Recognition: unknown
The Essence of Balance for Self-Improving Agents in Vision-and-Language Navigation
Pith reviewed 2026-05-10 03:03 UTC · model grok-4.3
The pith
Stability-Diversity Balance lets vision-and-language navigation agents self-improve reliably by generating and aggregating multiple consistent behavioral hypotheses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Self-improvement from policy-induced experience in VLN critically depends on balancing behavioral diversity and learning stability. SDB expands each decision step into multiple latent behavioral hypotheses by applying controlled shifts in the instruction-conditioned hidden states, then performs reliability-aware soft evaluation and aggregation to retain diverse yet instruction-consistent alternatives. An explicit regularizer constrains hypothesis interactions to prevent excessive drift or premature collapse, stabilizing self-improvement without discarding training signals.
What carries the argument
Stability-Diversity Balance (SDB), a plug-and-play mechanism that creates multiple latent behavioral hypotheses from controlled shifts in instruction-conditioned hidden states and aggregates them through reliability-aware soft evaluation plus an interaction regularizer.
If this is right
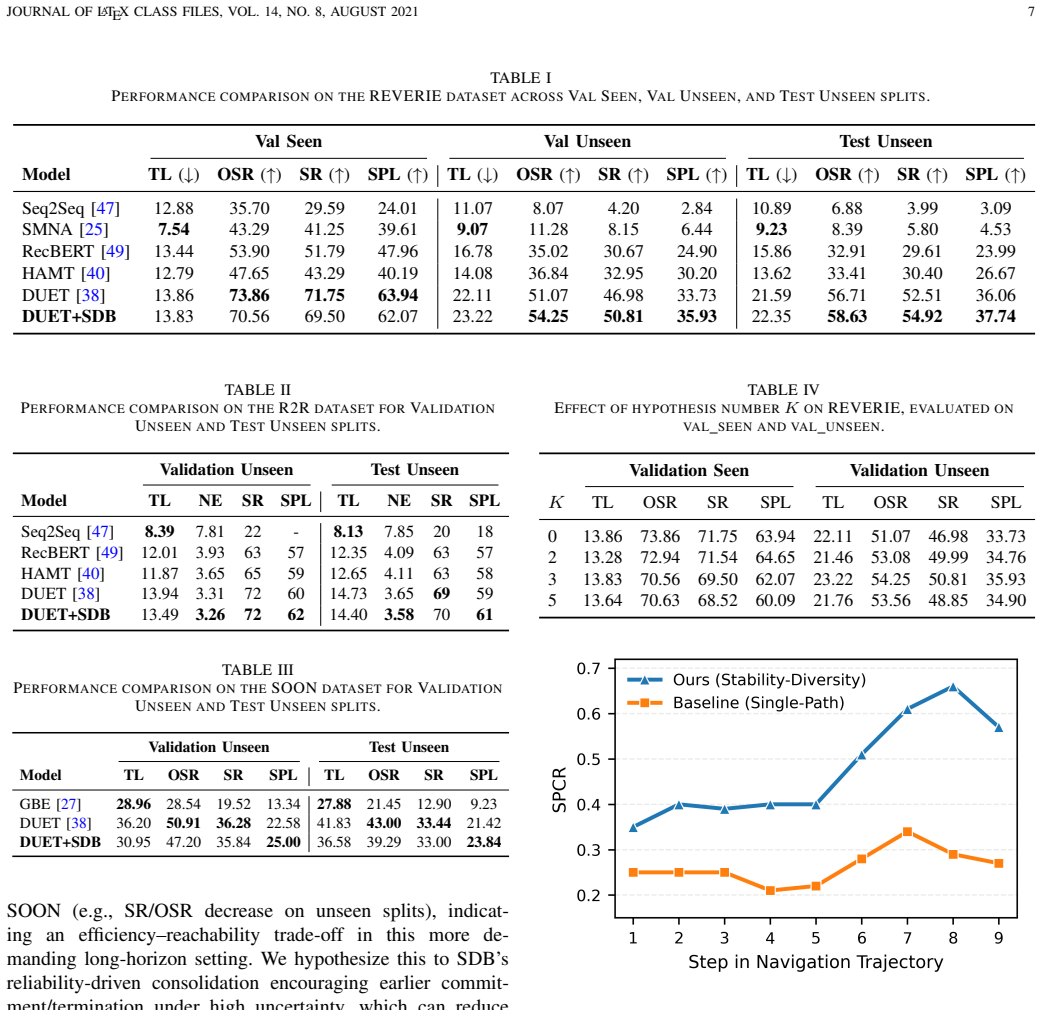
- Agents reach higher SPL (33.73 to 35.93) and OSR (51.07 to 54.25) on REVERIE val-unseen.
