Recognition: unknown
Explicit Trait Inference for Multi-Agent Coordination
Pith reviewed 2026-05-10 02:41 UTC · model grok-4.3
The pith
LLM agents that track partners' warmth and competence traits coordinate more effectively and lose less payoff.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
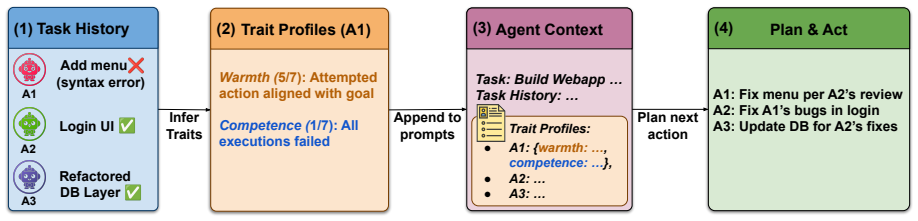
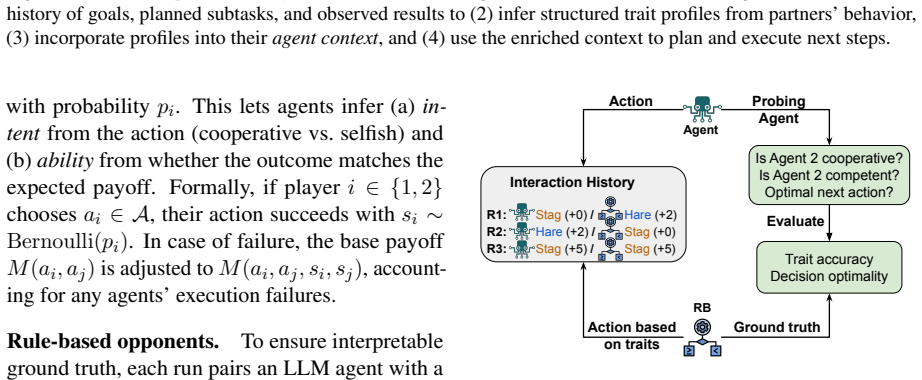
Explicit Trait Inference enables agents to infer and track partner characteristics along two established psychological dimensions—warmth and competence—from interaction histories to guide decisions. This results in 45-77% reduction in payoff loss in economic games and 3-29% performance improvement in MultiAgentBench relative to a CoT baseline. The gains are linked to the quality of trait inferences, as profiles predict actions and informative ones drive improvements.
What carries the argument
Explicit Trait Inference (ETI), a method that builds profiles of partner agents' warmth (trust, etc.) and competence (skill, etc.) from histories and uses them for decision-making.
If this is right
- ETI profiles can predict agents' future actions.
- Performance gains increase with more informative trait profiles.
- ETI provides evidence that LLM agents can reliably infer traits from interactions.
- The method works across various models and scenarios in the benchmarks.
Where Pith is reading between the lines
- Extending ETI to additional trait dimensions could further enhance coordination in diverse social settings.
- Integrating trait inference with other planning techniques might compound the benefits in long-running tasks.
- Testing ETI in environments with deceptive or changing traits would reveal its robustness limits.
Load-bearing premise
That agents can accurately and stably infer psychological traits like warmth and competence from interaction histories and that acting on these inferences will enhance coordination without introducing new errors or misalignments.
What would settle it
Observing no correlation between ETI-inferred traits and actual agent behaviors in follow-up interactions, or finding that ETI-equipped agents perform similarly or worse than baselines in coordination metrics.
