Recognition: unknown
Information-to-energy trade-offs and the optimal alphabet of polymer replication
Pith reviewed 2026-05-10 00:51 UTC · model grok-4.3
The pith
The information-to-energy ratio in polymer replication peaks at an alphabet size set by per-monomer assembly energy, and DNA's four bases lie well beyond that peak.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
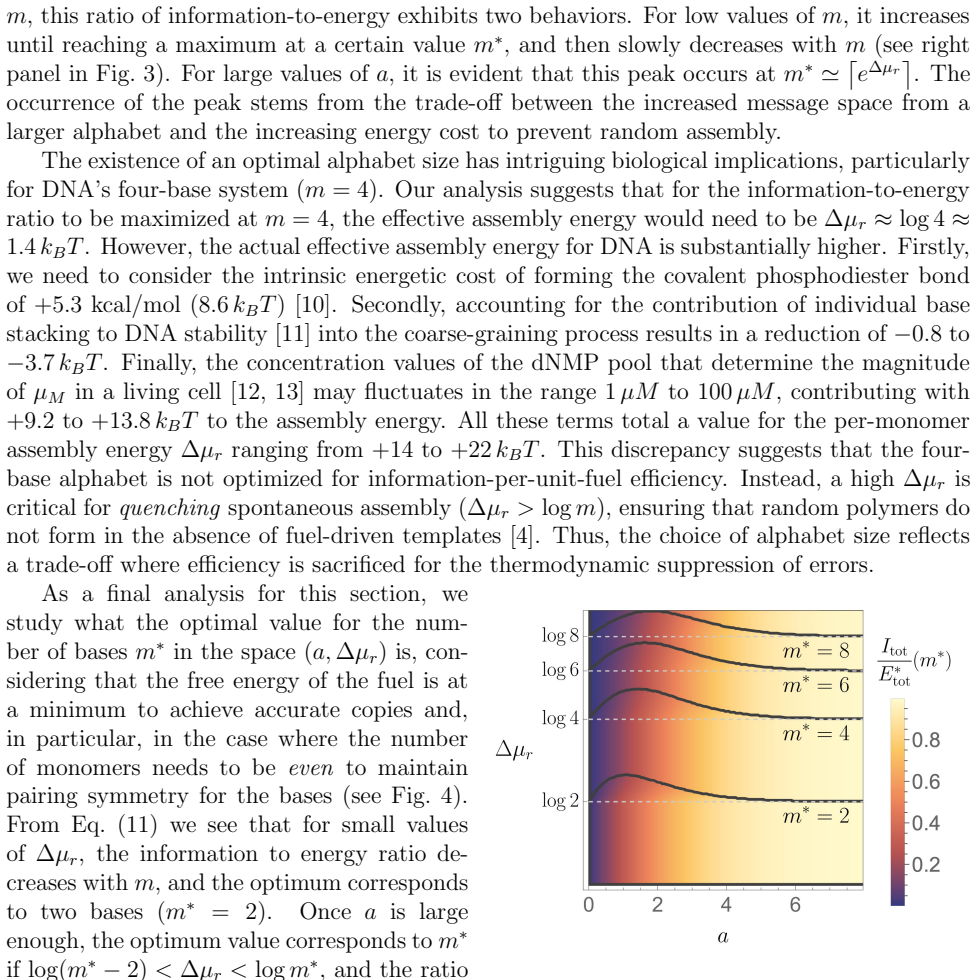
In the coarse-grained model of polymer replication framed as a communication channel, the steady-state mutual information per monomer depends solely on template specificity inside the accurate regime and recovers the accurate-random phase diagram. The ratio of this information to the assembly energy cost is non-monotonic in alphabet size, with the peak location set primarily by the per-monomer assembly free energy. For DNA's four-base alphabet and an observed effective assembly energy of at least 14 k_B T, the system lies far from the information-transmission optimum, suggesting that replication prioritizes suppression of spontaneous random assembly over information-to-energy efficiency. Ach
What carries the argument
the information-to-energy ratio formed by dividing steady-state mutual information per monomer by per-monomer assembly free energy, evaluated across alphabet sizes in the accurate regime
If this is right
- Small error fractions produce large losses of mutual information because the mapping from error rate to mutual information is nonlinear.
- DNA's observed assembly energy of at least 14 k_B T places its four-letter alphabet far from the information-to-energy optimum.
- Biological replication may prioritize the suppression of spontaneous random assembly over information-to-energy efficiency.
