Recognition: unknown
Handling and Interpreting Missing Modalities in Patient Clinical Trajectories via Autoregressive Sequence Modeling
Pith reviewed 2026-05-10 05:45 UTC · model grok-4.3
The pith
Autoregressive sequence modeling with missingness-aware contrastive pre-training allows transformers to outperform baselines on clinical tasks despite missing modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
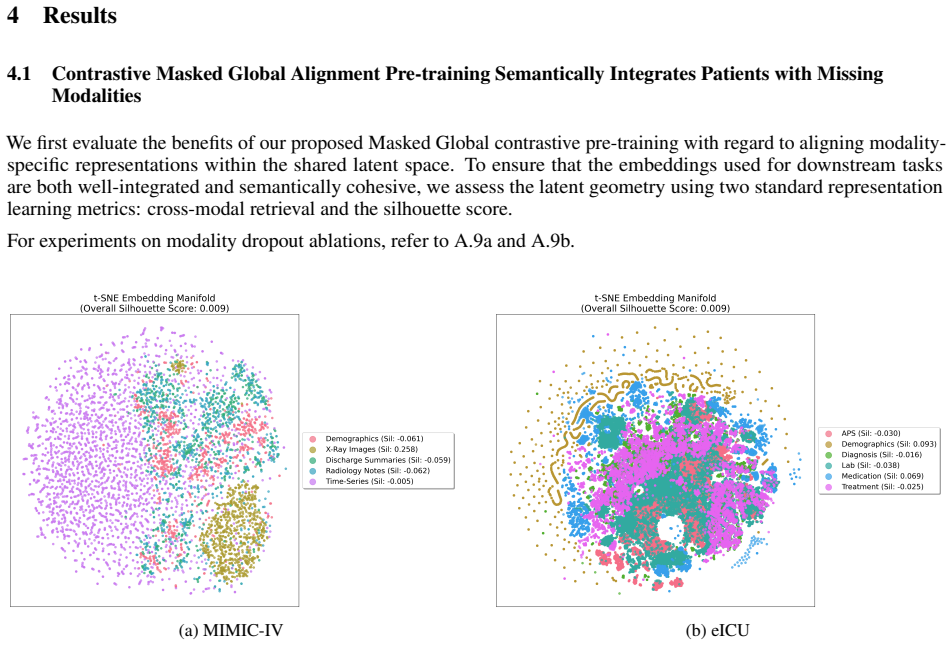
By abstracting clinical diagnosis as sequence modeling and interpreting patient stay trajectories, the authors develop a framework to profile and handle missing modalities. Autoregressive sequence modeling with transformer-based architectures outperforms baselines, and the contrastive pre-training prevents loss of predictive power when data types are absent during both pre-training and fine-tuning.
What carries the argument
The missingness-aware contrastive pre-training objective that integrates multiple modalities in datasets with missingness into a shared latent space for subsequent autoregressive fine-tuning.
If this is right
- The autoregressive models achieve better results than prior methods on standard clinical benchmarks with missing data.
- Removing individual modalities leads to less divergent model behavior thanks to the shared representation.
- Interpretability tools can reveal how each modality contributes across different patient trajectories.
- The framework directly supports the goal of safe and transparent clinical artificial intelligence.
Where Pith is reading between the lines
- The sequence modeling view could extend to other domains with temporal sparse multimodal data such as sensor networks or environmental monitoring.
- Clinicians might use the interpretability outputs to decide which additional tests would most improve a prediction for a specific patient.
- The method implies that pre-training on large but incomplete datasets can create representations robust to future missingness patterns not seen in fine-tuning.
Load-bearing premise
The missingness-aware contrastive pre-training objective successfully integrates multiple modalities into a shared latent space without introducing new biases or losing predictive signal when modalities are absent during both pre-training and fine-tuning.
What would settle it
If a new clinical dataset with unseen missingness patterns shows no performance gain or increased sensitivity to missing modalities after applying the pre-training, the central claim would be falsified.
