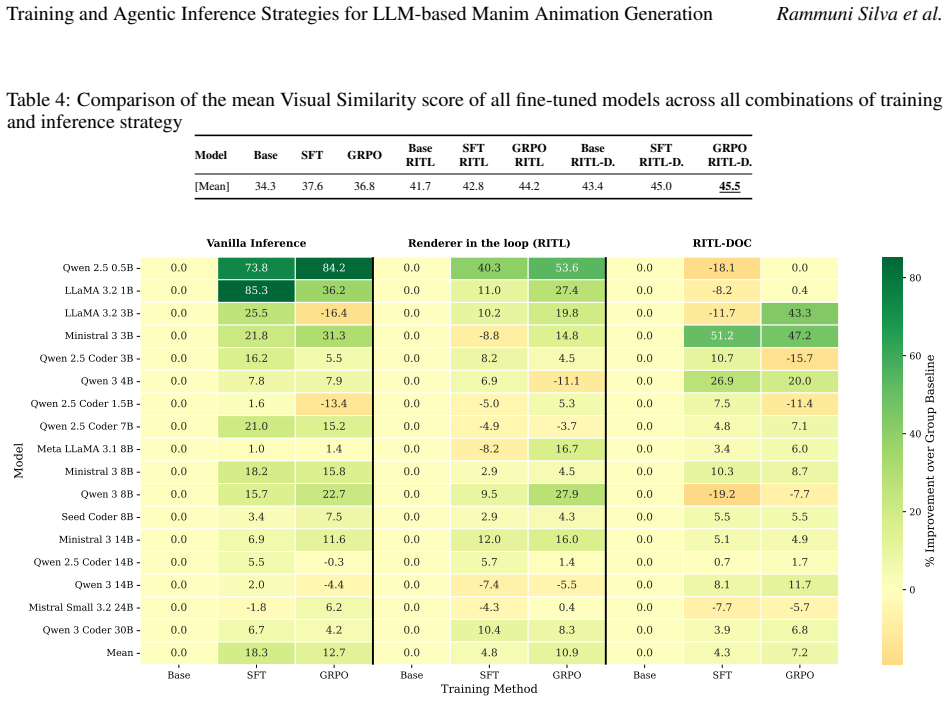
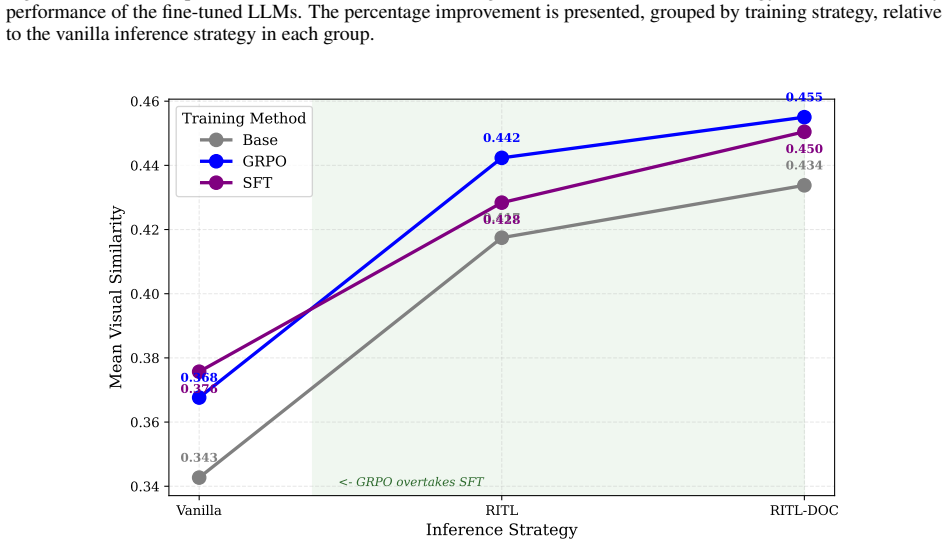
The paper establishes that a unified training and inference approach for LLM-based Manim animation generation yields superior results when models undergo supervised fine-tuning followed by group relative policy optimization with a fused code-visual reward, and then employ renderer-in-the-loop inference augmented with API documentation. Under this regime the Qwen 3 Coder 30B model achieves a 94% render success rate and 85.7% visual similarity to reference videos, outperforming the GPT-4.1 baseline by three percentage points in visual similarity. Analysis of metric correlations demonstrates that training phases strengthen the relationship between code quality and visual outcomes, whereas the R
What carries the argument
ManimTrainer, a pipeline for supervised fine-tuning combined with group relative policy optimization using a unified reward signal fusing code and visual assessments, and ManimAgent, an inference pipeline with renderer-in-the-loop and API documentation-augmented renderer-in-the-loop strategies.
