Recognition: unknown
Towards Scalable Lifelong Knowledge Editing with Selective Knowledge Suppression
Pith reviewed 2026-05-10 01:52 UTC · model grok-4.3
The pith
LightEdit performs lifelong knowledge editing in language models by selecting relevant facts and suppressing original knowledge probabilities during decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
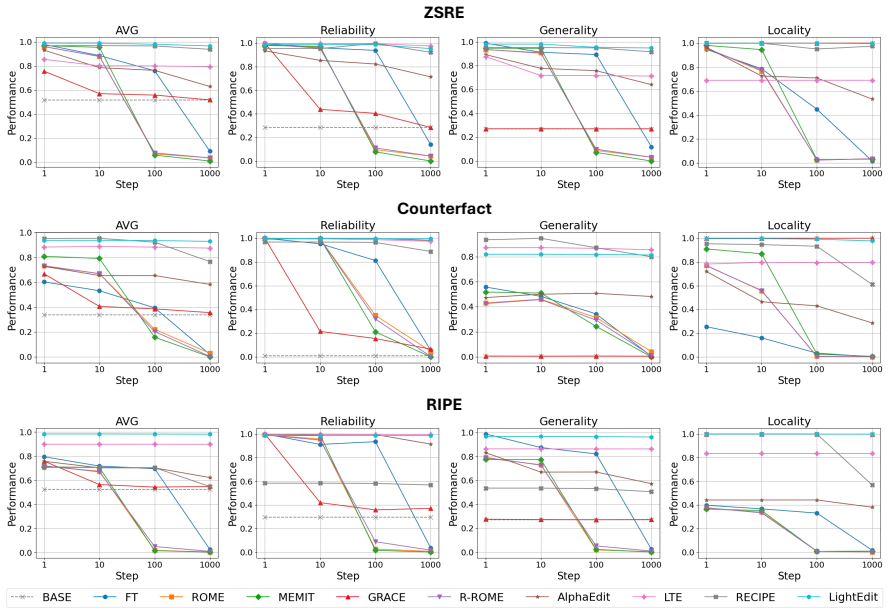
LightEdit first selects relevant knowledge from retrieved information to modify the query, then incorporates a decoding strategy that suppresses the model's original knowledge probabilities. This enables efficient edits without catastrophic forgetting. Experiments on the ZSRE, Counterfact, and RIPE benchmarks show it outperforms prior lifelong editing methods while minimizing training costs and allowing easy adaptation to different datasets.
What carries the argument
Selective suppression of original knowledge probabilities during decoding, which reduces the likelihood of generating pre-edit knowledge so the new information can appear in the output.
If this is right
- Sequential edits remain stable without the model forgetting earlier modifications.
- Training costs stay low enough to support many edits over time.
- Performance exceeds that of existing lifelong editing methods on standard benchmarks.
- The approach adapts to new datasets with minimal additional training effort.
Where Pith is reading between the lines
- The method could support ongoing fact corrections in deployed systems with low overhead.
- Suppression during decoding might combine with other techniques to lower hallucination rates more broadly.
- Applying the same selection and suppression steps to larger models would test whether efficiency gains persist.
Load-bearing premise
Selectively lowering the probabilities of the model's original knowledge during decoding will reliably produce correct new answers without introducing new hallucinations or degrading performance on unrelated queries.
What would settle it
After a series of sequential edits, evaluation on held-out queries shows either failure to produce the edited facts or new errors and hallucinations on unrelated topics.
Figures





read the original abstract
Large language models (LLMs) require frequent knowledge updates to reflect changing facts and mitigate hallucinations. To meet this demand, lifelong knowledge editing has emerged as a continual approach to modify specific pieces of knowledge without retraining the entire model. Existing parameter editing methods struggle with stability during sequential edits due to catastrophic forgetting. While retrieval-based approaches are proposed to alleviate this issue, their applicability remains limited across various datasets because of high training costs. To address these limitations and enhance scalability in lifelong settings, we propose LightEdit. Our framework first selects relevant knowledge from retrieved information to modify the query effectively. It then incorporates a decoding strategy to suppress the model's original knowledge probabilities, thereby enabling efficient edits based on the selected information. Extensive experiments on ZSRE, Counterfact, and RIPE benchmarks demonstrate that LightEdit outperforms existing lifelong knowledge editing methods. Furthermore, by minimizing training costs, LightEdit achieves cost-effective scalability, enabling easy adaptation to various datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LightEdit, a framework for lifelong knowledge editing in LLMs. It first retrieves and selects relevant knowledge to modify the input query, then applies a decoding-time strategy that suppresses the model's original knowledge probabilities to produce the edited output. The central claims are that this yields better performance than prior lifelong editing methods on the ZSRE, Counterfact, and RIPE benchmarks, while incurring minimal training cost and thus enabling scalable adaptation across datasets without catastrophic forgetting.
