Recognition: 2 theorem links
· Lean TheoremCalibrating Scientific Foundation Models with Inference-Time Stochastic Attention
Pith reviewed 2026-05-12 03:58 UTC · model grok-4.3
The pith
Stochastic Attention replaces softmax weights with normalized multinomial samples to generate calibrated predictive ensembles in transformers at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
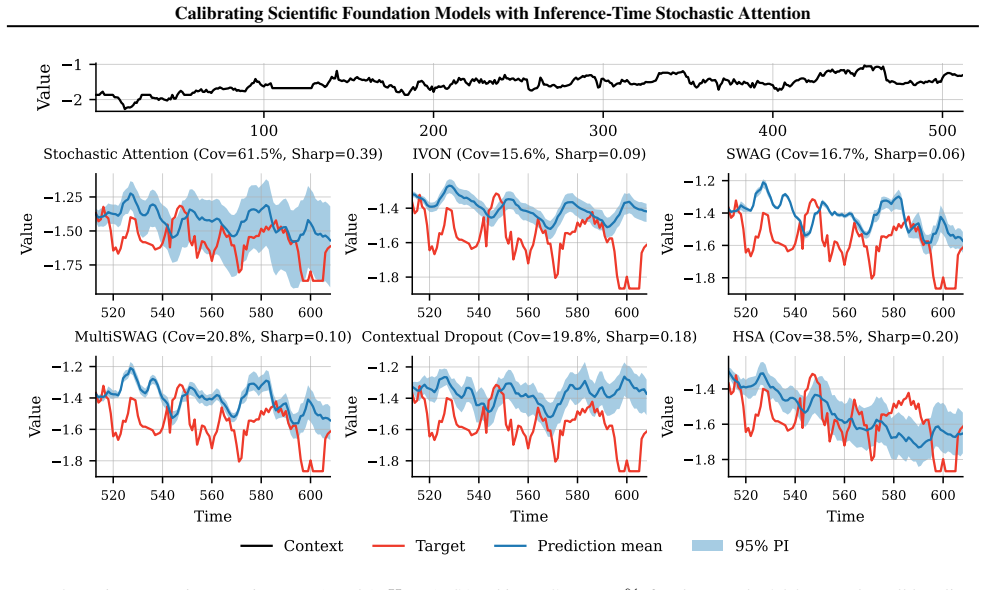
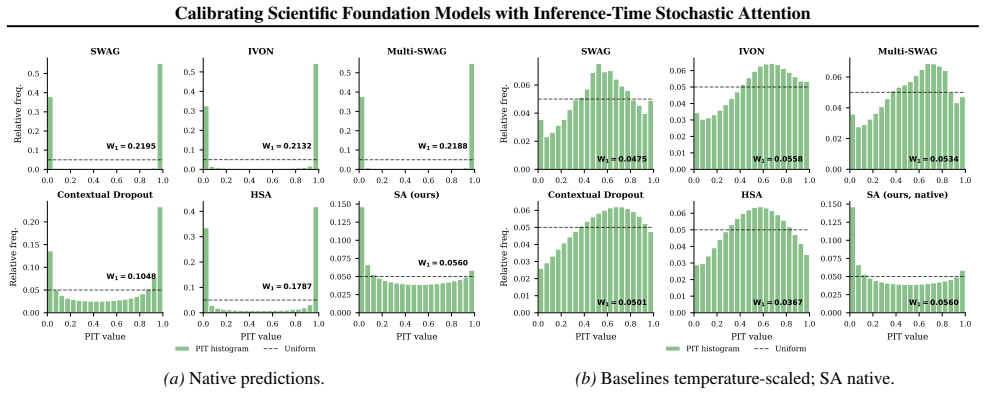
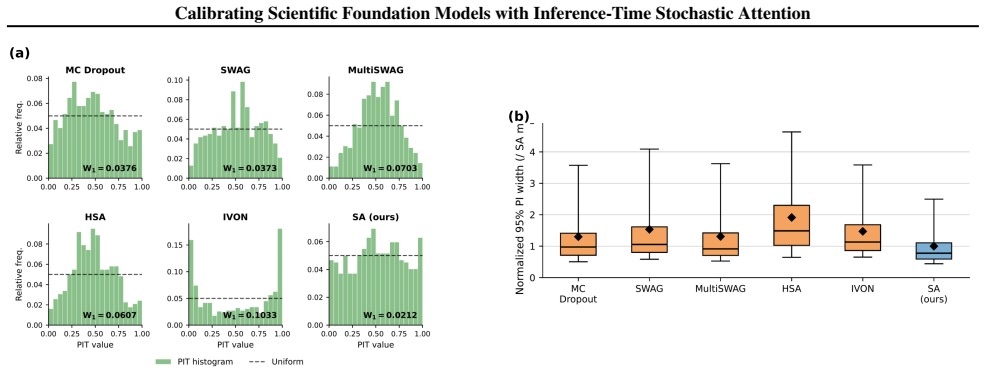
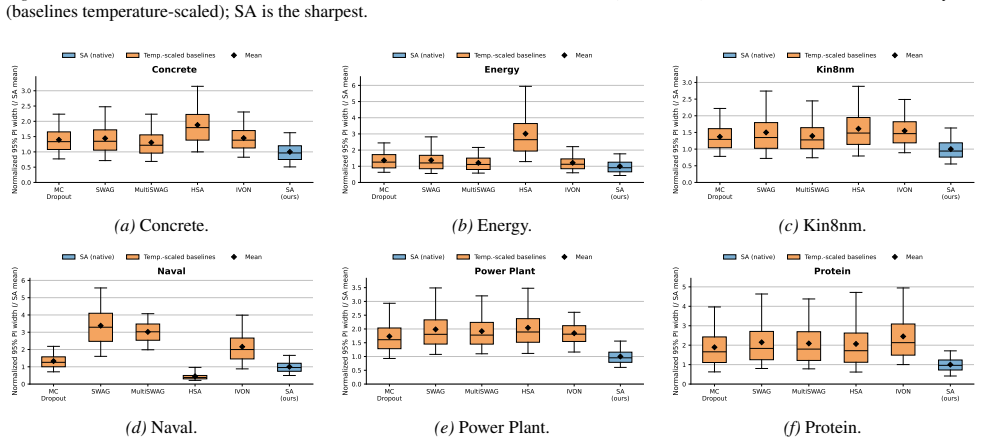
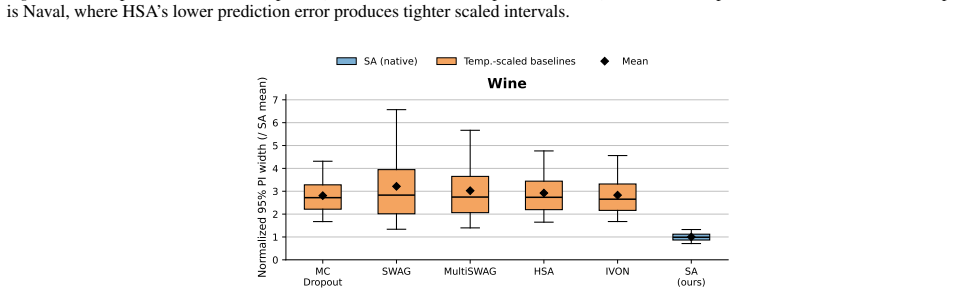
Replacing softmax attention weights with normalized multinomial samples controlled by a concentration parameter, then tuning that parameter through a post-hoc calibration objective, produces predictive ensembles whose uncertainty aligns closely with targets, delivering the strongest native calibration and sharpest intervals among tested approaches at adaptation costs nearly three orders of magnitude lower than the next-best baseline.
What carries the argument
Stochastic Attention: an inference-time randomization of the attention mechanism that substitutes normalized multinomial samples for softmax weights, governed by one concentration parameter whose value is set by matching ensemble outputs to calibration targets.
Load-bearing premise
The uncertainty produced by these single-pass stochastic attention ensembles can be aligned to desired targets through univariate post-hoc calibration of the concentration parameter without harming the model's core predictive accuracy.
What would settle it
On a held-out scientific forecasting benchmark, Sample Average Stochastic Attention yields higher calibration error or wider intervals than a strong uncertainty-aware baseline while the tuned concentration degrades mean squared error relative to the deterministic model.
