Recognition: unknown
S2MAM: Semi-supervised Meta Additive Model for Robust Estimation and Variable Selection
Pith reviewed 2026-05-10 03:34 UTC · model grok-4.3
The pith
S2MAM uses bilevel optimization to automatically select informative variables and update similarity matrices in manifold-regularized semi-supervised learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
S2MAM formulates semi-supervised manifold regularization as a bilevel program in which the outer level identifies informative variables and refines the similarity matrix while the inner level produces additive-model predictions; the scheme is accompanied by proofs of algorithmic convergence and a statistical generalization bound.
What carries the argument
Bilevel optimization that couples an outer problem of variable selection and similarity-matrix update with an inner problem of additive-model fitting under manifold regularization.
If this is right
- Variable selection occurs automatically during training rather than as a separate preprocessing step.
- The learned model remains interpretable because it is additive and the active variables are explicitly identified.
- Generalization bounds hold under the stated manifold and optimization assumptions.
- Robustness is observed across multiple corruption types and intensities in the reported experiments.
Where Pith is reading between the lines
- The bilevel structure could be adapted to other regularizers that depend on a similarity graph.
- High-dimensional applications with many irrelevant features would be a natural test bed for the variable-selection component.
- If the manifold assumption is mildly violated the method may still outperform fixed-metric baselines provided the bilevel updates remain stable.
Load-bearing premise
The data distribution is supported on a Riemannian manifold and the bilevel updates to the similarity matrix do not introduce additional bias.
What would settle it
A controlled experiment on data whose support is not a manifold, or where bilevel updates demonstrably increase bias relative to a fixed similarity matrix, would refute the central claim.
Figures
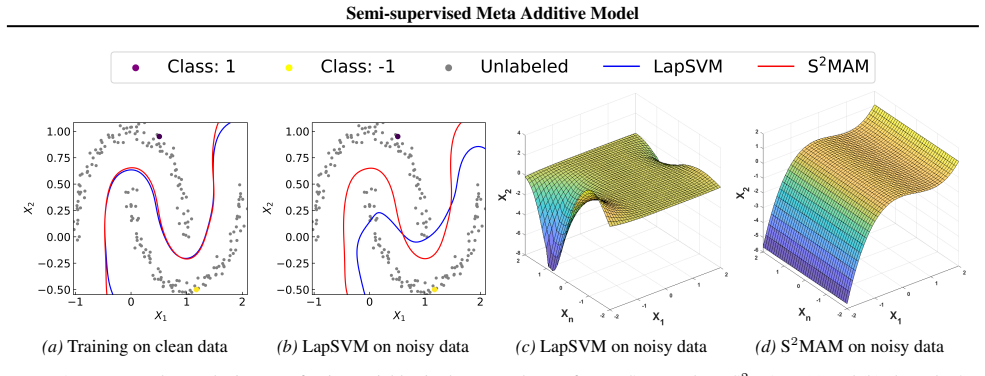
read the original abstract
Semi-supervised learning with manifold regularization is a classical framework for jointly learning from both labeled and unlabeled data, where the key requirement is that the support of the unknown marginal distribution has the geometric structure of a Riemannian manifold. Typically, the Laplace-Beltrami operator-based manifold regularization can be approximated empirically by the Laplacian regularization associated with the entire training data and its corresponding graph Laplacian matrix. However, the graph Laplacian matrix depends heavily on the prespecified similarity metric and may lead to inappropriate penalties when dealing with redundant or noisy input variables. To address the above issues, this paper proposes a new Semi-Supervised Meta Additive Model (S$^2$MAM) based on a bilevel optimization scheme that automatically identifies informative variables, updates the similarity matrix, and simultaneously achieves interpretable predictions. Theoretical guarantees are provided for S$^2$MAM, including the computing convergence and the statistical generalization bound. Experimental assessments across 4 synthetic and 12 real-world datasets, with varying levels and categories of corruption, validate the robustness and interpretability of the proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes S²MAM, a semi-supervised meta additive model that employs a bilevel optimization scheme to automatically identify informative variables, update the similarity matrix for manifold regularization, and produce interpretable predictions. It claims theoretical guarantees on computational convergence of the bilevel scheme and a statistical generalization bound, with experimental validation on 4 synthetic and 12 real-world datasets under varying corruption levels and types.
