Recognition: unknown
Machine Spirits: Speculation and Adaptation of LLM Agents in Asset Markets
Pith reviewed 2026-05-10 17:03 UTC · model grok-4.3
The pith
LLMs used as traders in asset markets can generate speculative bubbles and market instability through adaptation in heterogeneous groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
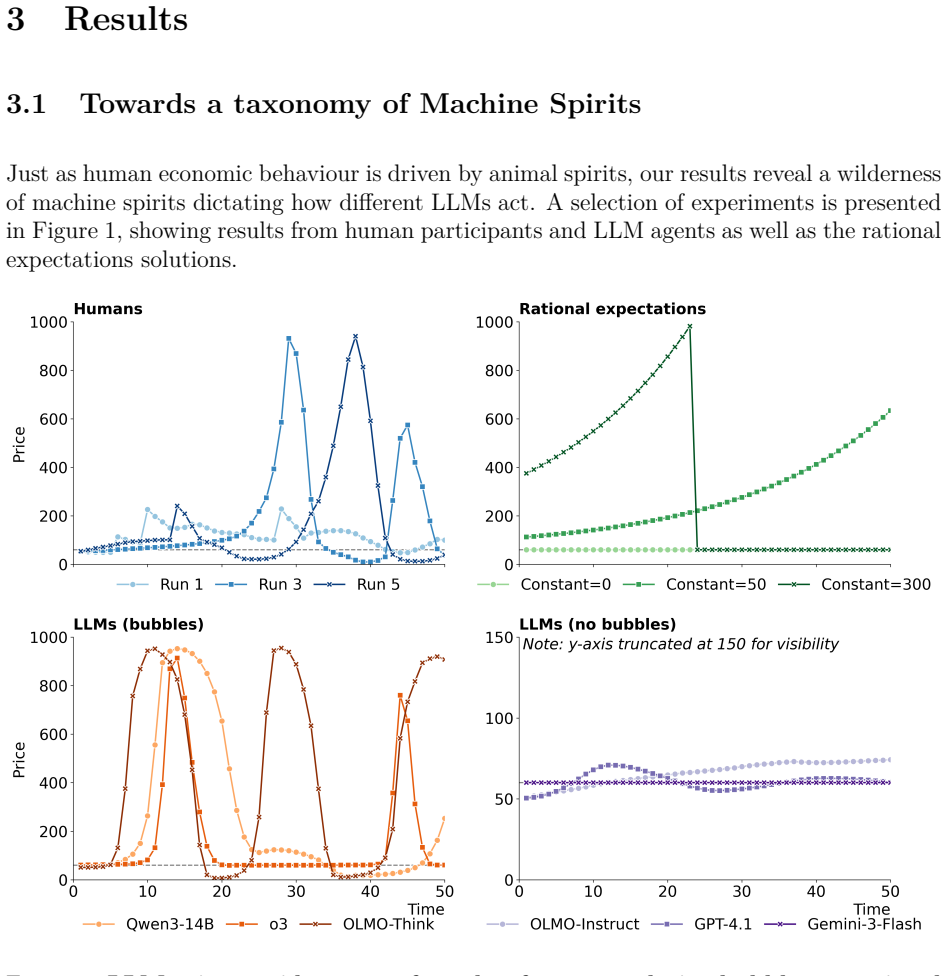
Heterogeneous groups of LLM agents in a simulated financial market generate variable outcomes across runs, with individual adaptation enabling exploitation of simpler agents and higher returns but also contributing to price bubbles and amplified volatility, contrary to expectations that more capable models would stabilize trading.
What carries the argument
The adaptation of LLM agents' forecasting strategies to the observed behavior of other agents in mixed populations.
If this is right
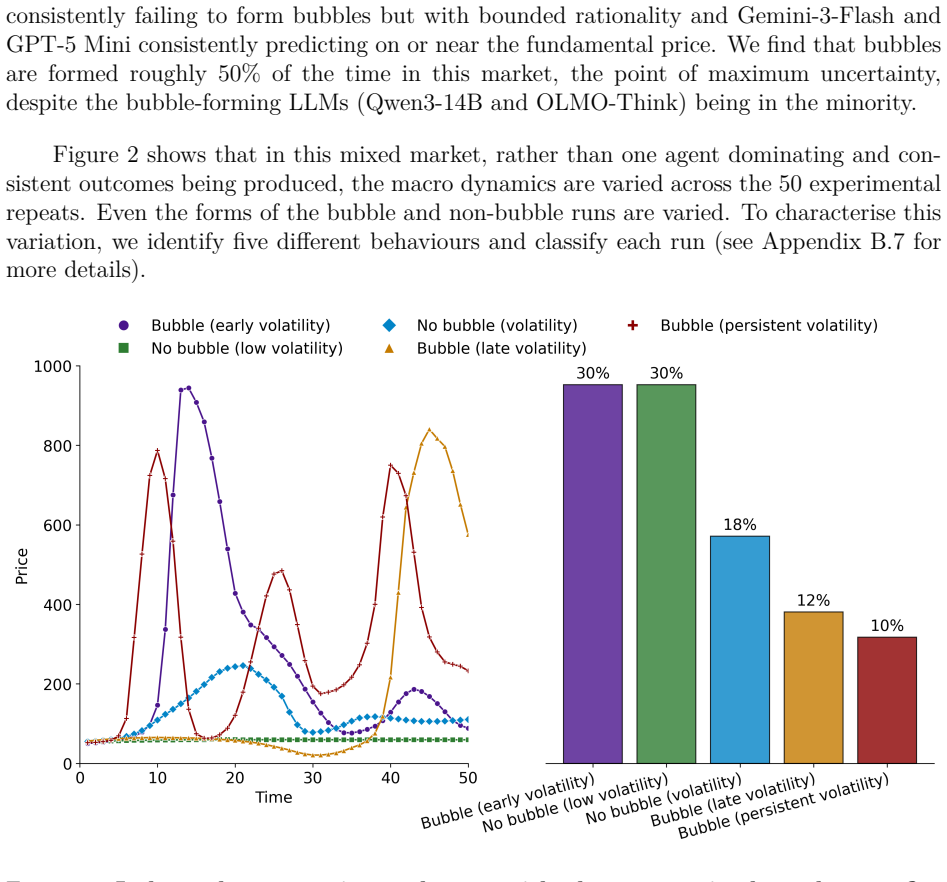
- Heterogeneous LLM populations produce outcomes that vary substantially across repeated simulations.
