Recognition: unknown
Mass Matrix Assembly on Tensor Cores for Implicit Particle-In-Cell Methods
Pith reviewed 2026-05-10 01:44 UTC · model grok-4.3
The pith
Mass matrix assembly for implicit particle-in-cell methods can be reformulated exactly as sequences of tensor-core matrix products.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
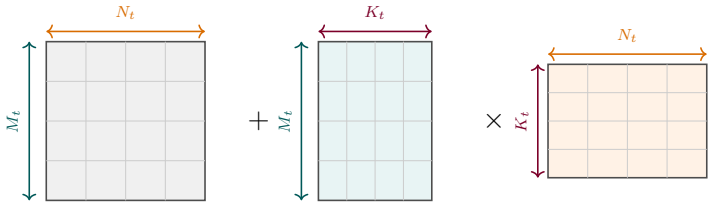
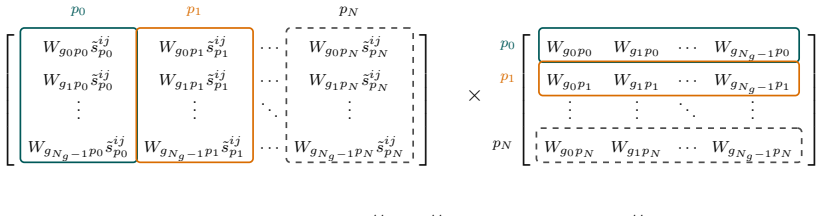
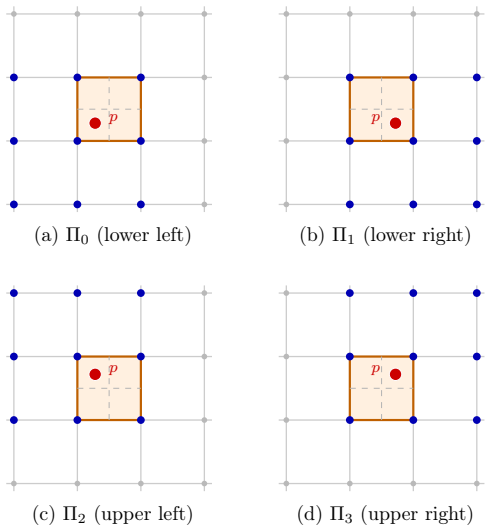
The central claim is that the per-cell accumulation of particle-weighted outer products that produces the mass matrix can be expressed exactly as a short sequence of matrix-matrix multiplies sized to match the tile dimensions of tensor cores, with the same numerical result as the conventional summation. The authors introduce particle batching to improve occupancy and a support-group decomposition that groups contributions from particles whose stencils span multiple cells, then specialize the scheme to first- and second-order B-splines and implement it on NVIDIA tensor cores, obtaining up to 3x kernel speedups and a 15% reduction in full ECSIM run time.
What carries the argument
Exact per-cell reformulation of weighted outer-product accumulation into tiled matrix products, together with particle batching and support-group decomposition for stencils that cross cell boundaries.
If this is right
- Kernels run up to three times faster than optimized conventional implementations on the same hardware.
- Full end-to-end ECSIM simulations finish 15 percent sooner.
- The same matrix-product view applies unchanged to both scalar and tensorial block mass matrices.
- The approach is stated to be independent of specific hardware as long as MMA units are present.
Where Pith is reading between the lines
- Other reduction kernels that build grid quantities from particle weights, such as current deposition, might admit similar exact rewrites.
- Codes that already run on tensor-core hardware could adopt the method with minimal changes to their particle data layout.
- The reformulation may reduce the relative cost of implicit solvers enough to make them competitive with explicit ones at higher particle counts.
Load-bearing premise
The batching and decomposition steps remain numerically stable and free of hidden overheads that would erase the speedups for every interpolation order and every particle distribution.
What would settle it
Compare the assembled mass-matrix entries element-by-element between the new tensor-core kernels and a reference double-precision summation for a test case with second-order B-splines; any nonzero difference falsifies exactness.
