Recognition: unknown
Dual-Guard: Dual-Channel Latent Watermarking for Provenance and Tamper Localization in Diffusion Images
Pith reviewed 2026-05-10 02:50 UTC · model grok-4.3
The pith
Dual watermarks in latent space let users verify AI image origins and locate edits even after reprompting or local changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
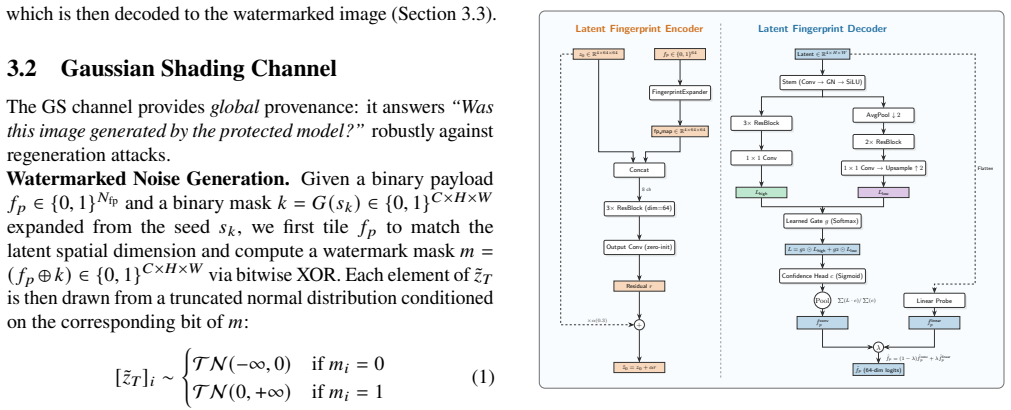
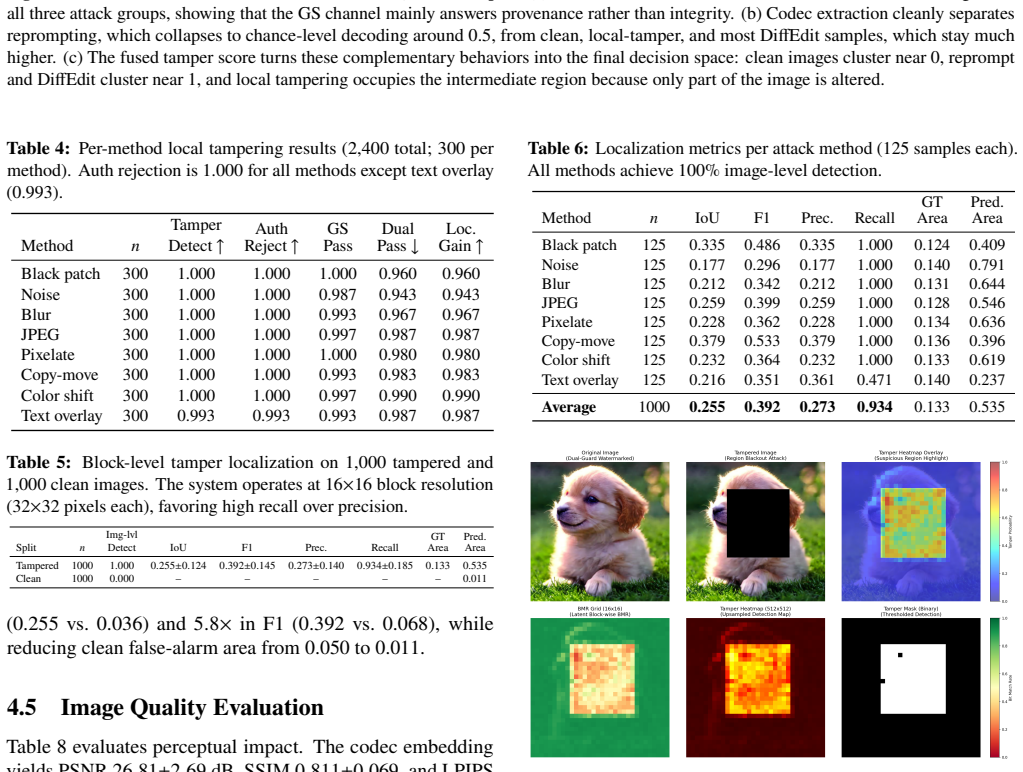
Dual-Guard places a Gaussian Shading watermark in the initial diffusion noise to serve as a global provenance signal and a Latent Fingerprint Codec in the final denoised latent to serve as a structured content anchor. Reprompting keeps the first signal intact but disrupts the second, while localized edits affect the content anchor only in the changed regions, yielding clean-image false rejection and tamper false alarm rates below 0.5 percent with near-complete detection on the benchmarked attacks.
