Recognition: unknown
Guiding Distribution Matching Distillation with Gradient-Based Reinforcement Learning
Pith reviewed 2026-05-10 02:41 UTC · model grok-4.3
The pith
Reinterpreting distillation gradients as reward targets lets reinforcement learning improve few-step diffusion models beyond their multi-step teachers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reinterpreting DMD gradients as implicit target tensors rather than scoring raw pixel outputs, GDMD supplies a gradient-level reward signal that functions as adaptive weighting, synchronizing the RL policy with the distillation objective and neutralizing optimization divergence to achieve state-of-the-art few-step generation.
What carries the argument
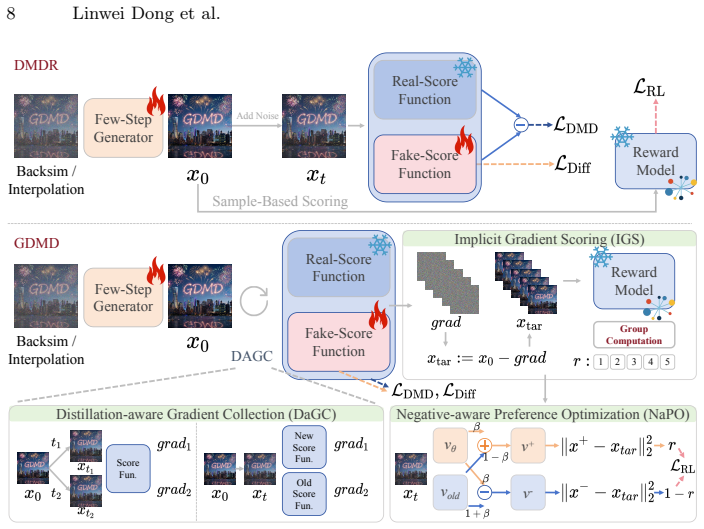
GDMD reward mechanism that substitutes DMD gradients for raw sample evaluation as the primary signal passed to existing reward models.
Where Pith is reading between the lines
- The same gradient-as-target substitution could be tested on other distillation objectives such as consistency or score matching to check generality.
- Because the reward signal is computed from internal gradients rather than final images, the method may reduce the number of full forward passes needed during RL fine-tuning.
- If the alignment effect holds, the technique could be applied to preference tuning of conditional generators where prompt adherence and aesthetic quality must be balanced at low step counts.
Load-bearing premise
That treating distillation gradients as implicit target tensors lets reward models evaluate updates without creating new optimization conflicts or unreliable signals.
What would settle it
A controlled experiment in which 4-step GDMD models score lower than their multi-step teacher or prior DMDR baselines on GenEval and human-preference ratings would disprove the benefit of gradient-level guidance.
Figures






read the original abstract
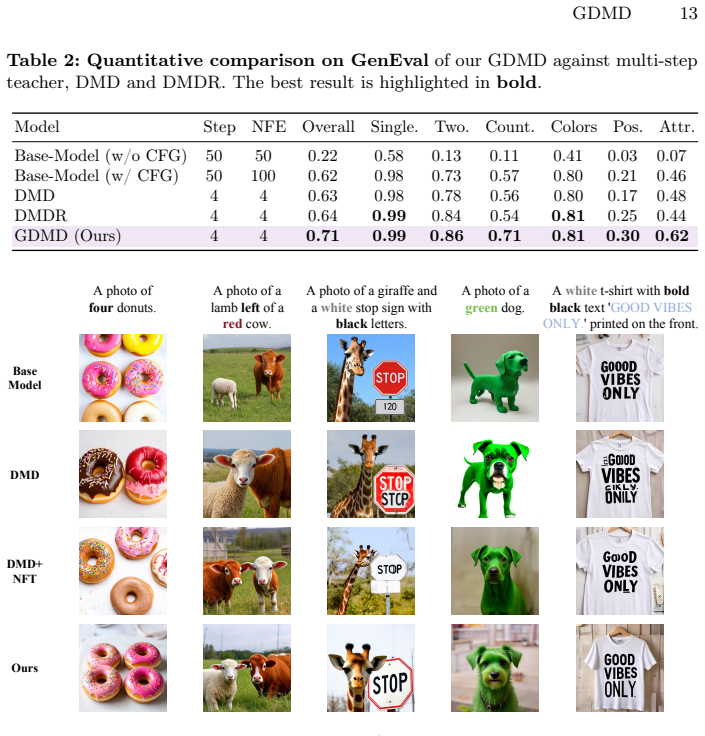
Diffusion distillation, exemplified by Distribution Matching Distillation (DMD), has shown great promise in few-step generation but often sacrifices quality for sampling speed. While integrating Reinforcement Learning (RL) into distillation offers potential, a naive fusion of these two objectives relies on suboptimal raw sample evaluation. This sample-based scoring creates inherent conflicts with the distillation trajectory and produces unreliable rewards due to the noisy nature of early-stage generation. To overcome these limitations, we propose GDMD, a novel framework that redefines the reward mechanism by prioritizing distillation gradients over raw pixel outputs as the primary signal for optimization. By reinterpreting the DMD gradients as implicit target tensors, our framework enables existing reward models to directly evaluate the quality of distillation updates. This gradient-level guidance functions as an adaptive weighting that synchronizes the RL policy with the distillation objective, effectively neutralizing optimization divergence. Empirical results show that GDMD sets a new SOTA for few-step generation. Specifically, our 4-step models outperform the quality of their multi-step teacher and substantially exceed previous DMDR results in GenEval and human-preference metrics, exhibiting strong scalability potential.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GDMD, a framework for integrating gradient-based reinforcement learning into Distribution Matching Distillation (DMD). It reinterprets DMD gradients as implicit target tensors so that existing reward models can directly score distillation updates rather than raw samples. This is claimed to act as adaptive weighting that synchronizes the RL policy with the distillation trajectory and neutralizes optimization divergence. The paper reports that the resulting 4-step models outperform their multi-step teacher as well as prior DMDR baselines on GenEval and human-preference metrics, positioning GDMD as a new SOTA for few-step diffusion generation with noted scalability potential.
