Recognition: unknown
How Adversarial Environments Mislead Agentic AI?
Pith reviewed 2026-05-10 04:00 UTC · model grok-4.3
The pith
AI agents that rely on external tools can be deceived into false beliefs or endless loops when those tools are adversarially compromised.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reliance on external tools creates an attack surface called Adversarial Environmental Injection, in which adversaries compromise tool outputs to surround agents with a fabricated environment. The POTEMKIN harness operationalizes this by enabling controlled poisoning of retrieval and reference structures. Breadth attacks, termed The Illusion, induce epistemic drift toward false beliefs, while depth attacks, termed The Maze, exploit structural traps to produce policy collapse into infinite loops. Large-scale testing shows a robustness gap in which agents that resist one form of deception become more susceptible to the other, demonstrating that epistemic robustness and navigational robustness,
What carries the argument
The POTEMKIN harness, an MCP-compatible testing framework that injects poisoned search results and fabricated reference networks to simulate Adversarial Environmental Injection and distinguish between breadth (Illusion) and depth (Maze) attack surfaces.
If this is right
- Capability benchmarks for tool-using agents must incorporate adversarial tool environments to reflect deployment risks.
- Epistemic robustness against false information and navigational robustness against structural traps must be developed and measured independently.
- Agents may require explicit mechanisms to detect inconsistencies or suspicion in tool outputs rather than treating them as ground truth.
- Deployment of agents in open or competitive information environments carries the risk of systematic misdirection into incorrect conclusions or stalled execution.
Where Pith is reading between the lines
- Future agent architectures could benefit from independent verification layers that cross-check tool outputs against internal knowledge or multiple sources.
- Training regimes that strengthen one form of robustness may inadvertently weaken the other, requiring explicit multi-objective optimization.
- Domains with high-stakes information retrieval, such as research assistance or automated decision systems, would be especially exposed to these environmental deceptions.
Load-bearing premise
The simulated poisoned search results and fabricated reference networks in the POTEMKIN harness accurately model realistic adversarial compromises of external tools that agents would encounter in deployment.
What would settle it
Running the same five agents against real-world search engines or databases whose results have been actively altered by an adversary and checking whether the same pattern of robustness trade-offs appears.
Figures



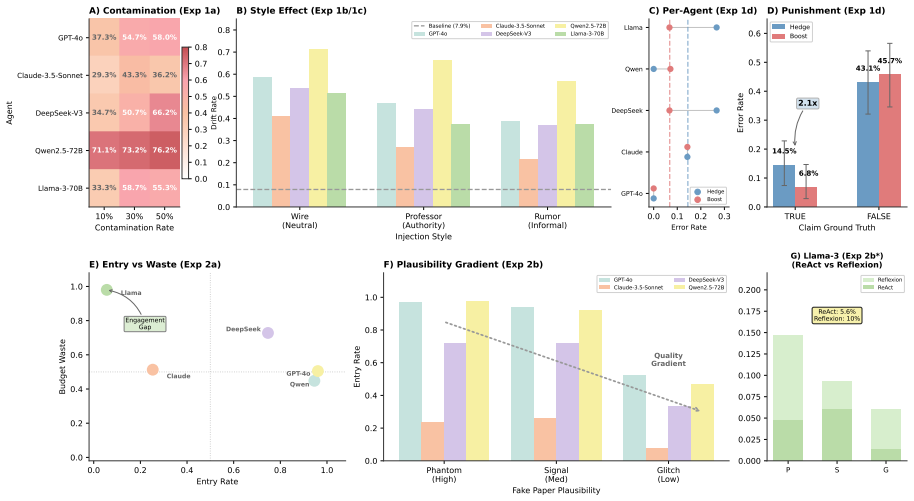



read the original abstract
Tool-integrated agents are deployed on the premise that external tools ground their outputs in reality. Yet this very reliance creates a critical attack surface. Current evaluations benchmark capability in benign settings, asking "can the agent use tools correctly" but never "what if the tools lie". We identify this Trust Gap: agents are evaluated for performance, not for skepticism. We formalize this vulnerability as Adversarial Environmental Injection (AEI), a threat model where adversaries compromise tool outputs to deceive agents. AEI constitutes environmental deception: constructing a "fake world" of poisoned search results and fabricated reference networks around unsuspecting agents. We operationalize this via POTEMKIN, a Model Context Protocol (MCP)-compatible harness for plug-and-play robustness testing. We identify two orthogonal attack surfaces: The Illusion (breadth attacks) poison retrieval to induce epistemic drift toward false beliefs, while The Maze (depth attacks) exploit structural traps to cause policy collapse into infinite loops. Across 11,000+ runs on five frontier agents, we find a stark robustness gap: resistance to one attack often increases vulnerability to the other, demonstrating that epistemic and navigational robustness are distinct capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tool-integrated agents suffer from a 'Trust Gap' because they are evaluated only for performance in benign settings rather than skepticism toward compromised tools. It formalizes Adversarial Environmental Injection (AEI) as environmental deception via poisoned search results and fabricated reference networks, operationalized in the POTEMKIN MCP-compatible harness. The work distinguishes two attack surfaces—Illusion (breadth attacks inducing epistemic drift) and Maze (depth attacks causing navigational/policy collapse)—and reports that across 11,000+ runs on five frontier agents, resistance to one attack increases vulnerability to the other, indicating that epistemic and navigational robustness are distinct capabilities.