- Consistent performance gains appear on R2R and SOON as well.
- Self-improvement proceeds using only standard VLN action supervision.
- Hypothesis diversity is preserved without destabilizing the overall learning process.
Where Pith is reading between the lines
- The same hypothesis-generation approach might help stabilize self-improvement in other sequential decision domains such as robotic manipulation.
- Reducing the need for external human feedback could follow if the soft evaluation reliably filters poor hypotheses.
- Similar regularizers on hypothesis interactions may prove useful in multi-path planning or ensemble-based agent training.
Load-bearing premise
Controlled shifts in instruction-conditioned hidden states will reliably produce useful, instruction-consistent behavioral hypotheses whose reliability can be evaluated without introducing new sources of instability or bias in the self-improvement loop.
What would settle it
If SDB produces no gain or a drop in SPL and OSR on REVERIE val-unseen, or if training curves show increased instability compared to baselines, the claimed balance would not hold.
Figures




read the original abstract
In vision-and-language navigation (VLN), self-improvement from policy-induced experience, using only standard VLN action supervision, critically depends on balancing behavioral diversity and learning stability, which governs whether the agent can extract a reliable learning signal for improvement. Increasing behavioral diversity is necessary to expose alternative action hypotheses but can destabilize policy-induced learning signals, whereas overly conservative stability constraints suppress exploration and induce early commitment, making reliable self-improvement difficult. To address this challenge, we propose Stability-Diversity Balance (SDB), a plug-and-play mechanism for balanced self-improvement in VLN. SDB expands each decision step into multiple latent behavioral hypotheses by applying controlled shifts in the instruction-conditioned hidden states, and then performs reliability-aware soft evaluation and aggregation to retain diverse yet instruction-consistent alternatives during learning. An explicit regularizer further constrains hypothesis interactions, preventing excessive drift or premature collapse of hypothesis diversity and stabilizing self-improvement without discarding training signals. Experiments on R2R, SOON, and REVERIE show consistent improvements; for example, on REVERIE val-unseen, SDB improves SPL from 33.73 to 35.93 and OSR from 51.07 to 54.25.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Stability-Diversity Balance (SDB), a plug-and-play mechanism for self-improving agents in vision-and-language navigation (VLN). SDB expands each decision step into multiple latent behavioral hypotheses via controlled shifts in instruction-conditioned hidden states, performs reliability-aware soft evaluation and aggregation to retain diverse yet instruction-consistent alternatives, and applies an explicit regularizer to constrain hypothesis interactions and stabilize learning. Experiments on R2R, SOON, and REVERIE report consistent improvements, such as SPL rising from 33.73 to 35.93 and OSR from 51.07 to 54.25 on REVERIE val-unseen.
Significance. If the central mechanism proves robust, SDB could provide a practical, supervision-free way to manage the diversity-stability tradeoff in VLN self-improvement, with potential applicability as a modular addition to existing agents. The multi-benchmark evaluation and focus on a core challenge in the field are strengths. However, the modest gains and absence of detailed statistical validation or ablations in the description suggest the significance is incremental rather than foundational.
major comments (3)
- Abstract: the claim of consistent benchmark gains lacks error bars, ablation details, or a full derivation of how the soft evaluation avoids post-hoc selection bias; modest numerical improvements (e.g., SPL +2.2) could be sensitive to implementation choices not visible here.
- Method description: no equations or derivations are shown that reduce the claimed improvement to a fitted quantity defined by the method itself; the description frames SDB as an independent plug-and-play addition rather than a re-expression of prior results.
