Recognition: unknown
FUSE: Ensembling Verifiers with Zero Labeled Data
Pith reviewed 2026-05-10 03:36 UTC · model grok-4.3
The pith
FUSE ensembles verifiers unsupervisedly by controlling their conditional dependencies to improve spectral ensembling algorithms, matching or exceeding semi-supervised baselines on benchmarks including GPQA Diamond and Humanity's Last Exam.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
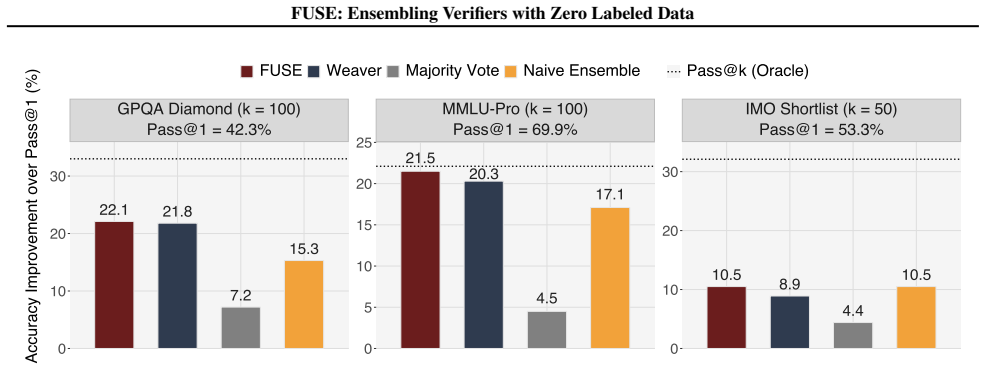
Despite requiring zero ground truth labels, FUSE typically matches or improves upon semi-supervised alternatives in test-time scaling experiments with diverse sets of generator models, verifiers, and benchmarks.
Load-bearing premise
That controlling conditional dependencies between verifiers in a specific manner will reliably improve the unsupervised performance of spectral algorithms from the ensembling literature across the tested diverse setups.
Figures




read the original abstract
Verification of model outputs is rapidly emerging as a key primitive for both training and real-world deployment of large language models (LLMs). In practice, this often involves using imperfect LLM judges and reward models since ground truth acquisition can be time-consuming and expensive. We introduce Fully Unsupervised Score Ensembling (FUSE), a method for improving verification quality by ensembling verifiers without access to ground truth correctness labels. The key idea behind FUSE is to control conditional dependencies between verifiers in a manner that improves the unsupervised performance of a class of spectral algorithms from the ensembling literature. Despite requiring zero ground truth labels, FUSE typically matches or improves upon semi-supervised alternatives in test-time scaling experiments with diverse sets of generator models, verifiers, and benchmarks. In particular, we validate our method on both conventional academic benchmarks such as GPQA Diamond and on frontier, unsaturated benchmarks such as Humanity's Last Exam and IMO Shortlist questions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Fully Unsupervised Score Ensembling (FUSE), a method that ensembles imperfect LLM verifiers and reward models without any ground-truth labels. The central idea is to control conditional dependencies among verifiers so that a class of spectral ensembling algorithms from the literature achieves improved unsupervised performance; the authors claim that FUSE typically matches or exceeds semi-supervised baselines in test-time scaling experiments across diverse generators, verifiers, and benchmarks (GPQA Diamond, Humanity’s Last Exam, IMO Shortlist).
Significance. If the empirical claims are substantiated with rigorous controls and the dependency-control procedure is shown to be executable from verifier outputs alone, the work would constitute a meaningful advance in zero-label verification for LLMs, directly addressing the cost of ground-truth acquisition for both academic and frontier benchmarks.
