Recognition: unknown
Quadruped Parkour Learning: Sparsely Gated Mixture of Experts with Visual Input
Pith reviewed 2026-05-10 02:26 UTC · model grok-4.3
The pith
Sparsely gated mixture-of-experts policies double successful trials over matched MLP baselines in real-robot vision-based quadruped parkour.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sparsely gated MoE architectures, when used for vision-based quadruped parkour policies, produce higher success rates than densely activated MLPs when the count of active parameters during inference is kept identical. Experiments on a real Unitree Go2 quadruped show the MoE policy achieving twice the number of successful trials over large obstacles. An MLP scaled to the full parameter count of the MoE model requires 14.3 percent more computation time yet still underperforms. The results establish that the sparse-gating mechanism supplies an efficient route to higher-capacity control policies for challenging terrain without proportional increases in runtime cost.
What carries the argument
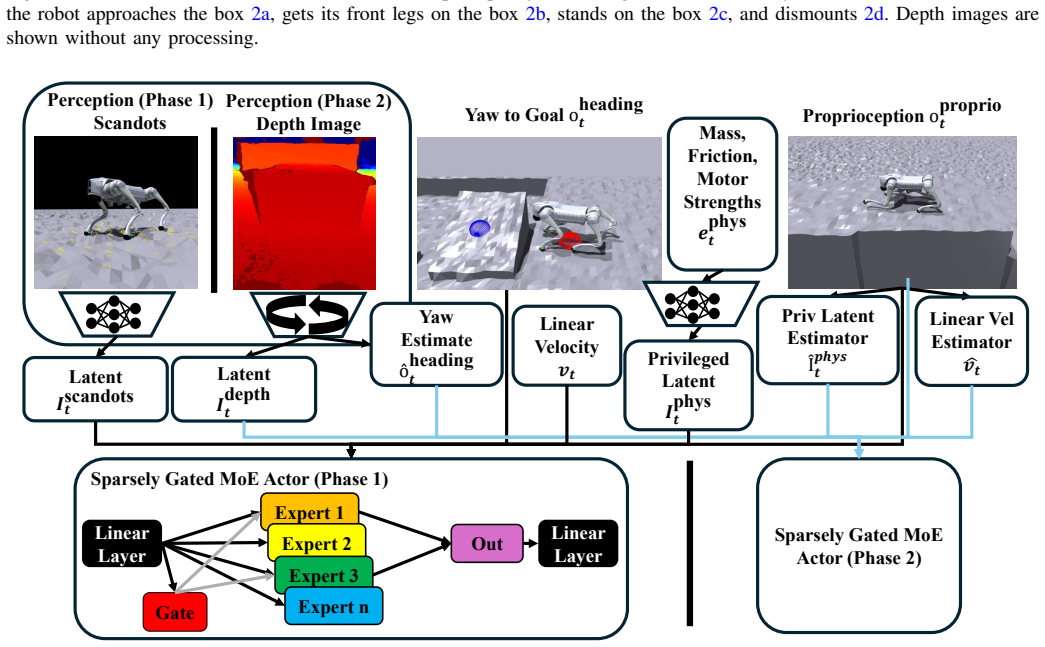
Sparsely gated mixture-of-experts architecture, which routes each input to activate only a small subset of expert sub-networks while maintaining a larger total parameter pool.
If this is right
- MoE policies reach higher success rates on discontinuous terrain without increasing inference-time computation.
- Scaling an MLP to the total parameter size of an MoE raises runtime cost by 14.3 percent while still falling short of MoE performance.
- Sparse activation enables larger vision-based locomotion policies to remain real-time feasible on hardware such as the Unitree Go2.
- The gating approach supports continued scaling of parkour capabilities without linear growth in per-step compute.
Where Pith is reading between the lines
- The same sparse-gating pattern could be applied to other high-dimensional robotic tasks such as manipulation or multi-robot coordination where input complexity varies.
- If active-parameter matching is preserved, future comparisons could isolate whether the benefit stems mainly from conditional computation or from the larger total capacity.
- Deploying MoE policies on embedded robot hardware may allow researchers to test even larger expert pools while staying within fixed latency budgets.
Load-bearing premise
All differences between MoE and MLP policies arise solely from the sparse gating mechanism because visual observation processing, training procedure, and active-parameter count have been matched exactly.
What would settle it
An experiment that retrains both policies from scratch with identical visual encoders, identical training data and hyperparameters, and identical active-parameter budgets yet finds the MLP achieving equal or higher success rates on the same large-obstacle course.
