Recognition: unknown
DW-Bench: Benchmarking LLMs on Data Warehouse Graph Topology Reasoning
Pith reviewed 2026-05-10 02:28 UTC · model grok-4.3
The pith
Tool-augmented LLMs substantially outperform static approaches on graph-topology reasoning over data warehouse schemas but plateau on hard compositional subtypes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
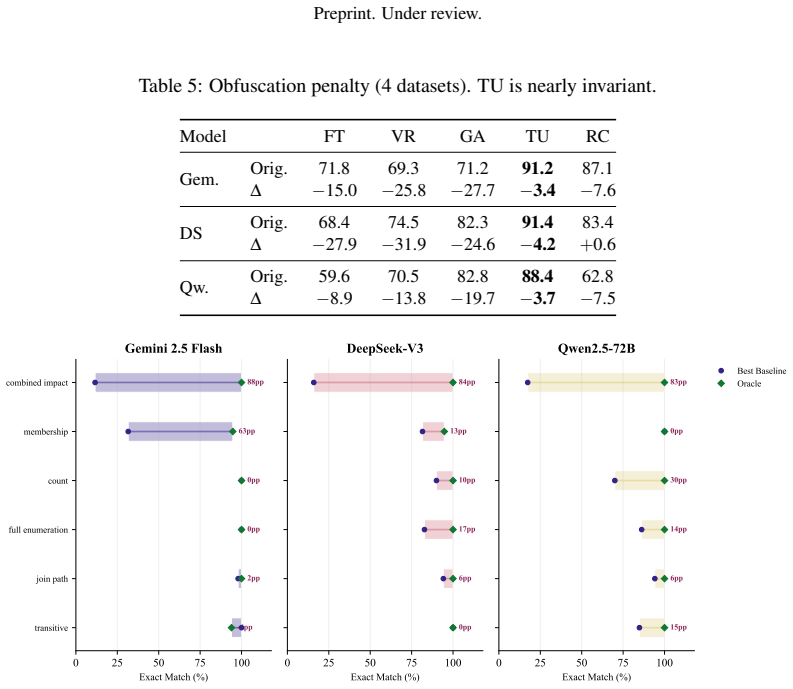
The paper claims that DW-Bench, built from 1,046 verifiably correct questions across five schemas, provides a reliable way to measure how well LLMs handle graph-topology reasoning that integrates foreign-key and data-lineage edges, and that tool-augmented methods achieve higher performance than static prompting yet reach a plateau on the hardest compositional question subtypes.
What carries the argument
DW-Bench benchmark whose questions are automatically generated to probe combined foreign-key and data-lineage navigation inside data warehouse schemas.
If this is right
- Tool augmentation is required for stronger performance when LLMs must traverse schema graphs.
- Current models still encounter clear limits once questions demand multiple layers of composition.
- The benchmark supplies a repeatable yardstick for measuring future gains in LLM schema reasoning.
- Performance gaps between methods point to the value of building better graph-traversal tools.
- Data warehouse tasks that rely on topology understanding can now be evaluated in a controlled setting.
Where Pith is reading between the lines
- The observed plateau suggests that further progress may require new tool designs that let models build and query temporary graph views rather than step through edges one at a time.
- Similar benchmarks focused on other database styles could reveal whether the same tool-versus-static pattern holds outside warehouse schemas.
- If the questions prove representative, DW-Bench results could help data teams decide which LLM setups to deploy for automated lineage analysis or impact assessment.
- Extending the benchmark to include real user workloads rather than generated questions would test whether the current findings generalize to production environments.
Load-bearing premise
The 1,046 automatically generated questions are verifiably correct and representative of the graph-topology reasoning required in real data warehouse schemas.
What would settle it
A manual audit that finds factual errors or non-representative questions among the 1,046 items, or a follow-up study in which strong DW-Bench scores fail to predict success on actual data-warehouse tasks performed by practitioners.