Figures




read the original abstract
An active challenge in developing multimodal machine learning (ML) models for healthcare is handling missing modalities during training and deployment. As clinical datasets are inherently temporal and sparse in terms of modality presence, capturing the underlying predictive signal via diagnostic multimodal ML models while retaining model explainability remains an ongoing challenge. In this work, we address this by re-framing clinical diagnosis as an autoregressive sequence modeling task, utilizing causal decoders from large language models (LLMs) to model a patient's multimodal trajectory. We first introduce a missingness-aware contrastive pre-training objective that integrates multiple modalities in datasets with missingness in a shared latent space. We then show that autoregressive sequence modeling with transformer-based architectures outperforms baselines on the MIMIC-IV and eICU fine-tuning benchmarks. Finally, we use interpretability techniques to move beyond performance boosts and find that across various patient stays, removing modalities leads to divergent behavior that our contrastive pre-training mitigates. By abstracting clinical diagnosis as sequence modeling and interpreting patient stay trajectories, we develop a framework to profile and handle missing modalities while addressing the canonical desideratum of safe, transparent clinical AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reframes clinical diagnosis as an autoregressive sequence modeling task using causal decoder transformers from LLMs to model patients' multimodal clinical trajectories. It introduces a missingness-aware contrastive pre-training objective to integrate multiple modalities despite missingness into a shared latent space. The authors report that autoregressive modeling with this approach outperforms baselines on the MIMIC-IV and eICU fine-tuning benchmarks, and use interpretability techniques to show that removing modalities leads to divergent behavior which the contrastive pre-training mitigates.
Significance. If the empirical results hold under rigorous controls, the work could meaningfully advance multimodal ML for healthcare by offering a unified framework for temporal sequence modeling, missing-data robustness via contrastive pre-training, and post-hoc interpretability. This directly targets the practical challenge of sparse, incomplete clinical datasets while emphasizing transparency, which aligns with needs for safe clinical AI.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of outperformance on MIMIC-IV and eICU benchmarks is stated without any quantitative metrics (e.g., AUROC, F1, or accuracy deltas), ablation results, details on missingness simulation or masking strategy during evaluation, or statistical tests. These elements are load-bearing for validating the empirical superiority and the mitigation of divergent behavior.
- [§3] §3 (Methods, pre-training objective): The missingness-aware contrastive loss is asserted to integrate modalities into a shared latent space without new biases or loss of signal when modalities are absent at both pre-training and fine-tuning stages, but no explicit formulation, hyperparameter sensitivity analysis, or controlled ablation isolating this effect is referenced. This assumption underpins the interpretability findings and requires concrete verification.
minor comments (2)
- The abstract and introduction use several acronyms (MIMIC-IV, eICU, LLM) without initial definitions; add these on first use for clarity.
- Figure captions and interpretability visualizations should explicitly state the patient cohort size, number of stays analyzed, and which modalities were removed in the divergent-behavior experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for strengthening the empirical claims and methodological transparency, and we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of outperformance on MIMIC-IV and eICU benchmarks is stated without any quantitative metrics (e.g., AUROC, F1, or accuracy deltas), ablation results, details on missingness simulation or masking strategy during evaluation, or statistical tests. These elements are load-bearing for validating the empirical superiority and the mitigation of divergent behavior.
Authors: We agree that the abstract and experimental section require explicit quantitative support. In the revised manuscript, we have updated the abstract to report specific performance metrics including AUROC, F1, and accuracy deltas on both MIMIC-IV and eICU benchmarks relative to baselines. Section 4 has been expanded with full ablation tables, precise descriptions of the missingness simulation and masking protocols applied during evaluation, and statistical significance testing (e.g., paired t-tests with p-values) confirming the reported outperformance and the reduction in divergent behavior after contrastive pre-training. revision: yes
-
Referee: [§3] §3 (Methods, pre-training objective): The missingness-aware contrastive loss is asserted to integrate modalities into a shared latent space without new biases or loss of signal when modalities are absent at both pre-training and fine-tuning stages, but no explicit formulation, hyperparameter sensitivity analysis, or controlled ablation isolating this effect is referenced. This assumption underpins the interpretability findings and requires concrete verification.