Figures


read the original abstract
LLM-based multi-agent systems (MAS) show promise on complex tasks but remain prone to coordination failures such as goal drift, error cascades, and misaligned behaviors. We propose Explicit Trait Inference (ETI), a psychologically grounded method for improving coordination. ETI enables agents to infer and track partner characteristics along two established psychological dimensions--warmth (e.g., trust) and competence (e.g., skill)--from interaction histories to guide decisions. We evaluate ETI in controlled settings (economic games), where it reduces payoff loss by 45-77%, and in more realistic, complex multi-agent settings (MultiAgentBench), where it improves performance by 3-29% depending on the scenario and model, relative to a CoT baseline. Additional analysis shows that gains are closely linked to trait inference: ETI profiles predict agents' actions, and informative profiles drive improvements. These results highlight ETI as a lightweight and robust mechanism for improving coordination in diverse multi-agent settings, and provide the first systematic evidence that LLM agents can (i) reliably infer others' traits from interaction histories and (ii) leverage structured awareness of others' traits for coordination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Explicit Trait Inference (ETI) as a method for LLM agents in multi-agent systems. Agents infer and track partners' traits along the psychological dimensions of warmth (e.g., trust) and competence (e.g., skill) from interaction histories; these inferences are then used to guide decisions. The central empirical claims are a 45-77% reduction in payoff loss relative to a CoT baseline in controlled economic games and 3-29% performance gains in MultiAgentBench scenarios, with additional analysis asserting that ETI profiles predict actions and that informative profiles drive the observed improvements.
Significance. If the central claims hold after appropriate controls, ETI would constitute a lightweight, psychologically grounded mechanism for reducing coordination failures such as goal drift and misaligned behaviors in LLM-based MAS. The work supplies the first systematic empirical evidence that LLM agents can reliably extract stable trait information from histories and leverage it for better joint outcomes. This could inform subsequent agent architectures and coordination protocols, particularly in settings where explicit partner modeling is feasible.
major comments (2)
- [Evaluation sections (economic games and MultiAgentBench)] The quantitative results (45-77% payoff-loss reduction and 3-29% MultiAgentBench gains) are presented without reported details on the number of independent trials, statistical tests, error bars, variance across random seeds, or exact prompt templates and history lengths. Because these elements are load-bearing for interpreting whether the gains exceed baseline variability, the Methods and Results sections must supply them before the performance claims can be evaluated.
- [Analysis linking profiles to improvements] The claim that gains are specifically attributable to inference along the warmth/competence dimensions (rather than any structured, queryable partner model) is not yet supported by the necessary ablation. An experiment that preserves history length and decision scaffolding but substitutes neutral or random labels for the inferred traits would directly test whether the psychological content is causal; its absence leaves open the possibility that any explicit partner modeling suffices.
minor comments (2)
- [Abstract and §1] The abstract and introduction should explicitly state the precise CoT baseline prompt and whether history is provided to the baseline in the same format and length as to ETI.
- [Method description] Notation for the two trait dimensions should be introduced once with clear operational definitions (e.g., how warmth and competence are scored from histories) rather than relying on parenthetical examples.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive comments on our paper. We address each of the major comments point by point below, indicating whether revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [Evaluation sections (economic games and MultiAgentBench)] The quantitative results (45-77% payoff-loss reduction and 3-29% MultiAgentBench gains) are presented without reported details on the number of independent trials, statistical tests, error bars, variance across random seeds, or exact prompt templates and history lengths. Because these elements are load-bearing for interpreting whether the gains exceed baseline variability, the Methods and Results sections must supply them before the performance claims can be evaluated.
Authors: We agree that these details are important for a thorough evaluation of our results. In the revised manuscript, we have updated the Methods and Results sections to include the number of independent trials performed, the statistical tests used to assess significance, error bars showing variance across random seeds, and the exact prompt templates along with the history lengths utilized in our experiments. These additions confirm that the performance improvements are statistically robust. revision: yes
-
Referee: [Analysis linking profiles to improvements] The claim that gains are specifically attributable to inference along the warmth/competence dimensions (rather than any structured, queryable partner model) is not yet supported by the necessary ablation. An experiment that preserves history length and decision scaffolding but substitutes neutral or random labels for the inferred traits would directly test whether the psychological content is causal; its absence leaves open the possibility that any explicit partner modeling suffices.