What carries the argument
The dual-channel latent watermarking setup, with one channel anchoring provenance in initial noise and the other anchoring content structure in the final latent for region-specific detection.
If this is right
- Clean diffusion images can be authenticated with error rates below 0.5 percent.
- Reprompting attacks can be distinguished from the original generation via the surviving global signal.
- Localized tampering can be mapped to specific image regions using the disrupted content anchor.
- Both provenance verification and tamper localization become available in one framework without separate tools.
Where Pith is reading between the lines
- The same dual-signal idea could be tested on video or 3D diffusion outputs to see if temporal or volumetric consistency holds.
- If the method scales, social platforms might require such embedded signals for upload verification of AI content.
- Combining the two signals with existing pixel-space detectors could reduce overall error rates further.
- The approach raises the question of whether watermark removal tools will evolve to target both channels simultaneously.
Load-bearing premise
The chosen attacks and model setups are representative enough that the two signals will remain effective and imperceptible across real-world prompts and different diffusion architectures.
What would settle it
Running the same 2400-sample tests on a previously unseen diffusion model or on a new attack type outside the eight local methods and finding false alarm rates above 5 percent would show the dual signals do not generalize.
Figures



read the original abstract
The rapid adoption of diffusion-based generative models has intensified concerns over the attribution and integrity of AI-generated content (AIGC). Existing single-domain watermarking methods either fail under regeneration, remain vulnerable to black-box reprompting that enables adversarial framing, or provide no spatial evidence for tampered regions. We propose Dual-Guard, a dual-channel latent watermarking framework for practical provenance verification, framing resistance, and region-level tamper localization. Dual-Guard combines two complementary anchors: a Gaussian Shading watermark in the initial diffusion noise as a global provenance signal, and a Latent Fingerprint Codec in the final denoised latent as a structured content anchor. Reprompting tends to preserve the former while breaking the latter, whereas localized edits disturb the content anchor only in tampered regions. In Full mode on a 2,400-sample benchmark, Dual-Guard keeps clean-image authentication false rejection and tamper false alarm below one half of one percent, while maintaining near-complete detection under reprompting, diffusion editing, and eight local tampering attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dual-Guard, a dual-channel latent watermarking framework for diffusion-generated images. It embeds a Gaussian Shading watermark into the initial diffusion noise to serve as a global provenance signal and a Latent Fingerprint Codec into the final denoised latent to serve as a structured content anchor. The design exploits the fact that reprompting tends to preserve the noise-based signal while disrupting the content anchor, while localized edits affect only the tampered regions of the content anchor. On a 2,400-sample benchmark in Full mode, the method reports clean-image false rejection and tamper false alarm rates below 0.5% together with near-complete detection under reprompting, diffusion editing, and eight local tampering attacks.
