Recognition: unknown
Structural Verification for Reliable EDA Code Generation without Tool-in-the-Loop Debugging
Pith reviewed 2026-05-10 03:47 UTC · model grok-4.3
The pith
Enforcing structural consistency prior to execution decouples EDA code correctness from repeated tool interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Each task is represented as a structural dependency graph that serves as an explicit execution contract, and a verifier-guided synthesis framework enforces this contract through graph-conditioned retrieval, constrained generation, and staged pre-execution verification with diagnosis-driven repair, eliminating tool-in-the-loop debugging while raising pass rates and reducing total tool calls.
What carries the argument
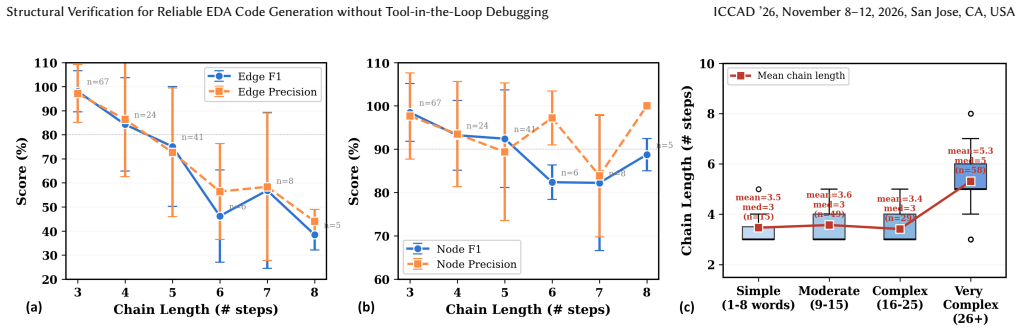
The structural dependency graph, which captures implicit dependencies such as acquisition paths, prerequisites, and API compatibility and serves as the contract enforced before any execution occurs.
If this is right
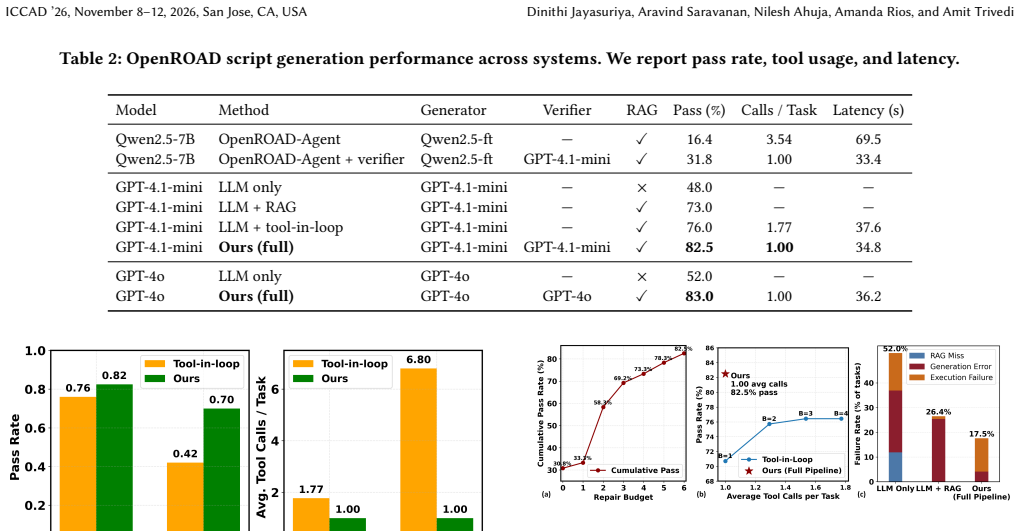
- Single-step tasks reach 82.5 percent pass rate while using exactly one tool call per task.
- Multi-step tasks reach 70 percent pass rate, improving further to 84 percent with trajectory-level reflection.
- Uncertainty-aware filtering reduces verifier false positives from 20 percent to 6.7 percent and raises precision from 80 percent to 93.3 percent.
Where Pith is reading between the lines
- Explicit pre-execution modeling of dependencies may reduce the cost of generating correct programs in other domains that involve chained tool calls or API sequences.
- The efficiency gains suggest that long-horizon automation workflows benefit more from upfront structural contracts than from repeated runtime correction.
- Automating the initial construction of the dependency graph could extend the method to EDA tasks where manual graph specification is impractical.
