Recognition: unknown
Dual Alignment Between Language Model Layers and Human Sentence Processing
Pith reviewed 2026-05-10 05:20 UTC · model grok-4.3
The pith
Later layers of language models better estimate human cognitive effort during syntactic ambiguity processing, unlike early layers which align with everyday reading.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
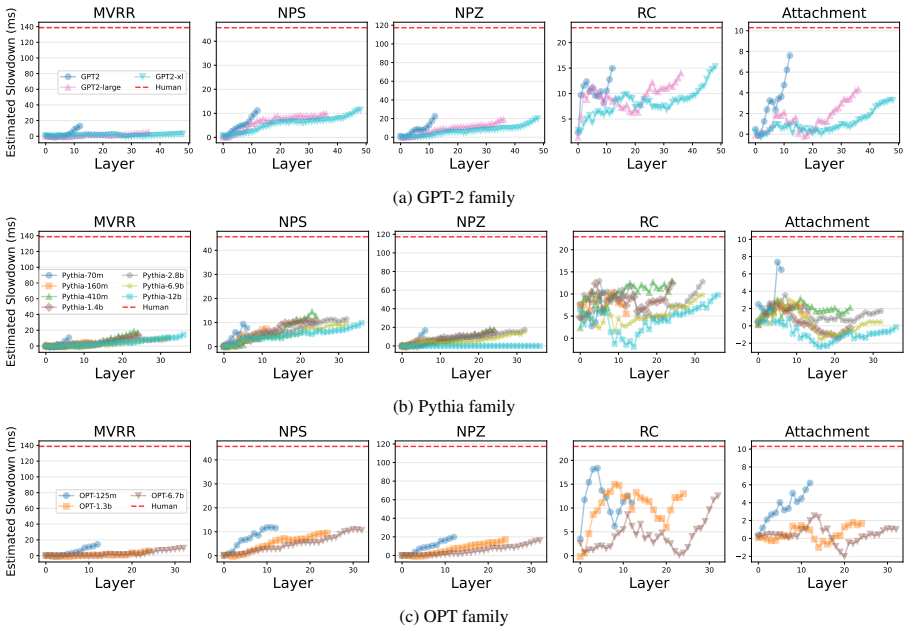
In contrast to naturalistic reading, later layers of LLMs better estimate human cognitive effort observed in syntactic ambiguity processing in English, but still underestimate the human data. This dual alignment indicates that naturalistic reading employs a somewhat weak prediction akin to earlier layers of LMs, while syntactically challenging processing requires more fully-contextualized representations better modeled by later layers. Probability-update measures using shallow and deep layers show a complementary advantage to single-layer surprisal in reading time modeling.
What carries the argument
Layer-specific surprisal and multi-layer probability-update measures from LLMs, compared against human reading times on syntactically ambiguous versus naturalistic sentences.
If this is right
- Naturalistic reading employs weaker predictions similar to early LLM layers, while syntactically challenging processing draws on more fully-contextualized representations from later layers.
- Measures that update probabilities using both shallow and deep layers together predict human reading times more accurately than surprisal from any one layer alone.
- Human sentence processing may operate in multiple modes depending on syntactic difficulty, each corresponding to different degrees of contextualization inside neural networks.
- Models of cognitive effort can be improved by selecting or combining LLM layers according to the processing demands of the input.
Where Pith is reading between the lines
- If the layer preference holds across additional languages and ambiguity types, it could guide the design of hybrid cognitive models that switch between shallow and deep processing.
- Controlled experiments that vary reading-time collection methods while holding stimuli fixed could isolate whether the underestimation by later layers stems from missing incremental constraints in current LLMs.
- The complementary advantage of mixed-layer updates suggests that future architectures might explicitly route information between early and late stages to better simulate human cognitive load.
Load-bearing premise
The observed differences in how early versus late layers align with human reading times reflect distinct human processing modes rather than artifacts of the chosen English ambiguity stimuli, model architectures, or reading-time measurement methods.
What would settle it
Running the same layer-wise comparison on a fresh set of syntactic ambiguities from a non-English language or with a different LLM family and finding that early layers instead better predict the ambiguity reading times would falsify the reported dual alignment.