Significance. If the selective suppression mechanism can be shown to avoid side-effects on unrelated knowledge and new hallucinations under sequential edits, the approach would provide a low-cost, training-light alternative to parameter-modification methods that suffer from stability issues, potentially improving practical deployment of updatable LLMs.
major comments (3)
- [§3] §3 (Method): The decoding strategy for suppressing original knowledge probabilities is described only procedurally, with no equation, pseudocode, or formal definition of how the probability adjustment is computed from the selected retrieved information; this is load-bearing for the claim that edits are reliable and side-effect-free.
- [§5] §5 (Experiments): The reported outperformance on ZSRE, Counterfact, and RIPE is not accompanied by ablations measuring accuracy on unrelated facts, hallucination rates, or stability after long sequences of edits; without these controls the central claim of scalable lifelong editing without forgetting cannot be evaluated.
- [§5.1] §5.1 and associated tables: No quantitative metrics (e.g., exact accuracy deltas, training-time comparisons, or error bars) or implementation details are supplied to support the assertions of outperformance and cost-effective scalability, leaving the experimental evidence insufficient to substantiate the abstract claims.
minor comments (2)
- [Abstract] Abstract: The phrase 'extensive experiments' is used without any numerical results, which reduces immediate readability for readers scanning for performance claims.
- [§3] Notation: The distinction between 'selected relevant knowledge' and 'retrieved information' is introduced without a clear diagram or pseudocode, making the pipeline flow harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The decoding strategy for suppressing original knowledge probabilities is described only procedurally, with no equation, pseudocode, or formal definition of how the probability adjustment is computed from the selected retrieved information; this is load-bearing for the claim that edits are reliable and side-effect-free.
Authors: We agree that a more formal presentation would improve clarity and verifiability. In the revised manuscript we will add an explicit equation for the probability adjustment together with pseudocode that shows how the suppression is computed from the selected retrieved knowledge. This will make the mechanism fully reproducible and directly support the reliability claims. revision: yes
-
Referee: [§5] §5 (Experiments): The reported outperformance on ZSRE, Counterfact, and RIPE is not accompanied by ablations measuring accuracy on unrelated facts, hallucination rates, or stability after long sequences of edits; without these controls the central claim of scalable lifelong editing without forgetting cannot be evaluated.
Authors: We acknowledge that dedicated ablations on unrelated facts, hallucination rates, and long-sequence stability would provide stronger evidence for the absence of side-effects and forgetting. We will add these experiments to Section 5 in the revision, reporting performance on held-out unrelated facts, hallucination metrics, and results after 100+ sequential edits. revision: yes
-
Referee: [§5.1] §5.1 and associated tables: No quantitative metrics (e.g., exact accuracy deltas, training-time comparisons, or error bars) or implementation details are supplied to support the assertions of outperformance and cost-effective scalability, leaving the experimental evidence insufficient to substantiate the abstract claims.
Authors: We will expand Section 5.1 and the tables with exact accuracy deltas, wall-clock training-time comparisons, standard-error bars where appropriate, and additional implementation details (hyperparameters, retrieval settings, and hardware). These additions will make the quantitative support for outperformance and scalability explicit. revision: yes
Circularity Check
No circularity: procedural framework with empirical validation, no self-referential derivations
full rationale
The paper presents LightEdit as a two-stage framework (knowledge selection from retrieval followed by decoding-time probability suppression) and validates it via experiments on ZSRE, Counterfact, and RIPE. No equations, derivations, or first-principles results are shown that reduce performance claims to quantities defined by the method's own fitted parameters or prior self-citations. The central claims rest on benchmark outperformance and reduced training cost rather than any self-definitional loop, fitted-input-as-prediction, or uniqueness theorem imported from the authors' prior work. This matches the reader's assessment of score 2.0 as a normal non-circular outcome for a methodological proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ibrahim M Alabdulmohsin, Behnam Neyshabur, and Xiaohua Zhai. 2022. Revisiting neural scaling laws in language and vision. Advances in Neural Information Processing Systems, 35:22300--22312
2022
- [3]
-
[5]
