Recognition: unknown
Cell-Based Representation of Relational Binding in Language Models
Pith reviewed 2026-05-10 02:16 UTC · model grok-4.3
The pith
Large language models bind entities to relations by retrieving attributes from cells in a low-dimensional activation subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
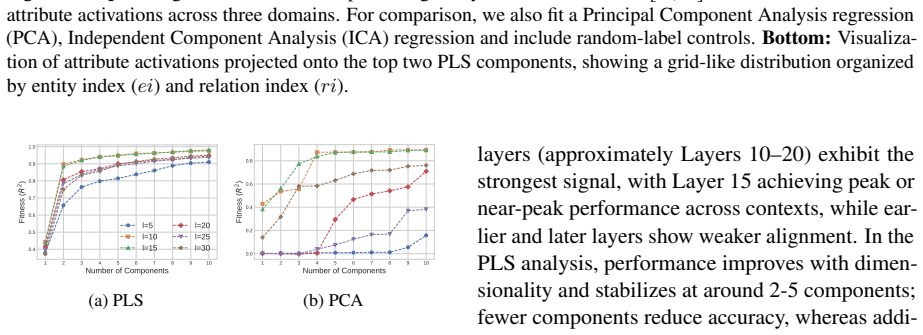
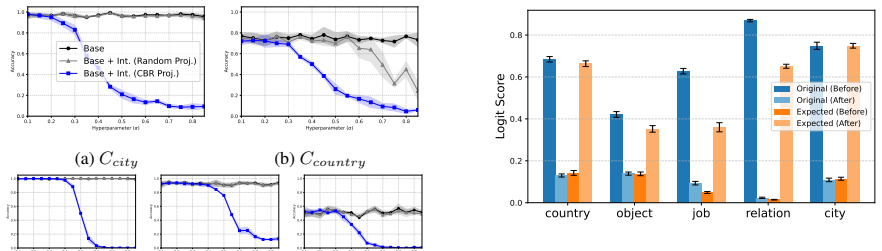
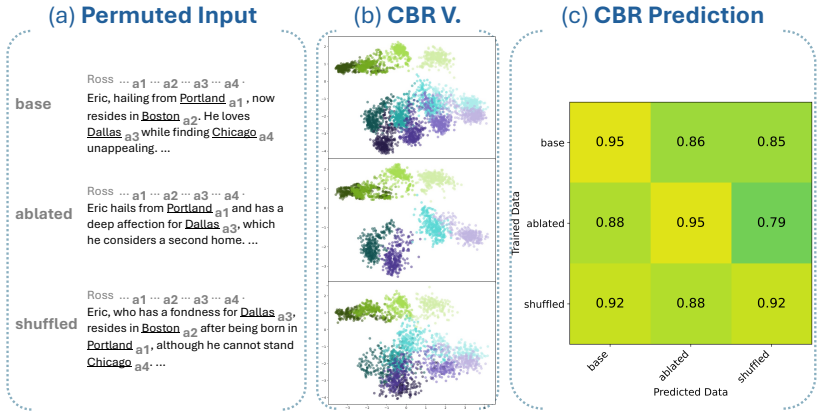
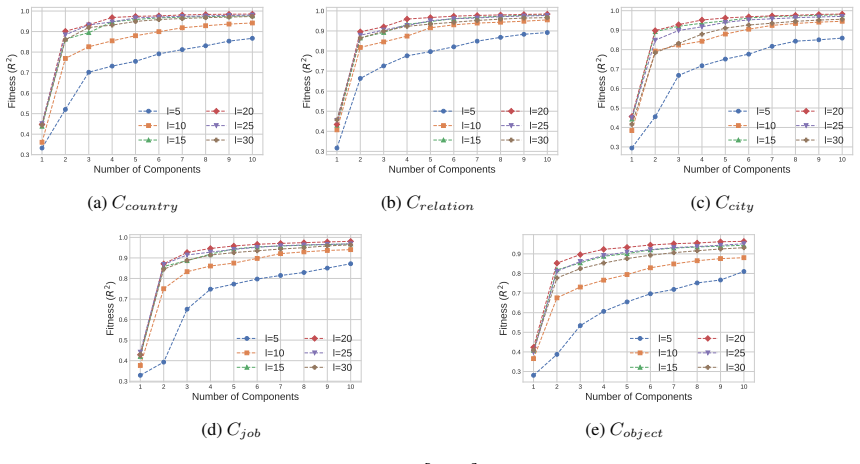
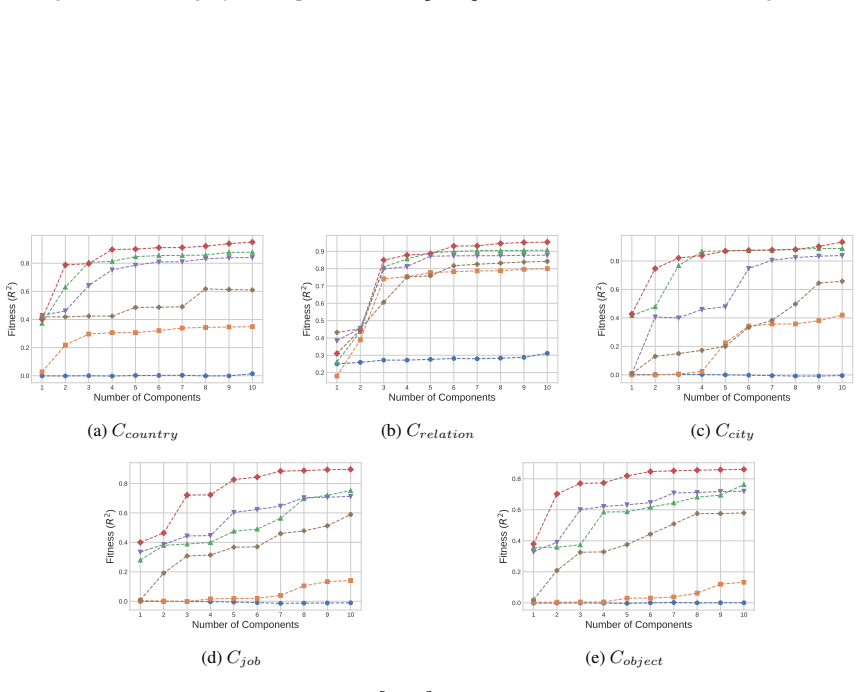