Figures




read the original abstract
A recent study (Kuribayashi et al., 2025) has shown that human sentence processing behavior, typically measured on syntactically unchallenging constructions, can be effectively modeled using surprisal from early layers of large language models (LLMs). This raises the question of whether such advantages of internal layers extend to more syntactically challenging constructions, where surprisal has been reported to underestimate human cognitive effort. In this paper, we begin by exploring internal layers that better estimate human cognitive effort observed in syntactic ambiguity processing in English. Our experiments show that, in contrast to naturalistic reading, later layers better estimate such a cognitive effort, but still underestimate the human data. This dual alignment sheds light on different modes of sentence processing in humans and LMs: naturalistic reading employs a somewhat weak prediction akin to earlier layers of LMs, while syntactically challenging processing requires more fully-contextualized representations, better modeled by later layers of LMs. Motivated by these findings, we also explore several probability-update measures using shallow and deep layers of LMs, showing a complementary advantage to single-layer's surprisal in reading time modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that, unlike in naturalistic reading where early LLM layers align better with human processing costs, later layers provide superior estimates of cognitive effort during syntactic ambiguity resolution in English (though still underestimating human data). This 'dual alignment' is interpreted as evidence for distinct human sentence processing modes (weak prediction vs. fully contextualized representations). Probability-update measures combining shallow and deep layers are shown to offer complementary advantages over single-layer surprisal for reading-time modeling.
Significance. If the empirical patterns hold after controls, the work usefully extends layer-wise surprisal analyses to challenging constructions and introduces probability-update metrics that may improve predictive power. It provides concrete comparisons between model internals and human data, addressing known underestimation issues in surprisal-based models of ambiguity processing.
major comments (1)
- [Abstract] The load-bearing claim that later layers specifically model 'more fully-contextualized representations' required for syntactically challenging processing (as opposed to early layers for naturalistic reading) rests on the assumption that observed layer differences reflect distinct human modes rather than artifacts of the English ambiguity stimuli, LLM architectures, or reading-time extraction methods. The manuscript should include targeted controls (e.g., stimulus-matched comparisons or cross-model tests) to rule out that later layers simply encode richer context for any low-predictability construction.
minor comments (2)
- [Abstract] The abstract states directional findings and underestimation but provides no quantitative details on effect sizes, statistical controls, or exact quantification of underestimation; these must be added with precise reporting from the results sections.
- Clarify the exact definition and computation of the 'probability-update measures' from shallow and deep layers, including how they are combined and compared to single-layer surprisal.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the scope of our claims. We respond to the major comment below and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract] The load-bearing claim that later layers specifically model 'more fully-contextualized representations' required for syntactically challenging processing (as opposed to early layers for naturalistic reading) rests on the assumption that observed layer differences reflect distinct human modes rather than artifacts of the English ambiguity stimuli, LLM architectures, or reading-time extraction methods. The manuscript should include targeted controls (e.g., stimulus-matched comparisons or cross-model tests) to rule out that later layers simply encode richer context for any low-predictability construction.
Authors: We agree that the dual-alignment interpretation benefits from explicit controls against confounds. The manuscript already contrasts results against Kuribayashi et al. (2025), who applied the identical LLM families to naturalistic (non-ambiguous) stimuli and observed the opposite layer preference; this cross-stimulus comparison within the same architectures provides initial evidence that the shift is tied to syntactic challenge rather than general low predictability. To strengthen this further, we will add a new subsection reporting stimulus-matched analyses on other low-predictability but syntactically unambiguous items drawn from the same reading-time corpora. We will also include a cross-model check using an additional LLM family. Finally, we will revise the abstract to replace 'required for' with 'better modeled by' to avoid overstatement. These changes will be incorporated in the revision. revision: partial
Circularity Check
No circularity: empirical layer comparisons are data-driven
full rationale
The paper reports experimental results from extracting surprisal and probability-update measures from LLM layers and correlating them with human reading-time data on naturalistic vs. syntactically ambiguous English sentences. No mathematical derivation chain exists that reduces a claimed prediction or uniqueness result to fitted inputs or self-citations by construction. The single self-citation to Kuribayashi et al. (2025) supplies background context for the extension to ambiguity stimuli but does not justify any core claim; all reported alignments, underestimations, and complementary advantages are direct measurements against external human data and are falsifiable independently of the present fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Surprisal from LLM layers can be meaningfully compared to human cognitive effort measured via reading times or eye-tracking.