Significance. If the generalization bound can be rigorously established despite the data-dependent Laplacian induced by the outer loop, the work would meaningfully extend manifold-regularized semi-supervised learning by integrating variable selection and meta-optimization for robustness and interpretability. The experimental design across corrupted datasets provides useful evidence of practical performance, but the overall significance is limited by the need to verify that the adaptive regularizer does not invalidate the claimed bound.
major comments (2)
- [§4] §4 (Theoretical Guarantees), Theorem on statistical generalization bound: the bound is stated for the adaptive graph Laplacian produced by the bilevel update of the similarity matrix. Classical manifold regularization bounds rely on a fixed Laplacian whose spectral properties follow from the Riemannian manifold assumption on the marginal support. The proof must explicitly control the Lipschitz constant of the inner solution map with respect to the learned variables (or show that the adaptive Laplacian stays close to a fixed one in high probability); without this step the bound does not follow from existing results and the central theoretical claim is unsupported.
- [§3.2] §3.2 (Bilevel Optimization Formulation), convergence analysis: the computing convergence guarantee assumes the inner additive-model problem yields a sufficiently smooth and strongly convex solution map. Once variable selection and the meta-objective are introduced, strong convexity is no longer automatic. The manuscript must state the precise conditions (e.g., restricted strong convexity parameter, smoothness modulus) under which the outer-loop iteration converges and verify that they hold for the proposed S²MAM objective.
minor comments (2)
- [Table 1] Table 1 and §5.1: the reported performance metrics under different corruption categories would benefit from explicit standard deviations across the 10 random splits to allow assessment of statistical significance.
- [Notation] Notation section: the symbol for the updated similarity matrix is introduced in the bilevel formulation but reused without redefinition in the generalization proof; add a short notational table for clarity.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed comments. We address each major comment point by point below, clarifying our approach and outlining the revisions that will be made to strengthen the theoretical sections.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Guarantees), Theorem on statistical generalization bound: the bound is stated for the adaptive graph Laplacian produced by the bilevel update of the similarity matrix. Classical manifold regularization bounds rely on a fixed Laplacian whose spectral properties follow from the Riemannian manifold assumption on the marginal support. The proof must explicitly control the Lipschitz constant of the inner solution map with respect to the learned variables (or show that the adaptive Laplacian stays close to a fixed one in high probability); without this step the bound does not follow from existing results and the central theoretical claim is unsupported.
Authors: We appreciate this observation on the need for rigorous control in the proof. In the revised manuscript, we will augment the proof of the statistical generalization bound in Section 4 by explicitly deriving a bound on the Lipschitz constant of the inner solution map with respect to the learned variables. We will further show that, under standard assumptions on the variable selection process and the manifold structure, the adaptive Laplacian remains close to a fixed Laplacian (corresponding to the true marginal support) with high probability. This step will ensure the bound extends existing manifold regularization results to the data-dependent case. revision: yes
-
Referee: [§3.2] §3.2 (Bilevel Optimization Formulation), convergence analysis: the computing convergence guarantee assumes the inner additive-model problem yields a sufficiently smooth and strongly convex solution map. Once variable selection and the meta-objective are introduced, strong convexity is no longer automatic. The manuscript must state the precise conditions (e.g., restricted strong convexity parameter, smoothness modulus) under which the outer-loop iteration converges and verify that they hold for the proposed S²MAM objective.
Authors: We thank the referee for pointing out this requirement in the convergence analysis. In the revised version, we will explicitly state the precise conditions, including the restricted strong convexity parameter and smoothness modulus, under which the outer-loop iteration converges. We will also verify that these conditions hold for the S²MAM objective through appropriate choices of regularization parameters and structural assumptions on the additive model components, ensuring the bilevel scheme remains well-defined. revision: yes
Circularity Check
No circularity: derivation remains independent of its fitted outputs
full rationale
The paper introduces S2MAM as a bilevel optimization procedure that jointly performs variable selection, similarity-matrix adaptation, and additive-model fitting under a manifold-regularization objective. It states that convergence of the bilevel scheme and a statistical generalization bound are proved. No quoted equation or derivation step reduces the claimed bound or convergence result to a tautological re-expression of the learned similarity matrix or selected variables; the proofs are presented as following from the optimization structure and the Riemannian-manifold assumption on the marginal support. The adaptive Laplacian is an explicit part of the algorithm rather than a hidden re-use of the target quantity, and no self-citation is invoked as the sole justification for the uniqueness or validity of the bound. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The support of the unknown marginal distribution has the geometric structure of a Riemannian manifold.