Roi Cohen, Eden Biran, Ori Yoran, Amir Globerson, and Mor Geva. 2024. Evaluating the ripple effects of knowledge editing in language models. Transactions of the Association for Computational Linguistics, 12:283--298
2024
-
[7]
Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognising textual entailment challenge. In Machine learning challenges workshop, pages 177--190. Springer
2005
- [8]
- [11]
-
[12]
Tom Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Yoon Kim, and Marzyeh Ghassemi. 2023 b . Aging with grace: Lifelong model editing with discrete key-value adaptors. Advances in Neural Information Processing Systems, 36:47934--47959
2023
-
[14]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/abs/2009.03300 Measuring massive multitask language understanding . Preprint, arXiv:2009.03300
work page internal anchor Pith review arXiv 2021
- [16]
- [19]
-
[22]
Angeliki Lazaridou, Adhi Kuncoro, Elena Gribovskaya, Devang Agrawal, Adam Liska, Tayfun Terzi, Mai Gimenez, Cyprien de Masson d'Autume, Tomas Kocisky, Sebastian Ruder, and 1 others. 2021. Mind the gap: Assessing temporal generalization in neural language models. Advances in Neural Information Processing Systems, 34:29348--29363
2021
-
[27]
Llama Team . 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
- [29]
-
[30]
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. 2023 b . https://arxiv.org/abs/2210.07229 Mass-editing memory in a transformer . Preprint, arXiv:2210.07229
work page internal anchor Pith review arXiv 2023
-
[31]
Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. 2022. Memory-based model editing at scale. In International Conference on Machine Learning, pages 15817--15831. PMLR
2022
-
[33]
OpenAI. 2023. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [36]
- [38]
- [39]
- [42]
-
[43]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. 2024. https://arxiv.org/abs/2308.10248 Steering language models with activation engineering . Preprint, arXiv:2308.10248
work page internal anchor Pith review arXiv 2024
-
[44]
Ben Wang and Aran Komatsuzaki. 2021. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model . https://github.com/kingoflolz/mesh-transformer-jax
2021
-
[46]
Song Wang, Yaochen Zhu, Haochen Liu, Zaiyi Zheng, Chen Chen, and Jundong Li. 2024 b . Knowledge editing for large language models: A survey. ACM Computing Surveys, 57(3):1--37
2024
- [47]
-
[49]
Ningyu Zhang, Yunzhi Yao, Bozhong Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, Siyuan Cheng, Ziwen Xu, Xin Xu, Jia-Chen Gu, Yong Jiang, Pengjun Xie, Fei Huang, Lei Liang, Zhiqiang Zhang, and 3 others. 2024. https://arxiv.org/abs/2401.01286 A comprehensive study of knowledge editing for large language model...
-
[50]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, and 3 others. 2025. https://arxiv.org/abs/2303.18223 A survey of large language models . Preprint, arXiv:2303.18223
work page internal anchor Pith review arXiv 2025
-
[52]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[53]
Publications Manual , year = "1983", publisher =
1983
-
[54]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[55]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[56]
Dan Gusfield , title =. 1997
1997
-
[57]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[58]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[59]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[60]
Can We Edit Factual Knowledge by In-Context Learning?
Zheng, Ce and Li, Lei and Dong, Qingxiu and Fan, Yuxuan and Wu, Zhiyong and Xu, Jingjing and Chang, Baobao. Can We Edit Factual Knowledge by In-Context Learning?. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.296
-
[61]
2020 , eprint=
Modifying Memories in Transformer Models , author=. 2020 , eprint=
2020
-
[62]
2023 , eprint=
Eva-KELLM: A New Benchmark for Evaluating Knowledge Editing of LLMs , author=. 2023 , eprint=
2023
-
[63]
Wang, Ben and Komatsuzaki, Aran , title =
-
[64]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[65]
Advances in Neural Information Processing Systems , volume=
Revisiting neural scaling laws in language and vision , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
2025 , eprint=
A Survey of Large Language Models , author=. 2025 , eprint=
2025
-
[67]
Understanding Transformer Memorization Recall Through Idioms
Haviv, Adi and Cohen, Ido and Gidron, Jacob and Schuster, Roei and Goldberg, Yoav and Geva, Mor. Understanding Transformer Memorization Recall Through Idioms. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.19
-
[68]
2023 , eprint=
Inspecting and Editing Knowledge Representations in Language Models , author=. 2023 , eprint=
2023
-
[69]
2021 , eprint=
Self-Attention Attribution: Interpreting Information Interactions Inside Transformer , author=. 2021 , eprint=
2021
-
[70]
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale , year=. Survey of Hallucination in Natural Language Generation , volume=. ACM Computing Surveys , publisher=. doi:10.1145/3571730 , number=
-
[71]
2024 , eprint=
Continual Learning of Large Language Models: A Comprehensive Survey , author=. 2024 , eprint=
