Recognition: unknown
How Do Answer Tokens Read Reasoning Traces? Self-Reading Patterns in Thinking LLMs for Quantitative Reasoning
Pith reviewed 2026-05-10 02:36 UTC · model grok-4.3
The pith
Answer tokens in thinking LLMs attend to reasoning traces with a forward-drifting focus on semantic anchors when producing correct answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
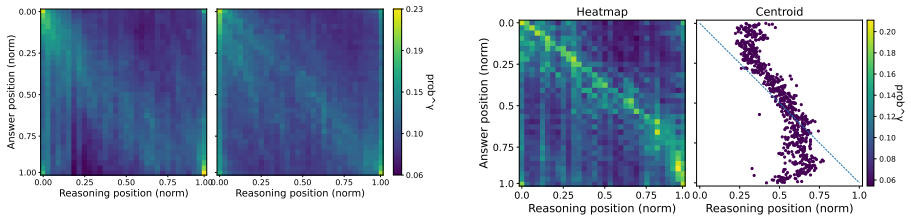
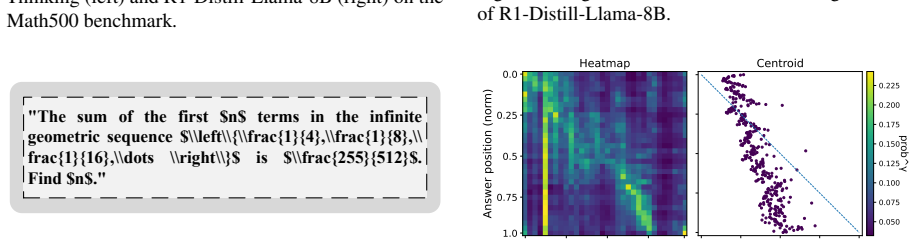
Thinking LLMs produce reasoning traces before answering. The answer tokens read these traces via attention, and correct answers correspond to a benign self-reading pattern with forward drift of the reading focus along the reasoning trace and persistent concentration on key semantic anchors, while incorrect ones are diffuse and irregular. This is interpreted as internal certainty where the model commits to a viable solution branch and integrates key evidence. A training-free steering method uses Self-Reading Quality (SRQ) scores, combining geometric metrics for process control with semantic metrics for content monitoring, to select data for steering vectors that guide toward this pattern and
What carries the argument
Self-Reading Quality (SRQ) scores that combine geometric metrics for process control with semantic metrics for content monitoring to select examples for building steering vectors that promote benign self-reading patterns in answer token attention to reasoning traces.
If this is right
- Steering models toward the benign self-reading pattern produces consistent accuracy gains on quantitative reasoning tasks.
- The approach requires no training and works by guiding answer token attention during decoding.
- Correct solutions correspond to the model committing to one viable branch through focused integration of evidence from its trace.
- Steering away from diffuse and irregular attention reduces the production of incorrect final answers.
- The pattern indicates an internal certainty mechanism that can be monitored and encouraged via geometric and semantic metrics.
Where Pith is reading between the lines
- The same attention analysis might expose self-verification mechanisms in other domains such as code generation or commonsense reasoning.
- If the pattern is causal, it could motivate architectures that explicitly encourage forward drift in long reasoning chains.
- Experiments on models of different sizes could test whether the benign pattern strengthens with scale or appears only above a capacity threshold.
- Comparing the internal drift and anchor concentration to human step-by-step solving behavior might connect model internals to cognitive focus shifts.
Load-bearing premise
The observed attention patterns from answer tokens to reasoning traces are causally linked to correctness rather than merely correlated, and steering vectors derived from SRQ-selected examples will reliably induce the benign pattern on new inputs without introducing new failure modes.
What would settle it
Applying the SRQ steering method to a new held-out set of quantitative problems and measuring no accuracy improvement or a drop in performance would challenge the method's effectiveness; alternatively, finding the forward-drift concentration pattern equally often in incorrect answers would undermine its alignment with correctness.
