Recognition: unknown
Latent Phase-Shift Rollback: Inference-Time Error Correction via Residual Stream Monitoring and KV-Cache Steering
Pith reviewed 2026-05-10 05:04 UTC · model grok-4.3
The pith
Large language models can correct unrecoverable reasoning errors at inference by monitoring residual stream phase shifts and steering the KV cache.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
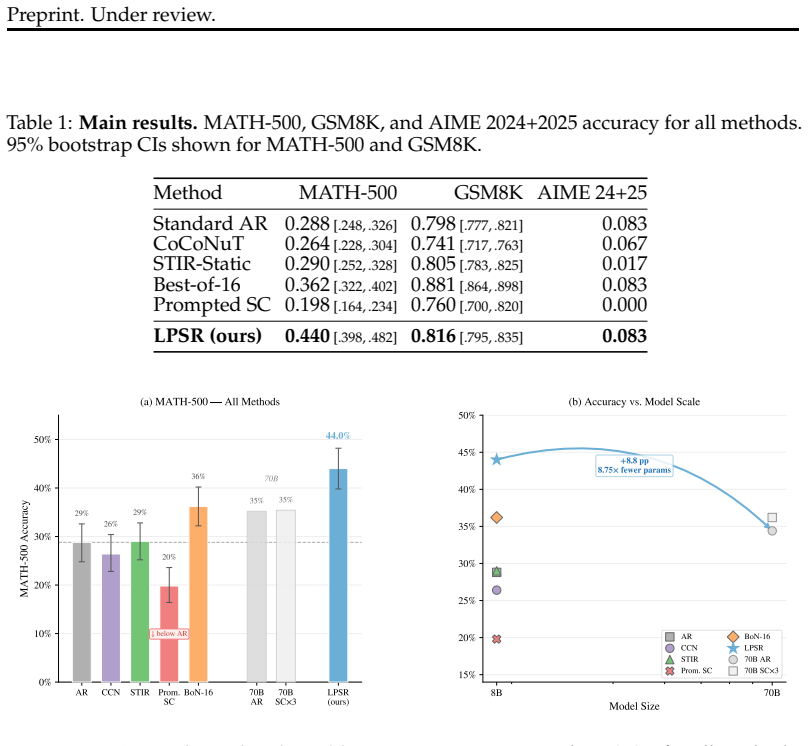
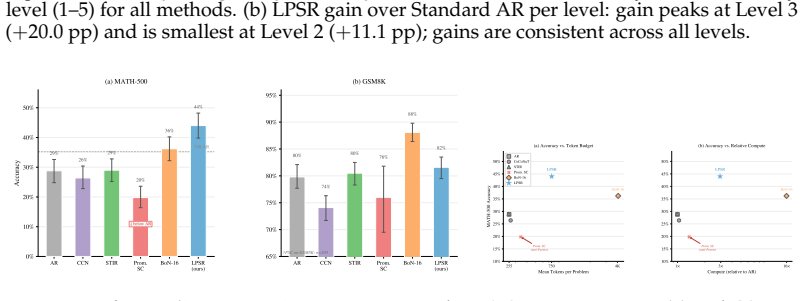
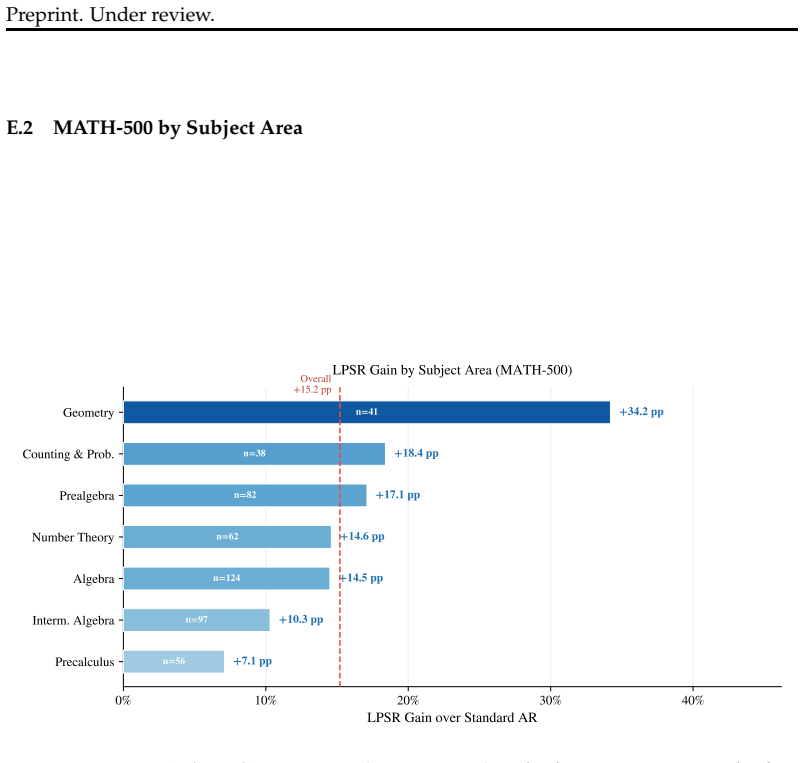
By monitoring the residual stream at a critical layer for abrupt directional reversals detected through a cosine-similarity and entropy dual gate, Latent Phase-Shift Rollback rolls back the KV-cache and injects a pre-computed steering vector to correct errors during generation, delivering 44.0% accuracy on MATH-500 with an 8B model compared to 28.8% for standard autoregressive decoding.
What carries the argument
Latent Phase-Shift Rollback, which uses a dual gate on cosine similarity and entropy at layer lcrit to detect phase shifts in the residual stream, followed by KV-cache rollback and steering vector injection.
If this is right
- Math accuracy improves by 15.2 percentage points on MATH-500 for 8B models.
- Prompted self-correction is outperformed by 24.2 points despite being a natural baseline.
- Token cost is 5.4 times lower than Best-of-16 sampling while achieving higher accuracy.
- Performance exceeds that of a 70B model with 8.75 times fewer parameters.
- The optimal layer for error detection differs from the optimal layer for correction accuracy.
Where Pith is reading between the lines
- The method implies that error signals appear in the internal activations before they affect the final output tokens.
- It could be extended to other domains like code generation or logical reasoning by identifying suitable critical layers.
- Adaptive selection of the monitoring layer during generation might further improve results.
- Combining this with other inference techniques could yield even larger gains at modest extra cost.
Load-bearing premise
That the detected abrupt directional reversals at the critical layer correspond to unrecoverable reasoning errors that the steering vector can reliably correct.
What would settle it