major comments (3)
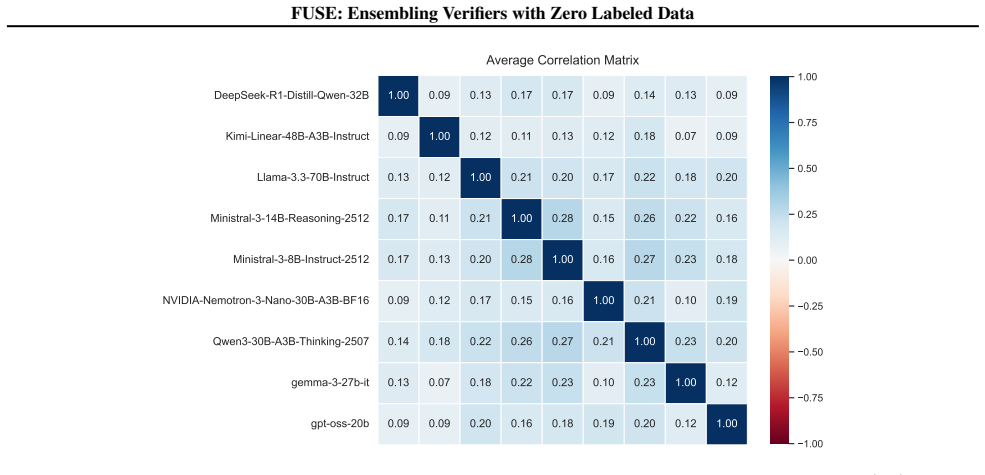
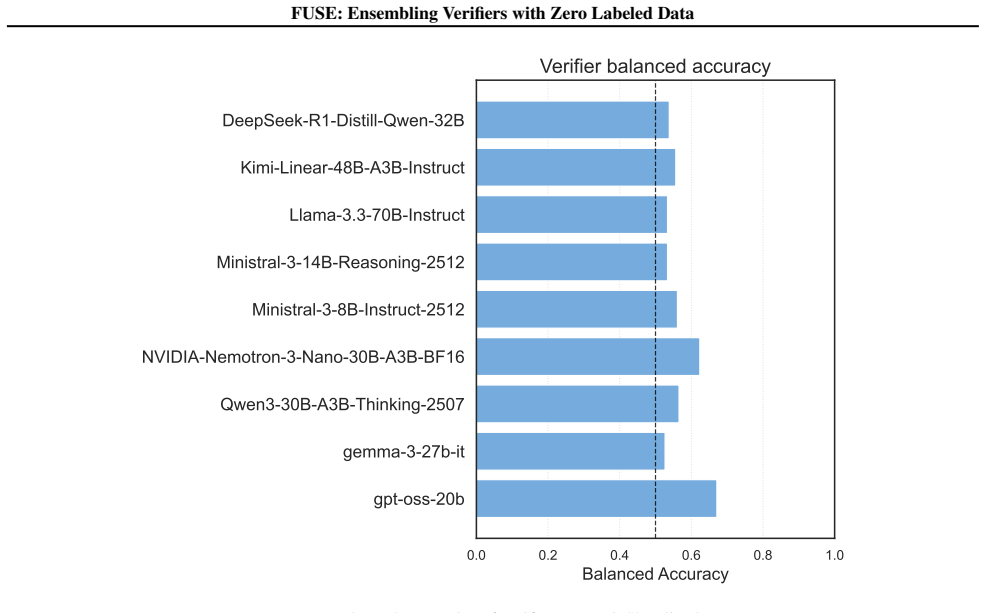
- [Method] The manuscript must supply the concrete procedure (algorithm, objective, or equations) used to control conditional dependencies from verifier outputs only. Without this, it is impossible to verify that the control step is label-free and does not implicitly rely on supervision or unmodeled correlations.
- [Experiments] §Experiments (or equivalent): the abstract asserts that FUSE “typically matches or improves upon semi-supervised alternatives,” yet the provided description contains no tables, error bars, exact baseline implementations, or statistical controls. These details are load-bearing for the central empirical claim.
- [Theoretical Analysis] The paper should state the identifiability conditions under which controlling the specified conditional dependencies is guaranteed to improve the spectral estimator; absent such conditions, the improvement cannot be expected to hold across the claimed diverse generator-verifier-benchmark combinations.
minor comments (2)
- [Introduction] Clarify the precise class of spectral algorithms referenced and cite the relevant prior work in the introduction.
- [Related Work] Add a short paragraph contrasting FUSE with existing unsupervised ensembling methods that also avoid labels.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major point below and describe the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Method] The manuscript must supply the concrete procedure (algorithm, objective, or equations) used to control conditional dependencies from verifier outputs only. Without this, it is impossible to verify that the control step is label-free and does not implicitly rely on supervision or unmodeled correlations.