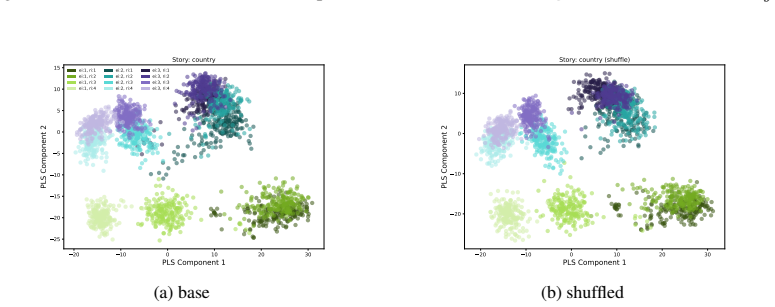
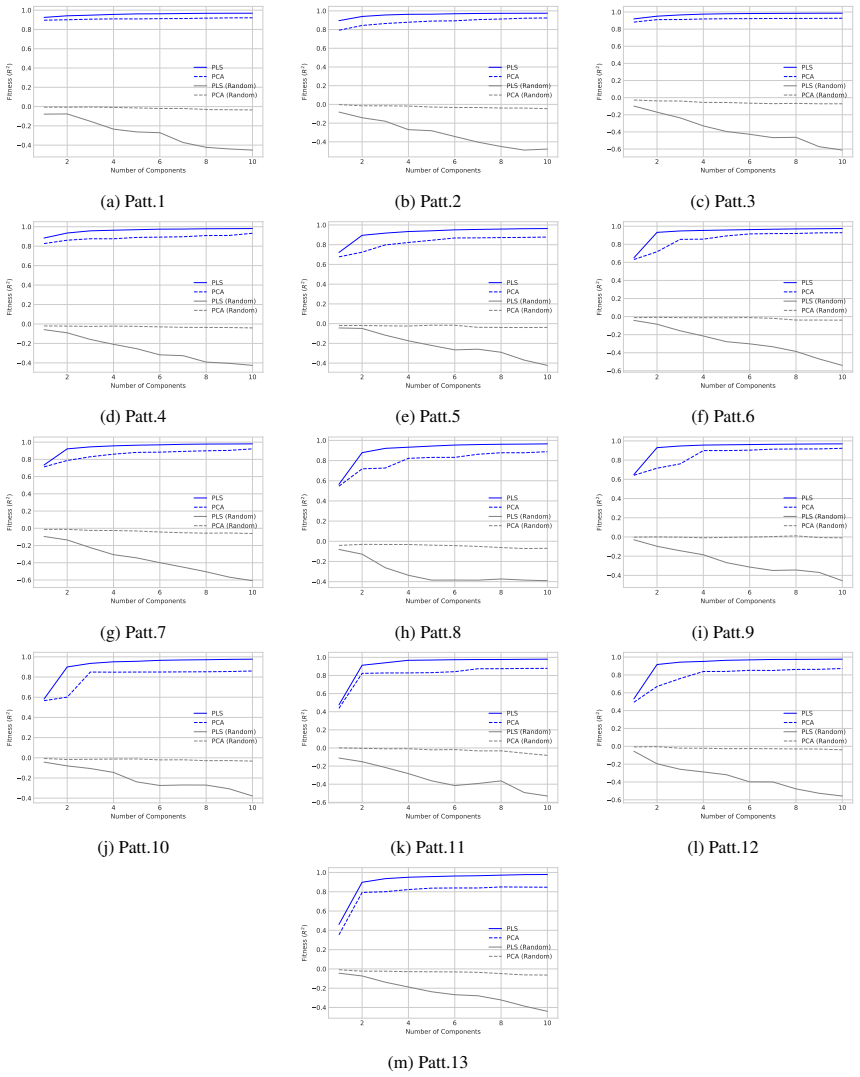
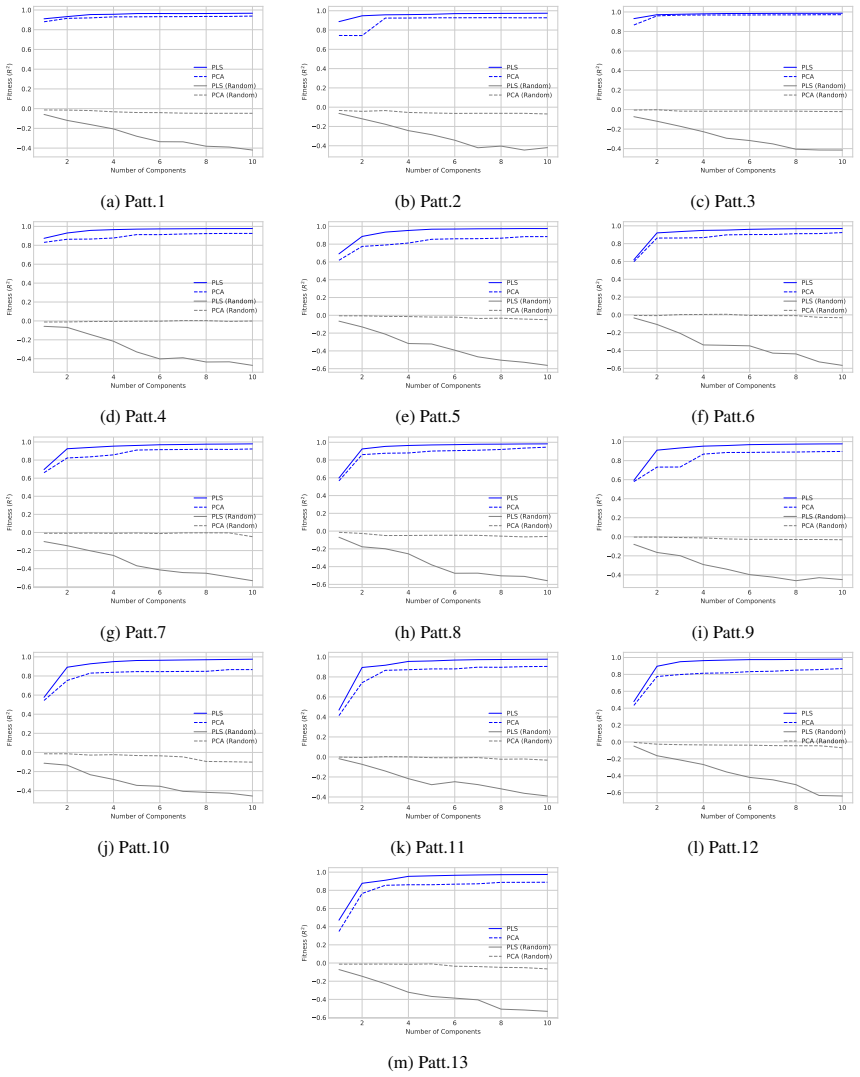
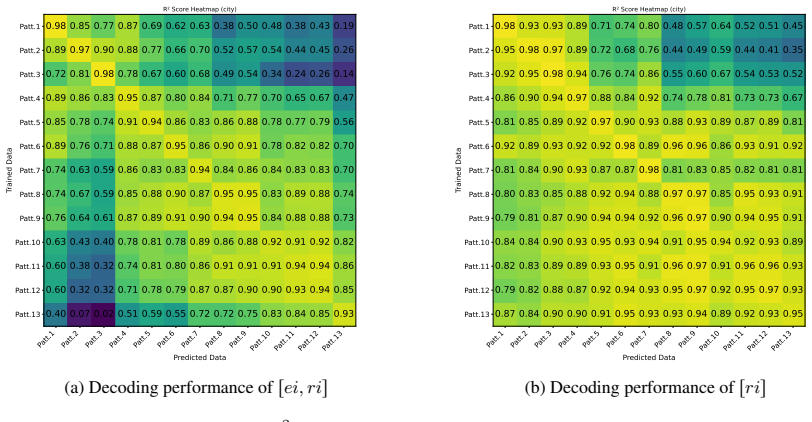
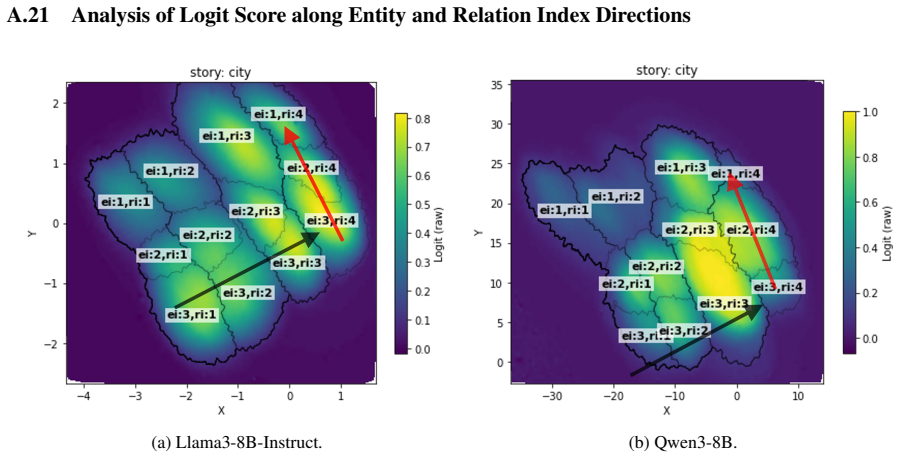
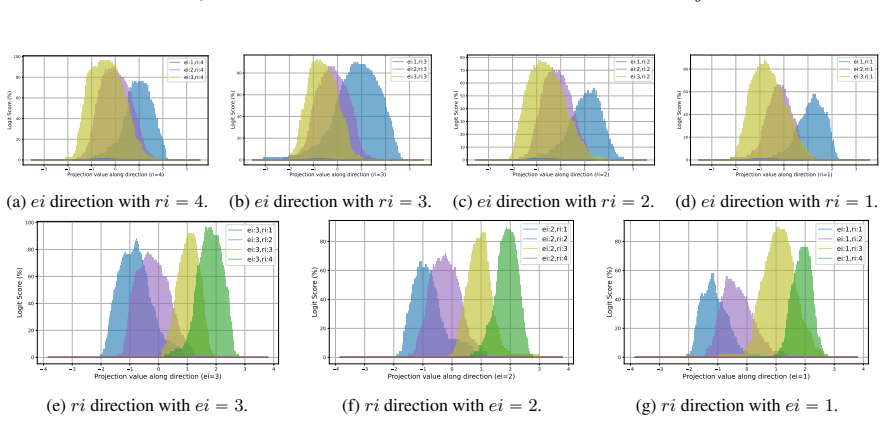
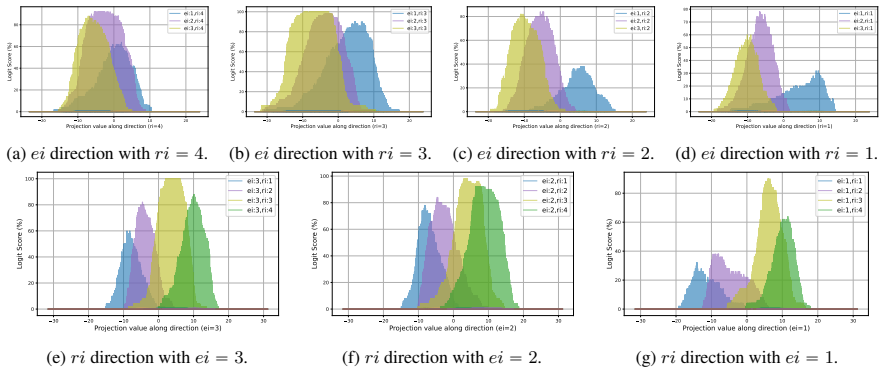
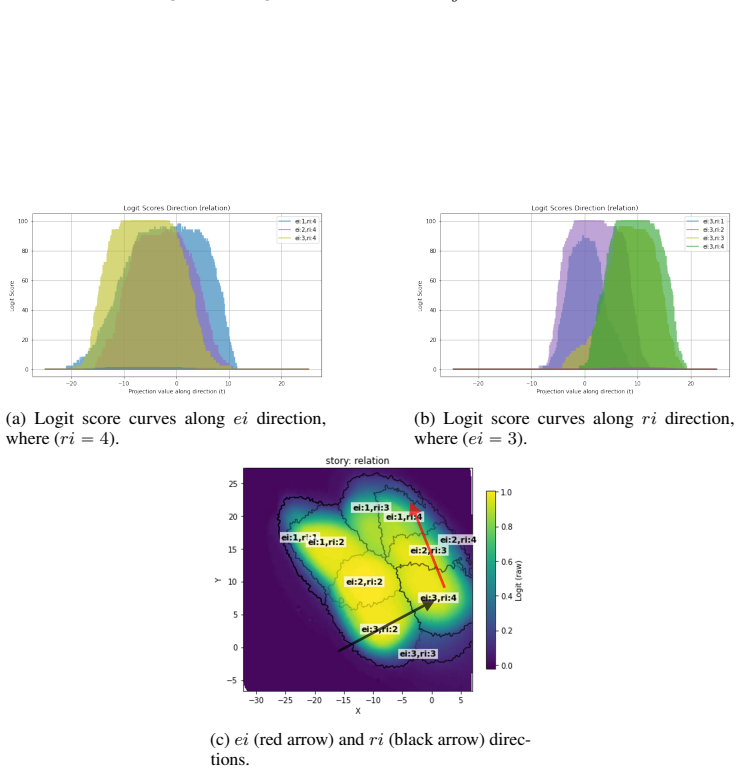
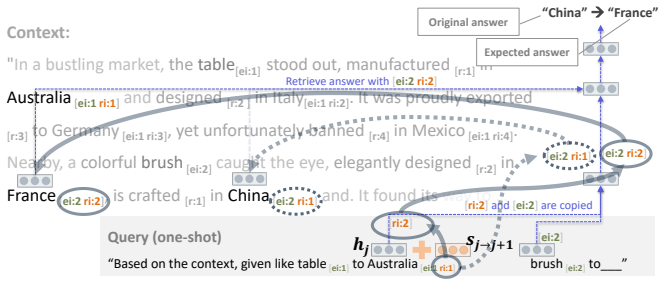
LLMs encode discourse-level relational binding via a Cell-based Binding Representation (CBR): a low-dimensional linear subspace in which each cell corresponds to an entity-relation index pair, and bound attributes are retrieved from the corresponding cell during inference. Using controlled multi-sentence data with entity and relation indices, the subspace is identified by decoding these indices from attribute-token activations with Partial Least Squares regression. The indices form a grid-like geometry in the projected space, and context-specific CBR representations are related by translation vectors in activation space. Activation patching shows that manipulating this subspace changes the (
What carries the argument
Cell-based Binding Representation (CBR): a low-dimensional linear subspace of model activations divided into cells, each holding information for one entity-relation index pair from which attributes are retrieved.
If this is right
- Entity and relation indices remain linearly decodable from activations inside the identified subspace across domains and model families.
- The subspace exhibits a stable grid-like geometry that supports consistent binding.