Load-bearing premise
The structural dependency graph can be constructed to capture all implicit dependencies and failure modes, and the verifier can diagnose and repair issues accurately without runtime execution feedback.
What would settle it
A collection of multi-step EDA tasks on which the generated scripts pass the verifier yet still fail when executed, due to missed dependencies or incorrect repairs, would show the claim does not hold.
Figures



read the original abstract
Large language models (LLMs) have enabled natural-language-driven automation of electronic design automation (EDA) workflows, but reliable execution of generated scripts remains a fundamental challenge. In LLM-based EDA tasks, failures arise not from syntax errors but from violations of implicit structural dependencies over design objects, including invalid acquisition paths, missing prerequisites, and incompatible API usage. Existing approaches address these failures through tool-in-the-loop debugging, repeatedly executing and repairing programs using runtime feedback. While effective, this paradigm couples correctness to repeated tool invocation, leading to high latency and poor scalability in multi-step settings. We propose to eliminate tool-in-the-loop debugging by enforcing structural correctness prior to execution. Each task is represented as a structural dependency graph that serves as an explicit execution contract, and a verifier-guided synthesis framework enforces this contract through graph-conditioned retrieval, constrained generation, and staged pre-execution verification with diagnosis-driven repair. On single-step tasks, our method improves pass rate from 73.0% (LLM+RAG) and 76.0% (tool-in-loop) to 82.5%, while requiring exactly one tool call per task and reducing total tool calls by more than 2x. On multi-step tasks, pass rate improves from 30.0% to 70.0%, and further to 84.0% with trajectory-level reflection. Uncertainty-aware filtering further reduces verifier false positives from 20.0% to 6.7% and improves precision from 80.0% to 93.3%. These results show that enforcing structural consistency prior to execution decouples correctness from tool interaction, improving both reliability and efficiency in long-horizon EDA code generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that representing EDA tasks as structural dependency graphs (as explicit execution contracts) and applying a verifier-guided synthesis framework—via graph-conditioned retrieval, constrained generation, and staged pre-execution verification with diagnosis-driven repair—allows LLMs to generate reliable EDA code without tool-in-the-loop debugging. This decouples correctness from runtime tool interactions, yielding pass-rate gains (single-step: 73% LLM+RAG / 76% tool-in-loop to 82.5%; multi-step: 30% to 70%, or 84% with trajectory-level reflection) and >2x tool-call reduction, plus uncertainty-aware filtering that cuts verifier false positives from 20% to 6.7%.
Significance. If the structural graphs prove exhaustive and the pre-execution verifier accurate without runtime traces, the approach could meaningfully improve scalability and latency for long-horizon LLM-driven EDA automation by eliminating repeated tool feedback loops.
major comments (3)
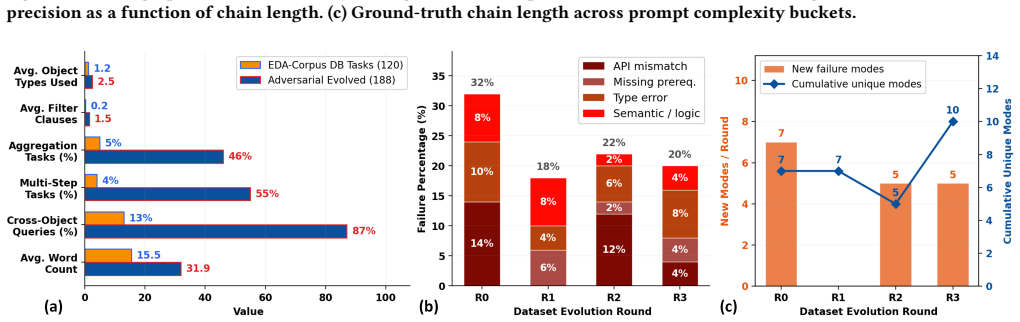
- [Abstract / Methods (graph construction)] The decoupling claim (that pre-execution verification substitutes for runtime tool feedback) is load-bearing on the assumption that the structural dependency graph captures all implicit EDA dependencies (acquisition paths, prerequisites, API compatibility). The manuscript provides no construction procedure, completeness argument, or adversarial evaluation showing the graph is exhaustive for the evaluated task distribution.
- [Abstract / Experimental Results] Reported empirical gains (e.g., single-step pass rate 82.5%, multi-step 70–84%, tool-call reduction >2x) are presented without baseline implementation details, number of trials, statistical significance tests, or error bars, undermining assessment of whether the improvements robustly support the decoupling claim over LLM+RAG and tool-in-loop controls.