Authors: We appreciate the referee's emphasis on rigor here. The revised §3 now includes the complete mathematical formulation of the missingness-aware contrastive pre-training objective. We have added a hyperparameter sensitivity analysis across key values (temperature, weighting factors) and a controlled ablation that isolates the contrastive term, demonstrating its role in aligning modalities into a shared latent space while preserving predictive signal and avoiding introduction of new biases when modalities are absent during both pre-training and fine-tuning. These results directly corroborate the interpretability observations. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core contributions consist of reframing clinical trajectories as autoregressive sequence modeling with a novel missingness-aware contrastive pre-training objective, followed by empirical validation on MIMIC-IV and eICU benchmarks plus interpretability analysis. No equations, derivations, or fitted parameters are described that reduce to their own inputs by construction, nor are any uniqueness theorems or ansatzes imported via self-citation in a load-bearing way. The claims of outperformance and mitigation of divergent behavior rest on external benchmark results and implementation details rather than self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Patient clinical data can be usefully represented as a temporal sequence of multimodal events that admits autoregressive modeling.
Reference graph
Works this paper leans on
-
[1]
Michael Poette, Sandrine Mouysset, Daniel Ruiz, Vincent Pey, Jean-Marc Alliot, and Vincent Minville
doi: 10.3233/SHTI240726. Michael Poette, Sandrine Mouysset, Daniel Ruiz, Vincent Pey, Jean-Marc Alliot, and Vincent Minville. Benchmarking imputation strategies for missing time-series data in critical care using real-world-inspired scenarios.Scientific Reports, 16(1):8116,
-
[2]
doi: 10.1038/s41598-026-39035-z
ISSN 2045-2322. doi: 10.1038/s41598-026-39035-z. URL https://doi.org/10. 1038/s41598-026-39035-z. Kwanhyung Lee, Soojeong Lee, Sangchul Hahn, et al. Learning missing modal electronic health records with unified multi-modal data embedding and modality-aware attention,
-
[3]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N
URLhttps://arxiv.org/abs/2305.02504. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need,
-
[4]
URLhttps://arxiv.org/abs/1706.03762. Alistair E. W. Johnson, Lucas Bulgarelli, Lu Shen, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific Data, 10, 1
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
MIMIC-IV , a freely accessible electronic health record dataset,
doi: 10.1038/s41597-022-01899-x. URL http://dx.doi.org/10.1038/ s41597-022-01899-x. Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, et al. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific Data, 6,
-
[6]
ISSN 2052-4463. doi: 10.1038/sdata.2018.178. URLhttps://doi.org/10.1038/sdata.2018.178. Husam Abuhamad, Suhaila Zainudin, and Azuraliza Abu Bakar. Integrative multimodal hybrid data fusion for mortality prediction.Scientific Reports, 16(1):5803, jan
-
[7]
URL https: //doi.org/10.1038/s41598-026-36296-6
doi: 10.1038/s41598-026-36296-6. URL https: //doi.org/10.1038/s41598-026-36296-6. Binesh Sadanandan. Multimodal deep learning for early prediction of patient deterioration in the icu: Integrating time-series ehr data with clinical notes,
-
[8]
Yi Zheng, Fei Zhao, Xiaohua Liu, et al
URLhttps://arxiv.org/abs/2603.14719. Yi Zheng, Fei Zhao, Xiaohua Liu, et al. A multimodal deep learning framework for predicting cardiovascular deterioration based on mimic-iv dataset. InProceedings of the 2025 6th International Symposium on Artificial Intelligence for Medical Sciences, page 837–842,