Figures









read the original abstract
Transformer-based scientific foundation models are increasingly deployed in high-stakes settings, but current architectures give deterministic outputs and provide limited support for calibrated predictive uncertainty. We propose Stochastic Attention, a sample average lightweight inference-time modification that randomizes attention by replacing softmax weights with normalized multinomial samples controlled by a single concentration parameter, and produces predictive ensembles without retraining. To set this parameter, we introduce a calibration objective that matches the stochastic attention output with the target, yielding an efficient univariate post-hoc tuning problem. We evaluate this mechanism on scientific foundation models for weather and time-series forecasting, as well as several regression tasks. Across benchmarks against uncertainty-aware baselines, we find that Sample Average Stochastic Attention achieves the strongest native calibration and the sharpest prediction intervals at comparable calibration, with adaptation costs nearly three orders of magnitude lower than the next-best baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Stochastic Attention, a lightweight inference-time modification for transformer-based scientific foundation models. It replaces softmax attention weights with normalized multinomial samples controlled by a single concentration parameter to generate predictive ensembles without retraining. A univariate post-hoc calibration tunes this parameter to match stochastic outputs to targets. On benchmarks for weather and time-series forecasting plus regression tasks, Sample Average Stochastic Attention is reported to achieve the strongest native calibration and sharpest prediction intervals at comparable calibration, with adaptation costs nearly three orders of magnitude lower than baselines.
Significance. If the claims hold after addressing the noted concerns, the approach would provide an efficient, low-cost method for adding calibrated uncertainty to existing large scientific foundation models without retraining, which could be impactful for high-stakes applications such as weather prediction.
major comments (2)
- [Abstract and methods description of Stochastic Attention] Abstract and Stochastic Attention mechanism: although sampled attention weights have the same expectation as the original softmax weights, the non-linear transformer blocks (FFN layers, activations, residual additions) that follow attention imply that the expected output of the full stochastic forward pass need not equal the deterministic output. This can bias the ensemble mean relative to the original model's point predictions and potentially degrade core performance metrics even before calibration. The manuscript provides no explicit comparison of deterministic vs. ensemble-mean predictions or correction for this effect on the reported benchmarks.
- [Experimental results section] Experimental evaluation: the abstract claims superior calibration and interval sharpness but the provided details lack full methods, benchmark specifications, statistical validation (e.g., error bars or significance tests), and verification that the univariate post-hoc tuning preserves predictive accuracy. These are load-bearing for the central claim of outperforming uncertainty-aware baselines without degradation.
minor comments (1)
- [Abstract] Clarify the precise definition and distinction of 'Sample Average Stochastic Attention' relative to the general Stochastic Attention proposal, as the term appears only in the results claim.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and methods description of Stochastic Attention] Abstract and Stochastic Attention mechanism: although sampled attention weights have the same expectation as the original softmax weights, the non-linear transformer blocks (FFN layers, activations, residual additions) that follow attention imply that the expected output of the full stochastic forward pass need not equal the deterministic output. This can bias the ensemble mean relative to the original model's point predictions and potentially degrade core performance metrics even before calibration. The manuscript provides no explicit comparison of deterministic vs. ensemble-mean predictions or correction for this effect on the reported benchmarks.
Authors: We agree that the non-linearities following the attention layer mean the ensemble mean need not equal the deterministic output, and the current manuscript does not provide an explicit comparison. In the revised version we will add this analysis to the experimental results section, reporting the relative difference between deterministic predictions and sample-average ensemble means on every benchmark. This will quantify any bias and its effect on core metrics prior to calibration. revision: yes
-
Referee: [Experimental results section] Experimental evaluation: the abstract claims superior calibration and interval sharpness but the provided details lack full methods, benchmark specifications, statistical validation (e.g., error bars or significance tests), and verification that the univariate post-hoc tuning preserves predictive accuracy. These are load-bearing for the central claim of outperforming uncertainty-aware baselines without degradation.