Significance. If the reported performance numbers prove robust, the work would be a meaningful contribution to AIGC provenance and integrity verification. The dual-channel construction supplies complementary signals that address the regeneration vulnerability and lack of spatial localization in prior single-domain watermarking schemes. The concrete benchmark numbers on a moderately sized test set constitute a clear empirical strength, though their generalizability across model architectures and prompt distributions remains to be confirmed.
major comments (1)
- The central performance claims (FR/FA <0.5% on 2,400 samples and near-complete detection under the listed attacks) are load-bearing for the paper's contribution, yet the manuscript supplies no details on benchmark construction, attack parameterizations, baseline comparisons, or statistical significance tests. Without these, the degree to which the data supports the claims cannot be evaluated.
minor comments (2)
- The abstract should quantify 'near-complete detection' with explicit rates rather than the qualitative phrase.
- The terms 'Gaussian Shading watermark' and 'Latent Fingerprint Codec' are introduced without prior reference; a brief definition or citation in the abstract would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential contribution of the dual-channel design. We address the major comment on the need for greater transparency in the experimental details below.
read point-by-point responses
-
Referee: The central performance claims (FR/FA <0.5% on 2,400 samples and near-complete detection under the listed attacks) are load-bearing for the paper's contribution, yet the manuscript supplies no details on benchmark construction, attack parameterizations, baseline comparisons, or statistical significance tests. Without these, the degree to which the data supports the claims cannot be evaluated.
Authors: We agree that these details are required for readers to fully assess the reliability of the reported results. In the revised manuscript we will expand the Experiments section with: (1) a complete description of benchmark construction, including the 2,400-sample selection process, prompt corpus, diffusion model version and hyperparameters used for generation, and the rationale for the Full-mode evaluation protocol; (2) explicit parameterizations for every attack, covering reprompting strategies (prompt variation methods and iteration counts), diffusion editing settings (denoising steps, guidance scales, and edit strengths), and the precise configurations of the eight local tampering attacks (edit types, region sizes, and intensity parameters); (3) direct quantitative comparisons against representative single-domain watermarking baselines, reporting their FR/FA and detection rates under the identical attack suite; and (4) statistical analysis consisting of 95% confidence intervals for all binomial rates together with any hypothesis testing used to support the sub-0.5% claims. These additions will be placed in the main text or a clearly referenced appendix so that the empirical support for the performance numbers can be evaluated directly. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents an empirical watermarking framework evaluated on a 2400-sample benchmark under listed attacks. Performance claims (FR/FA <0.5%, near-complete detection) rest on experimental results rather than any derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps. No equations, ansatzes, or uniqueness theorems appear that reduce outputs to inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Gaussian Shading watermark
no independent evidence
-
Latent Fingerprint Codec
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bang An, Mucong Ding, Tahseen Rabbani, Aarav Agarwal, Yuancheng Xu, Chenghao Deng, Sicheng Zhu, Abdirisak Mohamed, Yuxin Wen, Tom Goldstein, and Furong Huang. 2024. WAVES: Benchmarking the Robustness of Image Watermarks. arXiv preprint arXiv:2401.08573. https://arxiv.org/abs/2401 .08573
-
[2]
Kasra Arabi, R. Teal Witter, Chinmay Hegde, and Niv Cohen. 2025. SEAL: Semantic Aware Image Water- marking. arXiv preprint arXiv:2503.12172. https: //arxiv.org/abs/2503.12172
-
[3]
YoshuaBengio,JérômeLouradour,RonanCollobert,and Jason Weston. 2009. Curriculum Learning. InProceed- ings of the 26th International Conference on Machine 8 Learning (ICML). Omnipress, Madison, WI, USA, 41– 48
2009
-
[4]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros
-
[5]
IEEE/CVF, Los Alamitos, CA, USA, 18392–18402
InstructPix2Pix: LearningtoFollowImageEditing Instructions.InProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 18392–18402
-
[6]
Tu Bui, Shruti Agarwal, Ning Yu, and John Collomosse