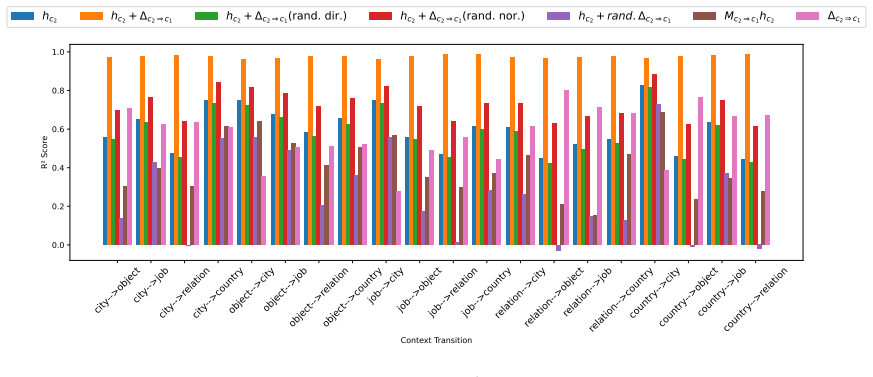
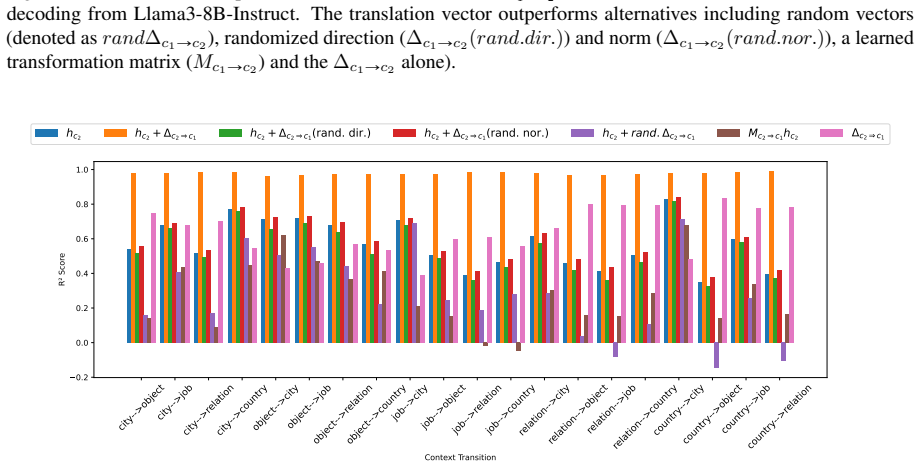
- Representations of the same bindings shift between contexts by fixed translation vectors in activation space.
- Targeted perturbation of the subspace produces predictable changes in the model's relational outputs.
Where Pith is reading between the lines
- If the cell structure is general, models could improve handling of long discourses simply by allocating more dimensions to this subspace.
- The translation vectors point to a possible route for transferring learned bindings to new contexts without retraining the entire model.
- Interventions that edit or enlarge this subspace might be used to debug or strengthen relational reasoning in existing systems.
Load-bearing premise
That linear decodability of entity-relation indices from the subspace plus the effects of activation patching show the model actually uses this cell structure for binding in ordinary inference rather than the subspace being a correlated side effect of the controlled experimental data.
What would settle it
Failure to decode the entity-relation indices or absence of any change in relational predictions when the subspace is patched on a new collection of natural, unscripted discourses would falsify the claim.
Figures






























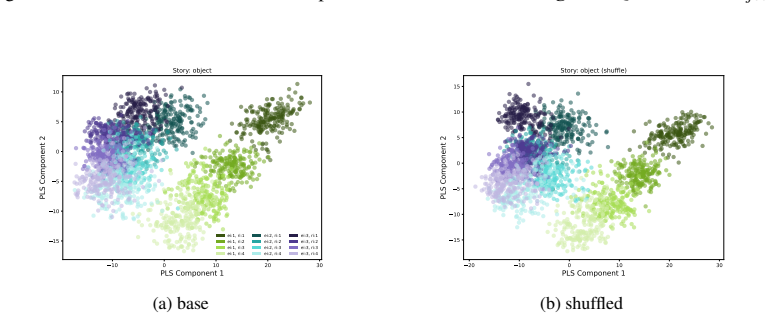
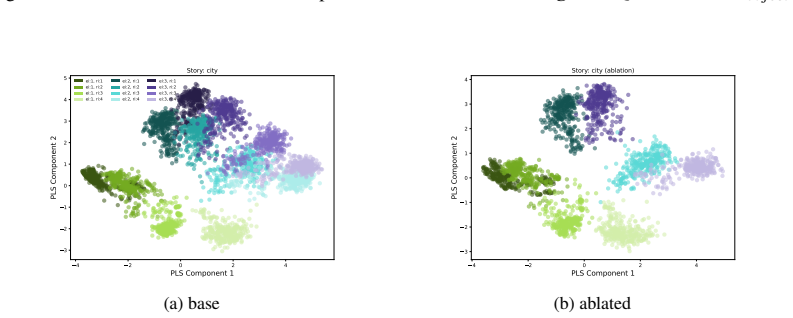
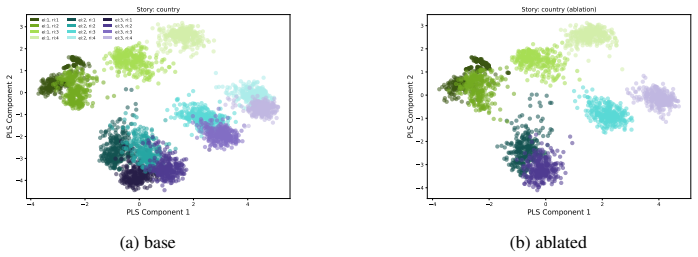






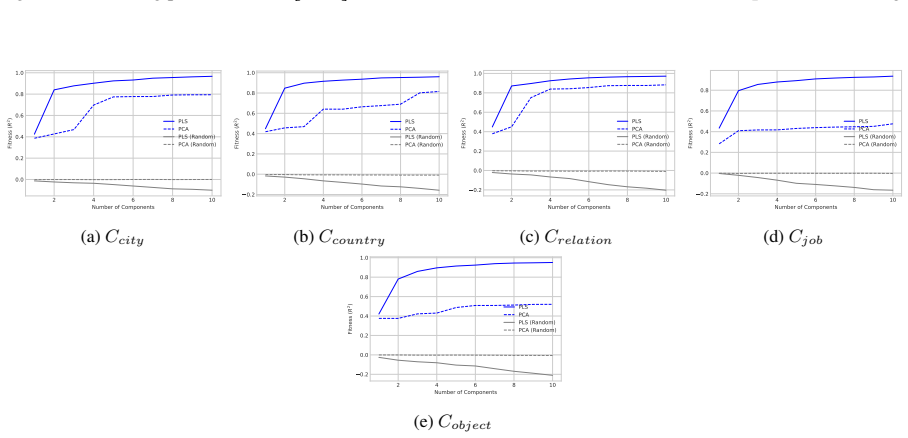


































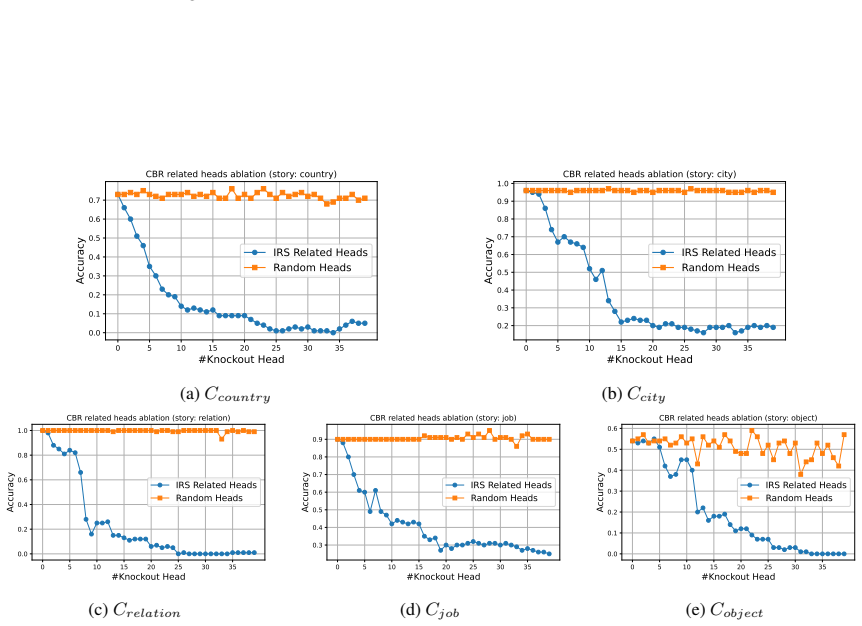

read the original abstract
Understanding a discourse requires tracking entities and the relations that hold between them. While Large Language Models (LLMs) perform well on relational reasoning, the mechanism by which they bind entities, relations, and attributes remains unclear. We study discourse-level relational binding and show that LLMs encode it via a Cell-based Binding Representation (CBR): a low-dimensional linear subspace in which each ``cell'' corresponds to an entity--relation index pair, and bound attributes are retrieved from the corresponding cell during inference. Using controlled multi-sentence data annotated with entity and relation indices, we identify the CBR subspace by decoding these indices from attribute-token activations with Partial Least Squares regression. Across domains and two model families, the indices are linearly decodable and form a grid-like geometry in the projected space. We further find that context-specific CBR representations are related by translation vectors in activation space, enabling cross-context transfer. Finally, activation patching shows that manipulating this subspace systematically changes relational predictions and that perturbing it disrupts performance, providing causal evidence that LLMs rely on CBR for relational binding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLMs encode discourse-level relational binding via a Cell-based Binding Representation (CBR): a low-dimensional linear subspace in which each cell corresponds to an entity-relation index pair and bound attributes are retrieved from the corresponding cell. Using controlled multi-sentence discourses annotated with entity and relation indices, the authors identify the CBR subspace via Partial Least Squares regression on attribute-token activations. They report that the indices are linearly decodable and exhibit grid-like geometry in the projected space, that context-specific CBR representations are related by translation vectors, and that activation patching of the subspace systematically alters relational predictions, providing causal evidence that LLMs rely on CBR for relational binding. Results are shown across domains and two model families.
