Recognition: unknown
Syntax as a Rosetta Stone: Universal Dependencies for In-Context Coptic Translation
Pith reviewed 2026-05-10 04:49 UTC · model grok-4.3
The pith
Combining dictionary glosses with Universal Dependencies syntax in prompts produces new state-of-the-art Coptic-to-English translations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
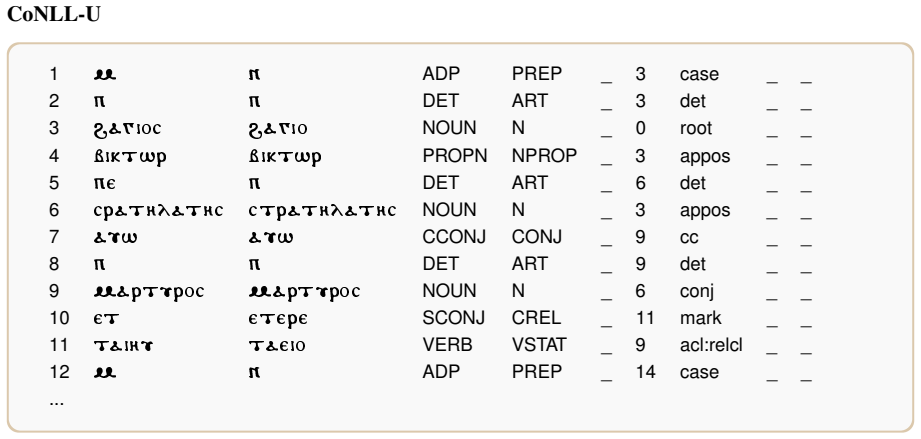
Augmenting in-context learning prompts with representations of Universal Dependencies parses—such as raw outputs, plain English verbalizations, and targeted instructions for difficult constructions—combined with retrieved bilingual dictionary items leads to significant gains in translation quality for Coptic to English, outperforming dictionary-only or syntax-only baselines and establishing new state-of-the-art results across various model sizes.
What carries the argument
syntactic augmentation of in-context prompts using Universal Dependencies parses in multiple formats, combined with bilingual dictionary glosses
If this is right
- Dictionary-based glosses alone outperform syntactic information alone in improving translation quality.
- Combining both sources of information produces additive gains not seen with either in isolation.
- The benefits of this combined approach hold across different sizes of underlying language models.
- Targeted instructions about specific syntactic constructions in the parses can be included to guide translation of difficult cases.
Where Pith is reading between the lines
- This approach may extend to other low-resource languages that have Universal Dependencies treebanks available.
- Future work could test whether similar syntactic augmentations help in other generation tasks beyond translation, such as summarization or question answering in low-resource settings.
- The method suggests that explicit linguistic structure can complement lexical knowledge in prompt engineering for historical or endangered languages.
- Developers of translation tools for Coptic might integrate UD parsers directly into their prompting pipelines to boost performance.
Load-bearing premise
The gains observed are due to the syntactic information provided rather than incidental factors like increased prompt length or differences in how examples are chosen.
What would settle it
Re-running the experiments with prompts of exactly matched length and identical example selection but with the syntactic augmentation removed or replaced by neutral text, and observing no drop in translation metrics.
Figures



read the original abstract
Low-resource machine translation requires methods that differ from those used for high-resource languages. This paper proposes a novel in-context learning approach to support low-resource machine translation of the Coptic language to English, with syntactic augmentation from Universal Dependencies parses of input sentences. Building on existing work using bilingual dictionaries to support inference for vocabulary items, we add several representations of syntactic analyses to our inputs , specifically exploring the inclusion of raw parser outputs, verbalizations of parses in plain English, and targeted instructions of difficult constructions identified in sub-trees and how they can be translated. Our results show that while syntactic information alone is not as useful as dictionary-based glosses, combining retrieved dictionary items with syntactic information achieves significant gains across model sizes, achieving new state-of-the-art translation results for Coptic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an in-context learning approach for Coptic-to-English machine translation that augments prompts with syntactic information from Universal Dependencies parses (raw outputs, English verbalizations, or targeted construction instructions) in addition to bilingual dictionary glosses. It reports that syntactic information alone is less effective than glosses but that the combination produces significant gains across model sizes and new state-of-the-art translation results for Coptic.