Significance. If the gradient-as-target mechanism can be shown to produce stable, non-conflicting signals that genuinely align the two objectives, the work would meaningfully advance few-step diffusion by allowing RL to improve quality without the usual sample-level reward conflicts. Outperforming the multi-step teacher would be a strong result with clear practical implications for efficient generation.
major comments (2)
- [Abstract] Abstract: The central claim that 'reinterpreting the DMD gradients as implicit target tensors' enables reward models to evaluate distillation updates while 'effectively neutralizing optimization divergence' is asserted without any derivation, equation, or analysis showing that the composed objective remains a valid surrogate for the joint distillation-RL goal or that gradient-space signals remain compatible with the reward model's training distribution. This assumption is load-bearing for the entire method and must be substantiated in the method section.
- [Experiments] Experiments (presumed §4 or §5): The claim that 4-step GDMD models 'outperform the quality of their multi-step teacher' and 'substantially exceed previous DMDR results' requires explicit controls, including the exact teacher step count, the base DMD checkpoint, ablation of the gradient-reward component versus naive RL fusion, and variance across multiple runs. Without these, attribution of gains to the proposed synchronization mechanism cannot be verified.
minor comments (1)
- [Method] Notation for the reinterpreted gradient tensor and the adaptive weighting term should be introduced with a clear equation early in the method section to allow readers to follow the synchronization argument.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we address each major comment in detail and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'reinterpreting the DMD gradients as implicit target tensors' enables reward models to evaluate distillation updates while 'effectively neutralizing optimization divergence' is asserted without any derivation, equation, or analysis showing that the composed objective remains a valid surrogate for the joint distillation-RL goal or that gradient-space signals remain compatible with the reward model's training distribution. This assumption is load-bearing for the entire method and must be substantiated in the method section.
Authors: We acknowledge the need for a formal substantiation of the central claim. We will add to the method section a derivation showing that the composed objective remains a valid surrogate for the joint distillation-RL goal, along with analysis demonstrating that gradient-space signals are compatible with the reward model's training distribution. This will include relevant equations and discussion on how the reinterpretation neutralizes optimization divergence. revision: yes
-
Referee: [Experiments] Experiments (presumed §4 or §5): The claim that 4-step GDMD models 'outperform the quality of their multi-step teacher' and 'substantially exceed previous DMDR results' requires explicit controls, including the exact teacher step count, the base DMD checkpoint, ablation of the gradient-reward component versus naive RL fusion, and variance across multiple runs. Without these, attribution of gains to the proposed synchronization mechanism cannot be verified.
Authors: We agree that the experimental claims require additional controls to allow proper verification. We will revise the experiments section to specify the exact teacher step count, the base DMD checkpoint used, provide an ablation of the gradient-reward component versus naive RL fusion, and include variance across multiple runs. These revisions will enable attribution of the gains to the synchronization mechanism. revision: yes
Circularity Check
No circularity: method defined independently of claimed outcomes
full rationale
The paper introduces GDMD by reinterpreting existing DMD gradients as implicit target tensors to guide RL-based weighting. No equations, derivations, or self-citations are shown that reduce the synchronization claim or empirical superiority to a fitted parameter or prior result defined by the same paper. The framework is presented as a novel combination of external DMD and reward-model components, with performance claims offered as experimental outcomes rather than by-construction predictions. This satisfies the criteria for a self-contained proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distillation gradients provide a more reliable and aligned reward signal than raw sample outputs for RL optimization.