Authors: We appreciate this insightful suggestion for strengthening the causal link. Our analysis in the paper shows that the inferred ETI profiles predict agents' subsequent actions and that scenarios with more informative profiles exhibit larger improvements. This provides correlational support for the role of the specific trait inferences. We acknowledge that the proposed ablation study with neutral or random labels would offer more definitive evidence. We have added a discussion of this point as a limitation in the revised manuscript and note that such an ablation is planned for future work. However, we maintain that the predictive power of the specific profiles supports our attribution to the warmth and competence dimensions rather than generic modeling. revision: partial
Circularity Check
No circularity: empirical evaluation of a prompting-based method
full rationale
The paper proposes ETI as a method for LLM agents to infer warmth and competence traits from histories and evaluates it via controlled experiments in economic games and MultiAgentBench against a CoT baseline. No equations, derivations, or parameter-fitting steps are described in the provided abstract or framing; performance gains are reported as measured outcomes rather than reductions to self-defined inputs. No self-citations are invoked as load-bearing uniqueness theorems, and the psychological dimensions are referenced as established external constructs. The central claims rest on comparative empirical results, which remain falsifiable outside any internal definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Warmth and competence are stable, inferable traits that influence coordination decisions in LLM agents.
Reference graph
Works this paper leans on
-
[1]
Trends in cognitive sciences , volume=
Universal dimensions of social cognition: Warmth and competence , author=. Trends in cognitive sciences , volume=. 2007 , publisher=
2007
-
[2]
Advances in experimental social psychology , volume=
Warmth and competence as universal dimensions of social perception: The stereotype content model and the BIAS map , author=. Advances in experimental social psychology , volume=. 2008 , publisher=
2008
-
[3]
Current opinion in behavioral sciences , volume=
Intergroup biases: A focus on stereotype content , author=. Current opinion in behavioral sciences , volume=. 2015 , publisher=
2015
-
[4]
Advances in experimental social psychology , volume=
Communal and agentic content in social cognition: A dual perspective model , author=. Advances in experimental social psychology , volume=. 2014 , publisher=
2014
-
[5]
Advances in experimental social psychology , volume=
From acts to dispositions the attribution process in person perception , author=. Advances in experimental social psychology , volume=. 1965 , publisher=
1965
-
[6]
European Journal of Social Psychology , volume=
Towards an operationalization of the fundamental dimensions of agency and communion: Trait content ratings in five countries considering valence and frequency of word occurrence , author=. European Journal of Social Psychology , volume=. 2008 , publisher=
2008
-
[7]
Academy of management review , volume=
An integrative model of organizational trust , author=. Academy of management review , volume=. 1995 , publisher=
1995
-
[8]
, author=
Trust, conflict, and cooperation: a meta-analysis. , author=. Psychological bulletin , volume=. 2013 , publisher=
2013
-
[9]
Management science , volume=
Coordinating expertise in software development teams , author=. Management science , volume=. 2000 , publisher=
2000
-
[10]
Organizational behavior and human decision processes , volume=
Choosing work group members: Balancing similarity, competence, and familiarity , author=. Organizational behavior and human decision processes , volume=. 2000 , publisher=
2000
-
[11]
Research in organizational behavior , volume=
The dynamics of warmth and competence judgments, and their outcomes in organizations , author=. Research in organizational behavior , volume=. 2011 , publisher=
2011
-
[12]
ACM collective intelligence , year=
Task Allocation in Teams as a Multi-Armed Bandit , author=. ACM collective intelligence , year=