2024
-
[72]
Advances in Neural Information Processing Systems , volume=
Mind the gap: Assessing temporal generalization in neural language models , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
2021 , eprint=
Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs , author=. 2021 , eprint=
2021
-
[74]
Pagnoni, Artidoro and Balachandran, Vidhisha and Tsvetkov, Yulia. Understanding Factuality in Abstractive Summarization with FRANK : A Benchmark for Factuality Metrics. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.383
-
[75]
ACM Computing Surveys , volume=
Knowledge editing for large language models: A survey , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[76]
2024 , eprint=
A Comprehensive Study of Knowledge Editing for Large Language Models , author=. 2024 , eprint=
2024
-
[77]
International Conference on Machine Learning , pages=
Memory-based model editing at scale , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[78]
Advances in Neural Information Processing Systems , volume=
Aging with grace: Lifelong model editing with discrete key-value adaptors , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
2023 , eprint=
Mass-Editing Memory in a Transformer , author=. 2023 , eprint=
2023
-
[80]
2021 , eprint=
Editing Factual Knowledge in Language Models , author=. 2021 , eprint=
2021
-
[81]
2022 , eprint=
Fast Model Editing at Scale , author=. 2022 , eprint=
2022
-
[82]
2024 , eprint=
Neighboring Perturbations of Knowledge Editing on Large Language Models , author=. 2024 , eprint=
2024
-
[83]
Knowledge Editing in Language Models , author=
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models , author=. 2023 , eprint=
2023
-
[84]
2023 , eprint=
Evaluating the Ripple Effects of Knowledge Editing in Language Models , author=. 2023 , eprint=
2023
-
[85]
2018 , eprint=
FEVER: a large-scale dataset for Fact Extraction and VERification , author=. 2018 , eprint=
2018
-
[86]
2017 , eprint=
Zero-Shot Relation Extraction via Reading Comprehension , author=. 2017 , eprint=
2017
-
[87]
Zhong, Zexuan and Wu, Zhengxuan and Manning, Christopher and Potts, Christopher and Chen, Danqi. MQ u AKE : Assessing Knowledge Editing in Language Models via Multi-Hop Questions. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.971
-
[88]
2024 , eprint=
Chain-of-History Reasoning for Temporal Knowledge Graph Forecasting , author=. 2024 , eprint=
2024
-
[89]
2024 , eprint=
EventGround: Narrative Reasoning by Grounding to Eventuality-centric Knowledge Graphs , author=. 2024 , eprint=
2024
-
[90]
2024 , eprint=
Timeline-based Sentence Decomposition with In-Context Learning for Temporal Fact Extraction , author=. 2024 , eprint=
2024
-
[91]
2021 , eprint=
TIMEDIAL: Temporal Commonsense Reasoning in Dialog , author=. 2021 , eprint=
2021
-
[92]
Temporal Reasoning in Natural Language Inference
Vashishtha, Siddharth and Poliak, Adam and Lal, Yash Kumar and Van Durme, Benjamin and White, Aaron Steven. Temporal Reasoning in Natural Language Inference. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.363
-
[93]
2023 , eprint=
Are Large Language Models Temporally Grounded? , author=. 2023 , eprint=
2023
-
[94]
2023 , eprint=
Towards Benchmarking and Improving the Temporal Reasoning Capability of Large Language Models , author=. 2023 , eprint=
2023
-
[95]
2024 , eprint=
TRAM: Benchmarking Temporal Reasoning for Large Language Models , author=. 2024 , eprint=
2024
-
[96]
2023 , eprint=
History Matters: Temporal Knowledge Editing in Large Language Model , author=. 2023 , eprint=
2023
-
[97]
2024 , eprint=
Multi-hop Question Answering under Temporal Knowledge Editing , author=. 2024 , eprint=
2024
-
[98]
2021 , eprint=
A Dataset for Answering Time-Sensitive Questions , author=. 2021 , eprint=
2021
-
[99]
Knowledge-Augmented Language Model Verification
Baek, Jinheon and Jeong, Soyeong and Kang, Minki and Park, Jong and Hwang, Sung. Knowledge-Augmented Language Model Verification. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.107
-
[100]
How Do Large Language Models Capture the Ever-changing World Knowledge? A Review of Recent Advances
Zhang, Zihan and Fang, Meng and Chen, Ling and Namazi-Rad, Mohammad-Reza and Wang, Jun. How Do Large Language Models Capture the Ever-changing World Knowledge? A Review of Recent Advances. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.516
-
[101]
doi: 10.18653/V1/2021.EMNLP-MAIN.522
De Cao, Nicola and Aziz, Wilker and Titov, Ivan. Editing Factual Knowledge in Language Models. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.522
-
[102]
2024 , eprint=
A Survey on Temporal Knowledge Graph: Representation Learning and Applications , author=. 2024 , eprint=
2024
-
[103]
2015 IEEE symposium on security and privacy , pages=
Towards making systems forget with machine unlearning , author=. 2015 IEEE symposium on security and privacy , pages=. 2015 , organization=
2015
-
[104]
2020 , eprint=
Machine Unlearning , author=. 2020 , eprint=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.