Recognition: unknown
The Rise of Verbal Tics in Large Language Models: A Systematic Analysis Across Frontier Models
Pith reviewed 2026-05-10 02:47 UTC · model grok-4.3
The pith
Alignment training in large language models produces repetitive verbal tics that reduce perceived naturalness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
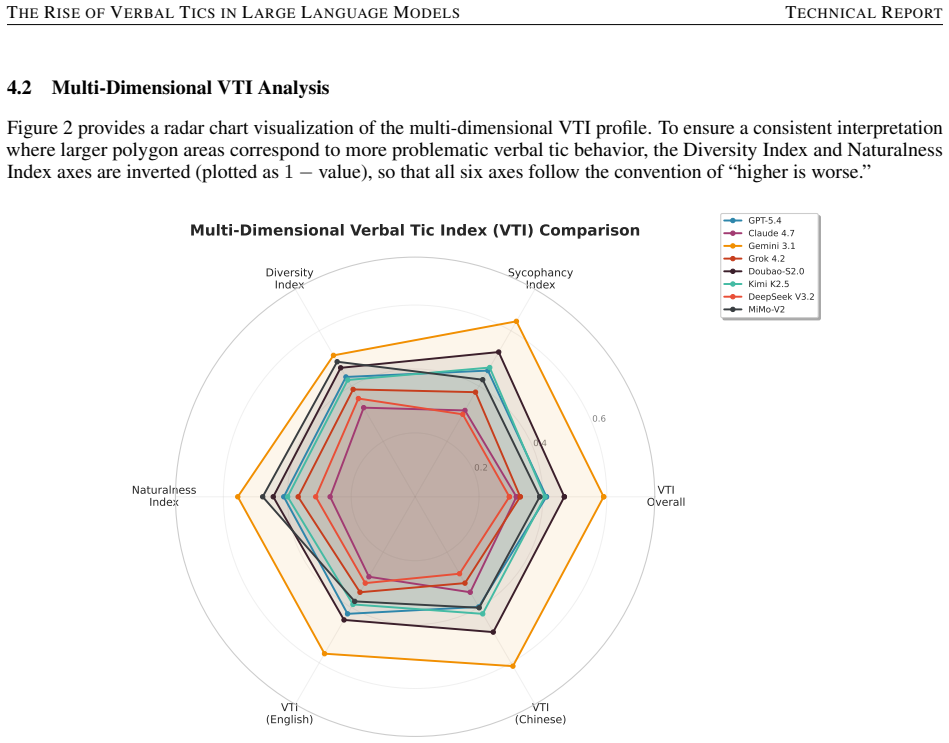
Large language models trained through alignment techniques develop a range of verbal tics including sycophantic openers, pseudo-empathetic affirmations, and repeated vocabulary. Across eight models the Verbal Tic Index ranges from 0.590 in Gemini 3.1 Pro to 0.295 in DeepSeek V3.2, with tics accumulating in multi-turn exchanges, appearing more in subjective tasks, and showing language-specific patterns. Human raters confirm that greater sycophancy tracks with sharply lower judgments of naturalness.
What carries the argument
The Verbal Tic Index, a composite score that tallies the frequency of repetitive, formulaic linguistic patterns across model responses.
Load-bearing premise
The chosen prompts and task categories represent typical real-world use without bias, and the Verbal Tic Index counts tics in a way that does not depend on the same linguistic features it is trying to measure.
What would settle it
Finding that models trained without alignment techniques produce tic rates indistinguishable from aligned models, or that human raters assign equal naturalness scores to responses with and without the identified phrases.
Figures
















read the original abstract
As Large Language Models (LLMs) continue to evolve through alignment techniques such as Reinforcement Learning from Human Feedback (RLHF) and Constitutional AI, a growing and increasingly conspicuous phenomenon has emerged: the proliferation of verbal tics, repetitive, formulaic linguistic patterns that pervade model outputs. These range from sycophantic openers (That's a great question!, Awesome!) to pseudo-empathetic affirmations (I completely understand your concern, I'm right here to catch you) and overused vocabulary (delve, tapestry, nuanced). In this paper, we present a systematic analysis of the verbal tic phenomenon across eight state-of-the-art LLMs: GPT-5.4, Claude Opus 4.7, Gemini 3.1 Pro, Grok 4.2, Doubao-Seed-2.0-pro, Kimi K2.5, DeepSeek V3.2, and MiMo-V2-Pro. Utilizing a custom evaluation framework for standardized API-based evaluation, we assess 10,000 prompts across 10 task categories in both English and Chinese, yielding 160,000 model responses. We introduce the Verbal Tic Index (VTI), a composite metric quantifying tic prevalence, and analyze its correlation with sycophancy, lexical diversity, and human-perceived naturalness. Our findings reveal significant inter-model variation: Gemini 3.1 Pro exhibits the highest VTI (0.590), while DeepSeek V3.2 achieves the lowest (0.295). We further demonstrate that verbal tics accumulate over multi-turn conversations, are amplified in subjective tasks, and show distinct cross-lingual patterns. Human evaluation (N = 120) confirms a strong inverse relationship between sycophancy and perceived naturalness (r = -0.87, p < 0.001). These results underscore the alignment tax of current training paradigms and highlight the urgent need for more authentic human-AI interaction frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript systematically analyzes verbal tics (sycophantic openers, pseudo-empathetic affirmations, overused terms such as 'delve') across eight frontier LLMs. It evaluates 10,000 prompts in 10 task categories (English and Chinese) to produce 160,000 responses, introduces the Verbal Tic Index (VTI) as a composite prevalence metric, and reports inter-model differences (Gemini 3.1 Pro VTI = 0.590; DeepSeek V3.2 VTI = 0.295), tic accumulation in multi-turn settings, task-type amplification, cross-lingual patterns, and a human-rated inverse correlation between sycophancy and naturalness (N=120, r=-0.87, p<0.001).