Figures








read the original abstract
Matrix-multiply-accumulate (MMA) units, or tensor cores, are now widespread across modern computing architectures. Yet, their use for particle-grid operators remains limited. In implicit particle methods, mass-matrix assembly is a reduction-dominated kernel in which weighted outer products of interpolation weights are accumulated over particle support. We show that this operation can be reformulated exactly, cell by cell, as a sequence of matrix products matched to hardware MMA tiles. The formulation is general with respect to interpolation order and hardware platform, and applies to both scalar mass matrices and the tensorial block mass matrix arising in implicit in the Energy-Conserving Semi-Implicit Method (ECSIM) for Particle-in-Cell simulations. We introduce particle batching and a support-group decomposition for higher-order shape functions whose stencil extends beyond a single cell, specialize the method to first- and second-order B-spline interpolation, and implement it on NVIDIA tensor cores. The resulting kernels achieve up to 3x over optimized conventional implementations and reduce end-to-end ECSIM runtime by 15%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the mass-matrix assembly operation in implicit particle-in-cell methods—accumulation of weighted outer products over particle supports—can be reformulated exactly, cell by cell, as sequences of matrix-multiply-accumulate operations matched to hardware tensor-core tiles. The reformulation is presented as general with respect to interpolation order and platform, covering both scalar mass matrices and the tensorial block matrices of the ECSIM method; it is specialized to first- and second-order B-splines via particle batching and support-group decomposition, implemented on NVIDIA tensor cores, and reported to deliver up to 3× kernel speedups with a 15 % reduction in end-to-end ECSIM runtime.
Significance. If the claimed exact equivalence holds and the tensor-core implementation preserves numerical fidelity without offsetting overheads, the work would provide a practical route to accelerate a reduction-dominated kernel that appears in many implicit PIC codes. The generality across interpolation orders and the explicit handling of both scalar and block matrices are strengths that could translate to other particle-grid operators once the numerical properties are confirmed.
major comments (2)
- [Abstract] Abstract: the central claim that the reformulation is 'exact' and produces results 'numerically equivalent' to conventional accumulation is load-bearing for the reported speedups, yet the manuscript provides no explicit numerical verification (e.g., relative-error tables or residual comparisons) between the tensor-core mixed-precision path and a reference double-precision implementation, particularly for second-order B-splines under irregular particle distributions.
- [Implementation] The description of particle batching and support-group decomposition (mentioned in the abstract) must be accompanied by a derivation or pseudocode showing that the decomposition preserves the exact cell-by-cell accumulation semantics; without this, it is impossible to confirm that no hidden overhead or accuracy loss is introduced when the stencil extends beyond a single cell.
minor comments (2)
- The abstract states that the formulation 'applies to both scalar mass matrices and the tensorial block mass matrix' but does not indicate whether separate kernels or a unified interface is provided; a short table contrasting the two cases would improve clarity.
- No mention is made of the floating-point formats actually used on the tensor cores (FP16/TF32 with FP32 accumulation) or of any fallback path that retains full double precision; adding this information would allow readers to assess the numerical trade-offs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying areas where additional clarity and verification would strengthen the manuscript. We respond to each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the reformulation is 'exact' and produces results 'numerically equivalent' to conventional accumulation is load-bearing for the reported speedups, yet the manuscript provides no explicit numerical verification (e.g., relative-error tables or residual comparisons) between the tensor-core mixed-precision path and a reference double-precision implementation, particularly for second-order B-splines under irregular particle distributions.
Authors: We agree that explicit numerical verification is necessary to substantiate the equivalence claim, particularly under mixed-precision tensor-core arithmetic. While the mathematical reformulation is exact, hardware-level rounding can produce small differences. In the revised manuscript we will add a new subsection containing relative-error tables (maximum and mean relative errors on mass-matrix entries) and residual comparisons against a double-precision reference implementation. These will be reported for both first- and second-order B-splines and will include test cases with irregular particle distributions. revision: yes
-
Referee: [Implementation] The description of particle batching and support-group decomposition (mentioned in the abstract) must be accompanied by a derivation or pseudocode showing that the decomposition preserves the exact cell-by-cell accumulation semantics; without this, it is impossible to confirm that no hidden overhead or accuracy loss is introduced when the stencil extends beyond a single cell.
Authors: We concur that a detailed derivation and pseudocode are required to demonstrate preservation of exact semantics. The current text introduces these techniques at a high level. We will expand the Implementation section with (i) a step-by-step mathematical derivation showing that the support-group decomposition maintains identical cell-by-cell accumulation and (ii) pseudocode for the particle-batching procedure. This addition will explicitly confirm the absence of hidden overhead or accuracy loss for stencils that span multiple cells. revision: yes
Circularity Check
No circularity: direct algorithmic reformulation of mass-matrix assembly
full rationale
The paper's core contribution is an exact cell-by-cell reformulation of weighted outer-product accumulation (mass-matrix assembly) into sequences of matrix-multiply-accumulate operations matched to hardware MMA tiles. This mapping follows directly from the definition of the particle-grid operator and the structure of B-spline supports; it does not invoke fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The claimed generality across interpolation orders and to both scalar and tensorial block matrices is obtained by specializing the same decomposition, without importing uniqueness theorems or ansatzes from prior author work. No derivation step reduces to its own inputs by construction, and the implementation details (particle batching, support-group decomposition) are presented as engineering choices rather than derived results. The work is therefore self-contained as an algorithmic technique.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Ba- jwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, R. Boyle, P.-l. Cantin, C. Chao, C. Clark, J. Coriell, M. Daley, M. Dau, J. Dean, B. Gelb, T. V. Ghaemmaghami, R. Gottipati, W. Gulland, R. Hagmann, C. R. Ho, D. Hogberg, J. Hu, R. Hundt, D. Hurt, J. Ibarz, A. Jaffey, A. Jaworski, A. Kaplan,...