-
[7]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
RoSteALS: Robust Steganography using Autoen- coder Latent Space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 933–942
-
[8]
Hai Ci, Pei Yang, Yiren Song, and Mike Zheng Shou
-
[9]
RingID: Rethinking Tree-Ring Watermarking for Enhanced Multi-Key Identification, July 2024
RingID: Rethinking Tree-Ring Watermarking for Enhanced Multi-Key Identification. arXiv preprint arXiv:2404.14055. https://arxiv.org/abs/2404 .14055
-
[10]
Coalition for Content Provenance and Authenticity (C2PA). 2025. C2PA and Content Credentials Explainer. Official online specification.https://spec.c2pa.or g/specifications/specifications/2.3/explai ner/Explainer.html
2025
-
[11]
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. 2023. DiffEdit: Diffusion-based SemanticImageEditingwithMaskGuidance.InInterna- tional Conference on Learning Representations (ICLR). OpenReview.net, Virtual, 16 pages
2023
-
[12]
Chenfan Dong, Yuliang Liu, Haoyu Chen, and Lian- wen Jin. 2023. MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence45, 3 (2023), 3539–3553
2023
-
[13]
Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. 2023. The Stable Sig- nature: Rooting Watermarks in Latent Diffusion Models. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV). IEEE/CVF, Los Alamitos, CA, USA, 22466–22477
2023
-
[14]
Pierre Fernandez, Alexandre Sablayrolles, Teddy Furon, Hervé Jégou, and Matthijs Douze. 2022. Watermark- ing Images in Self-Supervised Latent Spaces. InIEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP). IEEE, Piscataway, NJ, USA, 3054–3058
2022
-
[15]
Fabrizio Guillaro, Davide Cozzolino, Avneesh Sud, Nicholas Memon, and Luisa Verdoliva. 2023. Tru- For: Leveraging All-Round Clues for Trustworthy Image Forgery Detection and Localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- ternRecognition(CVPR).IEEE/CVF,LosAlamitos,CA, USA, 20606–20615
2023
-
[16]
AmirHertz,RonMokady,JayTenenbaum,KfirAberman, Yael Pritch, and Daniel Cohen-Or. 2023. Prompt-to- Prompt Image Editing with Cross-Attention Control. In International Conference on Learning Representations (ICLR). OpenReview.net, Virtual, 18 pages
2023
-
[17]
Denois- ingDiffusionProbabilisticModels.InAdvancesinNeural Information Processing Systems (NeurIPS), Vol
JonathanHo,AjayJain,andPieterAbbeel.2020. Denois- ingDiffusionProbabilisticModels.InAdvancesinNeural Information Processing Systems (NeurIPS), Vol. 33. Cur- ran Associates, Inc., Red Hook, NY, USA, 6840–6851
2020
-
[18]
Myung-Joon Kwon, In-Jae Yu, Seung-Hun Nam, and Heung-Kyu Lee. 2022. CAT-Net: Compression Artifact TracingNetworkforDetectionandLocalizationofImage Splicing.International Journal of Computer Vision (IJCV)130 (2022), 2492–2515
2022
-
[19]
Pearson Prentice Hall, Upper Saddle River, NJ, USA
ShuLinandDanielJ.Costello.2004.ErrorControlCod- ing: Fundamentals and Applications(2nd ed.). Pearson Prentice Hall, Upper Saddle River, NJ, USA
2004
-
[20]
Nils Lukas and Florian Kerschbaum. 2024. Leveraging OptimizationforAdaptiveAttacksonImageWatermarks. InInternationalConferenceonLearningRepresentations (ICLR). OpenReview.net, Virtual, 22 pages
2024
-
[21]
Xiyang Luo, Ruohan Zhan, Huiwen Chang, Feng Yang, and Peyman Milanfar. 2020. Distortion Agnostic Deep Watermarking. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 13548– 13557
2020
-
[22]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
ChenlinMeng,YutongHe,YangSong,JiamingSong,Jia- junWu, Jun-YanZhu, andStefanoErmon.2022. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. InInternational Conference on Learning Representations (ICLR). OpenReview.net, Vir- tual, 20 pages
2022
-
[23]
Andreas Müller, Denis Lukovnikov, Jonas Thietke, Asja Fischer, and Erwin Quiring. 2025. Black-Box Forgery AttacksonSemanticWatermarksforDiffusionModels.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 20937–20946
2025
-
[24]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical Text- Conditional Image Generation with CLIP Latents. arXiv preprint arXiv:2204.06125. https://arxiv.org/ab s/2204.06125
work page internal anchor Pith review arXiv 2022
-
[25]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 10684–10695. 9
2022
-
[26]
Mehrdad Saberi, Vinu Sankar Sadasivan, Keivan Rezaei, Aounon Kumar, Atoosa Chegini, Wenxiao Wang, and Soheil Feizi. 2024. Robustness of AI-Image De- tectors: Fundamental Limits and Practical Attacks. arXiv:2310.00076 [cs.CV] doi:10.48550/arXiv.2 310.00076
-
[27]
Fleet, and MohammadNorouzi.2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J. Fleet, and MohammadNorouzi.2022. PhotorealisticText-to-Image Diffusion Models with Deep Language Understanding. InAdvances in Neural Information Processing Systems (...