Reference graph
Works this paper leans on
-
[1]
A Probabilistic
Hale, John , pages =. A Probabilistic. 2001 , booktitle =
2001
-
[2]
2020 , booktitle =
Hu, Jennifer and Gauthier, Jon and Qian, Peng and Wilcox, Ethan and Levy, Roger , pages =. 2020 , booktitle =
2020
-
[3]
2016 , journal =
Brennan, Jonathan R and Stabler, Edward P and Van Wagenen, Sarah E and Luh, Wen-Ming and Hale, John T , pages =. 2016 , journal =
2016
-
[4]
2014 , journal =
Uchida, Shodai and Miyamoto, E and Hirose, Yuki and Kobayashi, Yuki and Ito, Takane , pages =. 2014 , journal =
2014
-
[5]
Proceedings of SCiL 2019 , author =
Can Entropy Explain Successor Surprisal Effects in Reading? , year =. Proceedings of SCiL 2019 , author =
2019
-
[6]
2019 , booktitle =
Aurnhammer, C and Frank, S L , pages =. 2019 , booktitle =
2019
-
[7]
2009 , booktitle =
Roark, Brian and Bachrach, Asaf and Cardenas, Carlos and Pallier, Christophe , month =. 2009 , booktitle =
2009
-
[8]
2020 , booktitle =
Oseki, Yohei and Asahara, Masayuki , pages =. 2020 , booktitle =
2020
-
[9]
1996 , journal =
Rayner, Keith and Well, Arnold D , number =. 1996 , journal =
1996
-
[10]
Entropy Rate Constancy in Text
Genzel, Dmitriy and Charniak, Eugene. Entropy Rate Constancy in Text. Proceedings of ACL. 2002. doi:10.3115/1073083.1073117
-
[11]
2020 , booktitle =
Linzen, Tal , pages =. 2020 , booktitle =
2020
-
[12]
2020 , booktitle =
Meister, Clara and Cotterell, Ryan and Vieira, Tim , pages =. 2020 , booktitle =
2020
-
[13]
Psychological Science , author =
Insensitivity of the Human Sentence-Processing System to Hierarchical Structure , year =. Psychological Science , author =
-
[14]
Proceedings of NeurIPS , author =
Language Models are Few-Shot Learners , year =. Proceedings of NeurIPS , author =
-
[15]
2020 , journal =
Tamkin, Alex and Jurafsky, Dan and Goodman, Noah , volume =. 2020 , journal =
2020
-
[16]
2006 , journal =
Kudo, Taku , url =. 2006 , journal =
2006
-
[17]
2011 , journal =
Bender, Emily M , number =. 2011 , journal =
2011
-
[18]
2020 , booktitle =
Upadhye, Shiva and Bergen, Leon and Kehler, Andrew , month =. 2020 , booktitle =
2020
-
[19]
2020 , journal =
Kaplan, Jared and McCandlish, Sam and Henighan, Tom and Brown, Tom B and Chess, Benjamin and Child, Rewon and Gray, Scott and Radford, Alec and Wu, Jeffrey and Amodei, Dario , url =. 2020 , journal =
2020
-
[20]
2012 , booktitle =
Fossum, Victoria and Levy, Roger , month =. 2012 , booktitle =
2012
-
[21]
2007 , booktitle =
Jaeger, T and Levy, Roger , editor =. 2007 , booktitle =
2007
-
[22]
2018 , booktitle =
Marvin, Rebecca and Linzen, Tal , pages =. 2018 , booktitle =
2018
-
[23]
Stefan L. Frank and Leun J. Otten and Giulia Galli and Gabriella Vigliocco , keywords =. The ERP response to the amount of information conveyed by words in sentences , journal =. 2015 , issn =. doi:https://doi.org/10.1016/j.bandl.2014.10.006 , url =
-
[24]
2020 , booktitle =
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit , pages =. 2020 , booktitle =
2020
-
[25]
1981 , journal =
Prince, Ellen F , publisher =. 1981 , journal =
1981
-
[26]
2019 , journal =
Linzen, Tal , number =. 2019 , journal =
2019
-
[27]
Why are some word orders more common than others? A uniform information density account , url =
Maurits, Luke and Navarro, Dan and Perfors, Amy , booktitle =. Why are some word orders more common than others? A uniform information density account , url =
-
[28]
2019 , booktitle =
