Recognition: unknown
ShadowPEFT: Shadow Network for Parameter-Efficient Fine-Tuning
Pith reviewed 2026-05-10 02:10 UTC · model grok-4.3
The pith
ShadowPEFT adapts large language models by evolving a shared shadow state at each layer rather than applying low-rank updates to individual weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
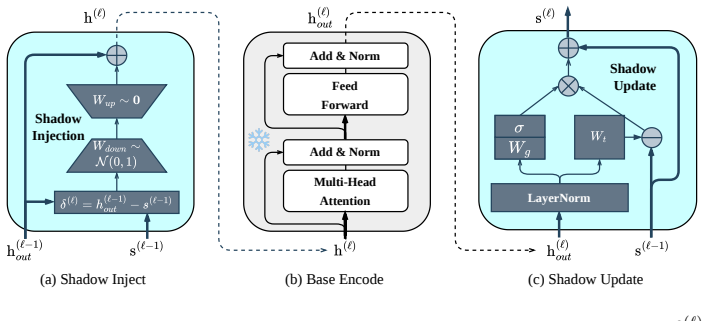
ShadowPEFT introduces a centralized PEFT framework where adaptation occurs through depth-shared shadow modules that evolve parallel shadow states repeatedly at each transformer layer, shifting from distributed weight-space perturbations to shared layer-space refinement that can be decoupled from the backbone.
What carries the argument
The depth-shared shadow module that maintains a parallel shadow state evolved repeatedly for richer hidden states at each layer.
If this is right
- The shadow module can be independently pretrained and then integrated into the model.
- It supports detached mode deployment for reduced inference costs in edge computing.
- Performance remains competitive across different parameter budgets on generation and understanding tasks.
- Analyses show benefits in cross-dataset transfer and parameter scaling without increasing latency significantly.
Where Pith is reading between the lines
- This design could enable swapping shadow modules for different tasks without modifying the backbone weights.
- Pretraining the shadow module on large unlabeled data might further improve adaptation quality for specific domains.
- Combining the shadow refinement with other techniques like prompt tuning could yield hybrid methods with even fewer parameters.
Load-bearing premise
Repeatedly evolving a parallel shadow state at each layer will produce hidden representations that adapt the model at least as effectively as adding low-rank perturbations directly to the backbone weights.
What would settle it
If ShadowPEFT consistently underperforms LoRA and DoRA by a large margin on standard benchmarks while using the same number of trainable parameters, the central claim would be falsified.
Figures



read the original abstract
Parameter-efficient fine-tuning (PEFT) reduces the training cost of full-parameter fine-tuning for large language models (LLMs) by training only a small set of task-specific parameters while freezing the pretrained backbone. However, existing approaches, such as Low-Rank Adaptation (LoRA), achieve adaptation by inserting independent low-rank perturbations directly to individual weights, resulting in a local parameterization of adaptation. We propose ShadowPEFT, a centralized PEFT framework that instead performs layer-level refinement through a depth-shared shadow module. At each transformer layer, ShadowPEFT maintains a parallel shadow state and evolves it repeatedly for progressively richer hidden states. This design shifts adaptation from distributed weight-space perturbations to a shared layer-space refinement process. Since the shadow module is decoupled from the backbone, it can be reused across depth, independently pretrained, and optionally deployed in a detached mode, benefiting edge computing scenarios. Experiments on generation and understanding benchmarks show that ShadowPEFT matches or outperforms LoRA and DoRA under comparable trainable-parameter budgets. Additional analyses on shadow pretraining, cross-dataset transfer, parameter scaling, inference latency, and system-level evaluation suggest that centralized layer-space adaptation is a competitive and flexible alternative to conventional low-rank PEFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ShadowPEFT, a centralized PEFT framework for LLMs that maintains a parallel shadow state at each transformer layer and evolves it repeatedly via a depth-shared shadow module to produce progressively richer hidden representations. This shifts adaptation from distributed low-rank weight-space perturbations (as in LoRA/DoRA) to shared layer-space refinement. The shadow module is decoupled from the backbone, enabling reuse across depth, independent pretraining, and detached deployment. Experiments on generation and understanding benchmarks claim that ShadowPEFT matches or outperforms LoRA and DoRA under comparable trainable-parameter budgets, with additional analyses on shadow pretraining, cross-dataset transfer, parameter scaling, inference latency, and system-level evaluation.
Significance. If the performance claims hold after isolating the design contributions, ShadowPEFT would provide a flexible alternative to conventional low-rank PEFT methods, with practical advantages for module reuse and edge deployment. The repeated evolution mechanism and centralized parameterization could open new directions for layer-level adaptation in efficient fine-tuning.
major comments (2)
- [Experiments and Method] The central performance claim (matching or exceeding LoRA/DoRA) is load-bearing for the paper's contribution, yet the abstract and method description emphasize repeated evolution of the shadow state 'for progressively richer hidden states' without an ablation that holds trainable parameter count fixed while varying iteration count. This leaves open the possibility that gains derive from extra per-layer compute rather than the shift to layer-space adaptation.
