Recognition: unknown
R²-dLLM: Accelerating Diffusion Large Language Models via Spatio-Temporal Redundancy Reduction
Pith reviewed 2026-05-10 02:52 UTC · model grok-4.3
The pith
R²-dLLM reduces diffusion LLM decoding steps by up to 75 percent by removing spatial and temporal redundancies during parallel token generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
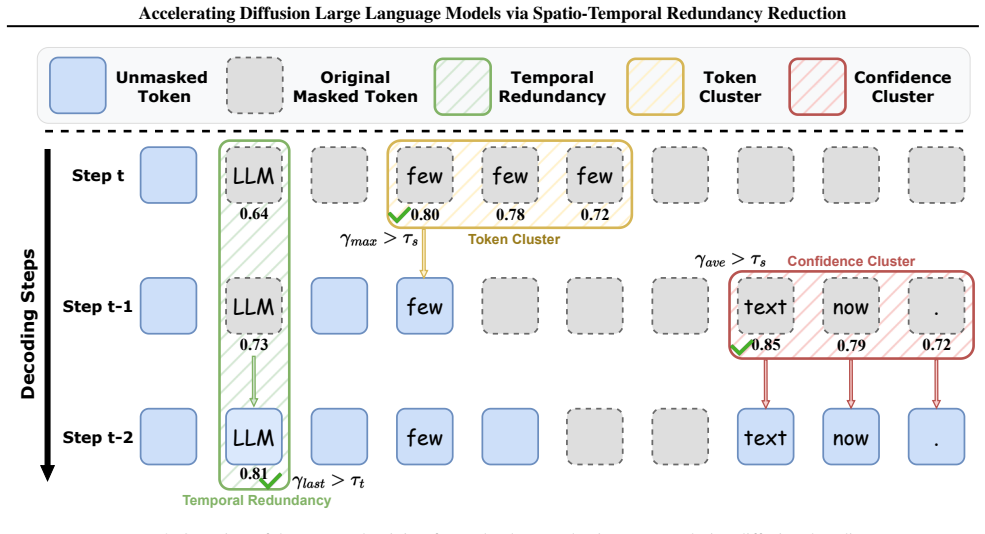
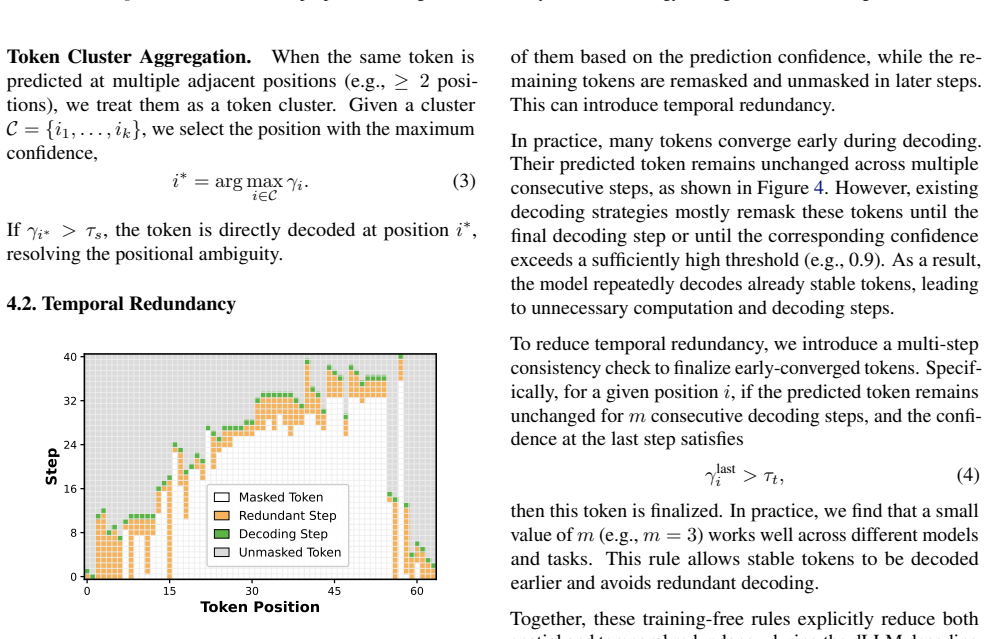
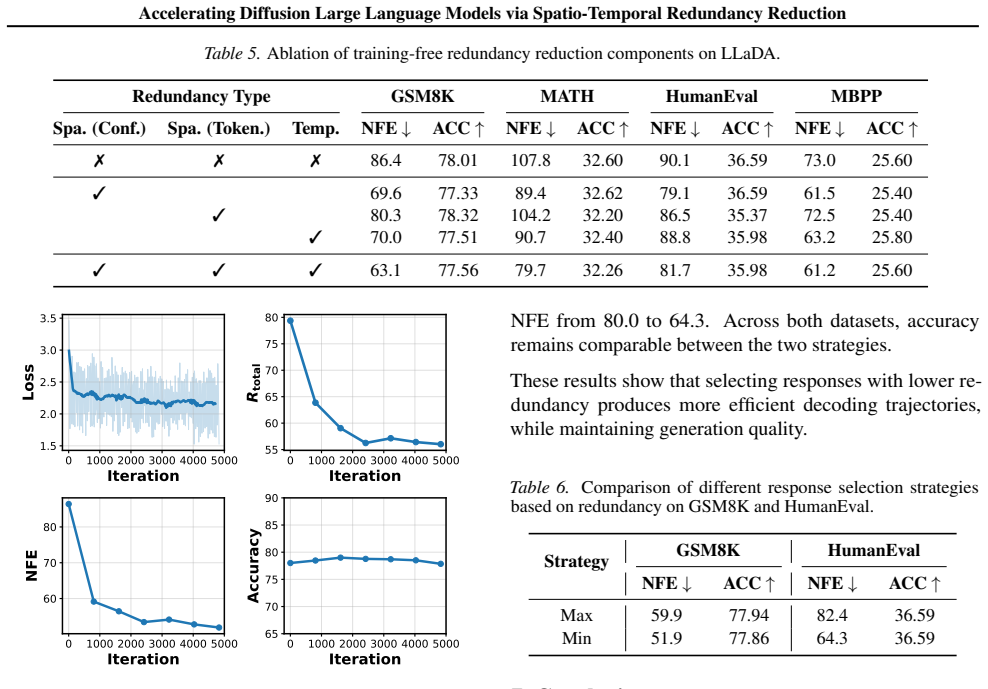
The paper establishes that a substantial share of dLLM decoding inefficiency stems from spatial redundancy caused by confidence clusters and positional ambiguity, together with temporal redundancy from repeatedly remasking predictions that have already stabilized. R²-dLLM counters this with training-free decoding rules that aggregate local confidence and token predictions and finalize temporally stable tokens, combined with a redundancy-aware supervised fine-tuning pipeline that aligns the model to efficient decoding trajectories, achieving up to 75 percent fewer decoding steps while preserving competitive generation quality across models and tasks.
What carries the argument
R²-dLLM framework of local confidence aggregation rules and stable-token finalization at inference time, plus redundancy-aware supervised fine-tuning to align models with shorter decoding paths.
If this is right
- Existing dLLM models can be accelerated at inference time with no retraining using the aggregation and finalization rules.
- Redundancy-aware fine-tuning produces models that naturally follow shorter decoding trajectories by design.
- The step reductions and quality preservation hold across different diffusion LLM architectures and generation tasks.
- Decoding latency drops substantially while standard quality metrics remain competitive with existing strategies.
Where Pith is reading between the lines
- Similar redundancy patterns may exist in other non-autoregressive or diffusion-based sequence generators, opening a route to broader efficiency gains.
- Lower step counts could allow dLLMs to compete on latency with autoregressive models in interactive settings such as chat or code completion.
- The approach could be combined with other acceleration methods like caching or quantization for compounded speedups in deployed systems.
Load-bearing premise
That the observed patterns of spatial redundancy from confidence clusters and temporal redundancy from remasking stabilized predictions appear consistently enough across different dLLM models and tasks for the aggregation rules and fine-tuning to remove them without quality loss.
What would settle it
Apply R²-dLLM to a new dLLM architecture or task and check whether step count reduction falls below 50 percent or quality metrics such as task accuracy drop compared with baseline decoding.