- Advanced models adapt to exploit less sophisticated ones and achieve higher profits.
- This adaptation contributes to increased market volatility.
- Bubbles form even with only a minority of naturally bubble-forming agents.
Where Pith is reading between the lines
- If these patterns hold in real markets, regulators may need to monitor AI trading systems for emergent instability.
- Designing LLMs specifically to prioritize market stability over individual profit could reduce risks.
- The findings point to potential challenges in scaling AI participation without coordinated rules of engagement.
Load-bearing premise
That the prompting and market simulation accurately represent how LLMs would behave when trading with actual capital at risk.
What would settle it
Observing whether real-world deployments of multiple LLM-based trading agents produce similar patterns of adaptation, exploitation, and volatility spikes in live asset markets.
Figures






read the original abstract
As Large Language Models (LLMs) become increasingly integrated into financial systems, understanding their behavioural properties is crucial. Do LLMs conform to the rational expectations paradigm, do they exhibit human-like "animal spirits", or do they instead manifest distinct "machine spirits"? We investigate these questions with a simulated financial market, exploring the behaviour of 15 LLMs spanning a range of sizes, capabilities, and providers. Our results show that LLMs exhibit a spectrum of economic behaviours, from stable coordination on the fundamental value to human-like speculative bubbles. These behaviours are generally inconsistent with the rational expectations hypothesis. We also consider an ecology of heterogeneous agents, a more realistic setting compared to markets with identical LLM agents. These mixed markets can produce outcomes which vary substantially across repeated simulations. Even the most advanced models fail to consistently stabilise the market, with price bubbles sometimes forming despite only a minority of agents naturally forming bubbles. Instead, advanced models in mixed markets adapt their forecasting strategies to the behaviour of other agents. This adaptation can allow them to successfully exploit less sophisticated counterparts and achieve higher profits, but can also contribute to increased market volatility. These findings suggest that the introduction of AI agents into financial markets fundamentally reshapes their ecology. In particular, heterogeneous populations of LLMs can generate endogenous instability, while individual-level adaptation may amplify, rather than mitigate, market volatility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports simulation experiments placing 15 LLMs (spanning sizes and providers) into an abstracted asset market. It finds that individual LLMs produce a range of behaviors inconsistent with rational expectations, including coordination on fundamentals and human-like speculative bubbles; heterogeneous populations generate variable outcomes across runs, with advanced models adapting to exploit others, sometimes increasing volatility. The central claim is that LLM agents can endogenously destabilize markets and that adaptation may amplify rather than dampen volatility.
Significance. If the reported patterns survive changes in prompting, market microstructure, and capital-at-risk constraints, the work would supply concrete empirical evidence that LLM heterogeneity introduces new instability channels in financial systems. The simulation design is reproducible in principle and avoids parameter fitting, which strengthens the internal validity of the observed adaptation and bubble-formation results.
major comments (3)
- [Methods / Experimental Setup] Methods (prompting and market setup): The abstract and setup description provide no explicit prompting templates, temperature settings, context-window usage, or market parameters (initial price, dividend process, number of periods, trading rules). Without these, it is impossible to judge whether the reported bubble formation and adaptation are robust or sensitive to minor implementation choices; this directly affects the load-bearing claim that heterogeneous LLM populations generate endogenous instability.
- [Results / Heterogeneous Markets] Results on adaptation and volatility: The finding that individual-level adaptation can amplify market volatility rests on comparisons across repeated simulations with fixed prompts. No statistical controls (e.g., regression of volatility on adaptation metrics, robustness to seed variation, or comparison against non-adaptive baselines) are described, leaving open whether the amplification effect is an artifact of the particular ecology or a general property.