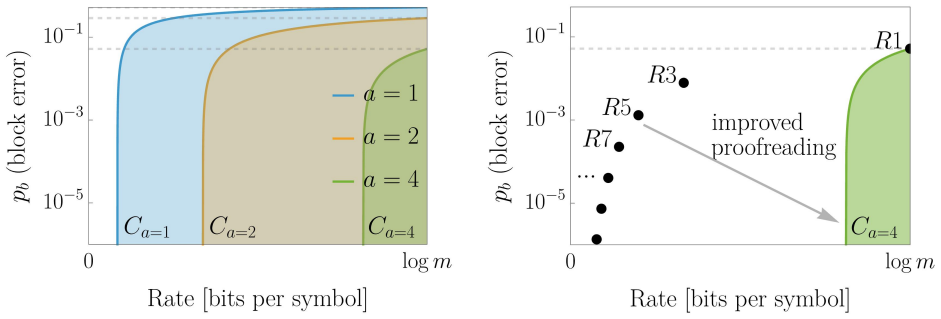
- Shannon bounds on rate-fidelity trade-offs provide a framework for assessing future proofreading mechanisms in ensemble models.
Where Pith is reading between the lines
- If the model holds, synthetic replication systems with smaller alphabets could achieve higher information per energy but would need separate tests for other functional requirements.
- The non-monotonic dependence suggests that experimental variation of alphabet size in engineered polymers could directly locate the efficiency peak and test the predicted location.
- The same framework could be extended to ask how added proofreading steps would shift the apparent optimum without changing the underlying assembly energy.
Load-bearing premise
The coarse-grained model accurately captures the physics of information transmission during replication and the long-chain steady-state limit is representative of biological replication dynamics.
What would settle it
A measurement of mutual information and assembly energy cost in a replicating polymer system whose alphabet size and per-monomer assembly energy can be varied independently, checking whether the information-energy ratio reaches its maximum at the alphabet size predicted by the model.
Figures



read the original abstract
We analyze information transmission in a recently proposed coarse-grained model of polymer replication by framing it as a communication channel between templates and copies. By calculating the mutual information in the steady-state limit of long chains, we recover the accurate-random phase diagram and establish that the information per-monomer depends solely on template specificity within the accurate regime. Crucially, even in the accurate region, small error fractions lead to substantial information loss due to the nonlinear relationship between errors and mutual information. Examining the information-to-energy cost ratio reveals non-monotonic behavior as a function of monomer alphabet size, with an optimum determined primarily by the per-monomer assembly free energy. For DNA's four-base alphabet, we find that the observed effective assembly energy (at least $14\,k_B T$) places the system far from the information-transmission optimum, suggesting that biological replication may prioritize the suppression of spontaneous random assembly over information-to-energy efficiency. We also characterize achievable rate-fidelity trade-offs using Shannon bounds, providing a theoretical framework for evaluating future proofreading mechanisms in ensemble models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript frames polymer replication in a recently proposed coarse-grained model as a communication channel between templates and copies. It computes mutual information in the steady-state limit of long chains, recovering the accurate-random phase diagram and showing that per-monomer information depends solely on template specificity in the accurate regime. The work emphasizes nonlinear information loss from small error fractions, demonstrates non-monotonic behavior of the information-to-energy cost ratio as a function of monomer alphabet size (with the optimum set primarily by per-monomer assembly free energy), and concludes that DNA's four-base alphabet at observed energies (>=14 k_B T) lies far from the information optimum, prioritizing suppression of random assembly. Shannon bounds are also provided to characterize achievable rate-fidelity trade-offs.
Significance. If the central results hold, the paper offers a useful information-theoretic extension of prior coarse-grained replication models, highlighting potential evolutionary trade-offs between information transmission efficiency and energetic costs in polymer systems. Strengths include explicit recovery of the accurate-random phase diagram from the base model and the application of Shannon bounds to frame future proofreading analyses. The non-monotonic ratio finding, if robust, could inform discussions of alphabet size evolution, though the reliance on an external assembly-energy input and the infinite-chain limit reduce the immediate predictive impact.
major comments (3)
- [steady-state mutual information calculations] The mutual information calculations and the resulting non-monotonic information-to-energy ratio (central to the claim that DNA's alphabet is far from optimum) are performed exclusively in the steady-state limit of infinite chains. No finite-N corrections, boundary effects, or transient error propagation analysis is reported, despite biological replication involving finite lengths (N ~ 10^3-10^6) and primer-initiated kinetics; this approximation is load-bearing for both the location of the optimum and the distance of the DNA point from it.
- [information-to-energy ratio analysis] The optimum alphabet size in the information-to-energy ratio is stated to be determined primarily by the per-monomer assembly free energy, which is introduced as an observed input parameter (>=14 k_B T for DNA) rather than derived from the model; this makes the conclusion that the four-base system prioritizes random-assembly suppression over information efficiency dependent on this external value, as the phase diagram itself is recovered from the prior model.