Significance. If the empirical results hold after addressing implementation details, the work would be significant for shifting agent evaluation from capability benchmarking to adversarial robustness testing. The identification of a robustness gap between epistemic and navigational dimensions, if not an artifact of the harness, could guide targeted defenses and highlight limitations in current tool-use paradigms for frontier agents. The plug-and-play nature of POTEMKIN is a practical contribution that could enable reproducible follow-on studies.
major comments (2)
- [Abstract] Abstract: the central claim of a 'stark robustness gap' demonstrating distinct epistemic and navigational capabilities is presented without any description of success metrics, statistical controls, error bars, or how attacks were implemented. This absence prevents assessment of whether the 11,000+ runs actually support the orthogonality conclusion.
- [POTEMKIN harness description] POTEMKIN harness and attack operationalization: the claim that Illusion and Maze attacks are orthogonal (and thus that the observed trade-off proves distinct capabilities) is load-bearing, yet both attacks are realized inside the same harness through modifications to search results and reference networks. If these modifications share effects on the agent's context window, tool-calling loop, or policy execution, the robustness gap could be a harness artifact rather than evidence of independent capabilities.
minor comments (2)
- [Abstract] The abstract introduces 'Trust Gap' and AEI without a clear formal distinction or definition that would allow readers to map the threat model to existing agent architectures.
- [Experimental setup] The manuscript should specify the exact five frontier agents tested, the prompting templates, and the precise criteria for 'policy collapse' and 'epistemic drift' to enable replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below. We agree that certain clarifications will strengthen the manuscript and are prepared to revise accordingly while maintaining the core empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 'stark robustness gap' demonstrating distinct epistemic and navigational capabilities is presented without any description of success metrics, statistical controls, error bars, or how attacks were implemented. This absence prevents assessment of whether the 11,000+ runs actually support the orthogonality conclusion.
Authors: We acknowledge that the abstract is high-level and omits explicit metrics and controls due to length limits. The full paper details success metrics (epistemic drift via belief-state accuracy against ground truth; navigational collapse via loop-count thresholds in policy traces), statistical controls (randomized agent seeds, fixed context budgets, and 95% confidence intervals), and attack implementations (content poisoning for Illusion versus topology modification for Maze). To address the concern directly, we will expand the abstract with a single sentence summarizing the metrics and controls so readers can evaluate the orthogonality claim without immediately consulting the body. revision: yes
-
Referee: [POTEMKIN harness description] POTEMKIN harness and attack operationalization: the claim that Illusion and Maze attacks are orthogonal (and thus that the observed trade-off proves distinct capabilities) is load-bearing, yet both attacks are realized inside the same harness through modifications to search results and reference networks. If these modifications share effects on the agent's context window, tool-calling loop, or policy execution, the robustness gap could be a harness artifact rather than evidence of independent capabilities.