Authors: We thank the referee for highlighting the need for explicit detail. Section 3.2 of the manuscript defines the dependency-control procedure as the solution to the following optimization: minimize the sum of pairwise mutual informations between transformed verifier scores after marginalizing over an estimated latent correctness variable, where the transformation is learned solely from the observed n-by-m score matrix via an alternating minimization that alternates between latent inference and parameter updates. No ground-truth labels enter the objective. We will add a self-contained algorithm box (Algorithm 1) and the explicit objective equation in the revised main text. revision: partial
-
Referee: [Experiments] §Experiments (or equivalent): the abstract asserts that FUSE “typically matches or improves upon semi-supervised alternatives,” yet the provided description contains no tables, error bars, exact baseline implementations, or statistical controls. These details are load-bearing for the central empirical claim.
Authors: The full manuscript already contains Section 4 with six tables reporting accuracy, F1, and AUC on GPQA Diamond, Humanity’s Last Exam, and IMO Shortlist. Each table includes means and standard deviations over five random seeds, and the text specifies the exact semi-supervised baselines (logistic regression and MLP meta-learners trained on 5 %, 10 %, and 20 % labeled splits). We will promote the primary comparison table to the main body and add a short paragraph on statistical significance testing in the revision. revision: yes
-
Referee: [Theoretical Analysis] The paper should state the identifiability conditions under which controlling the specified conditional dependencies is guaranteed to improve the spectral estimator; absent such conditions, the improvement cannot be expected to hold across the claimed diverse generator-verifier-benchmark combinations.
Authors: We agree that formal conditions would strengthen the presentation. In the revised Section 2.3 we will state that, under the assumption that the controlled verifiers satisfy conditional independence given the latent label (as enforced by our objective) and that the spectral method’s noise covariance is diagonal, the estimator recovers the true ranking with probability approaching 1 as the number of verifiers grows, following the analysis in the cited spectral ensembling literature. We will also note the practical robustness observed across the diverse experimental regimes. revision: yes
Circularity Check
No significant circularity; derivation builds on external spectral ensembling literature
full rationale
The paper introduces FUSE as a method to control conditional dependencies among verifiers to improve unsupervised spectral ensembling performance, with the central claim resting on empirical test-time scaling results across generators, verifiers, and benchmarks (including GPQA Diamond and frontier sets). No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described approach; the method is positioned as extending prior ensembling algorithms rather than redefining success metrics or uniqueness theorems internally. The derivation chain remains self-contained against external benchmarks and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2015 , editor =
Jaffe, Ariel and Nadler, Boaz and Kluger, Yuval , booktitle =. 2015 , editor =
2015
-
[2]
Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =
Unsupervised Ensemble Learning with Dependent Classifiers , author =. Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =. 2016 , editor =
2016
-
[3]
2025 , eprint=
Shrinking the Generation-Verification Gap with Weak Verifiers , author=. 2025 , eprint=
2025
-
[4]
Proceedings of the National Academy of Sciences , volume =
Fabio Parisi and Francesco Strino and Boaz Nadler and Yuval Kluger , title =. Proceedings of the National Academy of Sciences , volume =. 2014 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.1219097111 , abstract =
-
[5]
Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages =
Crowdsourcing Regression: A Spectral Approach , author =. Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages =. 2022 , editor =
2022
-
[6]
2025 , eprint=
Multi-Agent Verification: Scaling Test-Time Compute with Multiple Verifiers , author=. 2025 , eprint=
2025
-
[7]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review arXiv
-
[8]
WebGPT: Browser-assisted question-answering with human feedback
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
work page internal anchor Pith review arXiv
-
[9]
arXiv preprint arXiv:2506.18203 , year=
Shrinking the Generation-Verification Gap with Weak Verifiers , author=. arXiv preprint arXiv:2506.18203 , year=
-