-
[13]
Organizational Behavior and Human Decision Processes , volume=
Swiftly judging whom to bring on board: How person perception (accurate or not) influences selection of prospective team members , author=. Organizational Behavior and Human Decision Processes , volume=. 2022 , publisher=
2022
-
[14]
Journal of Experimental Social Psychology , volume=
Reinforcement learning in social interaction: The distinguishing role of trait inference , author=. Journal of Experimental Social Psychology , volume=. 2020 , publisher=
2020
-
[15]
and Yang, Shuyi and Agrawal, Lakshya A
Cemri, Mert and Pan, Melissa Z. and Yang, Shuyi and Agrawal, Lakshya A. and Chopra, Bhavya and Tiwari, Rishabh and Keutzer, Kurt and Parameswaran, Aditya and Klein, Dan and Ramchandran, Kannan and Zaharia, Matei and Gonzalez, Joseph E. and Stoica, Ion , booktitle=. Why Do Multi-Agent
-
[16]
The Thirteenth International Conference on Learning Representations , year=
Mixture-of-Agents Enhances Large Language Model Capabilities , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[18]
The Thirteenth International Conference on Learning Representations , year=
Scaling Large Language Model-based Multi-Agent Collaboration , author=. The Thirteenth International Conference on Learning Representations , year=
-
[19]
Humanities and Social Sciences Communications , volume=
Large language models empowered agent-based modeling and simulation: A survey and perspectives , author=. Humanities and Social Sciences Communications , volume=. 2024 , publisher=
2024
-
[20]
Simulating public administration crisis: A novel generative agent-based simulation system to lower technology barriers in social science research , author=. arXiv preprint arXiv:2311.06957 , year=
-
[21]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Agentcoder: Multi-agent-based code generation with iterative testing and optimisation , author=. arXiv preprint arXiv:2312.13010 , year=
work page internal anchor Pith review arXiv
-
[22]
Multi-agent collaboration: Harnessing the power of intelligent llm agents , author=. arXiv preprint arXiv:2306.03314 , year=
-
[23]
LLM multi-agent systems: Challenges and open problems , author=. arXiv preprint arXiv:2402.03578 , year=
-
[24]
Large language model based multi-agents: A survey of progress and challenges,
Guo, Taicheng and Chen, Xiuying and Wang, Yaqi and Chang, Ruidi and Pei, Shichao and Chawla, Nitesh V. and Wiest, Olaf and Zhang, Xiangliang , title =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , articleno =. 2024 , isbn =. doi:10.24963/ijcai.2024/890 , abstract =
-
[25]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Multi-agent collaboration mechanisms: A survey of llms , author=. arXiv preprint arXiv:2501.06322 , year=
work page internal anchor Pith review arXiv
-
[26]
MultiAgentBench : Evaluating the collaboration and competition of LLM agents
Zhu, Kunlun and Du, Hongyi and Hong, Zhaochen and Yang, Xiaocheng and Guo, Shuyi and Wang, Zhe and Wang, Zhenhailong and Qian, Cheng and Tang, Xiangru and Ji, Heng and You, Jiaxuan. M ulti A gent B ench : Evaluating the Collaboration and Competition of LLM agents. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol...
-
[27]
Autonomous Agents and Multi-Agent Systems , volume=
Warmth and competence in human-agent cooperation , author=. Autonomous Agents and Multi-Agent Systems , volume=. 2024 , doi=
2024
-
[28]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Persona vectors: Monitoring and controlling character traits in language models , author=. arXiv preprint arXiv:2507.21509 , year=
work page internal anchor Pith review arXiv
-
[29]
Companion Proceedings of the ACM on Web Conference 2025 , pages =
Bhandari, Pranav and Naseem, Usman and Datta, Amitava and Fay, Nicolas and Nasim, Mehwish , title =. Companion Proceedings of the ACM on Web Conference 2025 , pages =. 2025 , isbn =. doi:10.1145/3701716.3715504 , abstract =
-
[30]
P ersona LLM : Investigating the ability of large language models to express personality traits
Jiang, Hang and Zhang, Xiajie and Cao, Xubo and Breazeal, Cynthia and Roy, Deb and Kabbara, Jad. P ersona LLM : Investigating the Ability of Large Language Models to Express Personality Traits. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.229