Figures










read the original abstract
Thinking LLMs produce reasoning traces before answering. Prior activation steering work mainly targets on shaping these traces. It remains less understood how answer tokens actually read and integrate the reasoning to produce reliable outcomes. Focusing on quantitative reasoning, we analyze the answer-to-reasoning attention and observe a benign self-reading pattern aligned with correctness, characterized by a forward drift of the reading focus along the reasoning trace and a persistent concentration on key semantic anchors, whereas incorrect solutions exhibit diffuse and irregular attention pattern. We interpret this as internal certainty during answer decoding, where the model commits to a viable solution branch and integrates key evidence. Following this, we propose a training-free steering method driven by Self-Reading Quality (SRQ) scores combining geometric metrics for process control with semantic metrics for content monitoring. SRQ selects data to build steering vectors that guide inference toward benign self-reading and away from uncertain and disorganized reading. Experiments show that our method yields consistent accuracy gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes answer-to-reasoning attention patterns in thinking LLMs on quantitative reasoning tasks. It reports a benign self-reading pattern for correct solutions (forward drift of attention focus along the trace plus persistent concentration on semantic anchors) versus diffuse, irregular patterns for incorrect solutions. From this observation the authors define Self-Reading Quality (SRQ) scores that combine geometric process-control metrics with semantic content-monitoring metrics; SRQ is used to select examples for constructing training-free steering vectors that promote the benign pattern at inference time. Experiments are reported to produce consistent accuracy gains.
Significance. If the empirical results hold, the work supplies a concrete observational link between internal attention dynamics and solution correctness and demonstrates a practical, training-free steering technique that targets those dynamics. The geometric-plus-semantic formulation of SRQ and the explicit framing of steering as guidance toward an observed benign pattern are strengths that could inform both interpretability studies and lightweight control methods for reasoning models.
major comments (2)
- Experiments section: the central claim of 'consistent accuracy gains' is load-bearing yet the manuscript provides no visible details on dataset sizes, number of runs, baseline steering methods, statistical significance tests, or ablations isolating the geometric versus semantic components of SRQ. Without these, the robustness and reproducibility of the reported improvements cannot be assessed.
- Method section (SRQ construction): the geometric and semantic metrics are computed on the same reasoning traces that are later labeled by correctness for steering-vector selection. While the metrics themselves are not described as fitted parameters, the paper should explicitly demonstrate that the SRQ selection criterion remains independent of the downstream correctness labels used to validate the steering effect.
minor comments (2)
- Abstract and §2: the phrase 'self-reading pattern' is introduced without a concise operational definition; a one-sentence gloss would improve immediate readability.
- Notation: the combination rule for geometric and semantic terms inside the SRQ score is described in prose but would benefit from an explicit equation (e.g., a weighted sum or product) to remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments highlight important areas for improving clarity and rigor. We address each point below and will revise the manuscript to incorporate the suggested additions and clarifications.
read point-by-point responses
-
Referee: Experiments section: the central claim of 'consistent accuracy gains' is load-bearing yet the manuscript provides no visible details on dataset sizes, number of runs, baseline steering methods, statistical significance tests, or ablations isolating the geometric versus semantic components of SRQ. Without these, the robustness and reproducibility of the reported improvements cannot be assessed.
Authors: We agree that the current Experiments section is insufficiently detailed for assessing robustness. In the revision we will expand it to report: exact dataset sizes and train/test splits used for steering-vector construction and evaluation; the number of independent runs (with means and standard deviations); comparisons against baseline steering methods (random vectors, mean activation vectors, and prior activation-steering baselines); statistical significance tests (paired t-tests or Wilcoxon signed-rank tests with p-values); and ablations that separately disable the geometric and semantic components of SRQ to quantify their individual contributions. These additions will directly address reproducibility concerns. revision: yes
-
Referee: Method section (SRQ construction): the geometric and semantic metrics are computed on the same reasoning traces that are later labeled by correctness for steering-vector selection. While the metrics themselves are not described as fitted parameters, the paper should explicitly demonstrate that the SRQ selection criterion remains independent of the downstream correctness labels used to validate the steering effect.