Comparing performance when steering is applied at randomly chosen steps versus only at detected phase shifts; if random application matches or exceeds the gated version, the specific detection mechanism would be shown unnecessary.
Figures





read the original abstract
Large language models frequently commit unrecoverable reasoning errors mid-generation: once a wrong step is taken, subsequent tokens compound the mistake rather than correct it. We introduce $\textbf{Latent Phase-Shift Rollback}$ (LPSR): at each generation step, we monitor the residual stream at a critical layer lcrit, detect abrupt directional reversals (phase shifts) via a cosine-similarity $+$ entropy dual gate, and respond by rolling back the KV-cache and injecting a pre-computed steering vector. No fine-tuning, gradient computation, or additional forward passes are required. LPSR achieves $\mathbf{44.0\%}$ on MATH-500 with an 8B model versus $28.8\%$ for standard AR ($+15.2$ pp; McNemar $\chi^2 = 66.96$, $p < 10^{-15}$). Critically, prompted self-correction, the most natural inference-time baseline, scores only $19.8\%$, below standard AR; LPSR exceeds it by $+24.2$ pp ($\chi^2 = 89.4$, $p \approx 0$). LPSR also outperforms Best-of-16 ($+7.8$ pp) at $5.4\times$ lower token cost, and surpasses a standard 70B model ($35.2\%$) with $8.75\times$ fewer parameters at ${\sim}3\times$ the token budget. A 32-layer sweep reveals a novel \textbf{detection-correction dissociation}: error-detection AUC peaks at layer~14 ($0.718$) but task accuracy peaks at layer~16 ($44.0\%$ vs.\ $29.2\%$), demonstrating that optimal monitoring depth differs for detection and correction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Latent Phase-Shift Rollback (LPSR), an inference-time technique for correcting unrecoverable reasoning errors in LLMs. It monitors the residual stream at a critical layer l_crit for abrupt directional reversals using a cosine-similarity and entropy-based dual gate. Upon detection, it rolls back the KV-cache and injects a pre-computed steering vector. The method requires no fine-tuning or additional forward passes. On the MATH-500 benchmark, LPSR achieves 44.0% accuracy with an 8B model, compared to 28.8% for standard autoregressive decoding (+15.2 pp), outperforming prompted self-correction (19.8%) and Best-of-16 sampling, while also surpassing a 70B model.