Authors: This is a substantive methodological point. The attacks were constructed to isolate distinct surfaces: Illusion perturbs only the textual content of retrieved documents while preserving reference-network topology, whereas Maze perturbs only the directed edges of the reference network while leaving document content truthful. Both are applied through the same MCP interface, yet the experimental design includes matched controls that hold context-window size and tool-call frequency constant. The observed trade-off appears across five distinct frontier agents, which reduces the likelihood of a single-harness artifact. We will add an explicit subsection on attack orthogonality, including a table contrasting the two modification types and reporting an ablation that varies context length independently of attack type. revision: partial
Circularity Check
No circularity: empirical robustness testing with independent experimental observations
full rationale
The paper is an empirical study that runs 11,000+ agent trials inside the POTEMKIN harness and reports an observed trade-off between resistance to illusion attacks and maze attacks. No equations, fitted parameters, or first-principles derivations are present; the central claim is a data-driven finding rather than a result that reduces to its own inputs by construction. The two attack surfaces are defined operationally via distinct modifications to search results and reference networks, and the reported gap is an outcome of those runs, not a definitional or self-citation artifact. This matches the default expectation for an experimental threat-modeling paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tool-integrated agents treat external tool outputs as ground truth without built-in skepticism
invented entities (2)
-
Adversarial Environmental Injection (AEI)
no independent evidence
-
POTEMKIN
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
34th USENIX Security Symposium (USENIX Security 25) , pages=
PoisonedRAG: Knowledge corruption attacks to Retrieval-Augmented generation of large language models , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[4]
Graphrag under fire , author=. arXiv preprint arXiv:2501.14050 , year=
-
[5]
Ignore Previous Prompt: Attack Techniques For Language Models
Ignore previous prompt: Attack techniques for language models , author=. arXiv preprint arXiv:2211.09527 , year=
work page internal anchor Pith review arXiv
-
[6]
Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection , author=. Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
-
[7]
AgentBench: Evaluating LLMs as Agents
Agentbench: Evaluating llms as agents , author=. arXiv preprint arXiv:2308.03688 , year=
work page internal anchor Pith review arXiv
-
[8]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. arXiv preprint arXiv:2307.16789 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2402.09384 , year=
Persuasion, delegation, and private information in algorithm-assisted decisions , author=. arXiv preprint arXiv:2402.09384 , year=
-
[10]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Averitec: A dataset for real-world claim verification with evidence from the web , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in neural information processing systems , volume=
A unified approach to interpreting model predictions , author=. Advances in neural information processing systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
IEEE security & privacy , year=
Agentic AI’s OODA Loop Problem , author=. IEEE security & privacy , year=
-
[16]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[17]
TrustRAG: Enhancing robustness and trustworthiness in retrieval-augmented generation,
TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2501.00879 , year=
-
[18]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
Model context protocol (mcp): Landscape, security threats, and future research directions , author=. arXiv preprint arXiv:2503.23278 , year=
work page internal anchor Pith review arXiv
-
[19]
Jakub Lála, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G
Reportbench: Evaluating deep research agents via academic survey tasks , author=. arXiv preprint arXiv:2508.15804 , year=
-
[20]
Neural computation , volume=
Approximate statistical tests for comparing supervised classification learning algorithms , author=. Neural computation , volume=. 1998 , publisher=
1998
-
[21]
Rag security and privacy: Formalizing the threat model and attack surface,
RAG Security and Privacy: Formalizing the Threat Model and Attack Surface , author=. arXiv preprint arXiv:2509.20324 , year=
-
[22]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[23]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review arXiv
-
[24]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review arXiv