Significance. If the central claim holds, the work provides a concrete mechanistic hypothesis for relational binding in LLMs, moving beyond generic linear probes to a structured, cell-based representation that supports both decoding and causal intervention. Strengths include the use of controlled annotated data to isolate the mechanism, the geometric analysis revealing grid structure and translation vectors for cross-context transfer, and the activation patching experiments that supply causal evidence within the tested setting. These elements together offer converging empirical support that could inform interpretability methods and targeted improvements to discourse reasoning in language models.
major comments (2)
- [§5] §5 (activation patching): The patching interventions that zero or shift the identified subspace and alter relational outputs are performed exclusively inside the controlled, annotated data distribution used to locate the CBR via PLS. This leaves open whether the subspace functions as the binding mechanism on ordinary unannotated text whose entity-relation structure is implicit rather than explicitly constructed to match the probe labeling scheme.
- [§4] §4 (subspace identification and geometry): Linear decodability and grid geometry are demonstrated on data whose entity-relation indices were explicitly annotated and used as regression targets. Without controls that permute the index labels or evaluate the same subspace on natural discourses lacking such annotations, it remains possible that the observed structure is an artifact of the labeling procedure rather than the representation actually used for binding during inference.
minor comments (2)
- [Methods] The exact method for choosing subspace dimensionality (listed as a free parameter) and any accompanying ablation or cross-validation results should be reported in the methods section to allow readers to assess sensitivity.
- [Figure 2 / §4.1] Figure captions and the geometry analysis section would benefit from quantitative metrics (e.g., grid regularity scores or nearest-neighbor consistency) in addition to the visual projections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help sharpen the scope of our claims about Cell-Based Binding Representations. We address each major point below, offering the strongest honest defense of the current evidence while noting where revisions can strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (activation patching): The patching interventions that zero or shift the identified subspace and alter relational outputs are performed exclusively inside the controlled, annotated data distribution used to locate the CBR via PLS. This leaves open whether the subspace functions as the binding mechanism on ordinary unannotated text whose entity-relation structure is implicit rather than explicitly constructed to match the probe labeling scheme.