Significance. If the mechanistic interpretation holds, the results would be significant for inference-time scaling and error correction in LLMs. The approach offers substantial gains on mathematical reasoning tasks without training or extra forward passes, with reported efficiency advantages over sampling methods. The observed dissociation between optimal layers for detection (layer 14, AUC 0.718) and correction (layer 16, 44.0% accuracy) is a novel empirical finding. The inclusion of statistical tests (McNemar chi-squared with p-values) and a 32-layer sweep strengthens the empirical component.
major comments (2)
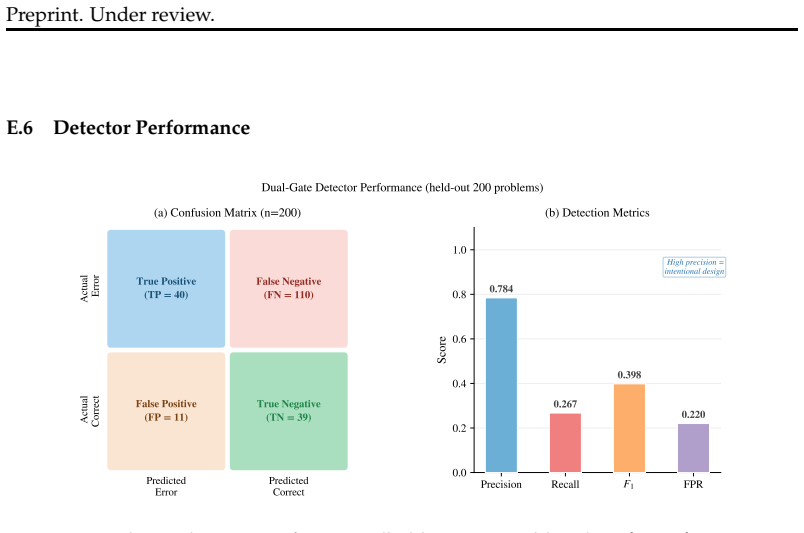
- [Abstract] The central performance claim (Abstract) that the cosine-similarity + entropy dual gate at l_crit specifically detects unrecoverable reasoning errors is not supported by direct evidence such as per-instance tracing, human annotation of triggered steps, or contrastive residual-stream analysis between error and non-error trajectories. Without this, the +15.2 pp lift could arise from rollback-induced diversity or untargeted vector injection rather than causal correction.
- [Results] The results section reports aggregate accuracy and a layer dissociation but provides no ablation showing that non-triggered generations remain unaffected or that the gate distinguishes error from non-error steps. This is load-bearing for the claim that LPSR performs targeted error correction rather than generic intervention.
minor comments (2)
- [Abstract] The notation for the critical layer is given as lcrit in the abstract text but would benefit from consistent mathematical formatting (e.g., l_{crit}) throughout.