-
[2]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaev, G. Venkatesh, H. Wu, Mixed precision training (10 2017).doi:10.48550/arXiv.1710.03740
work page internal anchor Pith review doi:10.48550/arxiv.1710.03740 2017
-
[3]
A. Reuther, P. Michaleas, M. Jones, V. Gadepally, S. Samsi, J. Kep- ner, Survey of machine learning accelerators, in: 2020 IEEE High Per- formance Extreme Computing Conference (HPEC), 2020, pp. 1–12. doi:10.1109/HPEC43674.2020.9286149
-
[4]
N. Jouppi, G. Kurian, S. Li, P. Ma, R. Nagarajan, L. Nai, N. Patil, S. Subramanian, A. Swing, B. Towles, C. Young, X. Zhou, Z. Zhou, D. Patterson, Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings (04 2023).doi: 10.48550/arXiv.2304.01433
-
[5]
N. J. Higham, T. Mary, Mixed precision algorithms in numerical linear algebra, Acta Numerica 31 (2022) 347–414.doi:10.1017/ S0962492922000022
2022
-
[6]
A. Haidar, S. Tomov, J. Dongarra, N. J. Higham, Harnessing gpu ten- sor cores for fast fp16 arithmetic to speed up mixed-precision iterative 24 refinement solvers, in: Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, SC ’18, IEEE Press, 2019.doi:10.1109/SC.2018.00050. URLhttps://doi.org/10.1109...
-
[7]
C. Cui, Acceleration of tensor-product operations with tensor cores, ACM Trans. Parallel Comput. 11 (4) (Nov. 2024).doi:10.1145/ 3695466. URLhttps://doi.org/10.1145/3695466
-
[8]
X. Liu, Y. Liu, H. Yang, J. Liao, M. Li, Z. Luan, D. Qian, Toward ac- celerated stencil computation by adapting tensor core unit on gpu, in: Proceedings of the 36th ACM International Conference on Supercom- puting, ICS ’22, Association for Computing Machinery, New York, NY, USA, 2022.doi:10.1145/3524059.3532392. URLhttps://doi.org/10.1145/3524059.3532392
-
[9]
L. Oostrum, B. Veenboer, R. Rook, M. Brown, P. Kruizinga, J. W. Romein, The Tensor-Core Beamformer: A High-Speed Signal-Processing Library for Multidisciplinary Use , in: 2025 IEEE International Parallel and Distributed Processing Symposium (IPDPS), IEEE Computer Society, Los Alamitos, CA, USA, 2025, pp. 582–592. doi:10.1109/IPDPS64566.2025.00058. URLhttp...
-
[10]
Schieffer, I
G. Schieffer, I. Peng, Accelerating drug discovery in autodock-gpu with tensor cores, in: J. Cano, M. D. Dikaiakos, G. A. Papadopoulos, M. Per- icàs, R. Sakellariou (Eds.), Euro-Par 2023: Parallel Processing, Springer Nature Switzerland, Cham, 2023, pp. 608–622
2023
-
[11]
J. Finkelstein, J. S. Smith, S. M. Mniszewski, K. Barros, C. F. A. Ne- gre, E. H. Rubensson, A. M. N. Niklasson, Quantum-based molecular dynamics simulations using tensor cores, Journal of Chemical Theory and Computation 17 (10) (2021) 6180–6192.doi:10.1021/acs.jctc. 1c00726. URLhttps://doi.org/10.1021/acs.jctc.1c00726
-
[12]
G. Lapenta, Exactly energy conserving semi-implicit particle in cell formulation, Journal of Computational Physics 334 (2017) 349–366. 25 doi:https://doi.org/10.1016/j.jcp.2017.01.002. URLhttps://www.sciencedirect.com/science/article/pii/ S0021999117300128
-
[13]
D. Burgess, D. Sulsky, J. Brackbill, Mass matrix formulation of the flip particle-in-cellmethod, JournalofComputationalPhysics103(1)(1992) 1–15.doi:https://doi.org/10.1016/0021-9991(92)90323-Q. URLhttps://www.sciencedirect.com/science/article/pii/ 002199919290323Q
-
[14]
Aparticlemethodforhistory-dependentmaterials
D. Sulsky, Z. Chen, H. Schreyer, A particle method for history- dependent materials, Computer Methods in Applied Mechan- ics and Engineering 118 (1) (1994) 179–196.doi:https: //doi.org/10.1016/0045-7825(94)90112-0. URLhttps://www.sciencedirect.com/science/article/pii/ 0045782594901120