Shain, Cory , isbn =. 2019 , booktitle =
2019
-
[29]
Shannon, C. E. , number =. 1948 , journal =. doi:10.1002/j.1538-7305.1948.tb01338.x , issn =
-
[30]
, isbn =
Hewitt, John and Manning, Christopher D. , isbn =. 2019 , booktitle =
2019
-
[31]
and Carpenter, Patricia A
Just, Marcel A. and Carpenter, Patricia A. , doi =. 1980 , journal =
1980
-
[32]
2010 , journal =
Nakatani, Kentaro and Gibson, Edward , doi =. 2010 , journal =
2010
-
[33]
and Kaiser, Lukasz and Polosukhin, Illia , pages =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , pages =. 2017 , booktitle =
2017
-
[34]
2018 , booktitle =
Asahara, Masayuki , pages =. 2018 , booktitle =
2018
-
[35]
2017 , booktitle =
Asahara, Masayuki , pages =. 2017 , booktitle =
2017
-
[36]
2017 , booktitle =
Asahara, Masayuki and Kato, Sachi , pages =. 2017 , booktitle =
2017
-
[37]
2018 , journal =
Asahara, Masayuki , number =. 2018 , journal =
2018
-
[38]
Beyond Accuracy: Behavioral Testing of
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer , pages =. 2020 , booktitle =. doi:10.18653/v1/2020.acl-main.442 , arxivId =
-
[39]
Human Sentence Processing: Recurrence or Attention?
Merkx, Danny and Frank, Stefan L. Human Sentence Processing: Recurrence or Attention?. Proceedings of CMCL. 2021. doi:10.18653/v1/2021.cmcl-1.2
-
[40]
and Gibson, Edward , doi =
Futrell, Richard and Levy, Roger P. and Gibson, Edward , doi =. 2020 , journal =
2020
-
[41]
Nakatani, Kentaro and Gibson, Edward , number =. 2008 , journal =. doi:10.1515/LING.2008.003 , issn =
-
[42]
Levy, Roger , number =. 2008 , journal =. doi:10.1016/j.cognition.2007.05.006 , issn =
-
[43]
Extracting Training Data from Large Language Models , journal =
Nicholas Carlini and Florian Tram. Extracting Training Data from Large Language Models , journal =. 2020 , url =
2020
-
[44]
Hale, John and Dyer, Chris and Kuncoro, Adhiguna and Brennan, Jonathan R. , pages =. 2018 , booktitle =. doi:10.18653/v1/p18-1254 , arxivId =
-
[45]
Frank, Stefan L. and Bod, Rens , number =. 2011 , journal =. doi:10.1177/0956797611409589 , issn =
-
[46]
2019 , url=
Language models are unsupervised multitask learners , author=. 2019 , url=
2019
-
[47]
doi:10.18653/v1/2020.acl-main.47 , arxivId =
2020 , author =. doi:10.18653/v1/2020.acl-main.47 , arxivId =
-
[48]
Gibson, Edward , number =. 1998 , journal =. doi:10.1016/S0010-0277(98)00034-1 , issn =
-
[49]
Konieczny, Lars , number =. 2000 , journal =. doi:10.1023/A:1026528912821 , issn =
-
[50]
2011 , journal =
Lin, Yowyu , number =. 2011 , journal =
2011
-
[52]
Futrell, Richard and Gibson, Edward and Levy, Roger P. , doi =. 2020 , journal =
2020
-
[53]
2019 , booktitle =
Oseki, Yohei and Yang, Charles and Marantz, Alec , pages =. 2019 , booktitle =
2019
-
[54]
Futrell, Richard and Wilcox, Ethan and Morita, Takashi and Qian, Peng and Ballesteros, Miguel and Levy, Roger , isbn =. 2019 , booktitle =. doi:10.18653/v1/n19-1004 , arxivId =
-
[55]
2016 , booktitle =
Sennrich, Rico and Haddow, Barry and Birch, Alexandra , pages =. 2016 , booktitle =
2016
-
[56]
2020 , booktitle =
Wilcox, Ethan Gotlieb and Gauthier, Jon and Hu, Jennifer and Qian, Peng and Levy, Roger , pages =. 2020 , booktitle =
2020
-
[57]
2018 , booktitle =
Goodkind, Adam and Bicknell, Klinton , pages =. 2018 , booktitle =
2018
-
[58]
2016 , booktitle =
Asahara, Masayuki and Ono, Hajime and Miyamoto, Edson T , pages =. 2016 , booktitle =
2016
-
[59]
Association for Computational Linguistics