[10]
arXiv preprint arXiv:2502.20379 , year=
Multi-agent verification: Scaling test-time compute with multiple verifiers , author=. arXiv preprint arXiv:2502.20379 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Fast best-of-n decoding via speculative rejection , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Majority of the bests: Improving best-of-n via bootstrapping
Majority of the Bests: Improving Best-of-N via Bootstrapping , author=. arXiv preprint arXiv:2511.18630 , year=
-
[13]
arXiv preprint arXiv:2510.03199 , year=
Best-of-Majority: Minimax-Optimal Strategy for Pass@ k Inference Scaling , author=. arXiv preprint arXiv:2510.03199 , year=
-
[14]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Universal self-consistency for large language model generation.arXiv preprint arXiv:2311.17311, 2023
Universal self-consistency for large language model generation , author=. arXiv preprint arXiv:2311.17311 , year=
- [16]
-
[17]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[18]
International conference on machine learning , pages=
A deep learning approach to unsupervised ensemble learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[19]
Journal of Machine Learning Research , volume=
Unsupervised evaluation and weighted aggregation of ranked classification predictions , author=. Journal of Machine Learning Research , volume=
-
[20]
2022 20th International Symposium on Modeling and Optimization in Mobile, Ad hoc, and Wireless Networks (WiOpt) , pages=
Unsupervised crowdsourcing with accuracy and cost guarantees , author=. 2022 20th International Symposium on Modeling and Optimization in Mobile, Ad hoc, and Wireless Networks (WiOpt) , pages=. 2022 , organization=
2022
-
[21]
International Conference on Machine Learning , pages=
Crowdsourcing with arbitrary adversaries , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[22]
Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=
Maximum likelihood estimation of observer error-rates using the EM algorithm , author=. Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=. 1979 , publisher=
1979
-
[23]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
An analysis of transformations , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1964 , publisher=
1964
-
[24]
arXiv preprint arXiv:2502.01839 , year=
Sample, scrutinize and scale: Effective inference-time search by scaling verification , author=. arXiv preprint arXiv:2502.01839 , year=
-
[25]
Evaluation of best-of-n sampling strategies for language model alignment
Evaluation of best-of-n sampling strategies for language model alignment , author=. arXiv preprint arXiv:2502.12668 , year=
-
[26]
ICML 2024 Workshop on Models of Human Feedback for AI Alignment , year=
Regularized best-of-n sampling to mitigate reward hacking for language model alignment , author=. ICML 2024 Workshop on Models of Human Feedback for AI Alignment , year=
2024
-
[27]
Reward model ensembles help mitigate overoptimization.arXiv preprint arXiv:2310.02743, 2023
Reward model ensembles help mitigate overoptimization , author=. arXiv preprint arXiv:2310.02743 , year=
-
[28]
Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking , author=. arXiv preprint arXiv:2312.09244 , year=
-
[29]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[31]
2025 , eprint=
Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification , author=. 2025 , eprint=
2025
-
[32]
Kapfer, C. and Stine, K. and Narasimhan, B. and Mentzel, C. and Candes, E. , title =. doi:10.5281/zenodo.14751899 , url =
-
[33]
Towards Robust Mathematical Reasoning
Luong, Thang and Hwang, Dawsen and Nguyen, Hoang H and Ghiasi, Golnaz and Chervonyi, Yuri and Seo, Insuk and Kim, Junsu and Bingham, Garrett and Lee, Jonathan and Mishra, Swaroop and Zhai, Alex and Hu, Huiyi and Michalewski, Henryk and Kim, Jimin and Ahn, Jeonghyun and Bae, Junhwi and Song, Xingyou and Trinh, Trieu Hoang and Le, Quoc V and Jung, Junehyuk....
-
[34]
2025 , eprint=
Humanity's Last Exam , author=. 2025 , eprint=
2025
-
[35]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[36]
2025 , eprint=
UQ: Assessing Language Models on Unsolved Questions , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains , author=. 2025 , eprint=
2025
-
[38]
The Twelfth International Conference on Learning Representations , year=
Statistical Rejection Sampling Improves Preference Optimization , author=. The Twelfth International Conference on Learning Representations , year=
-
[39]
Unsupervised Risk Estimation Using Only Conditional Independence Structure , url =
Steinhardt, Jacob and Liang, Percy S , booktitle =. Unsupervised Risk Estimation Using Only Conditional Independence Structure , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.