Figures


read the original abstract
This paper introduces DW-Bench, a new benchmark that evaluates large language models (LLMs) on graph-topology reasoning over data warehouse schemas, explicitly integrating both foreign-key (FK) and data-lineage edges. The benchmark comprises 1,046 automatically generated, verifiably correct questions across five schemas. Experiments show that tool-augmented methods substantially outperform static approaches but plateau on hard compositional subtypes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DW-Bench, a benchmark for evaluating LLMs on graph-topology reasoning over data warehouse schemas that integrates foreign-key (FK) and data-lineage edges. It consists of 1,046 automatically generated questions across five schemas. Experiments indicate that tool-augmented methods substantially outperform static approaches but plateau on hard compositional subtypes.
Significance. If the benchmark questions are verifiably correct and representative, the work provides a useful empirical framework for assessing LLM capabilities in data engineering tasks involving complex graph structures. It highlights potential benefits of tool augmentation while identifying limits in compositional reasoning, which could inform future agent designs for warehouse schema navigation.
major comments (3)
- [Benchmark construction section] The central claim that performance differences reflect genuine reasoning limits (rather than artifacts) depends on the 1,046 questions being free of subtle errors in FK/lineage topology. The abstract states they are 'automatically generated, verifiably correct,' but the generation procedure and verification method (e.g., rule-based templates vs. LLM-assisted, or exhaustive multi-hop graph-query equivalence checks) are not described. This is load-bearing for interpreting the plateau on hard subtypes.
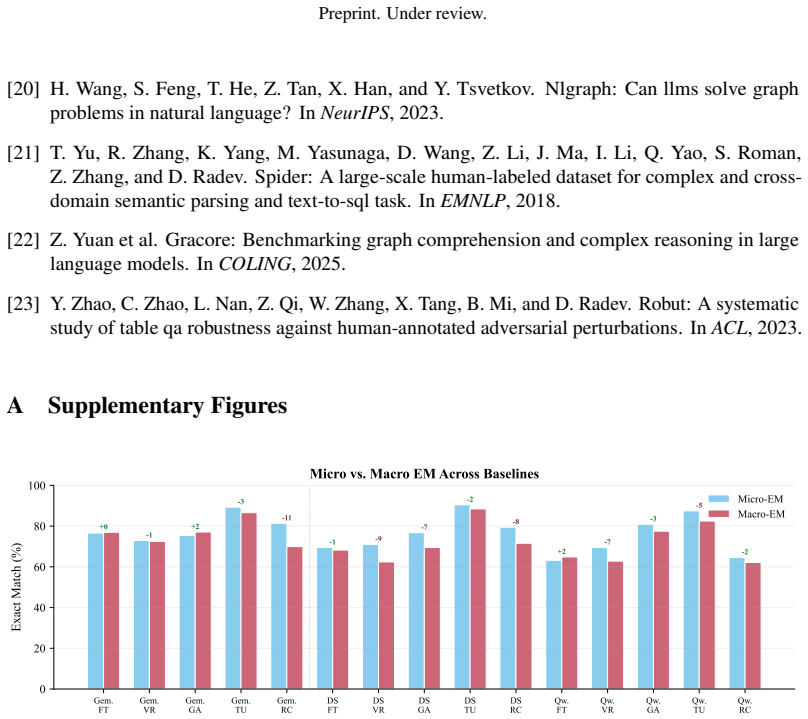
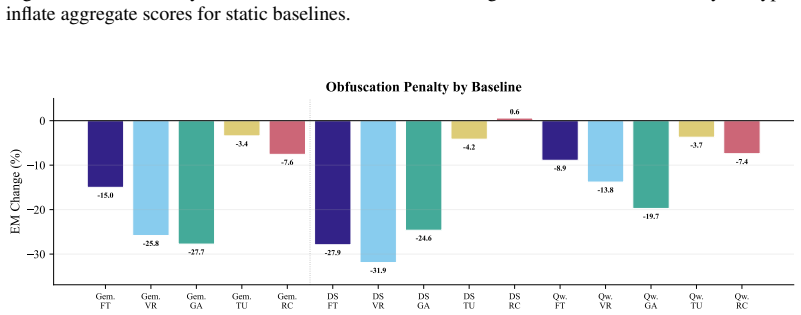
- [Experiments section] The claim of substantial outperformance by tool-augmented methods and the plateau on hard compositional subtypes requires exact accuracy numbers, statistical tests, and error analysis broken down by subtype and schema. Without these, the evidential support for the main experimental conclusion remains limited.