Authors: We agree that the activation patching experiments are performed exclusively on the controlled, annotated discourses. This design is required to enable precise targeting of specific entity-relation index pairs and to isolate the effect of the subspace from other factors. The systematic changes in relational predictions upon zeroing or shifting the subspace supply causal evidence that the identified CBR is used for binding within these discourses. Extending the same interventions to ordinary unannotated text would require new methods to locate the relevant cells without explicit labels and is left for future work. revision: no
-
Referee: [§4] §4 (subspace identification and geometry): Linear decodability and grid geometry are demonstrated on data whose entity-relation indices were explicitly annotated and used as regression targets. Without controls that permute the index labels or evaluate the same subspace on natural discourses lacking such annotations, it remains possible that the observed structure is an artifact of the labeling procedure rather than the representation actually used for binding during inference.
Authors: The annotations are used only as regression targets to identify the subspace; the grid geometry and translation vectors are emergent properties of the model's activations. Their consistency across domains and model families, together with the functional role shown by patching, makes a pure labeling artifact unlikely. To address the concern directly, we will add label-permutation controls in the revision to confirm that the observed structure and decodability do not arise from the specific annotation scheme. revision: partial
Circularity Check
No significant circularity: empirical measurements and interventions are independent of fitted inputs
full rationale
The paper identifies the proposed CBR subspace via PLS regression on attribute-token activations from specially constructed annotated discourses, then reports linear decodability, grid geometry, translation vectors, and causal effects from activation patching. None of these steps reduce by the paper's own equations or self-citations to a fitted quantity renamed as a prediction; the central claim rests on measured decodability and intervention outcomes rather than any self-definitional loop or load-bearing self-citation. The work is self-contained against external benchmarks and contains no instances of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- subspace dimensionality
axioms (2)
- domain assumption Internal activations of LLMs contain information about entity and relation indices that is linearly extractable
- domain assumption The controlled multi-sentence texts with explicit entity-relation indices elicit the same binding mechanisms used in natural language
invented entities (1)
-
Cell-based Binding Representation (CBR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Notes from the linguistic underground , pages=
Discourse referents , author=. Notes from the linguistic underground , pages=. 1976 , publisher=
1976
-
[9]
Semantics Critical Concepts in Linguistics , pages=
File change semantics and the familiarity theory of definiteness , author=. Semantics Critical Concepts in Linguistics , pages=
-
[10]
Cognition , volume=
Connectionism and cognitive architecture: A critical analysis , author=. Cognition , volume=. 1988 , publisher=
1988
-
[11]
Current opinion in neurobiology , volume=
The binding problem , author=. Current opinion in neurobiology , volume=. 1996 , publisher=
1996
-
[12]
PLS-regression: a basic tool of chemometrics Chemometr , author=. Intell. Lab , volume=
-
[13]
Journal of cognitive neuroscience , volume=
When peanuts fall in love: N400 evidence for the power of discourse , author=. Journal of cognitive neuroscience , volume=. 2006 , publisher=
2006
-
[14]
Computational Linguistics , volume=
Modeling local coherence: An entity-based approach , author=. Computational Linguistics , volume=. 2008 , publisher=
2008
-
[15]
Handbook of Philosophical Logic: Volume 15 , pages=
Discourse representation theory , author=. Handbook of Philosophical Logic: Volume 15 , pages=. 2010 , publisher=
2010
-
[16]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[17]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Knowledge neurons in pretrained transformers , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[19]
arXiv preprint arXiv:2109.04727 , year=
A simple and effective method to eliminate the self language bias in multilingual representations , author=. arXiv preprint arXiv:2109.04727 , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
Interpretability at scale: Identifying causal mechanisms in alpaca , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Dissecting recall of factual associations in auto-regressive language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[22]
arXiv preprint arXiv:2308.09124 , year=
Linearity of relation decoding in transformer language models , author=. arXiv preprint arXiv:2308.09124 , year=
-
[23]
Probing for the Usage of Grammatical Number
Lasri, Karim and Pimentel, Tiago and Lenci, Alessandro and Poibeau, Thierry and Cotterell, Ryan. Probing for the Usage of Grammatical Number. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.603
-
[24]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Entity tracking in language models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
How do language models bind entities in context? , author=. arXiv preprint arXiv:2310.17191 , year=
-
[26]
A mechanism for solving relational tasks in transformer language models , author=
-
[27]
Fine-tuning enhances existing mechanisms: A case study on entity tracking
Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking , author=. arXiv preprint arXiv:2402.14811 , year=
-
[28]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Monotonic representation of numeric attributes in language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[29]
The Hydra Effect: Emergent Self-repair in Language Model Computations , journal =
The hydra effect: Emergent self-repair in language model computations , author=. arXiv preprint arXiv:2307.15771 , year=
-
[30]
Advances in neural information processing systems , volume=
Investigating gender bias in language models using causal mediation analysis , author=. Advances in neural information processing systems , volume=
-
[31]
arXiv preprint arXiv:2210.13382 , year=
Emergent world representations: Exploring a sequence model trained on a synthetic task , author=. arXiv preprint arXiv:2210.13382 , year=
-
[32]
arXiv preprint arXiv:2301.06758 , year=
Tracing and Manipulating Intermediate Values in Neural Math Problem Solvers , author=. arXiv preprint arXiv:2301.06758 , year=
-
[33]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small , author=. arXiv preprint arXiv:2211.00593 , year=
work page internal anchor Pith review arXiv
-
[34]
Advances in Neural Information Processing Systems , volume=
Locating and editing factual associations in GPT , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
International Conference on Machine Learning , pages=
Inducing causal structure for interpretable neural networks , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[36]
Towards best practices of activation patching in language models: Metrics and methods , author=. arXiv preprint arXiv:2309.16042 , year=
-
[37]
Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Emergent linear representations in world models of self-supervised sequence models , author=. Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[38]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review arXiv
-
[39]
arXiv preprint arXiv:2310.15154 , year=
Linear representations of sentiment in large language models , author=. arXiv preprint arXiv:2310.15154 , year=
-
[40]
Steering Language Models With Activation Engineering
Activation addition: Steering language models without optimization , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review arXiv
-
[41]
Advances in Neural Information Processing Systems , volume=
Towards automated circuit discovery for mechanistic interpretability , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Language models represent space and time , author=. arXiv preprint arXiv:2310.02207 , year=
-
[43]
2023 , Eprint =
Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller ...
