Recognition: unknown
How Far Are Video Models from True Multimodal Reasoning?
Pith reviewed 2026-05-10 02:41 UTC · model grok-4.3
The pith
State-of-the-art video models handle basic understanding but fail on logically grounded and interactive video generation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
While state-of-the-art video models demonstrate competence on certain understanding and reasoning subtasks, they fall substantially short with logically grounded and interactive generation tasks, achieving success rates below 25 percent and approximately zero percent, respectively.
What carries the argument
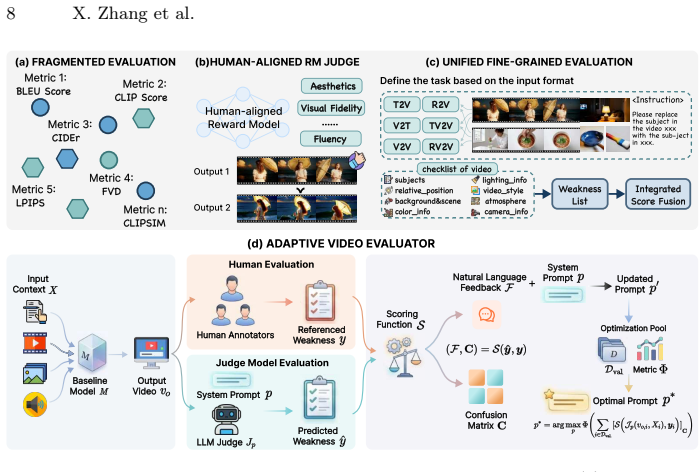
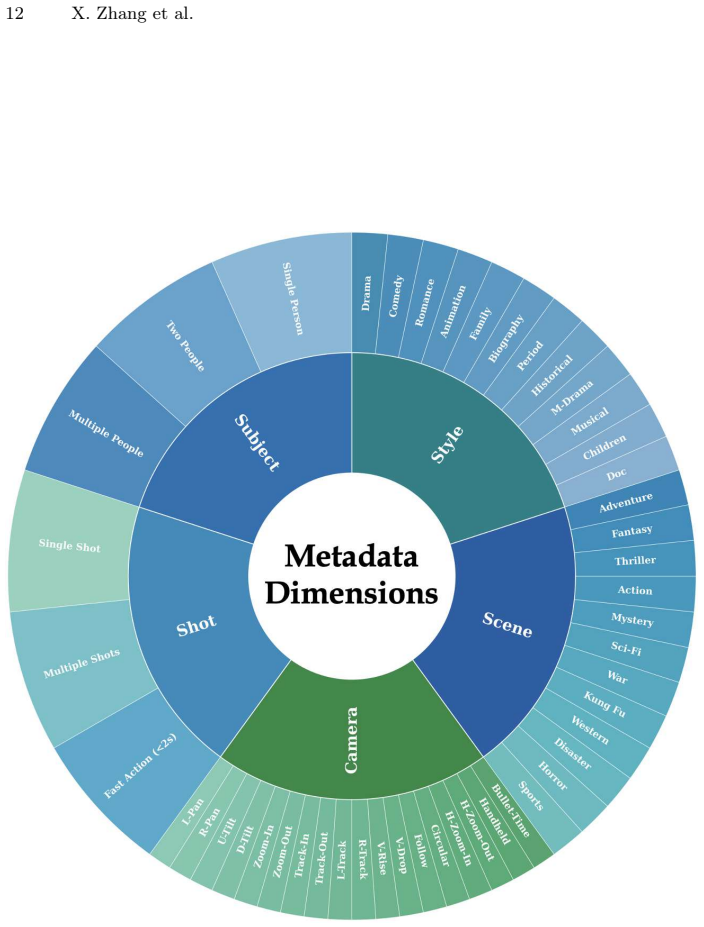
CLVG-Bench, a Context Learning in Video Generation evaluation framework consisting of manually annotated metadata across 6 categories and 47 subcategories, together with the Adaptive Video Evaluator that supplies textual feedback aligned to human perception.
Load-bearing premise
The manually created tasks in CLVG-Bench and the Adaptive Video Evaluator capture true multimodal reasoning in a way that matches human expert judgment without systematic bias or gaps.