If this is right
- Supervised fine-tuning generally improves code quality in the generated Manim scripts.
- Group relative policy optimization enhances the visual quality of the resulting animations and increases model responsiveness to correction signals.
- The correlation between code metrics and visual metrics strengthens after training but weakens when inference enhancements are applied.
- Certain open-source models under 30 billion parameters can achieve higher visual similarity than GPT-4.1 when using these combined strategies.
Where Pith is reading between the lines
- The observed complementarity between training and agentic inference suggests similar hybrid approaches could improve performance in other domains where code must produce verifiable visual or execution outputs.
- Reliance on custom visual similarity metrics points to the need for developing standardized perceptual benchmarks for animation quality assessment.
- Extending the ManimBench dataset or applying the pipelines to related libraries could test broader applicability of the training and inference strategies.
Load-bearing premise
The custom render success rate and visual similarity metric serve as reliable proxies for true animation quality and correctness in the absence of human validation studies or more rigorous perceptual evaluation methods.
What would settle it
If a human preference study comparing animations from the top-performing model against those from GPT-4.1 shows that viewers rate the GPT-4.1 outputs as superior or equal in a majority of cases, this would falsify the claim of outperformance based on the reported metrics.
Figures













read the original abstract
Generating programmatic animation using libraries such as Manim presents unique challenges for Large Language Models (LLMs), requiring spatial reasoning, temporal sequencing, and familiarity with domain-specific APIs that are underrepresented in general pre-training data. A systematic study of how training and inference strategies interact in this setting is lacking in current research. This study introduces ManimTrainer, a training pipeline that combines Supervised Fine-tuning (SFT) with Reinforcement Learning (RL) based Group Relative Policy Optimisation (GRPO) using a unified reward signal that fuses code and visual assessment signals, and ManimAgent, an inference pipeline featuring Renderer-in-the-loop (RITL) and API documentation-augmented RITL (RITL-DOC) strategies. Using these techniques, this study presents the first unified training and inference study for text-to-code-to-video transformation with Manim. It evaluates 17 open-source sub-30B LLMs across nine combinations of training and inference strategies using ManimBench. Results show that SFT generally improves code quality, while GRPO enhances visual outputs and increases the models' responsiveness to extrinsic signals during self-correction at inference time. The Qwen 3 Coder 30B model with GRPO and RITL-DOC achieved the highest overall performance, with a 94% Render Success Rate (RSR) and 85.7% Visual Similarity (VS) to reference videos, surpassing the baseline GPT-4.1 model by +3 percentage points in VS. Additionally, the analysis shows that the correlation between code and visual metrics strengthens with SFT and GRPO but weakens with inference-time enhancements, highlighting the complementary roles of training and agentic inference strategies in Manim animation generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ManimTrainer, a pipeline that combines supervised fine-tuning (SFT) with Group Relative Policy Optimization (GRPO) using a unified reward fusing code and visual signals, and ManimAgent, an inference pipeline with Renderer-in-the-Loop (RITL) and API-documentation-augmented RITL (RITL-DOC). It evaluates 17 open-source sub-30B LLMs across nine training-inference combinations on ManimBench, reporting that SFT improves code quality, GRPO enhances visual outputs and self-correction responsiveness, and that the Qwen 3 Coder 30B model with GRPO plus RITL-DOC attains the best results: 94% Render Success Rate and 85.7% Visual Similarity, exceeding the GPT-4.1 baseline by 3 percentage points in VS. The work also analyzes how correlations between code and visual metrics strengthen under training but weaken under inference enhancements.