- [Benchmark construction section] Representativeness is untested: the five schemas may omit irregular topologies, naming conventions, and constraint patterns common in production data warehouses. The paper should include a comparison or discussion of how the synthetic schemas map to real-world DW characteristics to support generalizability.
minor comments (2)
- [Abstract] The abstract mentions performance differences and question counts but provides no exact accuracy figures or error analysis; adding a brief quantitative summary would improve clarity.
- [Throughout] Ensure consistent terminology for 'FK edges' and 'data-lineage edges' across all sections and figures.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on DW-Bench. We address each major comment point by point below, providing the strongest honest responses possible based on the manuscript content. Revisions have been made where the comments identify gaps in description or reporting.
read point-by-point responses
-
Referee: [Benchmark construction section] The central claim that performance differences reflect genuine reasoning limits (rather than artifacts) depends on the 1,046 questions being free of subtle errors in FK/lineage topology. The abstract states they are 'automatically generated, verifiably correct,' but the generation procedure and verification method (e.g., rule-based templates vs. LLM-assisted, or exhaustive multi-hop graph-query equivalence checks) are not described. This is load-bearing for interpreting the plateau on hard subtypes.
Authors: We agree that explicit details on question generation and verification are necessary to support the claim that observed performance differences and plateaus reflect reasoning limits rather than artifacts. The revised manuscript expands the Benchmark Construction section with a full description of the rule-based template system used to generate questions over the FK and lineage graphs, followed by verification via exhaustive execution of equivalent multi-hop graph queries on the underlying schemas to confirm topological correctness. This addition directly addresses the concern for the hard compositional subtypes. revision: yes
-
Referee: [Experiments section] The claim of substantial outperformance by tool-augmented methods and the plateau on hard compositional subtypes requires exact accuracy numbers, statistical tests, and error analysis broken down by subtype and schema. Without these, the evidential support for the main experimental conclusion remains limited.
Authors: We acknowledge that the evidential support would be strengthened by more granular reporting. The revised Experiments section now includes tables reporting exact accuracy percentages for all methods, broken down by question subtype and schema. We have added paired statistical significance tests comparing tool-augmented and static approaches, as well as a dedicated error analysis subsection that categorizes failure modes on the hard compositional subtypes across schemas. revision: yes
-
Referee: [Benchmark construction section] Representativeness is untested: the five schemas may omit irregular topologies, naming conventions, and constraint patterns common in production data warehouses. The paper should include a comparison or discussion of how the synthetic schemas map to real-world DW characteristics to support generalizability.