Significance. If the reported gains can be isolated to the syntactic content rather than prompt length or retrieval artifacts, the work would demonstrate a practical way to leverage existing UD resources for low-resource translation where parallel data is scarce. The use of multiple syntactic representations and the focus on a genuinely low-resource language with an available treebank are positive aspects.
major comments (3)
- [Experimental Setup / Results] The central claim that syntactic augmentations causally improve translation quality beyond dictionary glosses requires isolation from confounds. The experimental design (likely §4 and §5) does not appear to include length-matched controls or ablations in which syntactic content is replaced by neutral filler text of equal token count while preserving example selection and retrieval protocols. Without these, improvements cannot be attributed to syntax rather than increased context size.
- [Evaluation / Results] The abstract asserts 'significant gains' and 'new state-of-the-art' results, yet the evaluation section provides insufficient detail on the precise metrics (e.g., BLEU, chrF, COMET), the size and composition of test sets, the exact baselines compared, and any statistical significance testing. This information is load-bearing for the SOTA claim.
- [Method] The paper does not specify a fixed example-selection protocol or retrieval method for the in-context examples. If example selection varies with the addition of syntactic material, this introduces an uncontrolled variable that could explain the observed differences.
minor comments (2)
- [Abstract] The abstract would benefit from a brief parenthetical mention of the primary automatic metric(s) used to support the 'significant gains' claim.
- [Method] Notation for the different syntactic representations (raw UD, verbalized, targeted) should be introduced once and used consistently in tables and figures.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help us strengthen the paper's claims regarding the role of syntactic information in in-context learning for Coptic translation. We address each major comment in turn and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experimental Setup / Results] The central claim that syntactic augmentations causally improve translation quality beyond dictionary glosses requires isolation from confounds. The experimental design (likely §4 and §5) does not appear to include length-matched controls or ablations in which syntactic content is replaced by neutral filler text of equal token count while preserving example selection and retrieval protocols. Without these, improvements cannot be attributed to syntax rather than increased context size.
Authors: We agree that the current experimental design does not fully isolate the effect of syntactic content from potential confounds such as increased prompt length. To address this, we will add new ablation studies in the revised manuscript. These will include conditions where syntactic information is replaced by neutral filler text of equivalent token length, while maintaining the same example selection and retrieval protocols. This will help confirm whether the gains are due to the syntactic augmentations specifically. revision: yes
-
Referee: [Evaluation / Results] The abstract asserts 'significant gains' and 'new state-of-the-art' results, yet the evaluation section provides insufficient detail on the precise metrics (e.g., BLEU, chrF, COMET), the size and composition of test sets, the exact baselines compared, and any statistical significance testing. This information is load-bearing for the SOTA claim.
Authors: We will revise the evaluation section to provide comprehensive details on the metrics employed, including BLEU, chrF, and COMET. We will also specify the size and composition of the test sets, list the exact baselines used for comparison, and include statistical significance testing to substantiate the reported gains and state-of-the-art results. revision: yes
-
Referee: [Method] The paper does not specify a fixed example-selection protocol or retrieval method for the in-context examples. If example selection varies with the addition of syntactic material, this introduces an uncontrolled variable that could explain the observed differences.