Significance. If the metrics hold, this is the first systematic examination of how SFT, GRPO, and renderer-in-the-loop inference interact for LLM-based Manim animation generation, a task requiring spatial reasoning, temporal sequencing, and domain-specific API knowledge. The scale (17 models, multiple strategy combinations) and concrete trends (SFT for code, GRPO for visuals) supply practical guidance for fine-tuning LLMs on programmatic visual tasks. The complementary roles of training versus agentic inference are a useful empirical contribution to LLM-agent and code-generation research.
major comments (1)
- [§4 and §5.2] §4 (Evaluation Metrics) and §5.2 (Results): The headline claim that Qwen 3 Coder 30B + GRPO + RITL-DOC reaches 94% RSR and 85.7% VS (surpassing GPT-4.1 by +3 pp) and that GRPO 'enhances visual outputs' rests entirely on the custom Visual Similarity (VS) metric. The manuscript defines VS via a fused code+visual reward but reports no correlation analysis with human ratings, no comparison to established video metrics (FVD, video-LPIPS, or temporally weighted SSIM), and no ablation showing that VS improvements reflect motion coherence or timing correctness rather than static frame overlap. Because VS is the primary basis for model ranking and for attributing gains to GRPO, this absence is load-bearing for the central empirical conclusions.
minor comments (2)
- [Abstract and §3] The abstract and methods would benefit from an explicit statement of ManimBench size, test-case selection criteria, and how reference videos were generated, to allow readers to assess generalizability.
- [§3] Notation for the fused reward components and the exact implementation of RITL-DOC could be introduced with a short equation or pseudocode block for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. We address the concern regarding the Visual Similarity metric point by point below and outline targeted revisions.
read point-by-point responses
-
Referee: [§4 and §5.2] §4 (Evaluation Metrics) and §5.2 (Results): The headline claim that Qwen 3 Coder 30B + GRPO + RITL-DOC reaches 94% RSR and 85.7% VS (surpassing GPT-4.1 by +3 pp) and that GRPO 'enhances visual outputs' rests entirely on the custom Visual Similarity (VS) metric. The manuscript defines VS via a fused code+visual reward but reports no correlation analysis with human ratings, no comparison to established video metrics (FVD, video-LPIPS, or temporally weighted SSIM), and no ablation showing that VS improvements reflect motion coherence or timing correctness rather than static frame overlap. Because VS is the primary basis for model ranking and for attributing gains to GRPO, this absence is load-bearing for the central empirical conclusions.
Authors: We agree that stronger external validation of VS would increase confidence in the ranking and in the attribution of gains to GRPO. VS is deliberately constructed as a fused signal: after rendering succeeds, it combines (i) code-execution rewards that penalize API misuse or runtime errors with (ii) frame-wise visual similarity computed on the rendered video. This fusion is motivated by the programmatic nature of the task, where pure perceptual metrics can reward visually plausible but semantically incorrect animations. We already report in §5.3 that code-visual metric correlations increase under GRPO, providing indirect support that VS tracks meaningful improvements. Nevertheless, we did not conduct human ratings, direct comparisons against FVD/video-LPIPS, or a dedicated static-vs-temporal ablation. In the revised manuscript we will (a) expand §4 with the precise formulation of the fused reward and its weighting, (b) add a limitations paragraph in §6 explicitly noting the absence of human correlation and established video metrics, and (c) include a limited post-hoc breakdown (on the top-performing models) that separates static-frame overlap from temporal coherence components of VS. These changes clarify the metric’s scope without requiring a full re-evaluation of the 17-model study. revision: partial
Circularity Check
No significant circularity; empirical evaluation is self-contained
full rationale
The paper reports an empirical study of LLM training (SFT + GRPO) and inference strategies (RITL, RITL-DOC) for Manim code generation, evaluated on ManimBench via measured Render Success Rate and a custom Visual Similarity metric. No equations, derivations, or fitted-parameter predictions appear in the provided text or abstract; performance claims rest on direct test-set outcomes rather than any self-referential reduction. Self-citations, if present, are not load-bearing for any central result, and the work does not invoke uniqueness theorems or rename known results as novel derivations.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
PRISM: A Benchmark for Programmatic Spatial-Temporal Reasoning
PRISM benchmark of over 10k pairs shows LLMs have a 41% average drop from code execution success to spatial correctness in programmatic video generation.