What would settle it
A new set of video generation examples requiring interactive physical reasoning that current models solve at high rates while human raters still score the outputs as coherent.
Figures













read the original abstract
Despite remarkable progress toward general-purpose video models, a critical question remains unanswered: how far are these models from achieving true multimodal reasoning? Existing benchmarks fail to address this question rigorously, as they remain constrained by straightforward task designs and fragmented evaluation metrics that neglect complex multimodal reasoning. To bridge this gap, we introduce CLVG-Bench, an evaluation framework designed to probe video models' zero-shot reasoning capabilities via Context Learning in Video Generation. CLVG-Bench comprises more than 1,000 high-quality, manually annotated metadata across 6 categories and 47 subcategories, covering complex scenarios including physical simulation, logical reasoning, and interactive contexts. To enable rigorous and scalable assessment, we further propose an Adaptive Video Evaluator (AVE) that aligns with human expert perception using minimal annotations, delivering interpretable textual feedback across diverse video context tasks. Extensive experiments reveal a striking answer to our central question: while state-of-the-art (SOTA) video models, such as Seedance 2.0, demonstrate competence on certain understanding and reasoning subtasks, they fall substantially short with logically grounded and interactive generation tasks (achieving success rates <25% and ~0%, respectively), exposing multimodal reasoning and physical grounding as critical bottlenecks. By systematically quantifying these limitations, the proposed method provides actionable feedbacks and a clear roadmap toward truly robust, general-purpose video models. CLVG-Bench and code are released here.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLVG-Bench, a new evaluation framework with over 1,000 manually annotated metadata items across 6 categories and 47 subcategories to test video models' zero-shot multimodal reasoning via context learning in video generation tasks, covering physical simulation, logical reasoning, and interactive contexts. It proposes an Adaptive Video Evaluator (AVE) that claims to align with human expert perception using minimal annotations while providing interpretable textual feedback. Experiments on SOTA models such as Seedance 2.0 show competence on understanding and some reasoning subtasks but substantial shortfalls on logically grounded generation (<25% success) and interactive generation (~0% success), identifying multimodal reasoning and physical grounding as critical bottlenecks. The benchmark and code are released.
Significance. If the benchmark tasks are well-constructed and AVE produces reliable human-aligned labels, the work would offer a more rigorous probe of true multimodal reasoning than existing fragmented benchmarks, with actionable insights and a roadmap for video model improvement. The release of data and code supports reproducibility. However, the significance hinges on unverified aspects of the new evaluator and annotation process.
major comments (2)
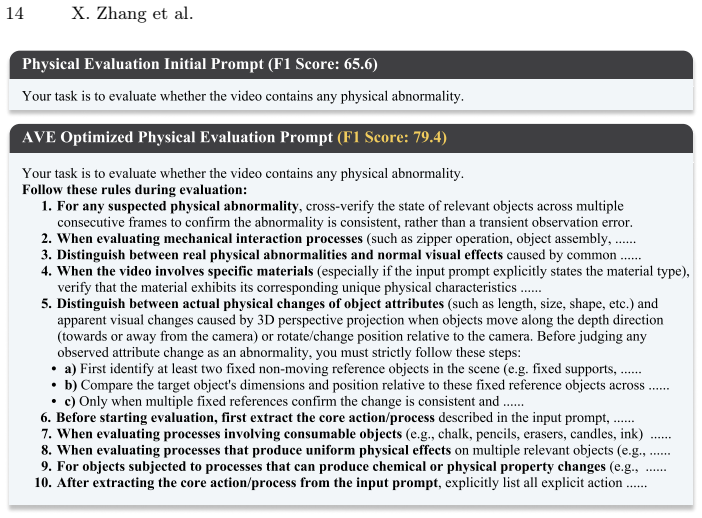
- [Abstract and §4] Abstract and §4 (Experiments): The headline results (SOTA models <25% success on logical generation tasks and ~0% on interactive generation) depend entirely on AVE producing accurate success/failure labels and feedback. The abstract states that AVE 'aligns with human expert perception using minimal annotations' but reports no quantitative validation (correlation coefficients, inter-rater reliability, or ablation studies on annotation volume) for the hardest categories such as physical simulation and logical reasoning. Without this, the performance gaps cannot be confidently attributed to reasoning bottlenecks rather than evaluator artifacts.