-
[15]
D. Sulsky, S.-J. Zhou, H. L. Schreyer, Application of a particle- in-cell method to solid mechanics, Computer Physics Commu- nications 87 (1) (1995) 236–252, particle Simulation Methods. doi:https://doi.org/10.1016/0010-4655(94)00170-7. URLhttps://www.sciencedirect.com/science/article/pii/ 0010465594001707
-
[16]
C. K. Birdsall, A. B. Langdon, Plasma Physics via Computer Simula- tion, 1991
1991
-
[17]
Hockney, Computer Simulation Using Particles, CRC Press, 1988
R. Hockney, Computer Simulation Using Particles, CRC Press, 1988. URLhttps://books.google.se/books?id=SVslEAAAQBAJ
1988
-
[18]
T. Montoya, D. W. Zingg, A unifying algebraic framework for discontin- uous galerkin and flux reconstruction methods based on the summation- by-parts property, Journal of Scientific Computing 92 (3) (2022) 87. doi:10.1007/s10915-022-01935-3. URLhttps://doi.org/10.1007/s10915-022-01935-3
-
[19]
URLhttps://doi.org/10.1137/20M1311934
B.Perse, K.Kormann, E.Sonnendrücker, Geometricparticle-in-cellsim- ulations of the vlasov–maxwell system in curvilinear coordinates, SIAM Journal on Scientific Computing 43 (1) (2021) B194–B218.arXiv: 26 https://doi.org/10.1137/20M1311934,doi:10.1137/20M1311934. URLhttps://doi.org/10.1137/20M1311934
-
[20]
J. Monaghan, Particle methods for hydrodynamics, Com- puter Physics Reports 3 (2) (1985) 71–124.doi:https: //doi.org/10.1016/0167-7977(85)90010-3. URLhttps://www.sciencedirect.com/science/article/pii/ 0167797785900103
-
[21]
S. Markidis, S. W. D. Chien, E. Laure, I. B. Peng, J. S. Vetter, Nvidia tensor core programmability, performance & precision, in: 2018 IEEE International Parallel and Distributed Processing Symposium Work- shops (IPDPSW), 2018, pp. 522–531.doi:10.1109/IPDPSW.2018. 00091
-
[22]
G. Schieffer, D. Medeiros, J. Faj, A. Marathe, I. Peng, On the rise of amd matrix cores: Performance, power efficiency, and programmability, 2024, pp. 132–143.doi:10.1109/ISPASS61541.2024.00022
-
[23]
H. Kim, G. Ye, N. Wang, A. Yazdanbakhsh, N. S. Kim, Exploiting intel advanced matrix extensions (amx) for large language model inference, IEEE Comput. Archit. Lett. 23 (1) (2024) 117–120.doi:10.1109/LCA. 2024.3397747. URLhttps://doi.org/10.1109/LCA.2024.3397747
work page doi:10.1109/lca 2024
-
[24]
Bowers, Accelerating a particle-in-cell simulation using a hybrid counting sort, Journal of Computational Physics 173 (2) (2001) 393– 411
K. Bowers, Accelerating a particle-in-cell simulation using a hybrid counting sort, Journal of Computational Physics 173 (2) (2001) 393– 411
2001
-
[25]
J. Brackbill, D. Forslund, An implicit method for electro- magnetic plasma simulation in two dimensions, Journal of Computational Physics 46 (2) (1982) 271–308.doi:https: //doi.org/10.1016/0021-9991(82)90016-X. URLhttps://www.sciencedirect.com/science/article/pii/ 002199918290016X
-
[26]
S. Markidis, G. Lapenta, Rizwan-uddin, Multi-scale simulations of plasma with ipic3d, Mathematics and Computers in Simulation 80 (7) (2010) 1509–1519, multiscale modeling of moving interfaces in materials. doi:https://doi.org/10.1016/j.matcom.2009.08.038. 27 URLhttps://www.sciencedirect.com/science/article/pii/ S0378475409002444
-
[27]
Laure, The fluid-kinetic particle-in-cell method for plasma simula- tions, Journal of Computational Physics 271 (2014) 415–429
S.Markidis, P.Henri, G.Lapenta, K.Rönnmark, M.Hamrin, Z.Meliani, E. Laure, The fluid-kinetic particle-in-cell method for plasma simula- tions, Journal of Computational Physics 271 (2014) 415–429. 28
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.