Authors: We accept that the experimental section requires greater detail to substantiate the claims. The revised manuscript will expand the methods with complete benchmark specifications (datasets, sizes, preprocessing, and evaluation protocols). We will add error bars from repeated runs, statistical significance tests against baselines, and explicit tables comparing predictive accuracy (e.g., RMSE/MAE) of the original deterministic model, the uncalibrated stochastic ensembles, and the post-hoc calibrated version to confirm that tuning does not degrade core performance. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes Stochastic Attention as an inference-time modification replacing softmax with normalized multinomial samples controlled by one concentration parameter, then introduces an explicit post-hoc calibration objective to tune that parameter by matching outputs to targets. Claims rest on empirical benchmark comparisons against baselines rather than any first-principles derivation or mathematical reduction. No equations, uniqueness theorems, or self-citations appear in the provided text that would create a self-definitional loop or force a result by construction. The mechanism is defined independently before the univariate tuning step, and performance metrics are reported after evaluation, not as tautological outputs of the fit itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- concentration parameter
axioms (1)
- domain assumption Replacing softmax attention weights with normalized multinomial samples produces valid attention distributions that yield meaningful predictive ensembles
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Stochastic attention replaces that exact expectation by a finite-sample approximation drawn from the same categorical distribution... indexed by a concentration parameter ν... calibration objective that matches the stochastic attention output with the target, yielding an efficient univariate post-hoc tuning problem.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
E[eπt | πt] = πt, E[eot | πt, V] = ot... Cov(eπt | πt) = (1/ν)(diag(πt) − πt πt⊺)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cong, B., Daheim, N., Shen, Y., Cremers, D., Yokota, R., Khan, M. E., and M \"o llenhoff, T. Variational low-rank adaptation using IVON . In NeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability, 2024. URL https://openreview.net/forum?id=nRD5uZa2fe
work page 2024
-
[2]
A decoder-only foundation model for time-series forecasting
Das, A., Kong, W., Sen, R., and Zhou, Y. A decoder-only foundation model for time-series forecasting. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=jn2iTJas6h
work page 2024
-
[3]
Dawid, A. P. Present position and potential developments: Some personal views statistical theory the prequential approach. Journal of the Royal Statistical Society: Series A (General), 147 0 (2): 0 278--290, 1984. doi:https://doi.org/10.2307/2981683. URL https://rss.onlinelibrary.wiley.com/doi/abs/10.2307/2981683
-
[4]
Contextual dropout: An efficient sample-dependent dropout module
Fan, X., Zhang, S., Tanwisuth, K., Qian, X., and Zhou, M. Contextual dropout: An efficient sample-dependent dropout module. In International Conference on Learning Representations, 2021 a . URL https://openreview.net/forum?id=ct8_a9h1M
work page 2021
-
[5]
Contextual dropout: An efficient sample-dependent dropout module
Fan, X., Zhang, S., Tanwisuth, K., Qian, X., and Zhou, M. Contextual dropout: An efficient sample-dependent dropout module. In International Conference on Learning Representations, 2021 b . URL https://openreview.net/forum?id=ct8_a9h1M
work page 2021
-
[6]
Gal, Y. and Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Balcan, M. F. and Weinberger, K. Q. (eds.), Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp.\ 1050--1059, New York, New York, USA, 20--22 Jun 2016. PMLR. URL htt...
work page 2016
-
[7]
Verifying probabilistic forecasts: Calibration and sharpness
Gneiting, T., Balabdaoui, F., and Raftery, A. E. Probabilistic forecasts, calibration and sharpness. Journal of the Royal Statistical Society Series B: Statistical Methodology, 69 0 (2): 0 243--268, 03 2007. ISSN 1369-7412. doi:10.1111/j.1467-9868.2007.00587.x. URL https://doi.org/10.1111/j.1467-9868.2007.00587.x. Originally presented at Workshop on Ensem...
-
[8]
Gruber, S. and Buettner, F. Better uncertainty calibration via proper scores for classification and beyond. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp.\ 8618--8632. Curran Associates, Inc., 2022
work page 2022
-
[9]
Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. On calibration of modern neural networks. In Precup, D. and Teh, Y. W. (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp.\ 1321--1330. PMLR, 06--11 Aug 2017. URL https://proceedings.mlr.press/v70/guo17a.html
work page 2017
-
[10]
Heo, J., Lee, H. B., Kim, S., Lee, J., Kim, K. J., Yang, E., and Hwang, S. J. Uncertainty-aware attention for reliable interpretation and prediction. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://pro...
work page 2018
-
[11]
J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W
Hu, E. J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lo RA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[12]
Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D. P., and Wilson, A. G. Averaging weights leads to wider optima and better generalization. In Globerson, A. and Silva, R. (eds.), Proceedings of the Thirty-Fourth Conference on Uncertainty in Artificial Intelligence, pp.\ 876--885, Monterey, California, USA, August 2018. AUAI Press
work page 2018
-
[13]
Kuleshov, V. and Deshpande, S. Calibrated and sharp uncertainties in deep learning via density estimation. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (eds.), Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pp.\ 11683--11693. PMLR, 17--23 Jul...