- [Abstract / Verifier-guided synthesis] The verifier's diagnosis-driven repair and uncertainty-aware filtering (reducing false positives 20%→6.7%, precision 80%→93.3%) are central, yet the manuscript gives no description of the verifier implementation, how it diagnoses violations using only static analysis, or coverage of failure modes that require execution traces.
minor comments (1)
- [Abstract] The abstract introduces 'trajectory-level reflection' for the 84% multi-step result but does not define the mechanism or its integration with the core graph-verifier pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving the clarity, rigor, and reproducibility of our work on structural verification for EDA code generation. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods (graph construction)] The decoupling claim (that pre-execution verification substitutes for runtime tool feedback) is load-bearing on the assumption that the structural dependency graph captures all implicit EDA dependencies (acquisition paths, prerequisites, API compatibility). The manuscript provides no construction procedure, completeness argument, or adversarial evaluation showing the graph is exhaustive for the evaluated task distribution.
Authors: We agree that the decoupling claim depends on the exhaustiveness of the structural dependency graphs and that the manuscript would benefit from greater explicitness here. In the revised version, we will add a dedicated subsection detailing the graph construction procedure, including systematic extraction of acquisition paths, prerequisites, and API compatibilities from EDA documentation and task specifications. We will also include a completeness argument grounded in the evaluated task distribution and an adversarial evaluation to test for potential missed dependencies. These additions will directly bolster support for the pre-execution verification approach. revision: yes
-
Referee: [Abstract / Experimental Results] Reported empirical gains (e.g., single-step pass rate 82.5%, multi-step 70–84%, tool-call reduction >2x) are presented without baseline implementation details, number of trials, statistical significance tests, or error bars, undermining assessment of whether the improvements robustly support the decoupling claim over LLM+RAG and tool-in-loop controls.
Authors: We concur that additional experimental details are essential for evaluating the robustness of the reported gains. In the revision, we will expand the experimental section to include full baseline implementation details, the exact number of trials per setting, statistical significance tests (such as paired t-tests with p-values), and error bars on all metrics including pass rates and tool-call reductions. This will allow readers to better assess whether the improvements support the decoupling claim. revision: yes
-
Referee: [Abstract / Verifier-guided synthesis] The verifier's diagnosis-driven repair and uncertainty-aware filtering (reducing false positives 20%→6.7%, precision 80%→93.3%) are central, yet the manuscript gives no description of the verifier implementation, how it diagnoses violations using only static analysis, or coverage of failure modes that require execution traces.
Authors: We acknowledge that the verifier implementation requires a more detailed description to fully substantiate its role in pre-execution verification. In the revised manuscript, we will provide an expanded account of the verifier, including the specific static analysis rules for diagnosing structural dependency violations, the diagnosis-driven repair process, and the uncertainty-aware filtering mechanism. We will also discuss the coverage of failure modes addressed by static analysis and note any limitations where runtime traces might still be relevant. These changes will clarify the verifier's capabilities without tool-in-the-loop debugging. revision: yes
Circularity Check
No circularity; empirical results on pass rates and tool-call counts are independent of any internal derivation loop
full rationale
The paper describes a verifier-guided synthesis framework that constructs structural dependency graphs as execution contracts and reports measured improvements in pass rates (73% to 82.5% single-step; 30% to 70-84% multi-step) and tool-call reductions against explicit baselines. No equations, fitted parameters, or first-principles derivations are presented that could reduce to their own inputs by construction. All quantitative claims are experimental outcomes on task distributions, not quantities obtained by renaming or re-using the method's own definitions or self-citations. The central decoupling claim is therefore supported by external measurement rather than tautological internal consistency.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption EDA tasks possess implicit structural dependencies (acquisition paths, prerequisites, API compatibility) that can be explicitly modeled as graphs serving as execution contracts
- ad hoc to paper Pre-execution verification and diagnosis-driven repair can substitute for runtime tool feedback without missing failure modes
invented entities (1)
-
structural dependency graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Software Engineering and Methodology , volume=