-
[31]
arXiv preprint arXiv:2312.15198 , year =
Do LLM agents exhibit social behavior? , author=. arXiv preprint arXiv:2312.15198 , year=
-
[32]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Generative agent simulations of 1,000 people , author=. arXiv preprint arXiv:2411.10109 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
2025 , url=
Ang Li and Haozhe Chen and Hongseok Namkoong and Tianyi Peng , booktitle=. 2025 , url=
2025
-
[34]
Proceedings of the 6th ACM Conference on Conversational User Interfaces , articleno =
Sun, Guangzhi and Zhan, Xiao and Such, Jose , title =. Proceedings of the 6th ACM Conference on Conversational User Interfaces , articleno =. 2024 , isbn =. doi:10.1145/3640794.3665887 , abstract =
-
[35]
P ersona G ym: Evaluating Persona Agents and LLM s
Samuel, Vinay and Zou, Henry Peng and Zhou, Yue and Chaudhari, Shreyas and Kalyan, Ashwin and Rajpurohit, Tanmay and Deshpande, Ameet and Narasimhan, Karthik R and Murahari, Vishvak. P ersona G ym: Evaluating Persona Agents and LLM s. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.368
-
[36]
Frisch, Ivar and Giulianelli, Mario. LLM Agents in Interaction: Measuring Personality Consistency and Linguistic Alignment in Interacting Populations of Large Language Models. Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSONALIZE 2024). 2024. doi:10.18653/v1/2024.personalize-1.9
-
[37]
InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES)
SycEval: Evaluating LLM Sycophancy , volume=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author=. 2025 , month=. doi:10.1609/aies.v8i1.36598 , abstractNote=
-
[38]
ELEPHANT: Measuring and understanding social sycophancy in LLMs
Social sycophancy: A broader understanding of llm sycophancy , author=. arXiv preprint arXiv:2505.13995 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong. C hat D ev: Communicative Agents for Software Development. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguist...
-
[40]
On the Resilience of
Huang, Jen-Tse and Zhou, Jiaxu and Jin, Tailin and Zhou, Xuhui and Chen, Zixi and Wang, Wenxuan and Yuan, Youliang and Lyu, Michael and Sap, Maarten , booktitle =. On the Resilience of. 2025 , editor =
2025
-
[41]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , url =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Tom and Cao, Yuan and Narasimhan, Karthik , booktitle =. Tree of Thoughts: Deliberate Problem Solving with Large Language Models , url =
-
[42]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Wang, Lei and Xu, Wanyu and Lan, Yihuai and Hu, Zhiqiang and Lan, Yunshi and Lee, Roy Ka-Wei and Lim, Ee-Peng. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.147
-
[43]
Human-level play in the game of Diplomacy by combining language models with strategic reasoning , journal =. 2022 , doi =. https://www.science.org/doi/pdf/10.1126/science.ade9097 , abstract =
-
[44]
Jian Xie, Kai Zhu, Zixun Song, Yu Zhang, and Ji-Rong Wen
Yu, XiaoPeng and Zhang, Wanpeng and Lu, Zongqing. LLM -Based Explicit Models of Opponents for Multi-Agent Games. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.41
-
[45]
Suspicion Agent: Playing Imperfect Information Games with Theory of Mind Aware
Jiaxian Guo and Bo Yang and Paul Yoo and Bill Yuchen Lin and Yusuke Iwasawa and Yutaka Matsuo , booktitle=. Suspicion Agent: Playing Imperfect Information Games with Theory of Mind Aware. 2024 , url=
2024
-
[46]
What You Need is what You Get: Theory of Mind for an LLM-Based Code Understanding Assistant , year=
Richards, Jonan and Wessel, Mairieli , booktitle=. What You Need is what You Get: Theory of Mind for an LLM-Based Code Understanding Assistant , year=
-
[47]
Minding language models’(lack of) theory of mind: A plug-and-play multi-character belief tracker
Minding language models'(lack of) theory of mind: A plug-and-play multi-character belief tracker , author=. arXiv preprint arXiv:2306.00924 , year=
-
[48]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[49]
Reflexion: language agents with verbal reinforcement learning , url =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle =. Reflexion: language agents with verbal reinforcement learning , url =