work page 2022
-
[14]
Accurate uncertainties for deep learning using calibrated regression
Kuleshov, V., Fenner, N., and Ermon, S. Accurate uncertainties for deep learning using calibrated regression. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ 2796--2804. PMLR, 10--15 Jul 2018. URL https://proceedings.mlr.press/v80/kuleshov18a.html
work page 2018
-
[15]
Simple and scalable predictive uncertainty estimation using deep ensembles
Lakshminarayanan, B., Pritzel, A., and Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neu...
work page 2017
-
[16]
J., Izmailov, P., Garipov, T., Vetrov, D
Maddox, W. J., Izmailov, P., Garipov, T., Vetrov, D. P., and Wilson, A. G. A simple baseline for B ayesian uncertainty in deep learning. In Advances in Neural Information Processing Systems, volume 32, pp.\ 13153--13164. Curran Associates, Inc., 2019
work page 2019
-
[17]
Nguyen, T., Brandstetter, J., Kapoor, A., Gupta, J. K., and Grover, A. Climax: A foundation model for weather and climate. In ICML, pp.\ 25904--25938, 2023
work page 2023
-
[18]
Gaussian stochastic weight averaging for bayesian low-rank adaptation of large language models
Onal, E., Fl \"o ge, K., Caldwell, E., Sheverdin, A., and Fortuin, V. Gaussian stochastic weight averaging for bayesian low-rank adaptation of large language models. In Sixth Symposium on Advances in Approximate Bayesian Inference - Non Archival Track, 2024. URL https://openreview.net/forum?id=LZrCBQBCzl
work page 2024
-
[19]
M., Hubin, A., Immer, A., Karaletsos, T., Khan, M
Papamarkou, T., Skoularidou, M., Palla, K., Aitchison, L., Arbel, J., Dunson, D., Filippone, M., Fortuin, V., Hennig, P., Hern\' a ndez-Lobato, J. M., Hubin, A., Immer, A., Karaletsos, T., Khan, M. E., Kristiadi, A., Li, Y., Mandt, S., Nemeth, C., Osborne, M. A., Rudner, T. G. J., R\" u gamer, D., Teh, Y. W., Welling, M., Wilson, A. G., and Zhang, R. Posi...
work page 2024
-
[20]
Transformer uncertainty estimation with hierarchical stochastic attention
Pei, J., Wang, C., and Szarvas, G. Transformer uncertainty estimation with hierarchical stochastic attention. Proceedings of the AAAI Conference on Artificial Intelligence, 36 0 (10): 0 11147--11155, Jun. 2022. doi:10.1609/aaai.v36i10.21364. URL https://ojs.aaai.org/index.php/AAAI/article/view/21364
-
[21]
Shen, Y., Daheim, N., Cong, B., Nickl, P., Marconi, G. M., Raoul, B. C. E. M., Yokota, R., Gurevych, I., Cremers, D., Khan, M. E., and M\" o llenhoff, T. Variational learning is effective for large deep networks. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pp.\ 44665--446...
work page 2024
-
[22]
Algorithmic Learning in a Random World
Vovk, V., Gammerman, A., and Shafer, G. Algorithmic Learning in a Random World. Springer, Cham, first edition edition, 2005. ISBN 9783031066481. URL https://link.springer.com/book/10.1007/978-3-031-06649-8. First edition, 2005
-
[23]
Wilson, A. G. and Izmailov, P. Bayesian deep learning and a probabilistic perspective of generalization. In Advances in Neural Information Processing Systems, volume 33, pp.\ 4697--4708. Curran Associates, Inc., 2020
work page 2020
-
[24]
Show, attend and tell: Neural image caption generation with visual attention
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., and Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Bach, F. and Blei, D. (eds.), Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pp.\ 2048--2057, Lille, Fr...
work page 2048
-
[25]
Yadav, A. and Zhang, R. Bayesian optimization under uncertainty for training a scale parameter in stochastic models, 2025
work page 2025
-
[26]
F., Yilmaz, E., Shi, S., and Tu, Z
Ye, F., Yang, M., Pang, J., Wang, L., Wong, D. F., Yilmaz, E., Shi, S., and Tu, Z. Benchmarking llms via uncertainty quantification. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 15356--15385. Curran Associates, Inc., 2024. doi:10.52202...
-
[27]
maintain its level of performance under any circumstances
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., and Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. Proceedings of the AAAI Conference on Artificial Intelligence, 35 0 (12): 0 11106--11115, May 2021. doi:10.1609/aaai.v35i12.17325. URL https://ojs.aaai.org/index.php/AAAI/article/view/17325
-
[28]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.