Recognition: unknown
PLaMo 2.1-VL Technical Report
Pith reviewed 2026-05-10 03:05 UTC · model grok-4.3
The pith
PLaMo 2.1-VL outperforms comparable open models on Japanese and English VQA benchmarks while supporting practical industrial applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PLaMo 2.1-VL introduces lightweight 8B and 2B vision-language models optimized for autonomous devices that achieve superior results on Japanese and English benchmarks for visual question answering and grounding, and deliver useful performance in factory task analysis and infrastructure anomaly detection scenarios.
What carries the argument
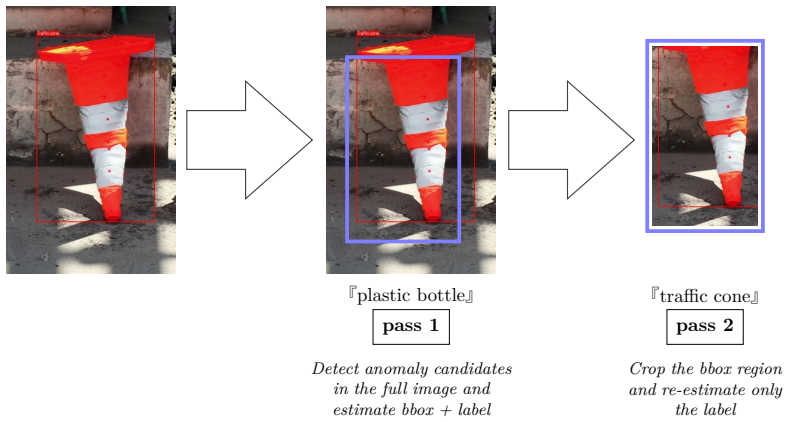
The large-scale synthetic data generation pipeline that creates training examples for Japanese visual grounding and question answering tailored to factory and power plant domains.
If this is right
- The approach enables deployment of vision-language capabilities directly on edge devices without constant internet connectivity.
- Domain-specific fine-tuning can substantially improve anomaly detection performance in infrastructure settings.
- Japanese-language VLMs can now handle practical industrial tasks like tool recognition at competitive accuracy levels.
- Synthetic data pipelines offer a scalable way to build training sets for specialized visual tasks where real data is scarce.
Where Pith is reading between the lines
- Similar models could be adapted for other languages and industrial domains by replicating the synthetic data approach.
- Local processing might improve response times and data privacy in sensitive manufacturing environments.
- Further scaling down or quantization could make the 2B variant suitable for even more constrained hardware.
Load-bearing premise
The large-scale synthetic data generation pipeline produces training examples that are sufficiently representative of real factory and power-plant visual distributions.
What would settle it
Deployment of the model in an actual factory or power plant where the achieved accuracy on live visual tasks falls significantly below the reported benchmark and fine-tuned scores.
Figures








read the original abstract
We introduce PLaMo 2.1-VL, a lightweight Vision Language Model (VLM) for autonomous devices, available in 8B and 2B variants and designed for local and edge deployment with Japanese-language operation. Focusing on Visual Question Answering (VQA) and Visual Grounding as its core capabilities, we develop and evaluate the models for two real-world application scenarios: factory task analysis via tool recognition, and infrastructure anomaly detection. We also develop a large-scale synthetic data generation pipeline and comprehensive Japanese training and evaluation resources. PLaMo 2.1-VL outperforms comparable open models on Japanese and English benchmarks, achieving 61.5 ROUGE-L on JA-VG-VQA-500 and 85.2% accuracy on Japanese Ref-L4. For the two application scenarios, it achieves 53.9% zero-shot accuracy on factory task analysis, and fine-tuning on power plant data improves anomaly detection bbox + label F1-score from 39.7 to 64.9.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PLaMo 2.1-VL, a lightweight vision-language model in 8B and 2B variants optimized for local/edge deployment with Japanese-language support. Core capabilities are VQA and visual grounding, enabled by a large-scale synthetic data generation pipeline and new Japanese resources. The models are claimed to outperform comparable open models on Japanese and English benchmarks (61.5 ROUGE-L on JA-VG-VQA-500; 85.2% on Japanese Ref-L4) and are evaluated in two industrial scenarios: 53.9% zero-shot accuracy on factory task analysis and an F1-score lift from 39.7 to 64.9 for power-plant anomaly detection after fine-tuning.