Figures




read the original abstract
Diffusion Large Language Models (dLLMs) have emerged as a promising alternative to autoregressive generation by enabling parallel token prediction. However, practical dLLM decoding still suffers from high inference latency, which limits deployment. In this work, we observe that a substantial part of this inefficiency comes from recurring redundancy in the decoding process, including spatial redundancy caused by confidence clusters and positional ambiguity, and temporal redundancy caused by repeatedly remasking predictions that have already stabilized. Motivated by these patterns, we propose $R^2$-dLLM, a unified framework for reducing decoding redundancy from both inference and training perspectives. At inference time, we introduce training-free decoding rules that aggregate local confidence and token predictions, and finalize temporally stable tokens to avoid redundant decoding steps. We further propose a redundancy-aware supervised fine-tuning pipeline that aligns the model with efficient decoding trajectories and reduces reliance on manually tuned thresholds. Experiments demonstrate that $R^2$-dLLM consistently reduces the number of decoding steps by up to 75% compared to existing decoding strategies, while maintaining competitive generation quality across different models and tasks. These results validate that decoding redundancy is a central bottleneck in dLLMs, and that explicitly reducing it yields substantial practical efficiency gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes R²-dLLM, a framework for accelerating diffusion large language models (dLLMs) by reducing spatio-temporal redundancy during decoding. It identifies spatial redundancy arising from confidence clusters and positional ambiguity, and temporal redundancy from repeated remasking of stabilized predictions. The method introduces training-free decoding rules that aggregate local confidence and token predictions while finalizing temporally stable tokens, together with a redundancy-aware supervised fine-tuning (SFT) pipeline to align the model with efficient trajectories. The central empirical claim is that these changes reduce the number of decoding steps by up to 75% relative to existing strategies while preserving competitive generation quality across models and tasks.
Significance. If the reported speedups and quality preservation hold under broader scrutiny, the work could meaningfully advance the practicality of dLLMs by targeting a core inference bottleneck. The training-free aggregation rules and the integration of redundancy-aware SFT constitute clear strengths, as does the explicit framing of redundancy as an exploitable pattern rather than an incidental artifact. These elements, if shown to generalize, would provide a concrete path toward lower-latency parallel generation without requiring architectural overhauls.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the headline claim of 'up to 75% step reduction' is presented without enumeration of the concrete baselines, model sizes, tasks, number of runs, error bars, or data-exclusion criteria. This omission directly affects verifiability of the central result and prevents assessment of whether the observed gains are robust or task-specific.
- [Method / Experiments] The weakest assumption—that confidence clusters, positional ambiguity, and stabilized remasking predictions are reliably present and exploitable across dLLM architectures and task domains—is not supported by ablations on high- versus low-ambiguity tasks or by per-step quality trajectory comparisons. Without such evidence, the guarantee of 'no quality loss' under the aggregation rules plus SFT remains untested and load-bearing for the transferability claim.
minor comments (1)
- [Method] Notation for the aggregation rules (local confidence, temporal stability thresholds) should be defined with explicit symbols and ranges in the main text rather than left to supplementary material.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity and empirical robustness. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline claim of 'up to 75% step reduction' is presented without enumeration of the concrete baselines, model sizes, tasks, number of runs, error bars, or data-exclusion criteria. This omission directly affects verifiability of the central result and prevents assessment of whether the observed gains are robust or task-specific.