Authors: We will explicitly describe the example-selection protocol in the methods section of the revised paper. The retrieval method is based on semantic similarity of the input sentences and is fixed across all conditions; syntactic information is added after example selection to ensure it does not affect the choice of in-context examples. revision: yes
Circularity Check
No circularity: straightforward empirical prompting comparison
full rationale
The paper reports experimental results on in-context learning for Coptic-English translation, comparing dictionary glosses alone versus dictionary plus various syntactic augmentations (raw UD parses, English verbalizations, targeted instructions). All claims rest on measured BLEU/CHRF scores and human evaluations against external test sets. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear; the central result is an empirical delta between prompting conditions. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RAG -Enhanced Neural Machine Translation of A ncient E gyptian Text: A Case Study of THOTH AI
Miyagawa, So. RAG -Enhanced Neural Machine Translation of A ncient E gyptian Text: A Case Study of THOTH AI. Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities. 2025. doi:10.18653/v1/2025.nlp4dh-1.4
-
[2]
From N ile Sands to Digital Hands: Machine Translation of C optic Texts
Saeed, Muhammed and Mohamed, Asim and Mohamed, Mukhtar and Shehata, Shady and Abdul-Mageed, Muhammad. From N ile Sands to Digital Hands: Machine Translation of C optic Texts. Proceedings of the Second Arabic Natural Language Processing Conference. 2024. doi:10.18653/v1/2024.arabicnlp-1.25
-
[3]
Assessing Large Language Models in Translating C optic and A ncient G reek Ostraca
Wannaz, Audric-Charles and Miyagawa, So. Assessing Large Language Models in Translating C optic and A ncient G reek Ostraca. Proceedings of the 4th International Conference on Natural Language Processing for Digital Humanities. 2024. doi:10.18653/v1/2024.nlp4dh-1.44
-
[4]
Neural Machine Translation for
Nasma Chaoui and Richard Khoury , year=. Neural Machine Translation for. 2508.10683 , archivePrefix=
work page internal anchor Pith review arXiv
-
[5]
Manning, Joakim Nivre, and Daniel Zeman
de Marneffe, Marie-Catherine and Manning, Christopher D. and Nivre, Joakim and Zeman, Daniel. U niversal D ependencies. Computational Linguistics. 2021. doi:10.1162/coli_a_00402
-
[6]
Schroeder and Amir Zeldes , title =
Caroline T. Schroeder and Amir Zeldes , title =. Digital Humanities Quarterly , year =
-
[7]
The C optic U niversal D ependency Treebank
Zeldes, Amir and Abrams, Mitchell. The C optic U niversal D ependency Treebank. Proceedings of the Second Workshop on Universal Dependencies ( UDW 2018). 2018. doi:10.18653/v1/W18-6022
-
[8]
and Zeldes, Amir
Feder, Frank and Kupreyev, Maxim and Manning, Emma and Schroeder, Caroline T. and Zeldes, Amir. A Linked C optic Dictionary Online. Proceedings of the Second Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature. 2018
2018
-
[9]
Kocmi, Tom and Agrawal, Sweta and Artemova, Ekaterina and Avramidis, Eleftherios and Briakou, Eleftheria and Chen, Pinzhen and Fadaee, Marzieh and Freitag, Markus and Grundkiewicz, Roman and Hou, Yupeng and Koehn, Philipp and Kreutzer, Julia and Mansour, Saab and Perrella, Stefano and Proietti, Lorenzo and Riley, Parker and S \'a nchez, Eduardo and Schmid...
-
[10]
Kocmi, Tom and Artemova, Ekaterina and Avramidis, Eleftherios and Bawden, Rachel and Bojar, Ond r ej and Dranch, Konstantin and Dvorkovich, Anton and Dukanov, Sergey and Fishel, Mark and Freitag, Markus and Gowda, Thamme and Grundkiewicz, Roman and Haddow, Barry and Karpinska, Marzena and Koehn, Philipp and Lakougna, Howard and Lundin, Jessica and Monz, C...