Authors: We agree that a discussion of generalizability strengthens the work. The revised Benchmark Construction section adds a new subsection that maps the five synthetic schemas to common real-world data warehouse characteristics drawn from the literature (e.g., prevalence of star/snowflake topologies, typical lineage depths, and naming patterns). This discussion explicitly notes the scope and limitations of the chosen schemas without claiming exhaustive coverage of all production irregularities. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted predictions
full rationale
This is a pure empirical benchmark paper that introduces DW-Bench, generates 1,046 questions across five schemas, and reports comparative LLM performance (tool-augmented vs. static methods). No equations, parameter fits, uniqueness theorems, or ansatzes appear in the provided text or abstract. The central claims rest on experimental outcomes rather than any derivation chain that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for the benchmark results themselves. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. B. Chen et al. Beaver: An enterprise benchmark for text-to-sql. InACL, 2024
2024
-
[2]
DeepSeek-AI. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
D. Edge, H. Trinh, N. Cheng, et al. From local to global: A graph RAG approach to query- focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Fatemi, J
B. Fatemi, J. Halcrow, and B. Perozzi. Talk like a graph: Encoding graphs for large language models. InICLR, 2024
2024
-
[5]
Fey and J
M. Fey and J. E. Lenssen. Fast graph representation learning with pytorch geometric.ICLR Workshop on Representation Learning on Graphs and Manifolds, 2019
2019
-
[6]
A. A. Hagberg, D. A. Schult, and P. J. Swart. Exploring network structure, dynamics, and function using networkx. SciPy Conference, 2008
2008
-
[7]
X. He, Y . Tian, Y . Sun, N. V . Chawla, T. Laurent, Y . LeCun, X. Bresson, and B. Hooi. G- retriever: Retrieval-augmented generation for textual graph understanding and question answer- ing.NeurIPS, 2024
2024
-
[8]
Hripcsak et al
G. Hripcsak et al. Observational health data sciences and informatics (OHDSI): Opportunities for observational researchers.Studies in Health Technology and Informatics, 216, 2015
2015
-
[9]
B. Jin, C. Xie, J. Zhang, K. K. R. Meng, H. Zhang, S. Zhang, D. Bo, et al. Graph chain- of-thought: Augmenting large language models by reasoning on graphs.Findings of ACL, 2024
2024
-
[10]
Johnson, M
J. Johnson, M. Douze, and H. Jégou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 2019
2019
-
[11]
Lei et al
F. Lei et al. Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows. InICLR, 2025
2025
-
[12]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela. Retrieval-augmented generation for knowledge- intensive NLP tasks. InNeurIPS, 2020
2020
-
[13]
J. Li, B. Hui, G. Qu, J. Yang, B. Li, B. Li, B. Wang, B. Qin, R. Geng, N. Huo, X. Zhou, C. Ma, G. Li, K. Chang, F. Si, and Y . Li. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. InNeurIPS, 2023
2023
-
[14]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Reimers and I
N. Reimers and I. Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InEMNLP, 2019
2019
-
[16]
J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y . Gong, H.-Y . Shum, and J. Guo. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. InICLR, 2024
2024
-
[17]
Tang et al
J. Tang et al. Grapharena: Benchmarking large language models on graph computational problems. InICLR, 2025
2025
- [18]
-
[19]
Gemini: A Family of Highly Capable Multimodal Models
G. Team et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2024. 9 Preprint. Under review
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
H. Wang, S. Feng, T. He, Z. Tan, X. Han, and Y . Tsvetkov. Nlgraph: Can llms solve graph problems in natural language? InNeurIPS, 2023
2023
-
[21]
T. Yu, R. Zhang, K. Yang, M. Yasunaga, D. Wang, Z. Li, J. Ma, I. Li, Q. Yao, S. Roman, Z. Zhang, and D. Radev. Spider: A large-scale human-labeled dataset for complex and cross- domain semantic parsing and text-to-sql task. InEMNLP, 2018
2018
-
[22]
Yuan et al
Z. Yuan et al. Gracore: Benchmarking graph comprehension and complex reasoning in large language models. InCOLING, 2025
2025
-
[23]
Y . Zhao, C. Zhao, L. Nan, Z. Qi, W. Zhang, X. Tang, B. Mi, and D. Radev. Robut: A systematic study of table qa robustness against human-annotated adversarial perturbations. InACL, 2023. A Supplementary Figures /uni0000002a/uni00000048/uni00000050/uni00000011 /uni00000029/uni00000037 /uni0000002a/uni00000048/uni00000050/uni00000011 /uni00000039/uni0000003...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.