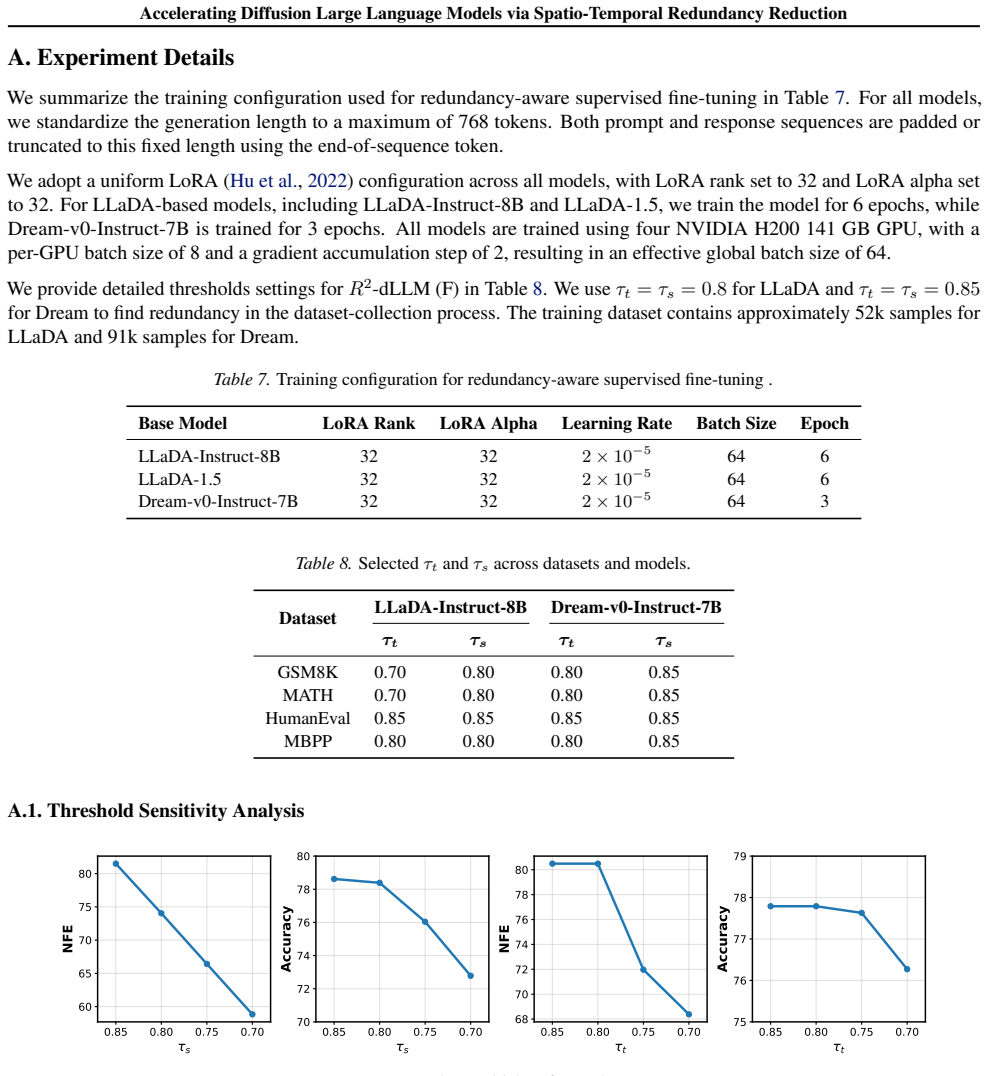
Authors: We agree that greater explicitness in the abstract and Experiments section would improve verifiability. The full Experiments section already contains tables reporting results on multiple models and tasks with comparisons to standard decoding strategies, but we will revise the abstract to briefly enumerate the primary baselines, model scales, and task categories. We will also add a dedicated paragraph in the Experiments section that details the number of runs, reports error bars or variance where applicable, and clarifies any data exclusion criteria. These changes will make the 75% reduction claim easier to assess without altering the underlying results. revision: yes
-
Referee: [Method / Experiments] The weakest assumption—that confidence clusters, positional ambiguity, and stabilized remasking predictions are reliably present and exploitable across dLLM architectures and task domains—is not supported by ablations on high- versus low-ambiguity tasks or by per-step quality trajectory comparisons. Without such evidence, the guarantee of 'no quality loss' under the aggregation rules plus SFT remains untested and load-bearing for the transferability claim.