-
[50]
Reflective Multi-Agent Collaboration based on Large Language Models , url =
Bo, Xiaohe and Zhang, Zeyu and Dai, Quanyu and Feng, Xueyang and Wang, Lei and Li, Rui and Chen, Xu and Wen, Ji-Rong , booktitle =. Reflective Multi-Agent Collaboration based on Large Language Models , url =. doi:10.52202/079017-4397 , editor =
-
[51]
Gradientsys: A multi-agent llm scheduler with react orchestration,
Gradientsys: A Multi-Agent LLM Scheduler with ReAct Orchestration , author=. arXiv preprint arXiv:2507.06520 , year=
-
[52]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[53]
Theory of Mind for Multi-Agent Collaboration via Large Language Models
Li, Huao and Chong, Yu and Stepputtis, Simon and Campbell, Joseph and Hughes, Dana and Lewis, Charles and Sycara, Katia. Theory of Mind for Multi-Agent Collaboration via Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.13
-
[54]
Agashe, Saaket and Fan, Yue and Reyna, Anthony and Wang, Xin Eric. LLM -Coordination: Evaluating and Analyzing Multi-agent Coordination Abilities in Large Language Models. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.448
-
[55]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society , url =
Li, Guohao and Hammoud, Hasan and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , booktitle =. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society , url =
-
[56]
AutoGen: Enabling Next-Gen
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and Ahmed Hassan Awadallah and Ryen W White and Doug Burger and Chi Wang , booktitle=. AutoGen: Enabling Next-Gen. 2024 , url=
2024
-
[57]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face , url =
Shen, Yongliang and Song, Kaitao and Tan, Xu and Li, Dongsheng and Lu, Weiming and Zhuang, Yueting , booktitle =. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face , url =
-
[58]
Sycara , booktitle=
Muhan Lin and Shuyang Shi and Yue Guo and Vaishnav Tadiparthi and Behdad Chalaki and Ehsan Moradi Pari and Simon Stepputtis and Woojun Kim and Joseph Campbell and Katia P. Sycara , booktitle=. Speaking the Language of Teamwork:. 2025 , url=
2025
-
[59]
DRF: LLM-AGENT Dynamic Reputation Filtering Framework
Lou, Yuwei and Hu, Hao and Ma, Shaocong and Zhang, Zongfei and Wang, Liang and Ge, Jidong and Tao, Xianping. DRF: LLM-AGENT Dynamic Reputation Filtering Framework. Neural Information Processing. 2026
2026
-
[60]
Can large language model agents simulate human trust behavior? , isbn =
Xie, Chengxing and Chen, Canyu and Jia, Feiran and Ye, Ziyu and Lai, Shiyang and Shu, Kai and Gu, Jindong and Bibi, Adel and Hu, Ziniu and Jurgens, David and Evans, James and Torr, Philip H.S. and Ghanem, Bernard and Li, Guohao , booktitle =. Can Large Language Model Agents Simulate Human Trust Behavior? , url =. doi:10.52202/079017-0501 , editor =
-
[61]
Nature Human Behaviour , volume=
Playing repeated games with large language models , author=. Nature Human Behaviour , volume=. 2025 , doi=
2025
-
[62]
ICML 2024 Workshop on LLMs and Cognition , year=
Large Language Models are Bad Game Theoretic Reasoners: Evaluating Performance and Bias in Two-Player Non-Zero-Sum Games , author=. ICML 2024 Workshop on LLMs and Cognition , year=
2024
-
[63]
arXiv preprint arXiv:2410.10479 , year =
Tmgbench: A systematic game benchmark for evaluating strategic reasoning abilities of llms , author=. arXiv preprint arXiv:2410.10479 , year=
-
[64]
Sun, Haoran and Wu, Yusen and Cheng, Yukun and Chu, Xu , title =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , articleno =. 2025 , isbn =. doi:10.24963/ijcai.2025/1184 , abstract =
-
[65]
Ex- ploring large language models for communica- tion games: An empirical study on werewolf
Exploring large language models for communication games: An empirical study on werewolf , author=. arXiv preprint arXiv:2309.04658 , year=
-
[66]
Avalon’s game of thoughts: Battle against deception through recursive contemplation,
Avalon's game of thoughts: Battle against deception through recursive contemplation , author=. arXiv preprint arXiv:2310.01320 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.