Figures



read the original abstract
Robotic parkour provides a compelling benchmark for advancing locomotion over highly challenging terrain, including large discontinuities such as elevated steps. Recent approaches have demonstrated impressive capabilities, including dynamic climbing and jumping, but typically rely on sequential multilayer perceptron (MLP) architectures with densely activated layers. In contrast, sparsely gated mixture-of-experts (MoE) architectures have emerged in the large language model domain as an effective paradigm for improving scalability and performance by activating only a subset of parameters at inference time. In this work, we investigate the application of sparsely gated MoE architectures to vision-based robotic parkour. We compare control policies based on standard MLPs and MoE architectures under a controlled setting where the number of active parameters at inference time is matched. Experimental results on a real Unitree Go2 quadruped robot demonstrate clear performance gains, with the MoE policy achieving double the number of successful trials in traversing large obstacles compared to a standard MLP baseline. We further show that achieving comparable performance with a standard MLP requires scaling its parameter count to match that of the total MoE model, resulting in a 14.3\% increase in computation time. These results highlight that sparsely gated MoE architectures provide a favorable trade-off between performance and computational efficiency, enabling improved scaling of control policies for vision-based robotic parkour. An anonymized link to the codebase is https://osf.io/v2kqj/files/github?view_only=7977dee10c0a44769184498eaba72e44.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates sparsely gated Mixture-of-Experts (MoE) architectures for vision-based quadruped parkour, contrasting them with standard MLP policies under a controlled setting that matches the number of active parameters at inference time. It reports real-robot experiments on a Unitree Go2 in which the MoE policy doubles the number of successful trials for traversing large obstacles relative to the MLP baseline, and shows that an MLP scaled to the total MoE parameter count incurs a 14.3% increase in computation time to reach comparable performance.
Significance. If the reported controls and results are verified, the work demonstrates that sparse gating can improve success rates in challenging vision-based locomotion without raising inference-time compute, offering a practical route to scale robotic control policies. The hardware validation on a standard quadruped platform adds direct applicability, though the absence of trial counts, statistical tests, and explicit matching protocols in the abstract limits immediate evaluation of robustness.
major comments (3)
- Abstract: The central claim that performance gains are observed 'under a controlled setting where the number of active parameters at inference time is matched' is load-bearing for attributing improvements to the MoE architecture. No quantitative values for active parameter counts, visual encoder details (architecture, preprocessing, feature dimension), or training hyperparameters (RL algorithm, horizon, batch size, reward, optimizer) are supplied, preventing verification that the doubling of successful trials isolates the effect of sparse gating.
- Abstract: The headline result states that the MoE policy achieves 'double the number of successful trials' without reporting absolute trial counts, success percentages, number of runs, or any statistical tests. This omission makes it impossible to assess whether the reported gain is statistically reliable or sensitive to experimental variability.
- Abstract: The secondary claim that matching MLP performance requires scaling to the total MoE parameter count and yields a '14.3% increase in computation time' lacks specification of the measurement protocol (hardware platform, batch size, whether gating overhead is included) and whether the scaled MLP preserves the same active-parameter regime as the MoE policy.
minor comments (2)
- The anonymized OSF codebase link is appropriate for review but should be replaced with a permanent, non-anonymized repository or DOI in the camera-ready version to support reproducibility.
- Consider adding a table or figure in the results section that explicitly lists active parameter counts, total parameter counts, inference latency, and success rates for all compared policies to make the matching protocol transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We have revised the abstract to incorporate the requested quantitative details, absolute trial results, and measurement protocols drawn from the main text. This improves verifiability while preserving the manuscript's contributions. We address each major comment below.
read point-by-point responses
-
Referee: Abstract: The central claim that performance gains are observed 'under a controlled setting where the number of active parameters at inference time is matched' is load-bearing for attributing improvements to the MoE architecture. No quantitative values for active parameter counts, visual encoder details (architecture, preprocessing, feature dimension), or training hyperparameters (RL algorithm, horizon, batch size, reward, optimizer) are supplied, preventing verification that the doubling of successful trials isolates the effect of sparse gating.
Authors: We agree that the abstract benefits from explicit quantitative values to support the controlled comparison. The manuscript already provides these details in Section 3 (network architectures, visual encoder as a CNN with specified preprocessing and feature dimensions, and MoE gating) and Section 4 (PPO training with horizon, batch size, reward formulation, and optimizer). In the revised abstract we now summarize the active parameter count for the MoE policy, the visual encoder architecture and input processing, feature dimension, and core training hyperparameters. This makes the isolation of the sparse-gating effect transparent at the abstract level. revision: yes
-
Referee: Abstract: The headline result states that the MoE policy achieves 'double the number of successful trials' without reporting absolute trial counts, success percentages, number of runs, or any statistical tests. This omission makes it impossible to assess whether the reported gain is statistically reliable or sensitive to experimental variability.