-
[9]
URL https://doi.org/ 10.1145/3777577.3777712
doi: 10.1145/3777577.3777712. URL https://doi.org/ 10.1145/3777577.3777712. Wanyi Chen, Zihua Zhao, Jiangchao Yao, et al. Multi-modal medical diagnosis via large-small model collaboration. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 30763–30773,
-
[10]
doi: 10.1109/CVPR52734.2025.02865. Jiaxi Lin, Jin Yang, Minyue Yin, et al. Development and validation of multimodal models to predict the 30-day mortality of icu patients based on clinical parameters and chest x-rays.Journal of Imaging Informatics in Medicine, 37(4): 1312–1322,
-
[11]
URL https://doi.org/10.1007/s10278-024-01066-1
doi: 10.1007/s10278-024-01066-1. URL https://doi.org/10.1007/s10278-024-01066-1 . Xiaoguang Zhu, Lianlong Sun, Yang Liu, et al. Causal debiasing medical multimodal representation learning with missing modalities,
-
[12]
Andrew Wang, Jiashuo Zhang, and Michael Oberst
URLhttps://arxiv.org/abs/2509.05615. Andrew Wang, Jiashuo Zhang, and Michael Oberst. Revisiting performance claims for chest x-ray models using clinical context,
-
[13]
Seyedmostafa Sheikhalishahi, Vevake Balaraman, and Venet Osmani
URLhttps://arxiv.org/abs/2509.19671. Seyedmostafa Sheikhalishahi, Vevake Balaraman, and Venet Osmani. Benchmarking machine learning models on multi-centre eicu critical care dataset.PLOS ONE, 15(7):e0235424, July
-
[14]
URLhttp://dx.doi.org/10.1371/journal.pone.0235424
doi: 10.1371/journal.pone.0235424. URLhttp://dx.doi.org/10.1371/journal.pone.0235424. Chutong Wang, Xuebing Yang, Mengxuan Sun, et al. Multimodal fusion network for icu patient outcome prediction. Neural Networks, 180:106672,
-
[15]
doi: https://doi.org/10.1016/j.neunet.2024.106672. URL https://www. sciencedirect.com/science/article/pii/S0893608024005963. Jingyi Wu, Yu Lin, Pengfei Li, et al. Predicting prolonged length of icu stay through machine learning.Diagnostics, 11 (12),
-
[16]
URLhttps://www.mdpi.com/2075-4418/11/12/2242
doi: 10.3390/diagnostics11122242. URLhttps://www.mdpi.com/2075-4418/11/12/2242. Emma Rocheteau, Pietro Liò, and Stephanie Hyland. Temporal pointwise convolutional networks for length of stay prediction in the intensive care unit. InProceedings of the Conference on Health, Inference, and Learning, page 58–68, April
-
[17]
URLhttp://dx.doi.org/10.1145/3450439.3451860
doi: 10.1145/3450439.3451860. URLhttp://dx.doi.org/10.1145/3450439.3451860. 13 Xiaoyang Wang and Christopher C. Yang. Moe-health: A mixture of experts framework for robust multimodal healthcare prediction,
-
[18]
Jinghui Liu, Daniel Capurro, Anthony Nguyen, and Karin Verspoor
URLhttps://arxiv.org/abs/2508.21793. Jinghui Liu, Daniel Capurro, Anthony Nguyen, and Karin Verspoor. Attention-based multimodal fusion with contrast for robust clinical prediction in the face of missing modalities.Journal of Biomedical Informatics, 145:104466,
-
[19]
Malte Tölle, Mohamad Scharaf, Samantha Fischer, et al
doi: https://doi.org/10.1016/j.jbi.2023.104466. Malte Tölle, Mohamad Scharaf, Samantha Fischer, et al. Arbitrary data as images: Fusion of patient data across modalities and irregular intervals with vision transformers,
-
[20]
Wenfang Yao, Kejing Yin, William K
URLhttps://arxiv.org/abs/2501.18237. Wenfang Yao, Kejing Yin, William K. Cheung, et al. Drfuse: Learning disentangled representation for clinical multi- modal fusion with missing modality and modal inconsistency.Proceedings of the AAAI Conference on Artificial Intelligence, 38(15):16416–16424, Mar
-
[21]