- [Methods] Exact construction details for the pre-computed steering vector and the precise threshold values in the dual gate are referenced but would benefit from explicit equations or pseudocode to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger causal evidence on the specificity of LPSR's error detection. We address each major comment below and commit to revisions that add the requested analyses without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract] The central performance claim (Abstract) that the cosine-similarity + entropy dual gate at l_crit specifically detects unrecoverable reasoning errors is not supported by direct evidence such as per-instance tracing, human annotation of triggered steps, or contrastive residual-stream analysis between error and non-error trajectories. Without this, the +15.2 pp lift could arise from rollback-induced diversity or untargeted vector injection rather than causal correction.
Authors: We agree that per-instance tracing, human annotation of triggered steps, and explicit contrastive residual-stream analysis would provide stronger direct evidence for the gate's specificity to unrecoverable errors. The manuscript currently supports the claim indirectly via the statistically significant accuracy lift (McNemar χ² = 66.96, p < 10^{-15}), outperformance over prompted self-correction and Best-of-16, and the novel detection-correction layer dissociation (AUC peak at layer 14 vs. accuracy peak at layer 16). These elements are inconsistent with purely generic diversity or untargeted injection. In revision we will add a contrastive analysis of residual-stream trajectories on error vs. non-error steps and report intervention rates broken down by correctness. revision: yes
-
Referee: [Results] The results section reports aggregate accuracy and a layer dissociation but provides no ablation showing that non-triggered generations remain unaffected or that the gate distinguishes error from non-error steps. This is load-bearing for the claim that LPSR performs targeted error correction rather than generic intervention.
Authors: The current results section indeed lacks an explicit ablation confirming that non-triggered generations are unaffected and does not directly compare gate activation statistics between error and non-error steps. We acknowledge this limits the strength of the targeted-correction interpretation. In the revised manuscript we will include (1) an ablation measuring accuracy on the subset of generations where the dual gate never triggers (to verify no unintended degradation) and (2) gate-trigger statistics and activation histograms conditioned on whether the final answer is correct or incorrect. These additions will directly address whether the intervention is selective. revision: yes
Circularity Check
No circularity: empirical inference-time method validated on external benchmarks
full rationale
The paper introduces LPSR as a procedural inference-time technique involving residual-stream monitoring with a cosine-similarity plus entropy gate, KV-cache rollback, and injection of a pre-computed steering vector. All performance claims (e.g., 44.0% on MATH-500) are obtained via direct benchmarking against independent baselines and datasets, with no equations, derivations, or self-citations that reduce the reported gains to fitted inputs or definitional tautologies by construction. The 32-layer sweep and dissociation findings are likewise empirical observations, not self-referential.
Axiom & Free-Parameter Ledger
free parameters (2)
- critical layer lcrit
- cosine-similarity and entropy thresholds
invented entities (1)
-
latent phase shift
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Softmax linear units
Anthropic . Softmax linear units. Transformer Circuits Thread, 2022. https://transformer-circuits.pub/2022/solu/index.html
2022
-
[2]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models. In AAAI Conference on Artificial Intelligence, 2024
2024
-
[3]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. In Advances in Neural Information Processing Systems, 2021
2021
-
[4]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Saurav Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, Chris Olah, and J...
2021
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1 : Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In International Conference on Learning Representations, 2024
2024
-
[8]
Probability in Banach Spaces: Isoperimetry and Processes
Michel Ledoux and Michel Talagrand. Probability in Banach Spaces: Isoperimetry and Processes . Springer, Berlin, Heidelberg, 1991
1991
-
[9]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pp.\ 19274--19286. PMLR, 2023
2023
-
[10]
Let's verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In International Conference on Learning Representations, 2024
2024
-
[11]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Boaz Dolan, Swaroop He, Gerard De Melo, Peter Clark, Antoine Bosselut, and Ashish Sabharwal. Self-refine: Iterative refinement with self-feedback. In Advances in Neural Information Processing Systems...