Reference graph
Works this paper leans on
-
[1]
Manim – Mathematical Animation Framework, 2026
The Manim Community Developers. Manim – Mathematical Animation Framework, 2026
2026
-
[2]
Evaluating Large Language Models Trained on Code, 2021
Mark Chen, Tworek, et al. Evaluating Large Language Models Trained on Code, 2021. Version Number: 2
2021
-
[3]
Qwen2.5- Coder Technical Report, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5- Coder Technical Report, 2024. Version Number: 3
2024
-
[4]
Seed-Coder: Let the Code Model Curate Data for Itself, 2025
ByteDance Seed, Yuyu Zhang, Jing Su, Yifan Sun, Chenguang Xi, Xia Xiao, Shen Zheng, Anxiang Zhang, Kaibo Liu, Daoguang Zan, Tao Sun, Jinhua Zhu, Shulin Xin, Dong Huang, Yetao Bai, Lixin Dong, Chao Li, Jianchong Chen, Hanzhi Zhou, Yifan Huang, Guanghan Ning, Xierui Song, Jiaze Chen, Siyao Liu, Kai Shen, Liang Xiang, and Yonghui Wu. Seed-Coder: Let the Code...
2025
-
[5]
Ravidu Suien Rammuni Silva, Ahmad Lotfi, Isibor Kennedy Ihianle, Golnaz Shahtahmassebi, and Jordan J. Bird. Large Language Model Approaches to Educational Video Generation Using Manim. In Emma Hart, Tomas Horvath, Zhiyuan Tan, and Sarah Thomson, editors,Advances in Computational Intelligence Systems, volume 1468, pages 306–317. Springer Nature Switzerland...
2026
-
[6]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models, 2021. Version Number: 2
2021
-
[7]
Qlora: efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: efficient finetuning of quantized llms. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
2023
-
[8]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024. Version Number: 3
2024
-
[9]
Teaching Large Language Models to Self- Debug
Xinyun Chen, Maxwell Lin, Nathanael Schaerli, and Denny Zhou. Teaching Large Language Models to Self- Debug. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 8746–8825, 2024
2024
-
[10]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20...
2020
-
[11]
Xu, Yiqing Xie, Graham Neubig, and Daniel Fried
Zora Zhiruo Wang, Akari Asai, Xinyan Velocity Yu, Frank F. Xu, Yiqing Xie, Graham Neubig, and Daniel Fried. CodeRAG-Bench: Can Retrieval Augment Code Generation?, 2024. Version Number: 2
2024
-
[12]
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis, 2020
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. CodeBLEU: a Method for Automatic Evaluation of Code Synthesis, 2020. Version Number: 2
2020
-
[13]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages,
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. CodeBERT: A Pre-Trained Model for Programming and Natural Languages,
-
[14]
SSIM image quality metric for denoised images
Peter Ndajah, Hisakazu Kikuchi, Masahiro Yukawa, Hidenori Watanabe, and Shogo Muramatsu. SSIM image quality metric for denoised images. InProceedings of the 3rd WSEAS international conference on Visualization, imaging and simulation, pages 53–57, 2010
2010
-
[15]
Learning Transferable Visual Models From Natural Language Supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision, 2021. Version Number: 1
2021
-
[16]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions, 2024
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Biny...
2024
-
[17]
JanusCoder: Towards a Foundational Visual-Programmatic Interface for Code Intelligence, 2025
Qiushi Sun, Jingyang Gong, Yang Liu, Qiaosheng Chen, Lei Li, Kai Chen, Qipeng Guo, Ben Kao, and Fei Yuan. JanusCoder: Towards a Foundational Visual-Programmatic Interface for Code Intelligence, 2025. Version Number: 1
2025
-
[18]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforce- ment learning.Nature, 645(8081):633–638, September 2025
Daya Guo, Dejian Yang, and Zhang and others. DeepSeek-R1 incentivizes reasoning in LLMs through reinforce- ment learning.Nature, 645(8081):633–638, September 2025
2025
-
[19]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
2022
-
[20]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 53728–53741, 2023
2023
-
[21]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 8634–8652, 2023
2023
-
[22]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-Refine: Iterative Refinement with Self-Feedback. In A. Oh, T. Naumann, A. Globerson, K. Saenko, ...