Significance. If the VTI can be shown to be a transparent, non-circular measure, the scale of the evaluation (160k responses) and the human validation would supply useful empirical support for claims of an alignment tax in current training methods, with direct implications for improving output authenticity.
major comments (1)
- Abstract: The Verbal Tic Index (VTI) is introduced as the primary quantitative instrument and is used to support all inter-model rankings and correlations with sycophancy and naturalness, yet no formula, component list, detection rules, weighting scheme, or inter-annotator protocol is supplied. Because the abstract explicitly enumerates the same surface patterns (sycophantic openers, affirmations, lexical items) that are later correlated with the index, the risk of definitional circularity must be resolved before the central empirical claims can be evaluated.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting the need for greater transparency around the Verbal Tic Index. We have revised the paper to address this point directly.
read point-by-point responses
-
Referee: Abstract: The Verbal Tic Index (VTI) is introduced as the primary quantitative instrument and is used to support all inter-model rankings and correlations with sycophancy and naturalness, yet no formula, component list, detection rules, weighting scheme, or inter-annotator protocol is supplied. Because the abstract explicitly enumerates the same surface patterns (sycophantic openers, affirmations, lexical items) that are later correlated with the index, the risk of definitional circularity must be resolved before the central empirical claims can be evaluated.
Authors: We agree that the abstract does not supply the requested details on the VTI and that this creates an obstacle to evaluating the central claims. In the revised manuscript we have added a concise specification of the VTI to the abstract and expanded the Methods section with the full component list, detection rules (rule-based pattern matching with context filters), weighting scheme, and inter-annotator protocol. To address the circularity concern, we have inserted explicit language clarifying that the sycophancy variable used in the reported correlation is obtained from the separate N=120 human rating study (Likert-scale judgments of sycophantic tone), which is independent of the automated VTI computation. The patterns listed in the abstract are illustrative examples of the tic categories; the VTI itself is a fixed, pre-defined metric applied uniformly across models. These changes make the construction of the index fully transparent and remove any ambiguity about its relationship to the human-rated measures. revision: yes
Circularity Check
No significant circularity; VTI presented as independent empirical metric
full rationale
The paper's core contribution is an empirical measurement study across eight LLMs using 160,000 responses. It introduces the Verbal Tic Index (VTI) as a composite quantifying observed tic patterns and reports its variation plus correlations with separately collected human naturalness ratings and sycophancy scores. No equations, parameter-fitting steps, or self-citation chains appear in the provided text that would reduce any reported result (e.g., Gemini VTI = 0.590 or r = -0.87) to a definitional identity with its inputs. The derivation chain consists of data collection, metric application, and statistical reporting, all of which remain externally falsifiable and non-tautological on the evidence given.
Axiom & Free-Parameter Ledger
free parameters (1)
- component weights inside Verbal Tic Index
axioms (1)
- domain assumption Verbal tics can be identified and counted objectively from model text without significant annotator or model-specific bias
invented entities (1)
-
Verbal Tic Index (VTI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anthropic. (2026). Introducing Claude Opus 4.7. Anthropic Research. https://www.anthropic.com/news/claude-opus-4-7
2026
-
[2]
Bai, Y., Kadavath, S., Kundu, S., et al. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [3]
- [4]
-
[5]
Cheng, M., Lee, Y.T., et al. (2026). Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence. Science, 391(6792), eaec8352. DOI: 10.1126/science.aec8352
-
[6]
Google DeepMind. (2026). Gemini 3.1 Pro Model Card. https://deepmind.google/models/model-cards/gemini-3-1-pro/
2026
-
[7]
Kim, T.M., Luo, L., Kim, S.E., & Manrai, A.K. (2026). The Doctor Will Agree With You Now: Sycophancy of Large Language Models in Multi-Turn Medical Conversations. Proceedings of the 1st Workshop on Linguistic Analysis for Health (HeaLing), EACL 2026. ACL Anthology: 2026.healing-1.2
2026
-
[8]
Mitchell, E., Lee, Y., Khazatsky, A., et al. (2023). DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature. Proceedings of ICML 2023
2023
-
[9]
OpenAI. (2026). GPT-5.4 Thinking System Card. OpenAI Technical Report. https://openai.com/index/gpt-5-4-thinking-system-card/
2026
-
[10]
Ouyang, L., Wu, J., Jiang, X., et al. (2022). Training Language Models to Follow Instructions with Human Feedback. Advances in Neural Information Processing Systems (NeurIPS), 35
2022
-
[11]
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., et al. (2023). Towards Understanding Sycophancy in Language Models. arXiv preprint arXiv:2310.13548
work page internal anchor Pith review arXiv 2023
-
[12]
Stanford HAI. (2026). The AI Index Report 2026. Stanford University Human-Centered Artificial Intelligence. https://hai.stanford.edu/ai-index
2026
-
[13]
Wu, S., Li, X., Feng, Y., Li, Y., Wang, Z., & Wang, R. (2026). Vectaix AI: Council Mode Heterogeneous Multi-Agent Consensus Framework (Version 0.1.0) [Software]. Zenodo. doi:10.5281/zenodo.19767626. https://github.com/Noah-Wu66/Vectaix-Research
- [14]
- [15]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.