2023
-
[12]
The expressive power of transformers with chain of thought
William Merrill and Ashish Sabharwal. The expressive power of transformers with chain of thought. In International Conference on Learning Representations, 2024
2024
-
[14]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. In International Conference on Machine Learning, 2024
2024
-
[16]
Scaling LLM test-time compute optimally can be more effective than scaling model parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. In International Conference on Learning Representations, 2025
2025
-
[17]
Activation addition: Steering language models without optimization
Alex Turner, Lisa Thiergart, Gavin Udell, David Leech, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[18]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback. In Advances in Neural Information Processing Systems, 2022
2022
-
[19]
Large language models still can't plan (a benchmark for LLMs on planning and reasoning about change)
Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. Large language models still can't plan (a benchmark for LLMs on planning and reasoning about change). In Advances in Neural Information Processing Systems Workshop on Foundation Models for Decision Making, 2023
2023
-
[20]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations, 2023
2023
-
[21]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pp.\ 24824--24837. Curran Associates, Inc., 2022
2022
-
[22]
Jiayi Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qiyuan Feng, Haoming Xu, Shaochen Lian, Zheng Jiang, Zhengmian Hu, Xia Hu, et al. KV cache compression, but what must we give in return? A comprehensive benchmark of long context capable approaches. arXiv preprint arXiv:2407.01527, 2024
-
[23]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[24]
Representation engineering: A top-down approach to AI transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwath Goel, Nathaniel Li, Michael J Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to AI...
2024
-
[25]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
2022
-
[26]
International Conference on Learning Representations , year =
Let's Verify Step by Step , author =. International Conference on Learning Representations , year =
-
[27]
Advances in Neural Information Processing Systems , year =
Solving Math Word Problems with Process- and Outcome-Based Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[28]
International Conference on Learning Representations , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations , year =
-
[29]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , booktitle =. Scaling
-
[30]
Advances in Neural Information Processing Systems , volume =
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[31]
AAAI Conference on Artificial Intelligence , year =
Graph of Thoughts: Solving Elaborate Problems with Large Language Models , author =. AAAI Conference on Artificial Intelligence , year =
-
[32]
Transformer Circuits Thread , year =
A Mathematical Framework for Transformer Circuits , author =. Transformer Circuits Thread , year =
-
[33]
Transformer Circuits Thread , year =
Softmax Linear Units , author =. Transformer Circuits Thread , year =
-
[34]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwath and Li, Nathaniel and Byun, Michael J and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J Z...
-
[35]
Advances in Neural Information Processing Systems , volume =
Activation Addition: Steering Language Models Without Optimization , author =. Advances in Neural Information Processing Systems , volume =
-
[36]
International Conference on Machine Learning , year =
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. International Conference on Machine Learning , year =
-
[37]
International Conference on Machine Learning , pages =
Fast Inference from Transformers via Speculative Decoding , author =. International Conference on Machine Learning , pages =. 2023 , publisher =
2023
-
[38]
Yang, Jiayi and Jin, Hongye and Tang, Ruixiang and Han, Xiaotian and Feng, Qiyuan and Xu, Haoming and Lian, Shaochen and Jiang, Zheng and Hu, Zhengmian and Hu, Xia and others , journal =
-
[39]
Advances in Neural Information Processing Systems , volume =
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[40]
International Conference on Learning Representations , year =
Large Language Models Cannot Self-Correct Reasoning Yet , author =. International Conference on Learning Representations , year =
-
[41]
Training Large Language Models to Reason in a Continuous Latent Space
Training Large Language Models to Reason in a Continuous Latent Space , author =. arXiv preprint arXiv:2412.06769 , year =
work page internal anchor Pith review arXiv
-
[42]
The. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in Neural Information Processing Systems , year =
Training Verifiers to Solve Math Word Problems , author =. Advances in Neural Information Processing Systems , year =
-
[44]
Probability in
Ledoux, Michel and Talagrand, Michel , year =. Probability in
-
[45]
International Conference on Learning Representations , year =
The Expressive Power of Transformers with Chain of Thought , author =. International Conference on Learning Representations , year =
-
[46]
Large Language Models Still Can't Plan (A Benchmark for
Valmeekam, Karthik and Marquez, Matthew and Sreedharan, Sarath and Kambhampati, Subbarao , booktitle =. Large Language Models Still Can't Plan (A Benchmark for
-
[47]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , journal =
-
[48]
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity , author =. arXiv preprint arXiv:2506.06941 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.