Significance. If the empirical claims hold with full methodological transparency, the work could be significant for efficient VLMs on autonomous devices in Japanese industrial settings, particularly the application-focused evaluations. The synthetic data pipeline and dual-language benchmarks represent a practical contribution. However, the absence of architecture details, baselines, hyperparameters, and synthetic-to-real validation in the reported results substantially reduces the assessed significance and reproducibility.
major comments (2)
- [Abstract] Abstract: The central application claims (53.9% zero-shot factory accuracy; F1 improvement from 39.7 to 64.9) are presented as direct outcomes without any reference to baseline models, training hyperparameters, statistical significance, or error bars. This prevents verification of the reported gains and is load-bearing for the outperformance narrative.
- [Synthetic data generation pipeline] Synthetic data generation pipeline section: The performance numbers for both application scenarios rest on the unvalidated assumption that the synthetic images match real factory and power-plant visual statistics (lighting, noise, occlusions, textures). No domain-similarity metrics, feature-space distances, human studies, or ablation on held-out real imagery are provided, directly undermining generalization claims.
minor comments (1)
- [Abstract] The abstract supplies no architecture diagram, parameter counts beyond the two variants, or training objective details, which would improve clarity even for a technical report.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our technical report. The comments highlight important areas for improving transparency around the application results and the validation of our synthetic data pipeline. We will revise the manuscript accordingly to strengthen reproducibility while preserving the core contributions on lightweight Japanese VLMs for industrial use.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central application claims (53.9% zero-shot factory accuracy; F1 improvement from 39.7 to 64.9) are presented as direct outcomes without any reference to baseline models, training hyperparameters, statistical significance, or error bars. This prevents verification of the reported gains and is load-bearing for the outperformance narrative.
Authors: We agree that the abstract would benefit from additional context to support verification of the application claims. In the revised version, we will update the abstract to include brief references to the baseline models and prior performance levels (e.g., clarifying that the 39.7 F1 represents the pre-fine-tuning baseline on the same power-plant anomaly detection task). We will also add pointers to the sections detailing training hyperparameters, evaluation protocols, and any available measures of variability (such as standard deviations from multiple runs). These changes will make the reported gains more verifiable without altering the abstract's length substantially. revision: yes
-
Referee: [Synthetic data generation pipeline] Synthetic data generation pipeline section: The performance numbers for both application scenarios rest on the unvalidated assumption that the synthetic images match real factory and power-plant visual statistics (lighting, noise, occlusions, textures). No domain-similarity metrics, feature-space distances, human studies, or ablation on held-out real imagery are provided, directly undermining generalization claims.
Authors: We acknowledge that explicit validation of the synthetic data against real visual statistics is necessary to support the generalization claims for the factory and power-plant scenarios. The current manuscript describes the pipeline's design principles but does not report quantitative domain alignment. In the revision, we will add domain-similarity metrics (such as FID scores and feature-space distances computed on representative real and synthetic image sets), an ablation evaluating performance on held-out real imagery for the anomaly detection task, and a small-scale human study on image realism where feasible. These additions will directly address the concern while building on the existing pipeline description. revision: yes
Circularity Check
No circularity: purely empirical reporting with no derivation chain
full rationale
The paper is a technical report on model development and benchmarking. It presents PLaMo 2.1-VL as an empirical artifact whose performance numbers (ROUGE-L, accuracy, F1 scores) are obtained by direct training and evaluation on stated datasets and scenarios. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on external benchmarks and application metrics rather than any reduction to the paper's own inputs by construction. The synthetic data pipeline is described as a development step but is not used to derive the reported results tautologically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in Neural Information Processing Systems , 36:34892–34916, 2023
2023
-
[2]
Preferred Networks, Inc., Kaizaburo Chubachi, Yasuhiro Fujita, Shinichi Hemmi, Yuta Hi- rokawa, Kentaro Imajo, Toshiki Kataoka, Goro Kobayashi, Kenichi Maehashi, Calvin Met- zger, et al. PLaMo 2 Technical Report. https://arxiv.org/abs/2509.04897, 2025. arXiv preprint arXiv:2509.04897
-
[3]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Lo- calization, and Dense Features. https://arxiv.org/abs/2502.14786, 2025. arXiv preprint arXiv...