Authors: We acknowledge that absolute counts and run numbers strengthen interpretability. The experimental section already reports the raw trial counts, success percentages, and number of evaluation runs across seeds. We have updated the abstract to state these absolute figures explicitly. Formal statistical hypothesis testing was not performed in the original work because of the modest number of hardware trials; we have added a sentence noting observed variability across random seeds. If the referee considers a post-hoc test essential we can include it, but the raw counts allow direct assessment of the doubling claim. revision: partial
-
Referee: Abstract: The secondary claim that matching MLP performance requires scaling to the total MoE parameter count and yields a '14.3% increase in computation time' lacks specification of the measurement protocol (hardware platform, batch size, whether gating overhead is included) and whether the scaled MLP preserves the same active-parameter regime as the MoE policy.
Authors: We agree that the timing protocol must be stated for reproducibility. The measurements were obtained on the robot's onboard NVIDIA Jetson platform using single-sample (batch-size-1) inference to match real-time control conditions; the reported time for the MoE includes gating overhead, while the scaled MLP uses its full parameter set with all parameters active. We have added these protocol details to the abstract and cross-referenced the expanded description already present in the experiments section. revision: yes
Circularity Check
No circularity; empirical hardware comparison with no reductive equations
full rationale
The paper reports direct experimental results from training and deploying MoE versus MLP policies on a physical Unitree Go2 robot, measuring success rates over large obstacles. No derivation chain, first-principles equations, or predictions are presented that reduce reported outcomes to quantities defined by the paper's own fitted parameters or self-citations. The abstract and described results rely on empirical trials under stated controls (matched active parameters, visual input), with no mathematical steps that collapse by construction. This matches the default expectation of non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard reinforcement-learning assumptions for policy optimization from visual observations hold for both architectures.
Reference graph
Works this paper leans on
-
[1]
Anymal parkour: Learning agile navigation for quadrupedal robots,
D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,”Science Robotics, vol. 9, no. 88, p. eadi7566, 2024
2024
-
[2]
Extreme parkour with legged robots,
X. Cheng, K. Shi, A. Agarwal, and D. Pathak, “Extreme parkour with legged robots,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 443–11 450
2024
-
[3]
Z. Zhuang, Z. Fu, J. Wang, C. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao, “Robot parkour learning,”arXiv preprint arXiv:2309.05665, 2023
-
[4]
Learning coor- dinated badminton skills for legged manipulators,
Y . Ma, A. Cramariuc, F. Farshidian, and M. Hutter, “Learning coor- dinated badminton skills for legged manipulators,”Science robotics, vol. 10, no. 102, p. eadu3922, 2025
2025
-
[5]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[6]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “Gshard: Scaling giant models with conditional computation and automatic sharding,”arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review arXiv 2006
-
[7]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand,et al., “Mixtral of experts,”arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Moe-loco: Mixture of experts for multitask locomotion,
R. Huang, S. Zhu, Y . Du, and H. Zhao, “Moe-loco: Mixture of experts for multitask locomotion,”arXiv preprint arXiv:2503.08564, 2025
-
[9]
Experiments in balance with a 3d one-legged hopping machine,
M. H. Raibert, H. B. Brown Jr, and M. Chepponis, “Experiments in balance with a 3d one-legged hopping machine,”The International Journal of Robotics Research, vol. 3, no. 2, pp. 75–92, 1984
1984
-
[10]
Mit cheetah 3: Design and control of a robust, dynamic quadruped robot,
G. Bledt, M. J. Powell, B. Katz, J. Di Carlo, P. M. Wensing, and S. Kim, “Mit cheetah 3: Design and control of a robust, dynamic quadruped robot,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 2245–2252
2018
-
[11]
Anymal- a highly mobile and dynamic quadrupedal robot,
M. Hutter, C. Gehring, D. Jud, A. Lauber, C. D. Bellicoso, V . Tsounis, J. Hwangbo, K. Bodie, P. Fankhauser, M. Bloesch,et al., “Anymal- a highly mobile and dynamic quadrupedal robot,” in2016 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2016, pp. 38–44
2016
-
[12]
Mini cheetah: A platform for pushing the limits of dynamic quadruped control,
B. Katz, J. Di Carlo, and S. Kim, “Mini cheetah: A platform for pushing the limits of dynamic quadruped control,” in2019 international conference on robotics and automation (ICRA). IEEE, 2019, pp. 6295– 6301
2019
-
[13]