-
[11]
T ree S wap: Data Augmentation for Machine Translation via Dependency Subtree Swapping
Nagy, Attila and Lakatos, Dorina and Barta, Botond and \'A cs, Judit. T ree S wap: Data Augmentation for Machine Translation via Dependency Subtree Swapping. Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing. 2023
2023
-
[12]
Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on M anchu
Pei, Renhao and Liu, Yihong and Lin, Peiqin and Yvon, Fran c ois and Schuetze, Hinrich. Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on M anchu. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.429
-
[13]
All Roads Lead to UD : Converting S tanford and P enn Parses to E nglish U niversal D ependencies with Multilayer Annotations
Peng, Siyao and Zeldes, Amir. All Roads Lead to UD : Converting S tanford and P enn Parses to E nglish U niversal D ependencies with Multilayer Annotations. Proceedings of the Joint Workshop on Linguistic Annotation, Multiword Expressions and Constructions ( LAW - MWE - C x G -2018). 2018
2018
-
[14]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[15]
Lavie, Alon and Hanneman, Greg and Agrawal, Sweta and Kanojia, Diptesh and Lo, Chi-Kiu and Zouhar, Vil \'e m and Blain, Frederic and Zerva, Chrysoula and Avramidis, Eleftherios and Deoghare, Sourabh and Sindhujan, Archchana and Wang, Jiayi and Adelani, David Ifeoluwa and Thompson, Brian and Kocmi, Tom and Freitag, Markus and Deutsch, Daniel. Findings of t...
-
[16]
Zeldes, Amir and Schroeder, Caroline T. An NLP Pipeline for C optic. Proceedings of the 10th SIGHUM Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities. 2016. doi:10.18653/v1/W16-2119
-
[17]
Chain-of-Dictionary Prompting Elicits Translation in Large Language Models
Lu, Hongyuan and Yang, Haoran and Huang, Haoyang and Zhang, Dongdong and Lam, Wai and Wei, Furu. Chain-of-Dictionary Prompting Elicits Translation in Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.55
-
[18]
2023 , eprint=
Dictionary-based Phrase-level Prompting of Large Language Models for Machine Translation , author=. 2023 , eprint=
2023
-
[19]
Translating a low-resource language using GPT -3 and a human-readable dictionary
Elsner, Micha and Needle, Jordan. Translating a low-resource language using GPT -3 and a human-readable dictionary. Proceedings of the 20th SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morphology. 2023. doi:10.18653/v1/2023.sigmorphon-1.2
-
[20]
Shortcomings of LLM s for Low-Resource Translation: Retrieval and Understanding Are Both the Problem
Court, Sara and Elsner, Micha. Shortcomings of LLM s for Low-Resource Translation: Retrieval and Understanding Are Both the Problem. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.125
-
[21]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , publisher =. doi:10.1162/tacl_a_00638 , url =
-
[22]
The Twelfth International Conference on Learning Representations , url =
A Benchmark for Learning to Translate a New Language from One Grammar Book , author =. The Twelfth International Conference on Learning Representations , url =
-
[23]
Read it in Two Steps: Translating Extremely Low-Resource Languages with Code-Augmented Grammar Books
Zhang, Chen and Lin, Jiuheng and Liu, Xiao and Zhang, Zekai and Feng, Yansong. Read it in Two Steps: Translating Extremely Low-Resource Languages with Code-Augmented Grammar Books. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.202
-
[24]
How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models
Rust, Phillip and Pfeiffer, Jonas and Vuli \'c , Ivan and Ruder, Sebastian and Gurevych, Iryna. How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volum...