2023
-
[23]
Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. When Can LLMsActuallyCorrect Their Own Mistakes? A Critical Survey of Self-Correction of LLMs.Transactions of the Association for Computational Linguistics, 12:1417–1440, November 2024
2024
-
[24]
Can LLMs Correct Themselves? A Benchmark of Self-Correction in LLMs, 2025
Guiyao Tie, Zenghui Yuan, Zeli Zhao, Chaoran Hu, Tianhe Gu, Ruihang Zhang, Sizhe Zhang, Junran Wu, Xiaoyue Tu, Ming Jin, Qingsong Wen, Lixing Chen, Pan Zhou, and Lichao Sun. Can LLMs Correct Themselves? A Benchmark of Self-Correction in LLMs, 2025. Version Number: 2
2025
-
[25]
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C.H. Hoi. CodeRL: mastering code generation through pretrained models and deep reinforcement learning. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. event-place: New Orleans, LA, USA
2022
-
[26]
InterCode: standardizing and benchmarking interactive coding with execution feedback
John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao. InterCode: standardizing and benchmarking interactive coding with execution feedback. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc. event-place: New Orleans, LA, USA
2023
-
[27]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: agent-computer interfaces enable automated software engineering. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. event-place: Vanco...
2024
-
[28]
ReLook: Vision-Grounded RL with a Multimodal LLM Critic for Agentic Web Coding, 2025
Yuhang Li, Chenchen Zhang, Ruilin Lv, Ao Liu, Ken Deng, Yuanxing Zhang, Jiaheng Liu, Wiggin Zhou, and Bo Zhou. ReLook: Vision-Grounded RL with a Multimodal LLM Critic for Agentic Web Coding, 2025. Version Number: 1
2025
-
[29]
Keyframer: Empowering Animation Design using Large Language Models, 2024
Tiffany Tseng, Ruijia Cheng, and Jeffrey Nichols. Keyframer: Empowering Animation Design using Large Language Models, 2024
2024
-
[30]
VinciCoder: Unifying Multimodal Code Generation via Coarse-to-fine Visual Reinforce- ment Learning, 2025
Xuanle Zhao, Deyang Jiang, Zhixiong Zeng, Lei Chen, Haibo Qiu, Jing Huang, Yufeng Zhong, Liming Zheng, Yilin Cao, and Lin Ma. VinciCoder: Unifying Multimodal Code Generation via Coarse-to-fine Visual Reinforce- ment Learning, 2025. Version Number: 2
2025
-
[31]
LogoMotion: Visually-Grounded Code Synthesis for Creating and Editing Animation
Vivian Liu, Rubaiat Habib Kazi, Li-Yi Wei, Matthew Fisher, Timothy Langlois, Seth Walker, and Lydia Chilton. LogoMotion: Visually-Grounded Code Synthesis for Creating and Editing Animation. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[32]
Manimator: Transforming Research Papers into Visual Explanations, 2025
Samarth P, Vyoman Jain, Shiva Golugula, and Motamarri Sai Sathvik. Manimator: Transforming Research Papers into Visual Explanations, 2025. Version Number: 1. 21 Training and Agentic Inference Strategies for LLM-based Manim Animation GenerationRammuni Silva et al
2025
-
[33]
TheoremExplainAgent: Towards video-based multimodal explanations for llm theorem understanding
Max Ku, Cheuk Hei Chong, Jonathan Leung, Krish Shah, Alvin Yu, and Wenhu Chen. TheoremExplainAgent: Towards video-based multimodal explanations for llm theorem understanding. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 6663–6684, 2025
2025
-
[34]
Code2Video: A Code-centric Paradigm for Educational Video Generation, 2025
Yanzhe Chen, Kevin Qinghong Lin, and Mike Zheng Shou. Code2Video: A Code-centric Paradigm for Educational Video Generation, 2025. Version Number: 1
2025
-
[35]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[36]
Toward accurate dynamic time warping in linear time and space.Intell
Stan Salvador and Philip Chan. Toward accurate dynamic time warping in linear time and space.Intell. Data Anal., 11(5):561–580, October 2007
2007
-
[37]
Understanding R1-Zero-Like Training: A Critical Perspective, 2025
Zichen Liu, Changyu Chen, and Li and others. Understanding R1-Zero-Like Training: A Critical Perspective, 2025
2025
-
[38]
Unsloth, 2023
Michael Han Daniel Han and Unsloth team. Unsloth, 2023
2023
-
[39]
Qwen3 Technical Report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[40]
The Llama 3 Herd of Models, 2024
Aaron Grattafiori and Dubey and others. The Llama 3 Herd of Models, 2024. Version Number: 3
2024
-
[41]
Liu and Khandelwal and others
Alexander H. Liu and Khandelwal and others. Ministral 3, 2026. Version Number: 1
2026
-
[42]
Rae, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack W. Rae, and Laurent Sifre...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.