work page internal anchor Pith review arXiv 2025
-
[4]
google/siglip2-so400m-patch14-384
Google DeepMind. google/siglip2-so400m-patch14-384. https://huggingface.co/google/ siglip2-so400m-patch14-384 . Accessed: 2026-04-08
2026
- [6]
-
[8]
arXiv preprint arXiv:2407.07726. 25
work page internal anchor Pith review arXiv
-
[9]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jian- qiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL Technical Report....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
BLIP-2: Bootstrapping Language- Image Pre-training with Frozen Image Encoders and Large Language Models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping Language- Image Pre-training with Frozen Image Encoders and Large Language Models. In International Conference on Machine Learning , pages 19730–19742. PMLR, 2023
2023
-
[11]
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolu- tion
Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim M Alabdul- mohsin, et al. Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolu- tion. Advances in Neural Information Processing Systems , 36:2252–2274, 2023
2023
-
[12]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. LoRA: Low-Rank Adaptation of Large Language Models. ICLR, 1(2):3, 2022
2022
-
[13]
SakanaAI/JA-VG-VQA-500
Sakana AI. SakanaAI/JA-VG-VQA-500. https://huggingface.co/datasets/SakanaAI/ JA-VG-VQA-500 . Accessed: 2026-04-08
2026
-
[14]
ROUGE: A Package for Automatic Evaluation of Summaries
Chin-Yew Lin. ROUGE: A Package for Automatic Evaluation of Summaries. In Proc. Work- shop on Text Summariation Branches Out, Post-Conference Workshop of ACL 2004 , 2004
2004
-
[15]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Advances in Neural Information Processing Systems , 36:46595–46623, 2023
2023
-
[16]
Constructing Multimodal Datasets from Scratch for Rapid Development of a Japanese Visual Language Model
Keito Sasagawa, Koki Maeda, Issa Sugiura, Shuhei Kurita, Naoaki Okazaki, and Daisuke Kawahara. Constructing Multimodal Datasets from Scratch for Rapid Development of a Japanese Visual Language Model. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (S...
2025
-
[17]
JierunChen/Ref-L4
Jierun Chen, Fangyun Wei, Jinjing Zhao, Sizhe Song, Bohuai Wu, Zhuoxuan Peng, S-H Gary Chan, and Hongyang Zhang. JierunChen/Ref-L4. https://huggingface.co/datasets/ JierunChen/Ref-L4. Accessed: 2026-04-08
2026
-
[18]
Ja-Ref-L4
Preferred Networks, Inc. Ja-Ref-L4. https://github.com/pfnet-research/Ja-Ref-L4 ,
-
[20]
Modeling Context in Referring Expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling Context in Referring Expressions. In European Conference on Computer Vision , pages 69–85. Springer, 2016
2016
-
[21]
Distinctive Image Features from Scale-Invariant Keypoints
David G Lowe. Distinctive Image Features from Scale-Invariant Keypoints. International Journal of Computer Vision , 60(2):91–110, 2004
2004
-
[22]
LightGlue: Local Feature Matching at Light Speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Pollefeys. LightGlue: Local Feature Matching at Light Speed. In Proceedings of the IEEE/CVF international conference on com- puter vision , pages 17627–17638, 2023. 26