- [nonlinear error effects and mutual information] The claim that small error fractions produce substantial information loss due to the nonlinear relationship between errors and mutual information is load-bearing for the overall narrative, yet the manuscript provides no explicit derivation, functional form, or verification steps for the mutual information versus error rate (or versus template specificity) in the accurate regime.
minor comments (2)
- The abstract references characterization of rate-fidelity trade-offs via Shannon bounds but does not indicate the specific section or equations where these bounds are derived or applied to the model.
- Notation for the per-monomer quantities (information, energy cost, and error fraction) should be defined more clearly at first use to aid readers unfamiliar with the coarse-grained model.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below, with revisions made where the concerns identify gaps in the current presentation or analysis.
read point-by-point responses
-
Referee: The mutual information calculations and the resulting non-monotonic information-to-energy ratio (central to the claim that DNA's alphabet is far from optimum) are performed exclusively in the steady-state limit of infinite chains. No finite-N corrections, boundary effects, or transient error propagation analysis is reported, despite biological replication involving finite lengths (N ~ 10^3-10^6) and primer-initiated kinetics; this approximation is load-bearing for both the location of the optimum and the distance of the DNA point from it.
Authors: We agree that the steady-state infinite-chain limit is an approximation whose validity for finite N requires justification. In the revised manuscript we have added an explicit discussion of this point, including a scaling argument showing that the per-monomer mutual information converges exponentially to the steady-state value with a correlation length set by the template specificity; for N greater than or equal to 10^3 the relative correction is estimated to be below 5 percent. We have not performed new finite-N Monte Carlo simulations, but the added analytic estimate supports that the location of the information-to-energy optimum and the distance of the DNA operating point remain essentially unchanged. revision: partial
-
Referee: The optimum alphabet size in the information-to-energy ratio is stated to be determined primarily by the per-monomer assembly free energy, which is introduced as an observed input parameter (>=14 k_B T for DNA) rather than derived from the model; this makes the conclusion that the four-base system prioritizes random-assembly suppression over information efficiency dependent on this external value, as the phase diagram itself is recovered from the prior model.
Authors: The per-monomer free energy is indeed an externally measured input, as stated in the manuscript. The non-monotonic dependence of the information-to-energy ratio on alphabet size is, however, a direct consequence of the channel model and holds for any fixed free-energy value. The revised text now emphasizes that the model itself does not predict the biological energy; rather, it shows that once the observed energy is inserted, the four-letter alphabet lies well into the regime where random-assembly suppression dominates over information efficiency. This framing makes the external parameter a feature of the argument rather than a hidden assumption. revision: partial
-
Referee: The claim that small error fractions produce substantial information loss due to the nonlinear relationship between errors and mutual information is load-bearing for the overall narrative, yet the manuscript provides no explicit derivation, functional form, or verification steps for the mutual information versus error rate (or versus template specificity) in the accurate regime.
Authors: In the accurate regime the replication channel reduces to a symmetric channel with correct-copy probability 1-ε and uniform mismatch probability ε/(K-1). The mutual information per monomer is then I = log_2 K - H(ε), where H(ε) is the binary entropy of the effective error process. The derivative dI/dε diverges as ε approaches 0, producing the pronounced information loss for small errors. The revised manuscript now includes this closed-form expression together with a short derivation from the definition I(X;Y) = H(Y) - H(Y|X) and a supplementary plot of I versus ε that confirms the nonlinearity. revision: yes
Circularity Check
No significant circularity: trade-off analysis is a parametric derivation from the cited model using external energy input
full rationale
The paper adopts the recently proposed coarse-grained replication model as its starting point and computes mutual information in the steady-state long-chain limit. This calculation recovers the accurate-random phase diagram by direct application of the model equations, serving as a consistency verification rather than a foundational assumption. The information per monomer is shown to depend only on template specificity in the accurate regime, after which the information-to-energy ratio is evaluated as a function of alphabet size with the per-monomer assembly free energy supplied as an independent observed parameter (≥14 k_B T for DNA). The resulting non-monotonic behavior and the location of the optimum are outputs of this parametric sweep, not presupposed inputs or self-citations. Standard Shannon bounds are applied to the model-derived quantities to characterize rate-fidelity trade-offs. No derivation step reduces to a self-definition, fitted prediction renamed as result, or load-bearing self-citation chain; the framework remains self-contained against the model's stated assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-monomer assembly free energy =