URL https://ojs.aaai.org/ index.php/AAAI/article/view/29578
doi: 10.1609/aaai.v38i15.29578. URL https://ojs.aaai.org/ index.php/AAAI/article/view/29578. Linxiao Gong, Yang Liu, Lianlong Sun, et al. Embracing aleatoric uncertainty in medical multimodal learning with missing modalities,
-
[22]
Jack Geraghty, Andrew Hines, and Fatemeh Golpayegani
URLhttps://arxiv.org/abs/2601.21950. Jack Geraghty, Andrew Hines, and Fatemeh Golpayegani. Learning to associate: Multimodal inference with fully missing modalities.ACM Trans. Intell. Syst. Technol., 16(5),
-
[23]
doi: 10.1145/3746456. URL https://doi. org/10.1145/3746456. Julie Mordacq, Leo Milecki, Maria Vakalopoulou, et al. Adapt: Multimodal learning for detecting physiological changes under missing modalities. InProceedings of The 7nd International Conference on Medical Imaging with Deep Learning, volume 250 ofProceedings of Machine Learning Research, pages 1040–1055,
-
[24]
Vision transformers are parameter- efficient audio-visual learners
URLhttps://arxiv.org/abs/2507.19264. Hu Wang, Yuanhong Chen, Congbo Ma, et al. Multi-modal learning with missing modality via shared-specific feature modelling. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15878–15887, 2023a. doi: 10.1109/CVPR52729.2023.01524. Muyu Wang, Shiyu Fan, Yichen Li, and Hui Chen. Missing-mo...
-
[25]
Pawel Renc, Yugang Jia, Anthony E
URL https: //arxiv.org/abs/2402.17501. Pawel Renc, Yugang Jia, Anthony E. Samir, et al. Zero shot health trajectory prediction using transformer.npj Digital Medicine, 7(1):256,
-
[26]
npj Digital Medicine7(1), 256 (2024) https://doi.org/10.1038/s41746-024-01235-0
doi: 10.1038/s41746-024-01235-0. URL https://doi.org/10.1038/ s41746-024-01235-0. Alban Bornet, Dimitrios Proios, Anthony Yazdani, et al. Comparing neural language models for medical concept representation and patient trajectory prediction.medRxiv,
-
[27]
URL https: //www.medrxiv.org/content/early/2024/10/22/2023.06.01.23290824
doi: 10.1101/2023.06.01.23290824. URL https: //www.medrxiv.org/content/early/2024/10/22/2023.06.01.23290824. Yikuan Li, Mohammad Mamouei, Gholamreza Salimi-Khorshidi, et al. Hi-behrt: Hierarchical transformer-based model for accurate prediction of clinical events using multimodal longitudinal electronic health records.IEEE Journal of Biomedical and Health...
-
[28]
Michael Wornow, Suhana Bedi, Miguel Angel Fuentes Hernandez, et al
doi: 10.1109/JBHI.2022.3224727. Michael Wornow, Suhana Bedi, Miguel Angel Fuentes Hernandez, et al. Context clues: Evaluating long context models for clinical prediction tasks on ehrs,
-
[29]
URLhttps://arxiv.org/abs/2412.16178. Yingfang She, Liemin Zhou, and Yide Li. Interpretable machine learning models for predicting 90-day death in pa- tients in the intensive care unit with epilepsy.Seizure: European Journal of Epilepsy, 114:23–32,
-
[30]
URL https://www.sciencedirect.com/science/article/ pii/S1059131123003047
doi: https://doi.org/10.1016/j.seizure.2023.11.017. URL https://www.sciencedirect.com/science/article/ pii/S1059131123003047. Luis R. Soenksen, Yu Ma, Cynthia Zeng, et al. Integrated multimodal artificial intelligence framework for healthcare applications.npj Digital Medicine, 5(1):149,
-
[31]
URL https://doi.org/ 10.1038/s41746-022-00689-4
doi: 10.1038/s41746-022-00689-4. URL https://doi.org/ 10.1038/s41746-022-00689-4. Parvati Naliyatthaliyazchayil, Raajitha Muthyala, Judy Wawira Gichoya, et al. Evaluating the reasoning capabilities of large language models for medical coding and hospital readmission risk stratification: Zero-shot prompting approach. J Med Internet Res, 27:e74142,
-
[32]