- [§3] §3 (CLVG-Bench construction): The description of task construction, annotation guidelines, and how the 1,000+ items were selected to ensure they require 'true multimodal reasoning' (as opposed to pattern matching or superficial cues) is insufficient. This is load-bearing for the central claim, as the benchmark is newly invented and the results are benchmark-specific.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction would benefit from explicit comparison to prior video reasoning benchmarks (e.g., specific metrics or task types they fail to cover) to better motivate the new design.
- [§3.2] Clarify the exact definition of 'success rate' used by AVE (e.g., binary threshold on textual feedback or multi-criteria scoring) and whether it was applied uniformly across all 47 subcategories.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional details and validation as outlined.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The headline results (SOTA models <25% success on logical generation tasks and ~0% on interactive generation) depend entirely on AVE producing accurate success/failure labels and feedback. The abstract states that AVE 'aligns with human expert perception using minimal annotations' but reports no quantitative validation (correlation coefficients, inter-rater reliability, or ablation studies on annotation volume) for the hardest categories such as physical simulation and logical reasoning. Without this, the performance gaps cannot be confidently attributed to reasoning bottlenecks rather than evaluator artifacts.
Authors: We agree that the absence of quantitative validation metrics for AVE in the current manuscript is a limitation that weakens confidence in attributing the observed performance gaps specifically to multimodal reasoning shortfalls. The manuscript describes AVE's design and qualitative alignment but does not report correlation coefficients, inter-rater reliability, or annotation-volume ablations for the most challenging categories. In the revised manuscript, we will add a new subsection in §4 (and update the abstract if needed) presenting these quantitative results, including Pearson/Spearman correlations with human experts, Fleiss' kappa or similar inter-rater scores, and ablation curves showing performance stability with varying annotation budgets. These analyses were conducted during benchmark development and will be reported to allow readers to evaluate evaluator reliability directly. revision: yes
-
Referee: [§3] §3 (CLVG-Bench construction): The description of task construction, annotation guidelines, and how the 1,000+ items were selected to ensure they require 'true multimodal reasoning' (as opposed to pattern matching or superficial cues) is insufficient. This is load-bearing for the central claim, as the benchmark is newly invented and the results are benchmark-specific.
Authors: We concur that §3 currently provides only a high-level overview of task construction and selection, which is insufficient to fully substantiate that the 1,000+ items probe genuine multimodal reasoning rather than superficial cues. In the revision, we will substantially expand §3 to include: (i) the full annotation guidelines provided to expert annotators, (ii) concrete examples from each major category showing how prompts were engineered to require integration of visual context, physical simulation, and logical inference (with counter-examples of rejected superficial variants), and (iii) quantitative selection statistics (e.g., distribution across subcategories, rejection rates for cue-based items, and diversity metrics). This expanded description will make the benchmark's design more transparent and reproducible. revision: yes
Circularity Check
No circularity in evaluation framework or claims
full rationale
The paper presents an empirical evaluation introducing CLVG-Bench (new manually annotated dataset) and AVE (new evaluator) to measure video model performance on reasoning tasks. No derivation chain, equations, or fitted parameters are claimed; results are direct measurements of model success rates on the benchmark. No self-citations, self-definitions, or reductions of outputs to inputs by construction are present in the abstract or described methodology. The central finding (low performance on logical/interactive generation) is a reported observation, not a prediction forced by prior fits or renamings. This is a standard non-circular benchmark paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLVG-Bench tasks and subcategories comprehensively cover complex multimodal reasoning scenarios including physical simulation, logical reasoning, and interactive contexts.