Reference graph
Works this paper leans on
-
[1]
Journal of the American statistical association , volume=
Regularized discriminant analysis , author=. Journal of the American statistical association , volume=. 1989 , publisher=
1989
-
[2]
International Conference on Machine Learning , pages=
Learning latent variable Gaussian graphical models , author=. International Conference on Machine Learning , pages=. 2014 , organization=
2014
-
[3]
proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Agedb: the first manually collected, in-the-wild age database , author=. proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maskgan: Towards diverse and interactive facial image manipulation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[5]
Applied and Computational Harmonic Analysis , volume=
Consistency of regularized spectral clustering , author=. Applied and Computational Harmonic Analysis , volume=. 2011 , publisher=
2011
-
[6]
12th International Conference on Learning Representations, ICLR 2024 , year=
Semireward: A general reward model for semi-supervised learning , author=. 12th International Conference on Learning Representations, ICLR 2024 , year=
2024
-
[7]
Applied Soft Computing , volume=
Deep semi-supervised regression via pseudo-label filtering and calibration , author=. Applied Soft Computing , volume=. 2024 , publisher=
2024
-
[8]
European conference on computer vision , pages=
A discriminative feature learning approach for deep face recognition , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[9]
Journal of Machine Learning Research , volume=
Consistent semi-supervised graph regularization for high dimensional data , author=. Journal of Machine Learning Research , volume=
-
[10]
Journal of the American Statistical Association , volume=
Semi-supervised linear regression , author=. Journal of the American Statistical Association , volume=. 2022 , publisher=
2022
-
[11]
Journal of Machine Learning Research , volume=
A practical scheme and fast algorithm to tune the lasso with optimality guarantees , author=. Journal of Machine Learning Research , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Not all unlabeled data are equal: Learning to weight data in semi-supervised learning , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Energies , volume=
A well-overflow prediction algorithm based on semi-supervised learning , author=. Energies , volume=. 2022 , publisher=
2022
-
[14]
Information and Inference: A Journal of the IMA , volume=
Convergence of graph Laplacian with kNN self-tuned kernels , author=. Information and Inference: A Journal of the IMA , volume=. 2022 , publisher=
2022
-
[15]
Bernoulli , volume=
On the prediction performance of the Lasso , author=. Bernoulli , volume=
-
[16]
2009 , publisher=
The elements of statistical learning , author=. 2009 , publisher=
2009
-
[17]
Proceedings of the National Academy of Sciences , volume =
Zhigang Yao and Jiaji Su and Shing-Tung Yau , title =. Proceedings of the National Academy of Sciences , volume =
-
[18]
Science China Mathematics , volume=
Generalization errors of Laplacian regularized least squares regression , author=. Science China Mathematics , volume=. 2012 , publisher=
2012
-
[19]
Improving Neural Additive Models with Bayesian Principles , year =
Bouchiat, Kouroche and Immer, Alexander and Yèche, Hugo and Rätsch, Gunnar and Fortuin, Vincent , journal =. Improving Neural Additive Models with Bayesian Principles , year =
-
[20]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
CAT: Interpretable Concept-based Taylor Additive Models , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[21]
, author=
Visualizing data using t-SNE. , author=. Journal of machine learning research , volume=
-
[22]
SPABA: A Single-Loop and Probabilistic Stochastic Bilevel Algorithm Achieving Optimal Sample Complexity , author=. arXiv preprint arXiv:2405.18777 , year=
-
[23]
IEEE Signal Processing Magazine , volume=
An Introduction to Bilevel Optimization: Foundations and applications in signal processing and machine learning , author=. IEEE Signal Processing Magazine , volume=. 2024 , publisher=
2024
-
[24]
Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=
Convergence and Applications of ADMM on the Multi-convex Problems , author=. Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=. 2022 , organization=
2022
-
[25]
International Conference on Artificial Intelligence and Statistics , pages=
Alternating projected sgd for equality-constrained bilevel optimization , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[26]
Nature machine intelligence , volume=
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead , author=. Nature machine intelligence , volume=. 2019 , publisher=
2019
-
[27]
1990 , publisher=
Spline models for observational data , author=. 1990 , publisher=
1990
-
[28]
1998 , publisher=