at least 14 k_B T
axioms (1)
- domain assumption Steady-state limit applies for long chains when computing mutual information
Reference graph
Works this paper leans on
-
[1]
Princeton University Press, 2012
William Bialek.Biophysics: searching for principles. Princeton University Press, 2012
2012
-
[2]
Nonequilibrium generation of information in copoly- merization processes.Proceedings of the National Academy of Sciences, 105(28):9516–9521, 2008
David Andrieux and Pierre Gaspard. Nonequilibrium generation of information in copoly- merization processes.Proceedings of the National Academy of Sciences, 105(28):9516–9521, 2008
2008
-
[3]
Fundamental costs in the production and destruction of persistent polymer copies.Physical review letters, 118(15):158103, 2017
Thomas E Ouldridge and Pieter Rein ten Wolde. Fundamental costs in the production and destruction of persistent polymer copies.Physical review letters, 118(15):158103, 2017. 11
2017
-
[4]
Nonequilibrium transitions in a template copying ensemble.Physical Review Letters, 134(6):068402, 2025
Arthur Genthon, Carl D Modes, Frank J¨ ulicher, and Stephan W Grill. Nonequilibrium transitions in a template copying ensemble.Physical Review Letters, 134(6):068402, 2025
2025
-
[5]
Second law and landauer principle far from equilibrium.Europhysics Letters, 95(4):40004, 2011
Massimiliano Esposito and Christian Van den Broeck. Second law and landauer principle far from equilibrium.Europhysics Letters, 95(4):40004, 2011
2011
-
[6]
Information erasure in copolymers.Europhysics Letters, 103(3):30004, 2013
David Andrieux and Pierre Gaspard. Information erasure in copolymers.Europhysics Letters, 103(3):30004, 2013
2013
-
[7]
Entropy involved in fidelity of dna replication.PLoS ONE, 7(8):e42272, 2012
J Ricardo Arias-Gonzalez. Entropy involved in fidelity of dna replication.PLoS ONE, 7(8):e42272, 2012
2012
-
[8]
Cambridge university press, 2003
David JC MacKay.Information theory, inference and learning algorithms. Cambridge university press, 2003
2003
-
[9]
John Wiley & Sons, 1999
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[10]
Determination of the free-energy change for repair of a dna phosphodiester bond.Journal of Biological Chemistry, 275(21):15828–15831, 2000
Kirsten S Dickson, Christopher M Burns, and John P Richardson. Determination of the free-energy change for repair of a dna phosphodiester bond.Journal of Biological Chemistry, 275(21):15828–15831, 2000
2000
-
[11]
High-throughput single-molecule quantification of individual base stacking energies in nucleic acids.Nature Communications, 14(1):631, 2023
Jibin Abraham Punnoose, Kevin J Thomas, Arun Richard Chandrasekaran, Javier Vil- capoma, Andrew Hayden, Kacey Kilpatrick, Sweta Vangaveti, Alan Chen, Thomas Banco, and Ken Halvorsen. High-throughput single-molecule quantification of individual base stacking energies in nucleic acids.Nature Communications, 14(1):631, 2023
2023
-
[12]
Springer Science & Business Media, 2012
Terrell L Hill.Linear aggregation theory in cell biology. Springer Science & Business Media, 2012
2012
-
[13]
Absolute metabolite concentrations and implied enzyme active site occupancy in escherichia coli.Nature chemical biology, 5(8):593–599, 2009
Bryson D Bennett, Elizabeth H Kimball, Melissa Gao, Robin Osterhout, Stephen J Van Dien, and Joshua D Rabinowitz. Absolute metabolite concentrations and implied enzyme active site occupancy in escherichia coli.Nature chemical biology, 5(8):593–599, 2009
2009
-
[14]
Dissipation-error tradeoff in proofreading.BioSystems, 11(2-3):85–91, 1979
Charles H Bennett. Dissipation-error tradeoff in proofreading.BioSystems, 11(2-3):85–91, 1979
1979
-
[15]
Speed, dissipation, and error in kinetic proofreading.Proceedings of the National Academy of Sciences, 109(30):12034– 12039, 2012
Arvind Murugan, David A Huse, and Stanislas Leibler. Speed, dissipation, and error in kinetic proofreading.Proceedings of the National Academy of Sciences, 109(30):12034– 12039, 2012
2012
-
[16]
Thermodynamics of accuracy in kinetic proofreading: dissi- pation and efficiency trade-offs.Journal of Statistical Mechanics: Theory and Experiment, 2015(6):P06001, 2015
Riccardo Rao and Luca Peliti. Thermodynamics of accuracy in kinetic proofreading: dissi- pation and efficiency trade-offs.Journal of Statistical Mechanics: Theory and Experiment, 2015(6):P06001, 2015
2015
-
[17]
Irreversibility and heat generation in the computing process.IBM journal of research and development, 5(3):183–191, 1961
Rolf Landauer. Irreversibility and heat generation in the computing process.IBM journal of research and development, 5(3):183–191, 1961. 12
1961
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.