- domain assumption The Adaptive Video Evaluator produces assessments that align with human expert perception using minimal annotations.
invented entities (2)
-
CLVG-Bench
no independent evidence
-
Adaptive Video Evaluator (AVE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agrawal, L.A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., Singhvi, A., Shandilya, H., Ryan, M.J., Jiang, M., Potts, C., Sen, K., Dimakis, A.G., Stoica, I., Klein, D., Zaharia, M., Khattab, O.: Gepa: Reflective prompt evolution can outperform reinforcement learning (2025),https://arxiv.org/abs/2507.19457 9, 10
work page internal anchor Pith review arXiv 2025
-
[2]
Oxford University Press (1984) 6
Andrew, J.D.: Concepts in film theory. Oxford University Press (1984) 6
1984
- [3]
- [4]
-
[5]
Bordwell, D., Thompson, K., Smith, J.: Film art: An introduction, vol. 7. McGraw- Hill New York (2008) 6
2008
-
[6]
Advances in neural information processing systems33, 1877–1901 (2020) 1
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020) 1
1901
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2015) 4
Caba Heilbron, F., Escorcia, V., Ghanem, B., Carlos Niebles, J.: Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2015) 4
2015
- [8]
- [9]
-
[10]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025) 4 16 X. Zhang et al
work page internal anchor Pith review arXiv 2025
-
[11]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review arXiv 2025
-
[12]
In: Proceedings of the IEEE international conference on computer vision
Dosovitskiy, A., Fischer, P., Ilg, E., Hausser, P., Hazirbas, C., Golkov, V., Van Der Smagt, P., Cremers, D., Brox, T.: Flownet: Learning optical flow with convolu- tional networks. In: Proceedings of the IEEE international conference on computer vision. pp. 2758–2766 (2015) 2
2015
-
[13]
Eisenstein, J., Nagpal, C., Agarwal, A., Beirami, A., D’Amour, A., Dvijotham, D., Fisch, A., Heller, K., Pfohl, S., Ramachandran, D., Shaw, P., Berant, J.: Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking (2024),https://arxiv.org/abs/2312.092443
-
[14]
Fang, Y., Zhu, L., Lu, Y., Wang, Y., Molchanov, P., Kautz, J., Cho, J., Pavone, M., Han, S., Yin, H.: Vila2: Vila augmented vila. arXiv preprint arXiv:2407.17453 (2024)
-
[15]
Google: Gemini 3 pro model card. Tech. rep., Google DeepMind (12 2025), https://storage.googleapis.com/deepmind- media/Model- Cards/Gemini- 3- Pro-Model-Card.pdf, model Release: November 2025 6
2025
-
[16]
Google: Veo 3 launch.https://cloud.google.com/blog/products/ai-machine- learning/veo- 3- fast- available- for- everyone- on- vertex- ai(2025), ac- cessed: March 3, 2026 4, 9, 11
2025
-
[17]
arXiv preprint arXiv:2505.16770 (2025) 4, 5
Guo, M.H., Chu, X., Yang, Q., Mo, Z.H., Shen, Y., Li, P.l., Lin, X., Zhang, J., Chen, X.S., Zhang, Y., et al.: Rbench-v: A primary assessment for visual reasoning models with multi-modal outputs. arXiv preprint arXiv:2505.16770 (2025) 4, 5
-
[19]
LTX-2: Efficient Joint Audio-Visual Foundation Model
HaCohen, Y., Brazowski, B., Chiprut, N., Bitterman, Y., Kvochko, A., Berkowitz, A., Shalem, D., Lifschitz, D., Moshe, D., Porat, E., et al.: Ltx-2: Efficient joint audio-visual foundation model. arXiv preprint arXiv:2601.03233 (2026) 4, 11
work page Pith review arXiv 2026
- [20]
-
[21]
He, H., Wang, J., Zhang, J., Xue, Z., Bu, X., Yang, Q., Wen, S., Xie, L.: Openve- 3m: A large-scale high-quality dataset for instruction-guided video editing. arXiv preprint arXiv:2512.07826 (2025) 4, 5
-
[22]
He, X., Jiang, D., Nie, P., Liu, M., Jiang, Z., Su, M., Ma, W., Lin, J., Ye, C., Lu, Y., Wu, K., Schneider, B., Do, Q.D., Li, Z., Jia, Y., Zhang, Y., Cheng, G., Wang, H., Zhou, W., Lin, Q., Zhang, Y., Zhang, G., Huang, W., Chen, W.: Videoscore2: Think before you score in generative video evaluation (2025),https://arxiv.org/ abs/2509.227993
-
[23]