Learning with kernels , author=. 1998 , publisher=
1998
-
[29]
2005 , publisher=
Semi-supervised learning literature survey , author=. 2005 , publisher=
2005
-
[30]
, author=
Generalization Error Bounds in Semi-supervised Classification Under the Cluster Assumption. , author=. Journal of Machine Learning Research , volume=
-
[31]
, author=
On the effectiveness of Laplacian normalization for graph semi-supervised learning. , author=. Journal of Machine Learning Research , volume=
-
[32]
IEEE Transactions on Information Theory , volume=
Graph-based semi-supervised learning and spectral kernel design , author=. IEEE Transactions on Information Theory , volume=. 2008 , publisher=
2008
-
[33]
, author=
Learning coordinate covariances via gradients. , author=. Journal of Machine Learning Research , volume=
-
[34]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Semi-supervised deep kernel learning: Regression with unlabeled data by minimizing predictive variance , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[35]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Random features for large-scale kernel machines , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[36]
International Conference on Learning Representations (ICLR) , pages=
Realistic evaluation of semi-supervised learning algortihms , author=. International Conference on Learning Representations (ICLR) , pages=
-
[37]
arXiv preprint arXiv:2311.15982 , year=
Stab-GKnock: Controlled variable selection for partially linear models using generalized knockoffs , author=. arXiv preprint arXiv:2311.15982 , year=
-
[38]
IEEE Transactions on Cybernetics , volume=
Robust graph learning from noisy data , author=. IEEE Transactions on Cybernetics , volume=. 2020 , publisher=
2020
-
[39]
Journal of the American Statistical Association , volume=
On propagated scoring for semisupervised additive models , author=. Journal of the American Statistical Association , volume=. 2011 , publisher=
2011
-
[40]
Journal of Computational and Graphical Statistics , volume=
An iterative algorithm for extending learners to a semi-supervised setting , author=. Journal of Computational and Graphical Statistics , volume=. 2008 , publisher=
2008
-
[41]
The Annals of Applied Statistics , number =
Mark Culp and George Michailidis and Kjell Johnson , title =. The Annals of Applied Statistics , number =
-
[42]
IEEE Transactions on Image Processing , volume=
Flexible manifold embedding: A framework for semi-supervised and unsupervised dimension reduction , author=. IEEE Transactions on Image Processing , volume=. 2010 , publisher=
2010
-
[43]
Journal of Machine Learning Research , volume=
Manifold Fitting under Unbounded Noise , author=. Journal of Machine Learning Research , volume=
-
[44]
IEEE Transactions on Knowledge and Data Engineering , volume=
Semi-supervised feature selection via sparse rescaled linear square regression , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2018 , publisher=
2018
-
[45]
IEEE Transactions on Knowledge and Data Engineering , volume=
Semi-supervised learning with auto-weighting feature and adaptive graph , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2019 , publisher=
2019
-
[46]
Advances in Neural Information Processing Systems , volume=
When do neural networks outperform kernel methods? , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Pattern Recognition Letters , volume=
Noisy manifold learning using neighborhood smoothing embedding , author=. Pattern Recognition Letters , volume=. 2008 , publisher=
2008
-
[48]
IEEE Transactions on Knowledge and Data Engineering , volume=
Adaptive local embedding learning for semi-supervised dimensionality reduction , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2021 , publisher=
2021
-
[49]
Pattern Recognition , volume=
Robust embedding regression for semi-supervised learning , author=. Pattern Recognition , volume=. 2024 , publisher=
2024
-
[50]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
Accelerating flexible manifold embedding for scalable semi-supervised learning , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2018 , publisher=
2018
-
[51]
Science , volume=
Nonlinear dimensionality reduction by locally linear embedding , author=. Science , volume=. 2000 , publisher=
2000
-
[52]
Proceedings of the 20th International Conference on Machine Learning (ICML) , pages=
Semi-supervised learning using gaussian fields and harmonic functions , author=. Proceedings of the 20th International Conference on Machine Learning (ICML) , pages=
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Learning with local and global consistency , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[54]
Set-Valued and Variational Analysis , volume=
Firmly nonexpansive mappings and maximally monotone operators: correspondence and duality , author=. Set-Valued and Variational Analysis , volume=. 2012 , publisher=