Highly dynamic quadruped locomotion via whole-body impulse control and model predictive control
D. Kim, J. Di Carlo, B. Katz, G. Bledt, and S. Kim, “Highly dynamic quadruped locomotion via whole-body impulse control and model predictive control,”arXiv preprint arXiv:1909.06586, 2019
-
[14]
Feedback- mppi: fast sampling-based mpc via rollout differentiation–adios low- level controllers,
T. Belvedere, M. Ziegltrum, G. Turrisi, and V . Modugno, “Feedback- mppi: fast sampling-based mpc via rollout differentiation–adios low- level controllers,”IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 1–8, 2025
2025
-
[15]
Rolling in the deep–hybrid locomotion for wheeled-legged robots using online trajectory optimization,
M. Bjelonic, P. K. Sankar, C. D. Bellicoso, H. Vallery, and M. Hutter, “Rolling in the deep–hybrid locomotion for wheeled-legged robots using online trajectory optimization,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3626–3633, 2020
2020
-
[16]
Perceptive locomotion through whole-body mpc and optimal region selection,
T. Corb `eres, C. Mastalli, W. Merkt, J. Shim, I. Havoutis, M. Fallon, N. Mansard, T. Flayols, S. Vijayakumar, and S. Tonneau, “Perceptive locomotion through whole-body mpc and optimal region selection,” IEEE Access, vol. 13, pp. 69 062–69 080, 2025
2025
-
[17]
Terrain mapping for a roving planetary explorer,
I.-S. Kweon, M. Hebert, E. Krotkov, and T. Kanade, “Terrain mapping for a roving planetary explorer,” inIEEE International Conference on Robotics and Automation. IEEE, 1989, pp. 997–1002
1989
-
[18]
Robust rough-terrain locomotion with a quadrupedal robot,
P. Fankhauser, M. Bjelonic, C. D. Bellicoso, T. Miki, and M. Hutter, “Robust rough-terrain locomotion with a quadrupedal robot,” in2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 5761–5768
2018
-
[19]
Vision aided dynamic exploration of unstructured terrain with a small-scale quadruped robot,
D. Kim, D. Carballo, J. Di Carlo, B. Katz, G. Bledt, B. Lim, and S. Kim, “Vision aided dynamic exploration of unstructured terrain with a small-scale quadruped robot,” in2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 2464–2470
2020
-
[20]
Advanced skills by learning locomotion and local navigation end-to-end,
N. Rudin, D. Hoeller, M. Bjelonic, and M. Hutter, “Advanced skills by learning locomotion and local navigation end-to-end,” 2022. [Online]. Available: https://arxiv.org/abs/2209.12827
-
[21]
Legged locomotion in challenging terrains using egocentric vision,
A. Agarwal, A. Kumar, J. Malik, and D. Pathak, “Legged locomotion in challenging terrains using egocentric vision,” inConference on robot learning. PMLR, 2023, pp. 403–415
2023
-
[22]
N. Rudin, J. He, J. Aurand, and M. Hutter, “Parkour in the wild: Learning a general and extensible agile locomotion policy using multi-expert distillation and rl fine-tuning,”arXiv preprint arXiv:2505.11164, 2025
-
[23]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural Computation, vol. 3, no. 1, pp. 79–87, 1991
1991
-
[24]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Llama-moe: Building mixture-of-experts from llama with continual pre-training,
T. Zhu, X. Qu, D. Dong, J. Ruan, J. Tong, C. He, and Y . Cheng, “Llama-moe: Building mixture-of-experts from llama with continual pre-training,” inProceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 15 913–15 923
2024
-
[26]
Glam: Efficient scaling of language models with mixture-of-experts,
N. Du, Y . Huang, A. M. Dai, S. Tong, D. Lepikhin, Y . Xu, M. Krikun, Y . Zhou, A. W. Yu, O. Firat,et al., “Glam: Efficient scaling of language models with mixture-of-experts,” inInternational conference on machine learning. PMLR, 2022, pp. 5547–5569
2022
-
[27]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa,et al., “Isaac gym: High performance gpu-based physics simulation for robot learning,”arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review arXiv 2021
-
[28]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
2022
-
[29]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,”Science robotics, vol. 7, no. 62, p. eabk2822, 2022
2022
-
[31]
Learning by cheating,
D. Chen, B. Zhou, V . Koltun, and P. Kr¨ahenb¨uhl, “Learning by cheating,” inConference on robot learning. PMLR, 2020, pp. 66–75
2020
-
[32]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,”arXiv preprint arXiv:1412.3555, 2014
work page internal anchor Pith review arXiv 2014
-
[33]
Rma: Rapid motor adaptation for legged robots,
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,”arXiv preprint arXiv:2107.04034, 2021
-
[34]
Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
D.-A. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and accurate deep network learning by exponential linear units (elus),”arXiv preprint arXiv:1511.07289, vol. 4, no. 5, p. 11, 2015
work page Pith review arXiv 2015
-
[35]
K. Cho and Y . Bengio, “Exponentially increasing the capacity-to- computation ratio for conditional computation in deep learning,”arXiv preprint arXiv:1406.7362, 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.