He, X., Jiang, D., Zhang, G., Ku, M., Soni, A., Siu, S., Chen, H., Chandra, A., Jiang, Z., Arulraj, A., Wang, K., Do, Q.D., Ni, Y., Lyu, B., Narsupalli, Y., Fan, R., Lyu, Z., Lin, Y., Chen, W.: Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. ArXivabs/2406.15252(2024), https://arxiv.org/abs/2406.152523, 4
-
[24]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding (2021),https://arxiv. org/abs/2009.03300 How Far Are Video Models from True Multimodal Reasoning? 17
work page internal anchor Pith review arXiv 2021
-
[25]
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning (2022),https://arxiv.org/abs/2104. 087184
2022
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, H., Chan, K.C., Su, Y.C., Chen, W., Li, Y., Sohn, K., Zhao, Y., Ben, X., Gong, B., Cohen, W., et al.: Instruct-imagen: Image generation with multi-modal instruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4754–4763 (2024) 2
2024
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 2, 4
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 2, 4
2024
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) 2
2024
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) 4, 5
2024
-
[30]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Ji, P., Xiao, C., Tai, H., Huo, M.: T2vbench: Benchmarking temporal dynamics for text-to-video generation. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 5325–5335 (2024) 2, 4
2024
-
[31]
Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C., Pu, B., Zhang, Y., Yang, Z., Feng, Y., Zhou, J.T., et al.: Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668 (2025) 1
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025) 2, 4
2025
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025) 5
2025
-
[34]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., Girshick, R.: Clevr: A diagnostic dataset for compositional language and elemen- tary visual reasoning. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2901–2910 (2017) 4
2017
-
[35]
arXiv preprint arXiv:2503.19907 (2025) 2
Ju, X., Ye, W., Liu, Q., Wang, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Xu, Q.: Fulldit: Multi-task video generative foundation model with full attention. arXiv preprint arXiv:2503.19907 (2025) 2
-
[36]
Advances in neural information processing systems35, 22199–22213 (2022)
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. Advances in neural information processing systems35, 22199–22213 (2022)
2022
-
[38]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Ku, M., Wei, C., Ren, W., Yang, H., Chen, W.: Anyv2v: A tuning-free framework for any video-to-video editing tasks. arXiv preprint arXiv:2403.14468 (2024) 2 18 X. Zhang et al
-
[40]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review arXiv 2024
-
[41]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, M., Xie, C., Wu, Y., Zhang, L., Wang, M.: Five-bench: A fine-grained video editing benchmark for evaluating emerging diffusion and rectified flow models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 16672–16681 (2025) 5
2025
-
[42]
Liao, C., Liu, L., Wang, X., Luo, Z., Zhang, X., Zhao, W., Wu, J., Li, L., Tian, Z., Huang, W.: Mogao: An omni foundation model for interleaved multi-modal generation. arXiv preprint arXiv:2505.05472 (2025) 4
-
[44]
Zero-shot voice conversion with diffusion transform- ers,
Liu, S.: Zero-shot voice conversion with diffusion transformers. arXiv preprint arXiv:2411.09943 (2024) 7
-
[45]
Liu, Y., Cun, X., Liu, X., Wang, X., Zhang, Y., Chen, H., Liu, Y., Zeng, T., Chan, R., Shan, Y.: Evalcrafter: Benchmarking and evaluating large video generation models. arXiv preprint arXiv:2310.11440 (2023) 2, 4
- [46]
-
[48]
Meng, F., Liao, J., Tan, X., Shao, W., Lu, Q., Zhang, K., Cheng, Y., Li, D., Qiao, Y., Luo, P.: Towards world simulator: Crafting physical commonsense-based benchmark for video generation. arXiv preprint arXiv:2410.05363 (2024) 4