- §4 (Experiments): the weakest assumption—that controlled shifts in instruction-conditioned hidden states reliably produce useful, instruction-consistent behavioral hypotheses without introducing new instability or bias—requires explicit validation through ablations on shift magnitude, hypothesis count, and regularizer strength to support the self-improvement claims.
minor comments (1)
- Notation for the reliability-aware soft evaluation and aggregation steps could be clarified with explicit formulas to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity, empirical rigor, and methodological presentation, which we will address in the revision. We provide point-by-point responses below.
read point-by-point responses
-
Referee: Abstract: the claim of consistent benchmark gains lacks error bars, ablation details, or a full derivation of how the soft evaluation avoids post-hoc selection bias; modest numerical improvements (e.g., SPL +2.2) could be sensitive to implementation choices not visible here.
Authors: We agree that the abstract would benefit from better contextualization of the gains. In the revised version, we will update the abstract to explicitly reference the multi-run experimental results (including standard deviations across seeds) and key ablation findings reported in Section 4 and the appendix. The soft evaluation process is derived in Section 3 as a reliability-weighted aggregation using instruction-consistency scores, which avoids post-hoc bias by employing continuous soft probabilities rather than discrete selection; this is not a post-processing step but an integral part of the learning signal. Sensitivity analyses in the appendix confirm robustness to implementation variations, and we will highlight this more prominently. revision: partial
-
Referee: Method description: no equations or derivations are shown that reduce the claimed improvement to a fitted quantity defined by the method itself; the description frames SDB as an independent plug-and-play addition rather than a re-expression of prior results.
Authors: The full method section provides a step-by-step description of hypothesis expansion, aggregation, and regularization, but we acknowledge the value of explicit equations. We will add formal definitions in the revision, including the shift operation on hidden states, the soft aggregation formula as a weighted sum of hypothesis policies, and the regularizer term, showing how these define the optimized quantities driving the gains. SDB is intentionally presented as a modular, plug-and-play mechanism to enable easy integration with existing VLN agents; it is not a re-expression of prior results but introduces a new balance mechanism. We will clarify this distinction while retaining the modular framing. revision: yes
-
Referee: §4 (Experiments): the weakest assumption—that controlled shifts in instruction-conditioned hidden states reliably produce useful, instruction-consistent behavioral hypotheses without introducing new instability or bias—requires explicit validation through ablations on shift magnitude, hypothesis count, and regularizer strength to support the self-improvement claims.
Authors: We agree that targeted ablations are essential to substantiate this assumption. While the current results show consistent gains across three benchmarks, the revised manuscript will include a new ablation subsection in §4 varying shift magnitude, hypothesis count, and regularizer strength. These will report auxiliary metrics such as hypothesis consistency with instructions and policy update variance to demonstrate that the shifts yield useful, stable hypotheses without added bias or instability, directly supporting the self-improvement claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes SDB as an independent plug-and-play mechanism for VLN self-improvement: it expands decision steps into latent behavioral hypotheses via controlled shifts in instruction-conditioned hidden states, applies reliability-aware soft evaluation and aggregation, and adds an explicit regularizer to constrain interactions. This is presented as a design choice addressing the diversity-stability tradeoff, with empirical gains reported on R2R/SOON/REVERIE benchmarks. No equations, derivations, or load-bearing steps are shown that reduce the claimed improvements to fitted quantities defined by the method itself, self-citations, or renamings of prior results. The central claims remain self-contained as an architectural addition rather than tautological re-expressions of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lifelong learning: A survey,