- [Method] No equations, initialization details, or update rules for the shadow state evolution are provided in the method description, making it impossible to verify how the 'depth-shared shadow module' integrates with backbone layers or to reproduce the claimed layer-level refinement process.
minor comments (1)
- [Abstract] The abstract reports experimental outcomes without any numerical results, specific baselines, statistical significance, or ablation details, which reduces immediate assessability of the claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Experiments and Method] The central performance claim (matching or exceeding LoRA/DoRA) is load-bearing for the paper's contribution, yet the abstract and method description emphasize repeated evolution of the shadow state 'for progressively richer hidden states' without an ablation that holds trainable parameter count fixed while varying iteration count. This leaves open the possibility that gains derive from extra per-layer compute rather than the shift to layer-space adaptation.
Authors: We agree that an ablation isolating the contribution of iteration count at fixed parameter budget is important for validating the design. In the revised manuscript we have added this experiment (new Figure 5 and accompanying text in Section 4.3). With the depth-shared shadow module the trainable parameter count remains constant regardless of iteration depth; the ablation shows that performance improves with additional iterations up to a saturation point while still matching or exceeding LoRA/DoRA at the same parameter budget. This supports that the gains arise from the repeated layer-space refinement rather than merely from extra compute. We have also clarified in the method section that the shared parameterization prevents parameter inflation with iteration count. revision: yes
-
Referee: [Method] No equations, initialization details, or update rules for the shadow state evolution are provided in the method description, making it impossible to verify how the 'depth-shared shadow module' integrates with backbone layers or to reproduce the claimed layer-level refinement process.
Authors: We apologize for the insufficient detail in the original submission. The revised manuscript now includes a complete mathematical description in Section 3. We provide the equations governing the shadow-state update, the initialization procedure for the parallel shadow state, and the precise integration rule that applies the depth-shared module to each transformer layer's hidden state. These additions make the layer-level refinement process fully reproducible and clarify how the centralized module operates independently of the backbone weights. revision: yes
Circularity Check
No circularity: empirical architecture proposal without derivational claims
full rationale
The paper presents ShadowPEFT as an empirical design choice—a depth-shared shadow module that evolves parallel states for layer-level refinement—validated through benchmark experiments matching or exceeding LoRA/DoRA under parameter budgets. No equations, derivations, or first-principles predictions appear in the provided text; the method is not obtained by fitting parameters then relabeling the fit as a prediction, nor does any uniqueness theorem or ansatz reduce to self-citation. The central claim (centralized layer-space adaptation is competitive) rests on external experimental outcomes rather than tautological reduction to inputs, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
invented entities (1)
-
shadow module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adaptersoup: Weight averaging to improve generalization of pretrained language models
Alexandra Chronopoulou, Matthew E Peters, Alexander Fraser, and Jesse Dodge. Adaptersoup: Weight averaging to improve generalization of pretrained language models. InFindings of the Association for Computational Linguistics: EACL 2023, pages 2054–2063,
2023
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Parameter-efficient fine-tuning for large models: A comprehensive survey.Trans
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.Trans. Mach. Learn. Res., 2024,
2024
-
[4]
The multilingual amazon reviews corpus
Phillip Keung, Yichao Lu, György Szarvas, and Noah A Smith. The multilingual amazon reviews corpus. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 4563–4568,
2020
-
[5]
The power of scale for parameter-efficient prompt tuning
11 Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 3045–3059,
2021
-
[6]
Mixlora: Enhancing large language models fine-tuning with lora based mixture of experts,
Dengchun Li, Yingzi Ma, Naizheng Wang, Zhengmao Ye, Zhiyuan Cheng, Yinghao Tang, Yan Zhang, Lei Duan, Jie Zuo, Cal Yang, et al. Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts.arXiv preprint arXiv:2404.15159,
-
[7]
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Advances in Neural Information Processing Systems, 35:1950–1965, 2022a
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Advances in Neural Information Processing Systems, 35:1950–1965, 2022a. Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang- Ting Che...
1950
-
[8]
DOI: https://doi.org/10.24432/C5C323. Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for squad. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789,
-
[9]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, F. Xia, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models.ArXiv, abs/2201.11903,
work page internal anchor Pith review arXiv
-
[10]
doi: 10.1109/TPAMI.2026.3657354. 12 Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhengsu Chen, Xiaopeng Zhang, and Qi Tian. Qa-lora: Quantization-aware low-rank adaptation of large language models. InThe Twelfth International Conference on Learning Representations,
-
[11]
Tiny-attention adapter: Contexts are more important than the number of parameters
Hongyu Zhao, Hao Tan, and Hongyuan Mei. Tiny-attention adapter: Contexts are more important than the number of parameters. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6626–6638,
2022
-
[12]
explicit shadow models.ShadowPEFT supports two centralized shadow initialization strategies
A More Designs of Centralized Shadow Model Implicit vs. explicit shadow models.ShadowPEFT supports two centralized shadow initialization strategies. In theimplicitsetting the centralized shadow model is derived automatically from the base model’s configuration by reducing the number of layers toLs ≪L and optionally narrowing the intermediate width and att...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.