2012
-
[55]
International Conference on Machine Learning (ICML) , pages=
Hyperparameter optimization with approximate gradient , author=. International Conference on Machine Learning (ICML) , pages=. 2016 , organization=
2016
-
[56]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Meta-learning with implicit gradients , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[57]
Analysis and Applications , volume=
Learning rates for the risk of kernel-based quantile regression estimators in additive models , author=. Analysis and Applications , volume=
-
[58]
, author=
Laplacian Support Vector Machines Trained in the Primal. , author=. Journal of Machine Learning Research , volume=
-
[59]
Neurocomputing , volume=
Generalization error bound of semi-supervised learning with L1 regularization in sum space , author=. Neurocomputing , volume=. 2018 , publisher=
2018
-
[60]
Constructive Approximation , volume=
Learning theory estimates via integral operators and their approximations , author=. Constructive Approximation , volume=. 2007 , publisher=
2007
-
[61]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Coresets via bilevel optimization for continual learning and streaming , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[62]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Semisupervised inference for explained variance in high dimensional linear regression and its applications , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2020 , publisher=
2020
-
[63]
Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence , pages=
Semi-supervised Learning with density based distances , author=. Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence , pages=
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Improved techniques for training gans , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[65]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Semi-supervised learning with deep generative models , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[66]
arXiv e-prints , pages=
Semi-supervised Learning with Deep Generative Models for Asset Failure Prediction , author=. arXiv e-prints , pages=
-
[67]
Machine Learning , volume=
A survey on semi-supervised learning , author=. Machine Learning , volume=. 2020 , publisher=
2020
-
[68]
IEEE Transactions on Knowledge and Data Engineering , year=
A survey on deep semi-supervised learning , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[69]
Artificial Intelligence and Statistics (AISTAT) , pages=
Multi-manifold semi-supervised learning , author=. Artificial Intelligence and Statistics (AISTAT) , pages=. 2009 , organization=
2009
-
[70]
2006 , author=
Semi-supervised learning. 2006 , author=. Cambridge, Massachusettes: The MIT Press View Article , volume=
2006
-
[71]
International Workshop on Artificial Intelligence and Statistics (AISTAT) , pages=
On manifold regularization , author=. International Workshop on Artificial Intelligence and Statistics (AISTAT) , pages=. 2005 , organization=
2005
-
[72]
, author=
Manifold regularization: A geometric framework for learning from labeled and unlabeled examples. , author=. Journal of Machine Learning Research , volume=
-
[73]
Linear manifold regularization for large scale semi-supervised learning , author=. Proc. of the 22nd ICML Workshop on Learning with Partially Classified Training Data , volume=. 2005 , organization=
2005
-
[74]
Mathematical Programming , volume=
Mini-batch stochastic approximation methods for nonconvex stochastic composite optimization , author=. Mathematical Programming , volume=. 2016 , publisher=
2016
-
[75]
Neural Networks , volume=
Laplacian twin support vector machine for semi-supervised classification , author=. Neural Networks , volume=. 2012 , publisher=
2012
-
[76]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Smooth neighbors on teacher graphs for semi-supervised learning , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[77]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Ensemble manifold regularization , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2012 , publisher=
2012
-
[78]
Machine Learning , volume=
Semi-supervised learning on Riemannian manifolds , author=. Machine Learning , volume=. 2004 , publisher=
2004
-
[79]
Proceedings of the Eighteenth International Conference on Machine Learning (ICML) , pages=
Learning from Labeled and Unlabeled Data using Graph Mincuts , author=. Proceedings of the Eighteenth International Conference on Machine Learning (ICML) , pages=
-
[80]
Proceedings of the 26th annual International Conference on Machine Learning (ICML) , pages=
Graph construction and b-matching for semi-supervised learning , author=. Proceedings of the 26th annual International Conference on Machine Learning (ICML) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.