Authors: The SRQ metrics are computed exclusively from attention-head statistics (geometric drift and anchor concentration) and semantic token embeddings; no correctness label enters the metric formulas. Correctness labels are applied only after SRQ scoring, solely to select the subset of high-SRQ traces that happen to be correct for building the steering vector. In the revision we will add an explicit paragraph and a supplementary figure showing (i) the SRQ formula with no label dependence, (ii) the correlation between SRQ and correctness on held-out unlabeled traces, and (iii) a note that SRQ can be computed at inference time on new, unlabeled reasoning traces. This demonstrates that the selection criterion itself is label-independent. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper first observes attention patterns (forward drift and anchor concentration) in answer-to-reasoning attention on quantitative reasoning traces, then defines SRQ as an operationalization of those patterns via geometric and semantic metrics. SRQ is used to select examples from which steering vectors are constructed and applied at inference time. This is a standard observe-then-intervene pipeline; the metrics directly encode the reported observations rather than being fitted parameters, the steering vectors are derived from selected data and tested for accuracy gains on new inputs, and no equation or step reduces the claimed result to its own inputs by construction. No self-citation chains, uniqueness theorems, or ansatz smuggling appear in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Weston and Sainbayar Sukhbaatar , title =
Tianhao Wu and Janice Lan and Weizhe Yuan and Jiantao Jiao and Jason E. Weston and Sainbayar Sukhbaatar , title =. Forty-second International Conference on Machine Learning,
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[3]
Seal: Steer- able reasoning calibration of large language models for free
Runjin Chen and Zhenyu Zhang and Junyuan Hong and Souvik Kundu and Zhangyang Wang , title =. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2504.07986 , eprinttype =. 2504.07986 , timestamp =
-
[4]
The Thirteenth International Conference on Learning Representations,
Alessandro Stolfo and Vidhisha Balachandran and Safoora Yousefi and Eric Horvitz and Besmira Nushi , title =. The Thirteenth International Conference on Learning Representations,
-
[5]
Leon Eshuijs and Archie Chaudhury and Alan McBeth and Ethan Nguyen , title =. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2505.17760 , eprinttype =. 2505.17760 , timestamp =
-
[6]
arXiv preprint arXiv:2506.18167 , year=
Constantin Venhoff and Iv. Understanding Reasoning in Thinking Language Models via Steering Vectors , journal =. doi:10.48550/ARXIV.2506.18167 , eprinttype =. 2506.18167 , timestamp =
-
[7]
Seyedarmin Azizi and Erfan Baghaei Potraghloo and Massoud Pedram , title =. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2507.04742 , eprinttype =. 2507.04742 , timestamp =
-
[8]
Zekai Zhao and Qi Liu and Kun Zhou and Zihan Liu and Yifei Shao and Zhiting Hu and Biwei Huang , title =. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2505.17697 , eprinttype =. 2505.17697 , timestamp =
-
[9]
Jue Zhang and Qingwei Lin and Saravan Rajmohan and Dongmei Zhang , title =. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2509.23676 , eprinttype =. 2509.23676 , timestamp =
-
[10]
Journal of experimental psychology: General , year = 1997, pages =
Asher Koriat , title =. Journal of experimental psychology: General , year = 1997, pages =
1997
-
[11]
Psychology of learning and motivation , publisher =
Thomas O Nelson , title =. Psychology of learning and motivation , publisher =
-
[12]
Layer by Layer: Uncovering Hidden Representations in Language Models , booktitle =
Oscar Skean and Md Rifat Arefin and Dan Zhao and Niket Patel and Jalal Naghiyev and Yann LeCun and Ravid Shwartz. Layer by Layer: Uncovering Hidden Representations in Language Models , booktitle =
-
[13]
doi: 10.18653/v1/2024.findings-naacl.296
Anna Langedijk and Hosein Mohebbi and Gabriele Sarti and Willem H. Zuidema and Jaap Jumelet , title =. Findings of the Association for Computational Linguistics:. doi:10.18653/V1/2024.FINDINGS-NAACL.296 , timestamp =
-
[14]
Tak and Amin Banayeeanzade and Anahita Bolourani and Mina Kian and Robin Jia and Jonathan Gratch , title =
Ala N. Tak and Amin Banayeeanzade and Anahita Bolourani and Mina Kian and Robin Jia and Jonathan Gratch , title =. Findings of the Association for Computational Linguistics,
-
[15]
Steering Knowledge Selection Behaviours in
Yu Zhao and Alessio Devoto and Giwon Hong and Xiaotang Du and Aryo Pradipta Gema and Hongru Wang and Xuanli He and Kam. Steering Knowledge Selection Behaviours in. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies,. doi:10.18653/V1/2025.NAACL-LONG.264 , t...