S. Thrun, “Lifelong learning: A survey,”Learning to Learn, pp. 181– 209, 1998. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
1998
-
[2]
Learning to reinforcement learn
J. X. Wang, Z. Kurth-Nelson, D. Tirumala, H. Soyer, J. Z. Leibo, R. Munoz, C. Blundell, D. Kumaran, and M. Botvinick, “Learning to reinforcement learn,”arXiv preprint arXiv:1611.05763, 2016
work page Pith review arXiv 2016
-
[3]
Temporal Consistency Learning of Inter-Frames for Video Super-Resolution,
M. Liu, S. Jin, C. Yao, C. Lin, and Y . Zhao, “Temporal Consistency Learning of Inter-Frames for Video Super-Resolution,”IEEE Trans. Circuits Syst. Video Technol., vol. 33, no. 4, pp. 1507–1520, 2023
2023
-
[4]
Multi-Temporal Ultra Dense Memory Network for Video Super-Resolution,
P. Yi, Z. Wang, K. Jiang, Z. Shao, and J. Ma, “Multi-Temporal Ultra Dense Memory Network for Video Super-Resolution,”IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 8, pp. 2503–2516, 2020, doi: 10.1109/TCSVT.2019.2925844
-
[5]
Reliable and Dynamic Appearance Modeling and Label Consistency Enforcing for Fast and Coherent Video Object Segmentation With the Bilateral Grid,
Y . Gui, Y . Tian, D.-J. Zeng, Z. Xie, and Y . Cai, “Reliable and Dynamic Appearance Modeling and Label Consistency Enforcing for Fast and Coherent Video Object Segmentation With the Bilateral Grid,”IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 12, pp. 4781–4795, 2020
2020
-
[6]
Semi-Supervised Video Object Segmentation via Learning Object-Aware Global-Local Cor- respondence,
J. Fan, B. Liu, K. Zhang, and Q. Liu, “Semi-Supervised Video Object Segmentation via Learning Object-Aware Global-Local Cor- respondence,”IEEE Trans. Circuits Syst. Video Technol., 2022, doi: 10.1109/TCSVT.2021.3098118
-
[7]
Flow-Edge Guided Unsupervised Video Object Segmentation,
Y . Zhou, X. Xu, F. Shen, X. Zhu, and H. T. Shen, “Flow-Edge Guided Unsupervised Video Object Segmentation,”IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 12, pp. 8116–8127, 2022
2022
-
[8]
Separable Structure Modeling for Semi-Supervised Video Object Segmentation,
W. Zhu, J. Li, J. Lu, and J. Zhou, “Separable Structure Modeling for Semi-Supervised Video Object Segmentation,”IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 1, pp. 330–344, 2022
2022
-
[9]
View-Action Representation Learning for Active First-Person Vision,
C. Oh and A. Cavallaro, “View-Action Representation Learning for Active First-Person Vision,”IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 2, pp. 480–491, 2021, doi: 10.1109/TCSVT.2020.2987562
-
[10]
Divide-and- Conquer Completion Network for Video Inpainting,
Z. Wu, C. Sun, H. Xuan, K. Zhang, and Y . Yan, “Divide-and- Conquer Completion Network for Video Inpainting,”IEEE Trans. Cir- cuits Syst. Video Technol., vol. 33, no. 6, pp. 2753–2766, 2023, doi: 10.1109/TCSVT.2022.3225911
-
[11]
Temporal and Inter-View Consistent Error Concealment Technique for Multiview Plus Depth Video,
S. Khattak, T. Maugey, R. Hamzaoui, S. Ahmad, and P. Frossard, “Temporal and Inter-View Consistent Error Concealment Technique for Multiview Plus Depth Video,”IEEE Trans. Circuits Syst. Video Technol., vol. 26, no. 5, pp. 829–840, 2016, doi: 10.1109/TCSVT.2015.2418631
-
[12]
Temporally Consistent Referring Video Object Segmentation With Hybrid Memory,
B. Miao, M. Bennamoun, Y . Gao, M. Shah, and A. Mian, “Temporally Consistent Referring Video Object Segmentation With Hybrid Memory,” IEEE Trans. Circuits Syst. Video Technol., 2024
2024
-
[13]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. van den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProc. CVPR, 2018
2018
-
[14]
Chasing Ghosts: Instruction Following as Bayesian State Tracking,