A survey on large language models for code generation , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2026 , publisher=
2026
-
[2]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[3]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[4]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[5]
Executable code actions elicit better LLM agents, 2024
Executable code actions elicit better llm agents, 2024 , author=. URL https://arxiv. org/abs/2402.01030 , volume=
-
[6]
International conference on machine learning , pages=
Pal: Program-aided language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[7]
Teaching Large Language Models to Self-Debug
Teaching large language models to self-debug , author=. arXiv preprint arXiv:2304.05128 , year=
work page internal anchor Pith review arXiv
-
[8]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[9]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models, 2023 , author=. URL https://arxiv. org/abs/2305.16291 , volume=
work page internal anchor Pith review arXiv 2023
-
[10]
Chipnemo: Domain- adapted llms for chip design,
Chipnemo: Domain-adapted llms for chip design , author=. arXiv preprint arXiv:2311.00176 , year=
-
[11]
2024 IEEE LLM Aided Design Workshop (LAD) , pages=
Rtlcoder: Outperforming gpt-3.5 in design rtl generation with our open-source dataset and lightweight solution , author=. 2024 IEEE LLM Aided Design Workshop (LAD) , pages=. 2024 , organization=
2024
-
[12]
2024 IEEE LLM Aided Design Workshop (LAD) , pages=
Eda corpus: A large language model dataset for enhanced interaction with openroad , author=. 2024 IEEE LLM Aided Design Workshop (LAD) , pages=. 2024 , organization=
2024
-
[13]
Proceedings of Government Microcircuit Applications and Critical Technology Conference , year=
Openroad: Toward a self-driving, open-source digital layout implementation tool chain , author=. Proceedings of Government Microcircuit Applications and Critical Technology Conference , year=
-
[14]
OpenDB, OpenROAD’s database , author=. Proc. Workshop on Open-Source EDA Technology , year=
-
[15]
Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD , pages=
Openroad-assistant: An open-source large language model for physical design tasks , author=. Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD , pages=
2024
-
[16]
2025 IEEE International Conference on LLM-Aided Design (ICLAD) , pages=
OpenROAD Agent: An Intelligent Self-Correcting Script Generator for OpenROAD , author=. 2025 IEEE International Conference on LLM-Aided Design (ICLAD) , pages=. 2025 , organization=
2025
-
[17]
arXiv preprint arXiv:2410.03845 , year=
ORAssistant: A custom RAG-based conversational assistant for OpenROAD , author=. arXiv preprint arXiv:2410.03845 , year=
-
[18]
ACM SIGPLAN Notices , volume=
Type-and-example-directed program synthesis , author=. ACM SIGPLAN Notices , volume=. 2015 , publisher=
2015
-
[19]
International Conference on Tools and Algorithms for the Construction and Analysis of Systems , pages=
Abstract learning frameworks for synthesis , author=. International Conference on Tools and Algorithms for the Construction and Analysis of Systems , pages=. 2016 , organization=
2016
-
[20]
arXiv preprint arXiv:1807.03100 , year=
Robust text-to-sql generation with execution-guided decoding , author=. arXiv preprint arXiv:1807.03100 , year=
-
[21]
International Conference on Machine Learning , pages=
Lever: Learning to verify language-to-code generation with execution , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[22]
arXiv preprint arXiv:2510.09941 , year=
Causal-Guided Dimension Reduction for Efficient Pareto Optimization , author=. arXiv preprint arXiv:2510.09941 , year=
-
[23]
TRACER : Trajectory risk aggregation for critical episodes in agentic reasoning
TRACER: Trajectory Risk Aggregation for Critical Episodes in Agentic Reasoning , author=. arXiv preprint arXiv:2602.11409 , year=
-
[24]
Calibrated Decomposition of Aleatoric and Epistemic Uncertainty in Deep Features for Inference-Time Adaptation , author=. arXiv preprint arXiv:2511.12389 , year=
-
[25]
Self-play fine-tuning converts weak language models to strong language models , author=. arXiv preprint arXiv:2401.01335 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Self-playing adversarial language game enhances llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Learning to solve and verify: A self-play framework for code and test generation , author=. arXiv preprint arXiv:2502.14948 , year=
-
[28]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[29]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[30]
Advances in neural information processing systems , volume=
Selective classification for deep neural networks , author=. Advances in neural information processing systems , volume=
-
[31]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review arXiv
-
[32]
Information processing & management , volume=
A systematic analysis of performance measures for classification tasks , author=. Information processing & management , volume=. 2009 , publisher=
2009
-
[33]
Transactions of the Association for Computational Linguistics , volume=
Calibrated interpretation: Confidence estimation in semantic parsing , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.