-
[16]
Entropy-lens: The information signature of transformer computations.arXiv preprint arXiv:2502.16570,
Riccardo Ali and Francesco Caso and Christopher Irwin and Pietro Li. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2502.16570 , eprinttype =. 2502.16570 , timestamp =
-
[17]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[18]
Training Verifiers to Solve Math Word Problems
Karl Cobbe and Vineet Kosaraju and Mohammad Bavarian and Mark Chen and Heewoo Jun and Lukasz Kaiser and Matthias Plappert and Jerry Tworek and Jacob Hilton and Reiichiro Nakano and Christopher Hesse and John Schulman , title =. CoRR , year = 2021, url =. 2110.14168 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
The Twelfth International Conference on Learning Representations,
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. The Twelfth International Conference on Learning Representations,
-
[20]
Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year = 2021, editor =
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , title =. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year = 2021, editor =
2021
-
[21]
Are NLP Models really able to Solve Simple Math Word Problems?
Arkil Patel and Satwik Bhattamishra and Navin Goyal , title =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. doi:10.18653/V1/2021.NAACL-MAIN.168 , timestamp =
-
[22]
Data mining and knowledge discovery , 33(4):917–963
Johannes Welbl and Nelson F. Liu and Matt Gardner , title =. Proceedings of the 3rd Workshop on Noisy User-generated Text, NUT@EMNLP 2017, Copenhagen, Denmark, September 7, 2017 , year = 2017, pages =. doi:10.18653/V1/W17-4413 , timestamp =
-
[23]
CoRR , year = 2023, url =
Alexander Matt Turner and Lisa Thiergart and Gavin Leech and David Udell and Juan J Vazquez and Ulisse Mini and Monte MacDiarmid , title =. CoRR , year = 2023, url =
2023
-
[24]
Improving Reasoning Performance in Large Language Models via Representation Engineering , booktitle =
Bertram H. Improving Reasoning Performance in Large Language Models via Representation Engineering , booktitle =
-
[25]
Joris Postmus and Steven Abreu , title =. CoRR , year = 2024, url =. doi:10.48550/ARXIV.2410.16314 , eprinttype =. 2410.16314 , timestamp =
-
[26]
Zihao Li and Xu Wang and Yuzhe Yang and Ziyu Yao and Haoyi Xiong and Mengnan Du , title =. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2505.15634 , eprinttype =. 2505.15634 , timestamp =
-
[27]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year = 2025, pages =
Yiru Tang and Kun Zhou and Yingqian Min and Wayne Xin Zhao and Jing Sha and Zhichao Sheng and Shijin Wang , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year = 2025, pages =
2025
-
[28]
Chung. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2503.22048 , eprinttype =. 2503.22048 , timestamp =
-
[29]
American Invitational Mathematics Examination (
-
[30]
Data Intelligence , year = 2024, volume = 6, number = 2, pages =
Chen, Songlin and Wang, Weicheng and Chen, Xiaoliang and Lu, Peng and Yang, Zaiyan and Du, Yajun , title =. Data Intelligence , year = 2024, volume = 6, number = 2, pages =
2024
-
[31]
CoRR , year = 2025, url =
Dynamic Early Exit in Reasoning Models , author =. CoRR , year = 2025, url =
2025
-
[32]
Yi Liu and Xiangyu Liu and Zequn Sun and Wei Hu , title =. CoRR , year = 2025, url =. doi:10.48550/ARXIV.2508.18760 , eprinttype =. 2508.18760 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.