P. Anderson, A. Shrivastava, D. Parikh, D. Batra, and S. Lee, “Chasing Ghosts: Instruction Following as Bayesian State Tracking,” inAdvances in Neural Information Processing Systems 32 (NeurIPS), 2019, pp. 369– 379
2019
-
[15]
Tactical rewind: Self-correction via backtracking in vision- and-language navigation,
L. Ke, X. Li, Y . Bisk, A. Holtzman, Z. Gan, J. Liu, J. Gao, Y . Choi, and S. Srinivasa, “Tactical rewind: Self-correction via backtracking in vision- and-language navigation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019
2019
-
[16]
EvolveNav: Self-Improving Embodied Reasoning for LLM-Based Vision-Language Navigation,
B. Lin, Y . Nie, K. L. Zai, Z. Wei, M. Han, R. Xu, M. Niu, J. Han, L. Lin, C. Lu, and others, “EvolveNav: Self-Improving Embodied Reasoning for LLM-Based Vision-Language Navigation,”arXiv preprint arXiv:2506.01551, 2025
-
[17]
The Role of Predictive Uncertainty and Diversity in Embodied AI and Robot Learning,
R. Senanayake, “The Role of Predictive Uncertainty and Diversity in Embodied AI and Robot Learning,”arXiv preprint arXiv:2405.03164, 2024
-
[18]
System Neural Diversity: Measuring Behavioral Heterogeneity in Multi-Agent Learning,
M. Bettini, A. Shankar, and A. Prorok, “System Neural Diversity: Measuring Behavioral Heterogeneity in Multi-Agent Learning,”arXiv preprint arXiv:2305.02128, 2023
-
[19]
Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation,
X. Wang, Q. Huang, A. Celikyilmaz, J. Gao, D. Shen, Y . Wang, W. Y . Wang, and L. Zhang, “Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019
2019
-
[20]
The curse of diversity in ensemble-based exploration,
Z. Lin, P. D’Oro, E. Nikishin, and A. Courville, “The curse of diversity in ensemble-based exploration,” inProc. ICLR, 2024
2024
-
[21]
Vision-and- Language Navigation: A Survey of Tasks, Methods, and Future Direc- tions,
J. Gu, E. Stefani, Q. Wu, J. Thomason, and X. Wang, “Vision-and- Language Navigation: A Survey of Tasks, Methods, and Future Direc- tions,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022, pp. 7606–7623
2022
-
[22]
Vision-Language Navigation: A Survey and Taxonomy,
W. Wu, T. Chang, and X. Li, “Vision-Language Navigation: A Survey and Taxonomy,”arXiv preprint arXiv:2108.11544, 2021
-
[23]
The Regretful Agent: Heuristic-Aided Navigation Through Progress Estimation,
C.-Y . Ma, Z. Wu, G. AlRegib, C. Xiong, and Z. Kira, “The Regretful Agent: Heuristic-Aided Navigation Through Progress Estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 6732–6740
2019
-
[24]
Beyond the nav-graph: Vision-and-language navigation in continuous environments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16, 2020
2020
-
[25]
Self-Monitoring Navigation Agent via Auxiliary Progress Estimation,
C.-Y . Ma, J. Lu, Z. Wu, G. AlRegib, Z. Kira, R. Socher, and C. Xiong, “Self-Monitoring Navigation Agent via Auxiliary Progress Estimation,” inProceedings of the International Conference on Learning Represen- tations (ICLR), 2019
2019
-
[26]
Room-Across- Room: Multilingual vision-and-language navigation with dense spa- tiotemporal grounding,
A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge, “Room-Across- Room: Multilingual vision-and-language navigation with dense spa- tiotemporal grounding,” inProc. EMNLP, 2020
2020
-
[27]
SOON: Scenario oriented object navigation with graph-based exploration,
F. Zhu, X. Liang, Y . Zhu, Q. Yu, X. Chang, and X. Liang, “SOON: Scenario oriented object navigation with graph-based exploration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 12689–12699
2021
-
[28]
REVERIE: Remote embodied visual referring expression in real indoor environments,
Y . Qi, Q. Wu, P. Anderson, X. Wang, W. Y . Wang, C. Shen, and A. van den Hengel, “REVERIE: Remote embodied visual referring expression in real indoor environments,” inProc. CVPR, 2020
2020
-
[29]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inProc. ICML, 2017
2017
-
[30]
Continual lifelong learning with neural networks: A review,
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter, “Continual lifelong learning with neural networks: A review,”Neural Networks, vol. 113, pp. 54–71, 2019
2019
-
[31]
Meta- learning in neural networks: A survey,