2022
-
[28]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2021. Denoising Diffusion Implicit Models. InInternational Conference on Learning Representations (ICLR). Open- Review.net, Virtual, 16 pages
2021
-
[29]
Ste- gaStamp: Invisible Hyperlinks in Physical Photographs
MatthewTancik,BenMildenhall,andRenNg.2020. Ste- gaStamp: Invisible Hyperlinks in Physical Photographs. InProceedings of the IEEE/CVF Conference on Com- puterVisionandPatternRecognition(CVPR).IEEE/CVF, Los Alamitos, CA, USA, 2117–2126
2020
-
[30]
Junke Wang, Zuxuan Wu, Jingjing Chen, Xintong Han, Abhinav Shrivastava, Ser-Nam Lim, and Yu-Gang Jiang
-
[31]
InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
ObjectFormer for Image Manipulation Detection and Localization. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 2364– 2373
-
[32]
Bovik, Hamid R
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. 2004. Image Quality Assessment: From Error Visibility to Structural Similarity.IEEE Transactions on Image Processing13, 4 (2004), 600– 612
2004
-
[33]
Yuxin Wen, John Kirchenbauer, Jonas Geiping, and Tom Goldstein. 2023. Tree-Ring Watermarks: Finger- prints for Diffusion Images that are Invisible and Robust. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36. Curran Associates, Inc., Red Hook, NY, USA, 24 pages
2023
-
[34]
Yue Wu, Wael AbdAlmageed, and Premkumar Natara- jan. 2019. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries with Anomalous Features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 9543– 9552
2019
-
[35]
Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weim- ing Zhang, and Nenghai Yu. 2024. Gaussian Shading: Provable Performance-Lossless Image Watermarking for Diffusion Models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, Los Alamitos, CA, USA, 12162– 12171
2024
-
[36]
Ning Yu, Vladislav Skripniuk, Sahar Abdelnabi, and Mario Fritz. 2021. Artificial Fingerprinting for Genera- tive Models: Rooting Deepfake Attribution in Training Data. InProceedings of the IEEE/CVF International ConferenceonComputerVision(ICCV).IEEE/CVF,Los Alamitos, CA, USA, 14448–14457
2021
- [37]
-
[38]
Xuandong Zhao, Kexun Zhang, Zihao Su, Saastha Vasan, Ilya Grishchenko, Christopher Kruegel, Gio- vanni Vigna, Yu-Xiang Wang, and Lei Li. 2024. In- visible Image Watermarks Are Provably Removable Using Generative AI. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), Vol. 37. Cur- ran Associates, Inc., Red Hook, NY, USA, 14 pages. https://pro...
2024
- [39]
-
[40]
JirenZhu,RussellKaplan,JustinJohnson,andLiFei-Fei
-
[41]
In Proceedings of the European Conference on Computer Vision (ECCV)
HiDDeN: Hiding Data with Deep Networks. In Proceedings of the European Conference on Computer Vision (ECCV). Springer, Cham, Switzerland, 657–672. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.