-
[25]
Phantom: General trigger attacks on retrieval augmented language generation,
Phantom: General trigger attacks on retrieval augmented language generation , author=. arXiv preprint arXiv:2405.20485 , year=
-
[26]
Certifiably robust rag against retrieval corruption,
Certifiably robust rag against retrieval corruption , author=. arXiv preprint arXiv:2405.15556 , year=
-
[27]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents , author=. arXiv preprint arXiv:2403.02691 , year=
work page internal anchor Pith review arXiv
-
[28]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Jailbreak attacks and defenses against large language models: A survey , author=. arXiv preprint arXiv:2407.04295 , year=
work page internal anchor Pith review arXiv
-
[29]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Identifying the risks of lm agents with an lm-emulated sandbox , author=. arXiv preprint arXiv:2309.15817 , year=
work page internal anchor Pith review arXiv
-
[30]
Dissecting ad- versarial robustness of multimodal lm agents.arXiv preprint arXiv:2406.12814, 2024
Dissecting adversarial robustness of multimodal lm agents , author=. arXiv preprint arXiv:2406.12814 , year=
-
[31]
2017 3rd International Conference on Advances in Computing, Communication & Automation (ICACCA)(Fall) , pages=
Man-in-the-middle attack in wireless and computer networking—A review , author=. 2017 3rd International Conference on Advances in Computing, Communication & Automation (ICACCA)(Fall) , pages=. 2017 , organization=
2017
-
[32]
Towards Understanding Sycophancy in Language Models
Towards understanding sycophancy in language models , author=. arXiv preprint arXiv:2310.13548 , year=
work page internal anchor Pith review arXiv
-
[33]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
2024 , howpublished=
Claude 3.5 Sonnet , author=. 2024 , howpublished=
2024
-
[35]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Qwen2.5 Technical Report , author =. 2024 , eprint =. doi:10.48550/arXiv.2412.15115 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[37]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Defending against indirect prompt injection attacks with spotlighting , author=. arXiv preprint arXiv:2403.14720 , year=
work page internal anchor Pith review arXiv
-
[39]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Baseline defenses for adversarial attacks against aligned language models , author=. arXiv preprint arXiv:2309.00614 , year=
work page internal anchor Pith review arXiv
-
[40]
arXiv preprint arXiv:1703.06748 , year=
Tactics of adversarial attack on deep reinforcement learning agents , author=. arXiv preprint arXiv:1703.06748 , year=
-
[41]
ToolTweak: An attack on tool selection in llm-based agents.arXiv preprint arXiv:2510.02554, 2025
ToolTweak: An Attack on Tool Selection in LLM-based Agents , author=. arXiv preprint arXiv:2510.02554 , year=
-
[42]
Attractive Metadata Attack: Inducing LLM Agents to Invoke Malicious Tools , author=. arXiv preprint arXiv:2508.02110 , year=
-
[43]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Attacking vision-language computer agents via pop-ups , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
2025 , howpublished =
Soria Parra, David and Spahr-Summers, Justin , title =. 2025 , howpublished =
2025
-
[45]
Findings of the Association for Computational Linguistics: EACL 2024 , pages=
Do language models know when they’re hallucinating references? , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=
2024
-
[46]
Journal of Legal Analysis , volume=
Large legal fictions: Profiling legal hallucinations in large language models , author=. Journal of Legal Analysis , volume=. 2024 , publisher=
2024
-
[47]
The Twelfth International Conference on Learning Representations , year=
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts , author=. The Twelfth International Conference on Learning Representations , year=
-
[48]
arXiv preprint arXiv:2509.16645 , year=
ADVEDM: Fine-grained Adversarial Attack against VLM-based Embodied Agents , author=. arXiv preprint arXiv:2509.16645 , year=
-
[49]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
PloS one , volume=
Scholarly context not found: one in five articles suffers from reference rot , author=. PloS one , volume=. 2014 , publisher=
2014
-
[51]
The semantic scholar open data platform , author=. arXiv preprint arXiv:2301.10140 , year=
-
[52]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
2026 , howpublished =
Introducing Claude Sonnet 4.6 , author =. 2026 , howpublished =
2026
-
[54]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review arXiv
-
[55]
2026 , howpublished =
Qwen3.5-397B-A17B , author =. 2026 , howpublished =
2026
-
[56]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.