Reference graph
Works this paper leans on
-
[1]
Training Diffusion Models with Reinforcement Learning
Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Cai, H., Cao, S., Du, R., Gao, P., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L., et al.: Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699 (2025)
work page internal anchor Pith review arXiv 2025
-
[3]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chadebec, C., Tasar, O., Benaroche, E., Aubin, B.: Flash diffusion: Accelerating any conditional diffusion model for few steps image generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 15686–15695 (2025)
2025
-
[4]
ShareGPT-4o-Image: Aligning multimodal models with GPT-4o-level image generation
Chen, J., Cai, Z., Chen, P., Chen, S., Ji, K., Wang, X., Yang, Y., Wang, B.: Sharegpt-4o-image: Aligning multimodal models with gpt-4o-level image genera- tion. arXiv preprint arXiv:2506.18095 (2025)
-
[5]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[6]
Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023)
Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023)
2023
-
[7]
Advances in Neural Information Processing Systems36, 59729– 59760 (2023)
Franceschi, J.Y., Gartrell, M., Dos Santos, L., Issenhuth, T., de Bézenac, E., Chen, M., Rakotomamonjy, A.: Unifying gans and score-based diffusion as generative particle models. Advances in Neural Information Processing Systems36, 59729– 59760 (2023)
2023
-
[8]
Mean Flows for One-step Generative Modeling
Geng,Z.,Deng,M.,Bai,X.,Kolter,J.Z.,He,K.:Meanflowsforone-stepgenerative modeling. arXiv preprint arXiv:2505.13447 (2025)
work page internal anchor Pith review arXiv 2025
-
[9]
Advances in Neural Information Processing Systems36, 52132–52152 (2023) 16 Linwei Dong et al
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023) 16 Linwei Dong et al
2023
-
[10]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[11]
He, H., Ye, Y., Liu, J., Liang, J., Wang, Z., Yuan, Z., Wang, X., Mao, H., Wan, P., Pan, L.: Gardo: Reinforcing diffusion models without reward hacking (2025)
2025
-
[12]
Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324,
He, X., Fu, S., Zhao, Y., Li, W., Yang, J., Yin, D., Rao, F., Zhang, B.: Tempflow-grpo: When timing matters for grpo in flow models. arXiv preprint arXiv:2508.04324 (2025)
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hertz, A., Aberman, K., Cohen-Or, D.: Delta denoising score. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2328–2337 (2023)
2023
-
[14]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[15]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[16]
Jackyhate: Text-to-image-2m.https://huggingface.co/datasets/jackyhate/ text-to-image-2M(2025)
2025
-
[17]
arXiv preprint arXiv:2511.13649 (2025) 2
Jiang, D., Liu, D., Wang, Z., Wu, Q., Li, L., Li, H., Jin, X., Liu, D., Li, Z., Zhang, B., et al.: Distribution matching distillation meets reinforcement learning. arXiv preprint arXiv:2511.13649 (2025)
-
[18]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Advances in neural information processing systems36, 36652–36663 (2023)
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023)
2023
-
[20]
Aligning Text-to-Image Models using Human Feedback
Lee, K., Liu, H., Ryu, M., Watkins, O., Du, Y., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Gu, S.S.: Aligning text-to-image models using human feedback. arXiv preprint arXiv:2302.12192 (2023)
work page internal anchor Pith review arXiv 2023
-
[21]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Li, J., Cui, Y., Huang, T., Ma, Y., Fan, C., Yang, M., Zhong, Z.: Mixgrpo: Unlock- ing flow-based grpo efficiency with mixed ode-sde. arXiv preprint arXiv:2507.21802 (2025)
work page internal anchor Pith review arXiv 2025
-
[22]
arXiv preprint arXiv:2509.06040 (2025) 2, 3
Li, Y., Wang, Y., Zhu, Y., Zhao, Z., Lu, M., She, Q., Zhang, S.: Branchgrpo: Stable and efficient grpo with structured branching in diffusion models. arXiv preprint arXiv:2509.06040 (2025)
-
[23]
Li, Z., Liu, Z., Zhang, Q., Lin, B., Wu, F., Yuan, S., Yan, Z., Ye, Y., Yu, W., Niu, Y., et al.: Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback. arXiv preprint arXiv:2510.16888 (2025)
-
[24]
arXiv preprint arXiv:2402.13929 (2024) 5
Lin, S., Wang, A., Yang, X.: Sdxl-lightning: Progressive adversarial diffusion dis- tillation. arXiv preprint arXiv:2402.13929 (2024)
-
[25]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
arXiv preprint arXiv:2511.22677 (2025) 4, 5
Liu, D., Gao, P., Liu, D., Du, R., Li, Z., Wu, Q., Jin, X., Cao, S., Zhang, S., Li, H., et al.: Decoupled dmd: Cfg augmentation as the spear, distribution matching as the shield. arXiv preprint arXiv:2511.22677 (2025)
-
[27]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., Zhang, D., Ouyang, W.: Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470 (2025)
work page internal anchor Pith review arXiv 2025
-
[28]
In: The Twelfth Interna- tional Conference on Learning Representations (2023) GDMD 17
Liu, X., Zhang, X., Ma, J., Peng, J., et al.: Instaflow: One step is enough for high-quality diffusion-based text-to-image generation. In: The Twelfth Interna- tional Conference on Learning Representations (2023) GDMD 17