-
[25]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[27]
From Priest to Doctor: Domain Adaptation for Low-Resource Neural Machine Translation
Marashian, Ali and Rice, Enora and Gessler, Luke and Palmer, Alexis and von der Wense, Katharina. From Priest to Doctor: Domain Adaptation for Low-Resource Neural Machine Translation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[28]
B leu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[29]
chr F ++: words helping character n-grams
Popovi \'c , Maja. chr F ++: words helping character n-grams. Proceedings of the Second Conference on Machine Translation. 2017. doi:10.18653/v1/W17-4770
-
[30]
chr F - S : Semantics Is All You Need
Mukherjee, Ananya and Shrivastava, Manish. chr F - S : Semantics Is All You Need. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.33
-
[31]
METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Banerjee, Satanjeev and Lavie, Alon. METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005
2005
-
[32]
Post, Matt. A Call for Clarity in Reporting BLEU Scores. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018. doi:10.18653/v1/W18-6319
-
[33]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[34]
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.845
-
[35]
The Usefulness of B ibles in Low-Resource Machine Translation
Liu, Ling and Ryan, Zach and Hulden, Mans. The Usefulness of B ibles in Low-Resource Machine Translation. Proceedings of the 4th Workshop on the Use of Computational Methods in the Study of Endangered Languages Volume 1 (Papers). 2021
2021
-
[36]
2020 , url=
Claude 3.5 Sonnet Model Card Addendum , author=. 2020 , url=
2020
-
[37]
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Zhu, Wenhao and Liu, Hongyi and Dong, Qingxiu and Xu, Jingjing and Huang, Shujian and Kong, Lingpeng and Chen, Jiajun and Li, Lei. Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.176
-
[38]
and Meinhardt, Caroline and Badi Uz Zaman, Haifa and Friedman, Toni and Truong, Sang T
Pava, Juan N. and Meinhardt, Caroline and Badi Uz Zaman, Haifa and Friedman, Toni and Truong, Sang T. and Zhang, Daniel and Cryst, Elena and Marivate, Vukosi and Koyejo, Sanmi , year =. Mind the (Language) Gap: Mapping the Challenges of
-
[39]
Compensating for Data with Reasoning: Low-Resource Machine Translation with
Samuel Frontull and Thomas Ströhle , year=. Compensating for Data with Reasoning: Low-Resource Machine Translation with. 2505.22293 , archivePrefix=
-
[40]
and Schroeder, Caroline T
Zeldes, Amir and Speransky, Nina and Wagner, Nicholas E. and Schroeder, Caroline T. A UD Treebank for Bohairic C optic. Proceedings of the Eighth Workshop on Universal Dependencies (UDW, SyntaxFest 2025). 2025
2025
-
[41]
The Making of C optic W ordnet
Slaughter, Laura and Costa, Luis Morgado Da and Miyagawa, So and B. The Making of C optic W ordnet. Proceedings of the 10th Global Wordnet Conference. 2019. doi:10.18653/v1/2019.gwc-1.21
-
[42]
2019-05-12 , howpublished =
Comprehensive Coptic Lexicon: Including Loanwords from Ancient Greek v 1 , author =. 2019-05-12 , howpublished =
2019
-
[43]
A Universal Part-of-Speech Tagset
Petrov, Slav and Das, Dipanjan and McDonald, Ryan. A Universal Part-of-Speech Tagset. Proceedings of the Eighth International Conference on Language Resources and Evaluation ( LREC '12). 2012
2012
-
[44]
Amir Zeldes and Caroline T. Schroeder , title =. Digital Scholarship in the Humanities , year =. doi:10.1093/llc/fqv043 , url =
-
[45]
Designing a Uniform Meaning Representation for Natural Language Processing , author =. K. doi:10.1007/s13218-021-00722-w , url =
-
[46]
Survey of Low-Resource Machine Translation
Haddow, Barry and Bawden, Rachel and Miceli Barone, Antonio Valerio and Helcl, Jind r ich and Birch, Alexandra. Survey of Low-Resource Machine Translation. Computational Linguistics. 2022. doi:10.1162/coli_a_00446
-
[47]
Back to School: Translation Using Grammar Books
Hus, Jonathan and Anastasopoulos, Antonios. Back to School: Translation Using Grammar Books. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1127
-
[48]
and Feder, Frank and John, Katrin and Kupreyev, Maxim , year = 2020, doi =
Burns, Dylan M. and Feder, Frank and John, Katrin and Kupreyev, Maxim , year = 2020, doi =. Comprehensive
2020
-
[49]
Building machine translation systems for the next thousand languages , author =. arXiv preprint arXiv:2205.03983 , doi =
-
[50]
Boosting the Capabilities of Compact Models in Low-Data Contexts with Large Language Models and Retrieval-Augmented Generation
Shandilya, Bhargav and Palmer, Alexis. Boosting the Capabilities of Compact Models in Low-Data Contexts with Large Language Models and Retrieval-Augmented Generation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[51]
Kontaktinduzierter Sprachwandel des
Almond, Mathew and Hagen, Joost and John, Katrin and Richter, Tonio Sebastian and Walter, Vincent , journal=. Kontaktinduzierter Sprachwandel des
-
[52]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.