Dyer, Chris and Kuncoro, Adhiguna and Ballesteros, Miguel and Smith, Noah A. , isbn =. 2016 , publisher = "Association for Computational Linguistics", booktitle =. doi:10.18653/v1/n16-1024 , arxivId =
-
[60]
Davis, Forrest and van Schijndel, Marten , pages =. 2020 , booktitle =. doi:10.18653/v1/2020.acl-main.179 , arxivId =
-
[61]
Kudo, Taku and Richardson, John , pages =. 2018 , booktitle =. doi:10.18653/v1/d18-2012 , arxivId =
work page internal anchor Pith review doi:10.18653/v1/d18-2012 2018
-
[62]
2020 , booktitle =
Gauthier, Jon and Hu, Jennifer and Wilcox, Ethan and Qian, Peng and Levy, Roger , pages =. 2020 , booktitle =
2020
-
[63]
2000 , journal =
Gibson, Edward , pages =. 2000 , journal =
2000
-
[64]
2015 , booktitle =
Barrett, Maria and Agi, Zeljko and S. 2015 , booktitle =
2015
-
[65]
Rayner, Keith and Kambe, Gretchen and Duffy, Susan A. , number =. 2000 , journal =. doi:10.1080/713755934 , issn =
-
[66]
Goldin-Meadow, Susan and So, Wing Chee and. 2008 , journal =. doi:10.1073/pnas.0710060105 , issn =
-
[67]
2017 , journal =
Ferrer-i-Cancho, Ramon , issn =. 2017 , journal =
2017
-
[68]
Wilcox, Ethan and Levy, Roger and Morita, Takashi and Futrell, Richard , pages =. 2019 , booktitle =. doi:10.18653/v1/w18-5423 , arxivId =
-
[69]
fairseq: A fast, extensible toolkit for sequence modeling
Ott, Myle and Edunov, Sergey and Baevski, Alexei and Fan, Angela and Gross, Sam and Ng, Nathan and Grangier, David and Auli, Michael. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. Proceedings of NAACL (Demonstrations). 2019. doi:10.18653/v1/N19-4009
-
[70]
Douglas Bates and Martin Mächler and Ben Bolker and Steve Walker , title =. Journal of Statistical Software, Articles , volume =. 2015 , keywords =. doi:10.18637/jss.v067.i01 , url =
-
[71]
A Cognitive Regularizer for Language Modeling
Wei, Jason and Meister, Clara and Cotterell, Ryan. A Cognitive Regularizer for Language Modeling. Proceedings of ACL. 2021. doi:10.18653/v1/2021.acl-long.404
-
[72]
2016 , publisher=
Information Structure in Spoken Japanese: Particles, word order, and intonation , author=. 2016 , publisher=
2016
-
[73]
Proceedings of CMCL , pages=
Predicting Japanese scrambling in the wild , author=. Proceedings of CMCL , pages=. 2017 , url=
2017
-
[74]
2017 , editor =
Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[75]
Gengo seikatsu [Language life]
Saeki, Tetsuo. Gengo seikatsu [Language life]. 1960
1960
-
[76]
2017 , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , journal =. 2017 , url =
2017
-
[77]
Journal of Memory and Language , volume =
Inbal Arnon and Neal Snider , keywords =. Journal of Memory and Language , volume =. 2010 , issn =. doi:https://doi.org/10.1016/j.jml.2009.09.005 , url =
-
[78]
Sentence-Level Fluency Evaluation: References Help, But Can Be Spared!
Kann, Katharina and Rothe, Sascha and Filippova, Katja , journal=. 2018 , month = oct, booktitle=. doi:10.18653/v1/K18-1031 , address=
-
[79]
Proceedings of the Workshop on Statistical Machine Translation , pages=
Language models and reranking for machine translation , author=. Proceedings of the Workshop on Statistical Machine Translation , pages=. 2006 , month=jun, address=
2006
-
[80]
2019 , url=
Alexei Baevski and Michael Auli , booktitle=. 2019 , url=
2019
-
[81]
Asahara, Masayuki and Nambu, Satoshi and Sano, Shin-Ichiro , booktitle=. 2018 , address=. doi:10.18653/v1/W18-2805 , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.