2023
-
[23]
Qwen/Qwen2.5-VL-32B-Instruct
Qwen Team. Qwen/Qwen2.5-VL-32B-Instruct. https://huggingface.co/Qwen/Qwen2. 5-VL-32B-Instruct , 2025. Accessed: 2026-04-08
2025
-
[24]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL Technical Report. https: //arxiv.org/abs/2511.21631, 2025. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Qwen/Qwen3-32B
Qwen Team. Qwen/Qwen3-32B. https://huggingface.co/Qwen/Qwen3-32B, 2025. Accessed: 2026-04-08
2025
-
[27]
Open Images Dataset V7
Open Images. Open Images Dataset V7. https://storage.googleapis.com/openimages/ web/index.html. Accessed: 2026-04-08
2026
-
[28]
Tom May. P1210645-a. https://www.flickr.com/photos/sleepyhammer/16541842339,
-
[29]
Accessed: 2026-04-08
2026
-
[30]
Attribution 2.0 Generic (CC BY 2.0)
Creative Commons. Attribution 2.0 Generic (CC BY 2.0). https://creativecommons.org/ licenses/by/2.0/. Accessed: 2026-04-08
2026
-
[31]
Mohd Fazlin Mohd Effendy Ooi. Sunway Lagoon. https://www.flickr.com/photos/ phalinn/21104786682, 2015. Accessed: 2026-04-08
-
[32]
pfnet/plamo-2-translate
Preferred Networks, Inc. pfnet/plamo-2-translate. https://huggingface.co/pfnet/ plamo-2-translate, 2025. Accessed: 2026-04-08
2025
-
[33]
Pexels License
Pexels. Pexels License. https://www.pexels.com/ja-JP/license/. Accessed: 2026-04-08
2026
-
[34]
Pexels. Photo 2821220. https://www.pexels.com/ja-jp/photo/2821220/. Accessed: 2026- 04-08
-
[35]
pfnet/plamo-embedding-1b
Preferred Networks, Inc. pfnet/plamo-embedding-1b. https://huggingface.co/pfnet/ plamo-embedding-1b, 2025. Accessed: 2026-04-08
2025
-
[36]
MIL-UT/Asagi-14B
MIL-UT. MIL-UT/Asagi-14B. https://huggingface.co/MIL-UT/Asagi-14B. Accessed: 2026-04-08
2026
-
[37]
Qwen/Qwen3-VL-8B-Instruct
Qwen Team. Qwen/Qwen3-VL-8B-Instruct. https://huggingface.co/Qwen/ Qwen3-VL-8B-Instruct , 2025. Accessed: 2026-04-08
2025
-
[38]
Qwen/Qwen2.5-VL-7B-Instruct
Qwen Team. Qwen/Qwen2.5-VL-7B-Instruct. https://huggingface.co/Qwen/Qwen2. 5-VL-7B-Instruct , 2025. Accessed: 2026-04-08
2025
-
[39]
Qwen/Qwen3-VL-235B-A22B-Instruct
Qwen Team. Qwen/Qwen3-VL-235B-A22B-Instruct. https://huggingface.co/Qwen/ Qwen3-VL-235B-A22B-Instruct , 2025. Accessed: 2026-04-08. 27
2025
-
[40]
Fruit Mart
Pixabay. Fruit Mart. https://www.stockvault.net/photo/200223/adler32, 2016. Ac- cessed: 2026-04-08
2016
-
[41]
Family Ride bicycle cycle trailer
Kamyar Adl. Family Ride bicycle cycle trailer. https://commons.wikimedia.org/wiki/ File:Family_Ride_bicycle_cycle_trailer.jpg, 2007. Accessed: 2026-04-08
2007
-
[42]
A group of bowls of food
Aline Ponce. A group of bowls of food. https://freerangestock.com/photos/150988/ a-group-of-bowls-of-food.html . Accessed: 2026-04-08
2026
-
[43]
Fruit Mart
Pixabay. A construction site under a bridge with a crane in the background Highway construction site valley bridge crash. https://picryl.com/media/ highway-construction-site-valley-bridge-crash-dc08bd , 2016. Accessed: 2026-04-08. 28 A Appendix A.1 Prompt Example for Factory Task Analysis During inference for task analysis, we utilized prompts that provid...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.