URLhttps://doi.org/10.2196/74142
doi: 10.2196/74142. URLhttps://doi.org/10.2196/74142. Yusheng Liao, Chaoyi Wu, Junwei Liu, et al. Ehr-r1: A reasoning-enhanced foundational language model for electronic health record analysis,
-
[33]
URLhttps://arxiv.org/abs/2510.25628. 14 Pengcheng Qiu, Chaoyi Wu, Shuyu Liu, et al. Quantifying the reasoning abilities of llms on clinical cases.Nature Communications, 16(1):9799, nov
-
[34]
URL https://doi.org/10.1038/ s41467-025-64769-1
doi: 10.1038/s41467-025-64769-1. URL https://doi.org/10.1038/ s41467-025-64769-1. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations,
-
[35]
A Simple Framework for Contrastive Learning of Visual Representations
URLhttps://arxiv.org/abs/2002.05709. Rahul Thapa, Magnus Ruud Kjaer, Bryan He, Ian Covert, Hyatt Moore IV , Umaer Hanif, Gauri Ganjoo, M. Bran- don Westover, Poul Jennum, Andreas Brink-Kjaer, Emmanuel Mignot, and James Zou. A multimodal sleep foundation model for disease prediction.Nature Medicine, 32(2):752–762,
work page internal anchor Pith review arXiv 2002
-
[36]
doi: 10.1038/s41591-025-04133-4
ISSN 1546-170X. doi: 10.1038/s41591-025-04133-4. URLhttps://doi.org/10.1038/s41591-025-04133-4. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models,
-
[37]
URL https: //arxiv.org/abs/2407.21783. Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, et al. Mistral 7b,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
URL https://arxiv.org/abs/ 2310.06825. DeepSeek-AI, Xiao Bi, Deli Chen, et al. Deepseek llm: Scaling open-source language models with longtermism,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
URLhttps://arxiv.org/abs/2401.02954. Marah Abdin, Jyoti Aneja, Hany Awadalla, et al. Phi-3 technical report: A highly capable language model locally on your phone,
work page internal anchor Pith review arXiv
-
[40]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
URLhttps://arxiv.org/abs/2404.14219. Yanis Labrak, Adrien Bazoge, Emmanuel Morin, et al. Biomistral: A collection of open-source pretrained large language models for medical domains,
work page internal anchor Pith review arXiv
-
[41]
arXiv preprint arXiv:2402.10373 (2024)
URLhttps://arxiv.org/abs/2402.10373. Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, et al. Meditron-70b: Scaling medical pretraining for large language models,
-
[42]
Meditron-70b: Scaling medical pretraining for large language models,
URLhttps://arxiv.org/abs/2311.16079. Kexin Huang, Jaan Altosaar, and Rajesh Ranganath. Clinicalbert: Modeling clinical notes and predicting hospital readmission,
-
[43]
arXiv preprint arXiv:1904.05342 , year =
URLhttps://arxiv.org/abs/1904.05342. Edward J. Hu, Yelong Shen, Phillip Wallis, et al. Lora: Low-rank adaptation of large language models,
-
[44]
LoRA: Low-Rank Adaptation of Large Language Models
URL https://arxiv.org/abs/2106.09685. 15 A Clinical Dataset Preprocessing A.1 Contrastive Pretraining Data A.1.1 Cohort Selection and Data Linkage MIMIC-IV Cohort:The MIMIC cohort focuses on intensive care unit (ICU) admissions where multimodal data streams intersect. We performed an inner join between the MIMIC-CXR metadata and the MIMIC-IV icustays tabl...
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
to the pre-trained LLMs, injecting trainable decomposition matrices (rank r∈ {8,16} , α∈ {16,32} , dropout ∈ {0.1,0.3} ) into all linear projection layers of the self-attention mechanism ( q_proj, k_proj, v_proj, o_proj ) and the feed-forward network (gate_proj, up_proj, down_proj). B.3 Task-Specific Optimization and Loss Functions All models were optimiz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.