T. M. Hospedales, A. Antoniou, P. Micaelli, and A. J. Storkey, “Meta- learning in neural networks: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 9, pp. 5149–5169, 2022
2022
-
[32]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProc. Inter- national Conference on Artificial Intelligence and Statistics (AISTATS), 2011, pp. 627–635
2011
-
[33]
Scheduled sampling for sequence prediction with recurrent neural networks,
S. Bengio, O. Vinyals, N. Jaitly, and N. Shazeer, “Scheduled sampling for sequence prediction with recurrent neural networks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2015, pp. 1171– 1179
2015
-
[34]
Reinforcement and Imitation Learning via Interactive No-Regret Learning
S. Ross and J. A. Bagnell, “Reinforcement and imitation learning via interactive no-regret learning,”arXiv preprint arXiv:1406.5979, 2014
work page Pith review arXiv 2014
-
[35]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Deep exploration via bootstrapped DQN,
I. Osband, C. Blundell, A. Pritzel, and B. Van Roy, “Deep exploration via bootstrapped DQN,” inProc. NeurIPS, 2016
2016
-
[37]
Parameter space noise for exploration,
M. Plappert, R. Houthooft, P. Dhariwal, S. Sidor, R. Y . Chen, X. Chen, T. Asfour, P. Abbeel, and M. Andrychowicz, “Parameter space noise for exploration,” inProc. ICLR, 2018
2018
-
[38]
Think Deeply, Act Locally: Memory-Driven Transformers for Vision-and-Language Navigation,
X. Chen, Z. Liu, W. Bai, and S. K. Y . Lee, “Think Deeply, Act Locally: Memory-Driven Transformers for Vision-and-Language Navigation,” in Proceedings of CVPR, 2022
2022
-
[39]
Noisy networks for exploration,
M. Fortunato, M. G. Azar, B. Piot, J. Menick, M. Hessel, I. Osband, A. Graves, V . Mnih, R. Munos, D. Hassabis, O. Pietquin, C. Blundell, and S. Legg, “Noisy networks for exploration,” inProc. ICLR, 2018
2018
-
[40]
History aware multimodal transformer for vision-and-language navigation,
S. Chen, P. Guhur, C. Schmid, and I. Laptev, “History aware multimodal transformer for vision-and-language navigation,”Advances in neural information processing systems, 2021
2021
-
[41]
Hop+: History- enhanced and order-aware pre-training for vision-and-language naviga- tion,
Y . Qiao, Y . Qi, Y . Hong, Z. Yu, P. Wang, and Q. Wu, “Hop+: History- enhanced and order-aware pre-training for vision-and-language naviga- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[42]
Think global, act local: Dual-scale graph transformer for vision-and-language navigation,
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev, “Think global, act local: Dual-scale graph transformer for vision-and-language navigation,” inProc. CVPR, 2022
2022
-
[43]
On Evaluation of Embodied Navigation Agents
P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V . Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva, and oth- ers, “On evaluation of embodied navigation agents,”arXiv preprint arXiv:1807.06757, 2018
work page internal anchor Pith review arXiv 2018
-
[44]
Vision-and- language navigation via causal learning,
L. Wang, Z. He, R. Dang, M. Shen, C. Liu, and Q. Chen, “Vision-and- language navigation via causal learning,” inProc. CVPR, 2024
2024
-
[45]
NavGPT-2: Unleashing navigational reasoning capability for large vision-language models,
G. Zhou, Y . Hong, Z. Wang, X. E. Wang, and Q. Wu, “NavGPT-2: Unleashing navigational reasoning capability for large vision-language models,” inProc. ECCV, 2024
2024
-
[46]
Robust navigation with language pretraining and stochastic sampling,
X. Li, C. Li, Q. Xia, Y . Bisk, A. Celikyilmaz, J. Gao, N. Smith, and Y . Choi, “Robust navigation with language pretraining and stochastic sampling,”arXiv preprint arXiv:1909.02244, 2019
-
[47]
Vision-and-Language Navigation: JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 Interpreting Visually-Grounded Navigation Instructions in Real Envi- ronments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S¨underhauf, I.D. Reid, S. Gould, A. van den Hengel, “Vision-and-Language Navigation: JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 Interpreting Visually-Grounded Navigation Instructions in Real Envi- ronments,” in2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2...