- [Discussion / Conclusion] External validity discussion: The extrapolation that LLM agents will 'fundamentally reshape' real financial ecology is unsupported by any mapping exercise showing that the simulated behaviors persist under slippage, position limits, regulatory constraints, or multi-period strategic feedback with actual capital. This gap is load-bearing for the policy-relevant conclusion.
minor comments (2)
- [Abstract] The abstract contains an apparent truncation ('vo') and does not summarize the market model or statistical approach.
- [Figures and Tables] Figure captions and table legends should explicitly state the number of simulation runs, random seeds, and exact LLM identifiers used for each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for improving transparency, statistical rigor, and discussion of limitations. We address each major comment below and commit to revisions that strengthen the paper without altering its core findings.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] Methods (prompting and market setup): The abstract and setup description provide no explicit prompting templates, temperature settings, context-window usage, or market parameters (initial price, dividend process, number of periods, trading rules). Without these, it is impossible to judge whether the reported bubble formation and adaptation are robust or sensitive to minor implementation choices; this directly affects the load-bearing claim that heterogeneous LLM populations generate endogenous instability.
Authors: We agree that full methodological details are essential for reproducibility and assessing robustness. The original submission prioritized the behavioral results over exhaustive implementation specifics, which was an oversight. In the revised manuscript, we will add a comprehensive Methods subsection that includes the exact prompting templates for all 15 LLMs, temperature settings (0.7 for the majority of models), context-window management protocols, and complete market parameters: initial price of 100, dividend process (constant fundamental value with stochastic shocks), 50 trading periods, and trading rules (limit-order book with no short sales in the baseline). These additions will directly enable evaluation of sensitivity to prompting and setup choices. revision: yes
-
Referee: [Results / Heterogeneous Markets] Results on adaptation and volatility: The finding that individual-level adaptation can amplify market volatility rests on comparisons across repeated simulations with fixed prompts. No statistical controls (e.g., regression of volatility on adaptation metrics, robustness to seed variation, or comparison against non-adaptive baselines) are described, leaving open whether the amplification effect is an artifact of the particular ecology or a general property.
Authors: The manuscript already documents substantial outcome variability through 10 independent repeated simulations per heterogeneous configuration, with figures illustrating divergent price paths and profit outcomes. We acknowledge the lack of formal statistical controls. In revision, we will add mean and standard deviation summaries for volatility metrics across runs, explicit comparisons of volatility under adaptive versus fixed-strategy (non-adaptive) baselines, and checks for robustness to random seeds. These enhancements will clarify that the observed amplification arises from adaptation dynamics rather than being an artifact of the specific agent ecology. revision: yes
-
Referee: [Discussion / Conclusion] External validity discussion: The extrapolation that LLM agents will 'fundamentally reshape' real financial ecology is unsupported by any mapping exercise showing that the simulated behaviors persist under slippage, position limits, regulatory constraints, or multi-period strategic feedback with actual capital. This gap is load-bearing for the policy-relevant conclusion.
Authors: The conclusion uses suggestive language ('these findings suggest') to highlight potential instability channels identified in simulation, rather than claiming direct real-world effects. We accept that the external-validity discussion requires expansion. The revised Discussion will explicitly address the absence of slippage, position limits, regulatory constraints, and real-capital feedback loops, framing the results as identifying plausible new risk mechanisms that merit further study in more realistic environments. We will also moderate the abstract and conclusion wording to avoid over-extrapolation while preserving the emphasis on endogenous instability in heterogeneous LLM populations. revision: yes
Circularity Check
No significant circularity: purely empirical LLM simulation study
full rationale
The paper reports outcomes from running heterogeneous LLM agents in an abstracted asset market simulation. No mathematical derivations, fitted parameters, or first-principles claims appear that reduce reported results to input definitions by construction. Behaviors (bubbles, adaptation, volatility) emerge from prompt-driven agent interactions rather than from any self-referential fitting or renaming of known patterns. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify core results. The study is self-contained as an empirical exploration whose outputs are generated rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ariel Flint Ashery, Luca Maria Aiello, and Andrea Baronchelli
Accessed: 2026-03-05. Ariel Flint Ashery, Luca Maria Aiello, and Andrea Baronchelli. Emergent social conventions and collective bias in llm populations.Science Advances, 11(20):eadu9368, 2025. Jean-Philippe Bouchaud. The self-organized criticality paradigm in economics & finance. In Jenna Bednar, Eric Beinhocker, R. Maria del Rio-Chanona, J. Doyne Farmer,...
2026
-
[2]
doi: 10.37911/eecs.2025.09. William A Brock and Cars H Hommes. Heterogeneous beliefs and routes to chaos in a simple asset pricing model.Journal of Economic dynamics and Control, 22(8-9):1235–1274, 1998. Philip Brookins and Jason Matthew DeBacker. Playing games with gpt: What can we learn about a large language model from canonical strategic games?Availab...
-
[3]
reasoning
and three lengths of time (3, 5, 7), giving 15 classifications. ForPmean bubble, we consider four thresholds (90, 120, 150, 180). For each experimental run, this gives us 19 classifications. We then compute Cohen’s kappa between each classification pair to measure agreement between the measures. Cohen’s kappa ranges from -1 to 1, with higher values signal...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.