2023
-
[44]
arXiv preprint arXiv:2403.00745 , year=
AtP*: An efficient and scalable method for localizing LLM behaviour to components , author=. arXiv preprint arXiv:2403.00745 , year=
-
[45]
and Clark, Kevin and Hewitt, John and Khandelwal, Urvashi and Levy, Omer , year =
Manning, Christopher D. and Clark, Kevin and Hewitt, John and Khandelwal, Urvashi and Levy, Omer. Emergent linguistic structure in artificial neural networks trained by self-supervision. Proceedings of the National Academy of Sciences. 2020. doi:10.1073/pnas.1907367117
-
[46]
Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
Linguistic regularities in continuous space word representations , author=. Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
2013
-
[47]
Transactions of the Association for Computational Linguistics , volume=
A latent variable model approach to pmi-based word embeddings , author=. Transactions of the Association for Computational Linguistics , volume=. 2016 , publisher=
2016
-
[48]
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
work page internal anchor Pith review arXiv
-
[49]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The linear representation hypothesis and the geometry of large language models , author=. arXiv preprint arXiv:2311.03658 , year=
work page internal anchor Pith review arXiv
-
[50]
Monitoring latent world states in language models with propositional probes , author=. arXiv preprint arXiv:2406.19501 , year=
-
[51]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Representational analysis of binding in language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[52]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review arXiv
-
[53]
Proceedings of the third blackboxnlp workshop on analyzing and interpreting neural networks for NLP , pages=
Neural natural language inference models partially embed theories of lexical entailment and negation , author=. Proceedings of the third blackboxnlp workshop on analyzing and interpreting neural networks for NLP , pages=
-
[54]
Advances in Neural Information Processing Systems , volume=
Causal abstractions of neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[56]
Advances in Neural Information Processing Systems , volume=
How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Meaning and the Dynamics of Interpretation , pages=
A theory of truth and semantic representation , author=. Meaning and the Dynamics of Interpretation , pages=. 2013 , publisher=
2013
-
[58]
1982 , publisher=
The semantics of definite and indefinite noun phrases , author=. 1982 , publisher=
1982
-
[59]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Computational Geometry: An Introduction , author =
-
[62]
Haiyan Zhao, Heng Zhao, Bo Shen, Ali Payani, Fan Yang, and Mengnan Du
Beyond single concept vector: Modeling concept subspace in llms with gaussian distribution , author=. arXiv preprint arXiv:2410.00153 , year=
-
[63]
arXiv preprint arXiv:2506.02996 , year=
Linear Spatial World Models Emerge in Large Language Models , author=. arXiv preprint arXiv:2506.02996 , year=
-
[64]
arXiv preprint arXiv:2507.09709 , year=
Large language models encode semantics in low-dimensional linear subspaces , author=. arXiv preprint arXiv:2507.09709 , year=
-
[65]
The geometry of numerical reasoning: Language models compare numeric properties in linear subspaces , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2025
-
[66]
arXiv preprint arXiv:2503.09066 , year=
Probing latent subspaces in llm for ai security: Identifying and manipulating adversarial states , author=. arXiv preprint arXiv:2503.09066 , year=
-
[67]
and Millman, K
Harris, Charles R. and Millman, K. Jarrod and van der Walt, St. Array programming with. Nature , volume=
-
[68]
Scikit-learn: Machine Learning in
Pedregosa, Fabian and Varoquaux, Ga. Scikit-learn: Machine Learning in. Journal of Machine Learning Research , volume=
-
[69]
Paszke, Adam and Gross, Sam and Massa, Francisco and others , journal=
-
[70]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Transformers: State-of-the-Art Natural Language Processing , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2020
-
[71]
Computing in Science & Engineering , volume=
Matplotlib: A 2D Graphics Environment , author=. Computing in Science & Engineering , volume=
-
[72]
arXiv preprint arXiv:2406.19384 , year=
The remarkable robustness of llms: Stages of inference? , author=. arXiv preprint arXiv:2406.19384 , year=
-
[73]
A Formal Approach to Discourse Anaphora , editor =. 1979 , edition =. doi:10.4324/9781315403342 , isbn =
-
[74]
1983 , publisher=
Strategies of discourse comprehension , author=. 1983 , publisher=
1983
-
[75]
, author=
Situation models in language comprehension and memory. , author=. Psychological bulletin , volume=. 1998 , publisher=
1998
-
[76]
arXiv preprint arXiv:2510.06182 , year=
Mixing Mechanisms: How Language Models Retrieve Bound Entities In-Context , author=. arXiv preprint arXiv:2510.06182 , year=
-
[77]
Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
Revisiting DocRED-addressing the false negative problem in relation extraction , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.