Authors: We acknowledge that explicit ablations on ambiguity levels and per-step trajectories would provide stronger support for generalizability. Our reported results already cover multiple dLLM architectures and tasks that exhibit varying degrees of redundancy (as reflected in the range of observed speedups), and final quality metrics remain competitive. However, we did not include dedicated high-/low-ambiguity splits or step-wise quality curves. In the revision we will add (i) an analysis that proxies task ambiguity via metrics such as prediction entropy and cluster size, reporting corresponding speedups and quality, and (ii) per-step quality trajectory plots that compare our method against baselines to confirm quality preservation throughout decoding. These additions will directly test the load-bearing assumption. revision: yes
Circularity Check
No significant circularity: empirical rules and SFT validated by experiment
full rationale
The paper's core contribution is an empirical framework: observations of spatial/temporal redundancy patterns motivate training-free aggregation rules for early token finalization plus a redundancy-aware SFT pipeline. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or self-referential definitions. Results are reported via direct experiments measuring step reduction and quality across models/tasks, with no load-bearing self-citations or uniqueness theorems invoked. The approach is self-contained as an engineering optimization whose validity rests on external benchmarks rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption dLLMs exhibit spatial redundancy from confidence clusters and positional ambiguity plus temporal redundancy from remasking stabilized predictions
Reference graph
Works this paper leans on
-
[1]
Albalak, A., Phung, D., Lile, N., Rafailov, R., Gandhi, K., Castricato, L., Singh, A., Blagden, C., Xiang, V ., Mahan, D., et al. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models. arXiv preprint arXiv:2502.17387,
-
[2]
Program Synthesis with Large Language Models
Austin, J., Johnson, D. D., Ho, J., Tarlow, D., and Van Den Berg, R. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021a. Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. Program synthesis with large langu...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[3]
Chen, T., Zhang, R., and Hinton, G. Analog bits: Gen- erating discrete data using diffusion models with self- conditioning.arXiv preprint arXiv:2208.04202,
-
[4]
dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488,
Chen, Z., Fang, G., Ma, X., Yu, R., and Wang, X. dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488,
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review arXiv
-
[8]
S., Seo, J.-s., Zhang, Z., and Gupta, U
Hu, Z., Meng, J., Akhauri, Y ., Abdelfattah, M. S., Seo, J.-s., Zhang, Z., and Gupta, U. Accelerating diffusion language model inference via efficient kv caching and guided diffusion.arXiv preprint arXiv:2505.21467,
-
[9]
Kong, F., Zhang, J., Liu, Y ., Wu, Z., Tian, Y ., Zhou, G., et al. Accelerating diffusion llm inference via local deter- minism propagation.arXiv preprint arXiv:2510.07081,
-
[10]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[11]
Liu, Z., Yang, Y ., Zhang, Y ., Chen, J., Zou, C., Wei, Q., Wang, S., and Zhang, L. dllm-cache: Accelerating diffu- sion large language models with adaptive caching.arXiv preprint arXiv:2506.06295,
-
[12]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
9 Accelerating Diffusion Large Language Models via Spatio-Temporal Redundancy Reduction Ma, X., Yu, R., Fang, G., and Wang, X. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
-
[13]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y ., Wen, J.-R., and Li, C. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review arXiv
-
[14]
Shen, J., Sarkar, G., Ro, Y ., Sridhar, S. N., Wang, Z., Akella, A., and Kundu, S. Improving the through- put of diffusion-based large language models via a training-free confidence-aware calibration.arXiv preprint arXiv:2512.07173,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
CreditDecoding: Accelerating Parallel Decoding in Diffusion Large Language Models with Trace Credit
Wang, K., Jiang, Z., Feng, H., Zhao, W., Liu, L., Li, J., Lan, Z., and Lin, W. Creditdecoding: Accelerating parallel decoding in diffusion large language models with trace credits.arXiv preprint arXiv:2510.06133, 2025a. Wang, X., Xu, C., Jin, Y ., Jin, J., Zhang, H., and Deng, Z. Diffusion llms can do faster-than-ar inference via dis- crete diffusion forc...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Xu, C. and Yang, D. Dllmquant: Quantizing diffusion-based large language models.arXiv preprint arXiv:2508.14090,
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Dream 7B: Diffusion Large Language Models
Ye, J., Xie, Z., Zheng, L., Gao, J., Wu, Z., Jiang, X., Li, Z., and Kong, L. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review arXiv
-
[19]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Zhu, F., Wang, R., Nie, S., Zhang, X., Wu, C., Hu, J., Zhou, J., Chen, J., Lin, Y ., Wen, J.-R., et al. Llada 1.5: Variance- reduced preference optimization for large language diffu- sion models.arXiv preprint arXiv:2505.19223,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.