2023
-
[29]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Lu, C., Song, Y.: Simplifying, stabilizing and scaling continuous-time consistency models. arXiv preprint arXiv:2410.11081 (2024)
work page internal anchor Pith review arXiv 2024
-
[30]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency mod- els: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023)
work page internal anchor Pith review arXiv 2023
-
[31]
Advances in Neural Information Processing Systems36, 76525–76546 (2023)
Luo, W., Hu, T., Zhang, S., Sun, J., Li, Z., Zhang, Z.: Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models. Advances in Neural Information Processing Systems36, 76525–76546 (2023)
2023
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Luo, Y., Hu, T., Sun, J., Cai, Y., Tang, J.: Learning few-step diffusion models by trajectory distribution matching. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17719–17728 (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Nguyen, T.H., Tran, A.: Swiftbrush: One-step text-to-image diffusion model with variational score distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7807–7816 (2024)
2024
-
[34]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review arXiv 2023
-
[35]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review arXiv 2022
-
[36]
Advances in neural information processing systems37, 117340–117362 (2024)
Ren, Y., Xia, X., Lu, Y., Zhang, J., Wu, J., Xie, P., Wang, X., Xiao, X.: Hyper-sd: Trajectory segmented consistency model for efficient image synthesis. Advances in neural information processing systems37, 117340–117362 (2024)
2024
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[38]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[39]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512 (2022)
work page internal anchor Pith review arXiv 2022
-
[40]
In: SIGGRAPH Asia 2024 Conference Papers
Sauer, A., Boesel, F., Dockhorn, T., Blattmann, A., Esser, P., Rombach, R.: Fast high-resolution image synthesis with latent adversarial diffusion distillation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[41]
In: European Conference on Computer Vision
Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distilla- tion. In: European Conference on Computer Vision. pp. 87–103. Springer (2024)
2024
-
[42]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[43]
In: International conference on machine learning
Schulman, J., Levine, S., Abbeel, P., Jordan, M., Moritz, P.: Trust region policy optimization. In: International conference on machine learning. pp. 1889–1897. PMLR (2015)
2015
-
[44]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y., et al.: Seedream 4.0: Toward next-generation multimodal image generation. arXiv preprint arXiv:2509.20427 (2025)
work page internal anchor Pith review arXiv 2025
-
[46]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024) 18 Linwei Dong et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models (2023)
2023
-
[48]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8228–8238 (2024)
2024
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, H., Du, X., Li, J., Yeh, R.A., Shakhnarovich, G.: Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12619– 12629 (2023)
2023
-
[51]
Wang, J., Liang, J., Liu, J., Liu, H., Liu, G., Zheng, J., Pang, W., Ma, A., Xie, Z., Wang, X., et al.: Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping. arXiv preprint arXiv:2510.22319 (2025)
-
[52]
Advances in neural information processing systems36, 8406–8441 (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems36, 8406–8441 (2023)
2023
-
[53]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
work page internal anchor Pith review arXiv 2023
-
[54]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[55]
arXiv preprint arXiv:2509.25050 , year=
Xue, S., Ge, C., Zhang, S., Li, Y., Ma, Z.M.: Advantage weighted matching: Align- ing rl with pretraining in diffusion models. arXiv preprint arXiv:2509.25050 (2025)
-
[56]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al.: Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818 (2025)
work page internal anchor Pith review arXiv 2025
-
[57]
Advances in neural information processing systems37, 47455–47487 (2024)
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024)
2024
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6613– 6623 (2024)
2024
-
[59]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Zheng, K., Chen, H., Ye, H., Wang, H., Zhang, Q., Jiang, K., Su, H., Ermon, S., Zhu, J., Liu, M.Y.: Diffusionnft: Online diffusion reinforcement with forward process. arXiv preprint arXiv:2509.16117 (2025)
work page internal anchor Pith review arXiv 2025
-
[60]
In: Forty-first International Conference on Machine Learning (2024)
Zhou, M., Zheng, H., Wang, Z., Yin, M., Huang, H.: Score identity distillation: Ex- ponentially fast distillation of pretrained diffusion models for one-step generation. In: Forty-first International Conference on Machine Learning (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.