2021
-
[48]
Speaker-follower models for vision-and-language navigation,
D. Fried, R. Hu, V . Cirik, A. Rohrbach, J. Andreas, L. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein, and T. Darrell, “Speaker-follower models for vision-and-language navigation,”Advances in neural infor- mation processing systems, 2018
2018
-
[49]
VLn BERT: A recurrent vision-and-language BERT for navigation,
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and S. Gould, “VLn BERT: A recurrent vision-and-language BERT for navigation,” inCVPR, pp. 1643–1653, 2021
2021
-
[50]
CR- former: Single-image cloud removal with focused Taylor attention,
Y . Wu, Y . Deng, S. Zhou, Y . Liu, W. Huang, and J. Wang, “CR- former: Single-image cloud removal with focused Taylor attention,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1– 14, 2024
2024
-
[51]
Event-Equalized Dense Video Captioning,
K. Wu, P. Li, J. Fu, Y . Li, Y . Wu, Y . Liu, J. Wang, and S. Zhou, “Event-Equalized Dense Video Captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 8417–8427
2025
-
[52]
Semantic-aware representation learning for homography estimation,
Y . Liu, Q. Huang, S. Hui, J. Fu, S. Zhou, K. Wu, P. Li, and J. Wang, “Semantic-aware representation learning for homography estimation,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 2506–2514
2024
-
[53]
Mind the gap: Aligning vision foundation models to image feature matching,
Y . Liu, J. Fu, Y . Wu, K. Wu, P. Li, J. Wu, S. Zhou, and J. Xin, “Mind the gap: Aligning vision foundation models to image feature matching,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 20313–20323
2025
-
[54]
PatchCue: Enhancing Vision-Language Model Reasoning with Patch- Based Visual Cues,
Y . Qi, P. Fu, H. Li, Y . Liu, C. Jiang, B. Qin, Z. Luo, and J. Luan, “PatchCue: Enhancing Vision-Language Model Reasoning with Patch- Based Visual Cues,”arXiv preprint arXiv:2603.05869, 2026
-
[55]
Closing the gap between the upper bound and lower bound of Adam’s iteration com- plexity,
B. Wang, J. Fu, H. Zhang, N. Zheng, and W. Chen, “Closing the gap between the upper bound and lower bound of Adam’s iteration com- plexity,”Advances in Neural Information Processing Systems, vol. 36, pp. 39006–39032, 2023
2023
-
[56]
Recognition of surface defects on steel sheet using transfer learning,
J. Fu, X. Zhu, and Y . Li, “Recognition of surface defects on steel sheet using transfer learning,”arXiv preprint arXiv:1909.03258, 2019
-
[57]
When and why momentum accelerates SGD : An empirical study, 2023
J. Fu, B. Wang, H. Zhang, Z. Zhang, W. Chen, and N. Zheng, “When and why momentum accelerates SGD: An empirical study,”arXiv preprint arXiv:2306.09000, 2023
-
[58]
Understanding mobile GUI: From pixel-words to screen-sentences,
J. Fu, X. Zhang, Y . Wang, W. Zeng, and N. Zheng, “Understanding mobile GUI: From pixel-words to screen-sentences,”Neurocomputing, vol. 601, p. 128200, 2024
2024
-
[59]
Breaking through the learning plateaus of in-context learning in transformer,
J. Fu, T. Yang, Y . Wang, Y . Lu, and N. Zheng, “Breaking through the learning plateaus of in-context learning in transformer,”arXiv preprint arXiv:2309.06054, 2023
-
[60]
Regnav: Room expert guided image- goal navigation,
P. Li, K. Wu, J. Fu, and S. Zhou, “Regnav: Room expert guided image- goal navigation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 4860–4868
2025
-
[61]
Camera-aware la- bel refinement for unsupervised person re-identification,
P. Li, K. Wu, W. Huang, S. Zhou, and J. Wang, “Camera-aware label refinement for unsupervised person re-identification,”arXiv preprint arXiv:2403.16450, 2024. Zhen Liuis currently a Ph.D. student at the National Key Laboratory of Human-Machine Hybrid Aug- mented Intelligence, Xi’an Jiaotong University. His research focuses on vision-and-language navigatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.