-
[49]
OpenAI: Sora: A video generation model.https://openai.com/zh- Hans- CN/ index/sora-2/(2025), accessed: March 4 2026 9, 11
2025
-
[50]
pixverse.ai/(2023), accessed: March 3, 2026 4
PixVerse: Pixverse: AI-powered image and video editing platform.https://app. pixverse.ai/(2023), accessed: March 3, 2026 4
2023
-
[51]
Movie Gen: A Cast of Media Foundation Models
Polyak, A., Zohar, A., Brown, A., Tjandra, A., Sinha, A., Lee, A., Vyas, A., Shi, B., Ma, C.Y., Chuang, C.Y., et al.: Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720 (2024) 2
work page internal anchor Pith review arXiv 2024
-
[52]
AoPS Wiki,https: //artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions, accessed: 2026-03-01
of Problem Solving (AoPS), A.: Aime problems and solutions. AoPS Wiki,https: //artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions, accessed: 2026-03-01
2026
-
[53]
Rein, D., Hou, B.L., Stickland, A.C., Petty, J., Pang, R.Y., Dirani, J., Michael, J., Bowman, S.R.: Gpqa: A graduate-level google-proof qa benchmark (2023),https: //arxiv.org/abs/2311.12022
work page internal anchor Pith review arXiv 2023
-
[55]
arXiv preprint arXiv:2602.10102 (2026) 4
Ren, Z., Wei, Y., Yu, X., Luo, G., Zhao, Y., Kang, B., Feng, J., Jin, X.: Vide- oworld 2: Learning transferable knowledge from real-world videos. arXiv preprint arXiv:2602.10102 (2026) 4
-
[56]
Seed, B.: Seed2.0 model card: Towards intelligence frontier for real-world complex- ity. Tech. rep., 2026a. Technical Report (2026) 4, 6, 9, 11
2026
-
[57]
Seedance, T., Chen, H., Chen, S., Chen, X., Chen, Y., Chen, Y., Chen, Z., Cheng, F., Cheng, T., Cheng, X., et al.: Seedance 1.5 pro: A native audio-visual joint generation foundation model. arXiv preprint arXiv:2512.13507 (2025) 1, 9, 11 How Far Are Video Models from True Multimodal Reasoning? 19
-
[58]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Sun, K., Huang, K., Liu, X., Wu, Y., Xu, Z., Li, Z., Liu, X.: T2v-compbench: A comprehensive benchmark for compositional text-to-video generation. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 8406–8416 (2025) 2, 4
2025
-
[59]
In: The Twelfth In- ternational Conference on Learning Representations (2024)
Sun, Q., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, Y., Gao, H., Liu, J., Huang, T., Wang, X.: Emu: Generative pretraining in multimodality. In: The Twelfth In- ternational Conference on Learning Representations (2024)
2024
-
[60]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Sun, S., Liang, X., Fan, S., Gao, W., Gao, W.: Ve-bench: Subjective-aligned bench- mark suite for text-driven video editing quality assessment. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7105–7113 (2025) 4, 5
2025
-
[61]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024) 4
work page internal anchor Pith review arXiv 2024
-
[62]
Team, K., Chen, J., Ci, Y., Du, X., Feng, Z., Gai, K., Guo, S., Han, F., He, J., He, K., et al.: Kling-omni technical report. arXiv preprint arXiv:2512.16776 (2025) 1, 4
-
[63]
Team, T.H.F.M.: Hunyuanvideo 1.5 technical report (2025),https://arxiv.org/ abs/2511.188709
work page internal anchor Pith review arXiv 2025
-
[64]
Vidu: Vidu: AI-powered video generation platform.https://www.vidu.cn/(2024), accessed: 2026-03-03 4
2024
-
[65]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 2, 4, 9, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
ModelScope Text-to-Video Technical Report
Wang, J., Yuan, H., Chen, D., Zhang, Y., Wang, X., Zhang, S.: Modelscope text- to-video technical report. arXiv preprint arXiv:2308.06571 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[68]
A very big video reasoning suite
Wang, M., Wang, R., Lin, J., Ji, R., Wiedemer, T., Gao, Q., Luo, D., Qian, Y., Huang, L., Hong, Z., et al.: A very big video reasoning suite. arXiv preprint arXiv:2602.20159 (2026) 4
-
[69]
In: The Fourteenth International Conference on Learning Representations (2025) 4
Wang, S., Pei, M., Sun, L., Deng, C., Li, Y., Shao, K., Tian, Z., Zhang, H., Wang, J.: Spatialviz-bench: A cognitively-grounded benchmark for diagnosing spatial vi- sualization in mllms. In: The Fourteenth International Conference on Learning Representations (2025) 4
2025
-
[70]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024) 4
work page internal anchor Pith review arXiv 2024
-
[71]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Wang, Y., Liu, J., Gao, S., Feng, B., Tang, Z., Gai, X., Wu, J., Liu, Z.: V2t- cot: From vision to text chain-of-thought for medical reasoning and diagnosis. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 658–668. Springer (2025) 1
2025
-
[73]
Wei, C., Liu, Q., Ye, Z., Wang, Q., Wang, X., Wan, P., Gai, K., Chen, W.: Uni- video: Unified understanding, generation, and editing for videos. arXiv preprint arXiv:2510.08377 (2025)
-
[74]
Emergent Abilities of Large Language Models
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., et al.: Emergent abilities of large language models. arXiv preprint arXiv:2206.07682 (2022) 1 20 X. Zhang et al
work page internal anchor Pith review arXiv 2022
-
[76]
Video models are zero-shot learners and reasoners
Wiedemer, T., Li, Y., Vicol, P., Gu, S.S., Matarese, N., Swersky, K., Kim, B., Jaini, P., Geirhos, R.: Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328 (2025) 1, 5
work page internal anchor Pith review arXiv 2025
- [77]
-
[78]
Wu, J., Zhang, X., Yuan, H., Zhang, X., Huang, T., He, C., Deng, C., Zhang, R., Wu, Y., Long, M.: Visual generation unlocks human-like reasoning through multimodal world models. arXiv preprint arXiv:2601.19834 (2026) 7
-
[79]
Wu, R., Chen, L., Yang, T., Guo, C., Li, C., Zhang, X.: Lamp: Learn a motion patternforfew-shotvideogeneration.In:ProceedingsoftheIEEE/CVFconference on computer vision and pattern recognition. pp. 7089–7098 (2024) 4
2024
-
[80]
In: The Thirteenth International Conference on Learning Representations (2025)
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[81]
Xu, J., Huang, Y., Cheng, J., Yang, Y., Xu, J., Wang, Y., Duan, W., Yang, S., Jin, Q., Li, S., Teng, J., Yang, Z., Zheng, W., Liu, X., Ding, M., Zhang, X., Gu, X., Huang, S., Huang, M., Tang, J., Dong, Y.: Visionreward: Fine-grained multi- dimensional human preference learning for image and video generation (2024), https://arxiv.org/abs/2412.210593
-
[82]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xu, J., Mei, T., Yao, T., Rui, Y.: Msr-vtt: A large video description dataset for bridging video and language. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5288–5296 (2016) 4
2016
- [83]
-
[84]
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W.W., Salakhutdinov, R., Manning, C.D.: Hotpotqa: A dataset for diverse, explainable multi-hop question answering (2018),https://arxiv.org/abs/1809.09600
work page internal anchor Pith review arXiv 2018
-
[85]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review arXiv 2024
-
[88]
Unic: Unified in-context video editing.arXiv preprint arXiv:2506.04216, 2025
Ye, Z., He, X., Liu, Q., Wang, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Chen, Q., Luo, W.: Unic: Unified in-context video editing. arXiv preprint arXiv:2506.04216 (2025) 5
-
[89]
TextGrad: Automatic "Differentiation" via Text
Yuksekgonul, M., Bianchi, F., Boen, J., Liu, S., Huang, Z., Guestrin, C., Zou, J.: Textgrad: Automatic "differentiation" via text (2024),https://arxiv.org/abs/ 2406.074969
work page internal anchor Pith review arXiv 2024
-
[90]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025) How Far Are Video Models from True Multimodal Reasoning? 21
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.