Recognition: unknown
Detecting Hallucinations in SpeechLLMs at Inference Time Using Attention Maps
Pith reviewed 2026-05-10 01:52 UTC · model grok-4.3
The pith
Attention-derived metrics detect hallucinations in SpeechLLMs at inference time without gold labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
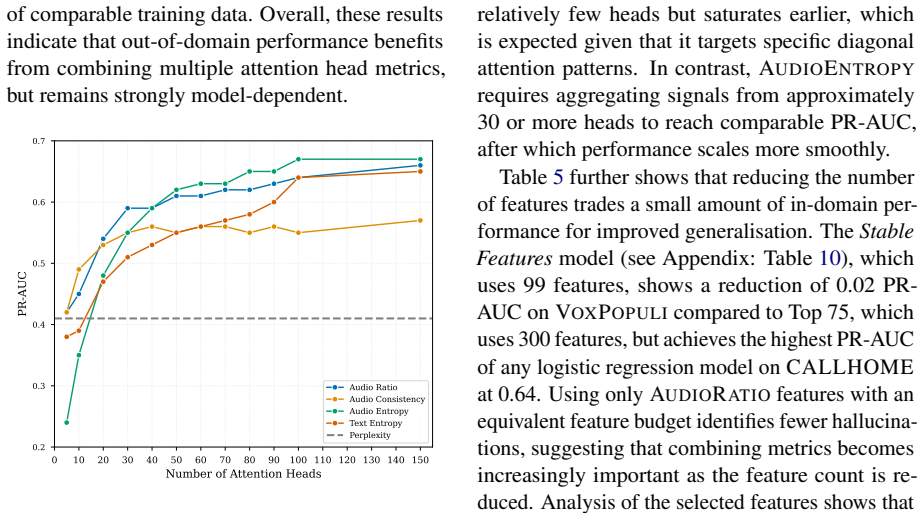
We investigate four attention-derived metrics: AUDIORATIO, AUDIOCONSISTENCY, AUDIOENTROPY, and TEXTENTROPY, designed to capture pathological attention patterns associated with hallucination, and train lightweight logistic regression classifiers on these features for efficient inference-time detection. Across automatic speech recognition and speech-to-text translation tasks, evaluations on Qwen-2-Audio and Voxtral-3B show that our approach outperforms uncertainty-based and prior attention-based baselines on in-domain data, achieving improvements of up to +0.23 PR-AUC, and generalises to out-of-domain ASR settings. We further find that strong performance can be achieved with approximately 100
What carries the argument
Four attention-derived metrics (AUDIORATIO, AUDIOCONSISTENCY, AUDIOENTROPY, TEXTENTROPY) that quantify pathological attention patterns between audio inputs and generated text to train a logistic regression detector.
If this is right
- Hallucination detection becomes possible at inference time using only internal attention data without gold-standard references.
- The method outperforms uncertainty-based and prior attention-based baselines by up to 0.23 PR-AUC on in-domain data.
- Detection generalizes to out-of-domain automatic speech recognition settings.
- Strong results hold when using only approximately 100 attention heads, which also improves out-of-domain generalization.
- Effectiveness remains model-dependent and requires task-specific training of the classifier.
Where Pith is reading between the lines
- The same attention-pattern approach might apply to hallucination detection in other multimodal large language models.
- Real-time speech applications could use this lightweight check to filter unreliable outputs before they reach users.
- Selecting informative subsets of attention heads could become a broader technique for improving generalization in model-internal detection tasks.
Load-bearing premise
The four attention-derived metrics reliably capture pathological patterns linked to hallucination and a logistic regression trained on them will generalize beyond the specific models and tasks used for training.
What would settle it
Evaluating the logistic regression trained on these four metrics from one SpeechLLM on hallucinations from a held-out different model or task and finding PR-AUC no better than uncertainty baselines would falsify the generalizability claim.
Figures


read the original abstract
Hallucinations in Speech Large Language Models (SpeechLLMs) pose significant risks, yet existing detection methods typically rely on gold-standard outputs that are costly or impractical to obtain. Moreover, hallucination detection methods developed for text-based LLMs do not directly capture audio-specific signals. We investigate four attention-derived metrics: AUDIORATIO, AUDIOCONSISTENCY, AUDIOENTROPY, and TEXTENTROPY, designed to capture pathological attention patterns associated with hallucination, and train lightweight logistic regression classifiers on these features for efficient inference-time detection. Across automatic speech recognition and speech-to-text translation tasks, evaluations on Qwen-2-Audio and Voxtral-3B show that our approach outperforms uncertainty-based and prior attention-based baselines on in-domain data, achieving improvements of up to +0.23 PR-AUC, and generalises to out-of-domain ASR settings. We further find that strong performance can be achieved with approximately 100 attention heads, improving out-of-domain generalisation compared to using all heads. While effectiveness is model-dependent and task-specific training is required, our results demonstrate that attention patterns provide a valuable tool for hallucination detection in SpeechLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes four attention-derived metrics (AUDIORATIO, AUDIOCONSISTENCY, AUDIOENTROPY, TEXTENTROPY) to capture pathological patterns in SpeechLLMs and trains lightweight logistic regression classifiers on them for inference-time hallucination detection. Evaluations on Qwen-2-Audio and Voxtral-3B for ASR and speech-to-text translation tasks claim up to +0.23 PR-AUC gains over uncertainty and prior attention baselines on in-domain data, plus generalization to out-of-domain ASR, with the additional finding that ~100 heads suffice and can improve OOD performance. The approach is noted to be model-dependent and to require task-specific training.
Significance. If the empirical claims are substantiated with full experimental details, this could provide a practical gold-standard-free method for detecting hallucinations in SpeechLLMs by leveraging audio-specific attention signals, addressing a limitation of text-LLM detection techniques. The observation that a small subset of heads yields better OOD generalization is a potentially useful insight for efficient deployment.
major comments (3)
- [Abstract] Abstract: The abstract reports concrete PR-AUC gains of up to +0.23 and OOD generalization, yet supplies no experimental details on data splits, sample sizes, statistical significance tests, ablation results for the four metrics, or how hallucination labels were obtained for LR training. These omissions make the central performance claims impossible to evaluate for reliability or reproducibility.
- [Abstract] Abstract: The metrics are described as capturing 'pathological attention patterns associated with hallucination', but the manuscript provides no direct evidence (e.g., distributions, visualizations, or correlation analysis) showing reliable, non-spurious differences between hallucinated and non-hallucinated generations. Because the logistic regression coefficients are fitted on labeled data, the reported gains may reflect model- or task-specific attention biases rather than general hallucination signals.
- [Abstract] Abstract: The OOD ASR generalization claim and the ~100-head finding require more specification, including the exact OOD datasets, whether head selection was performed on in-domain data only, and quantitative comparison of full-head vs. subset performance across models. The statement that 'effectiveness is model-dependent and task-specific training is required' indicates the generalization scope may be narrower than presented.
minor comments (1)
- [Abstract] Abstract: The four metric names (AUDIORATIO, etc.) appear without definition or brief description, reducing readability for readers unfamiliar with the subsequent sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below and revised the paper to improve clarity, provide missing experimental details, and strengthen the supporting evidence for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports concrete PR-AUC gains of up to +0.23 and OOD generalization, yet supplies no experimental details on data splits, sample sizes, statistical significance tests, ablation results for the four metrics, or how hallucination labels were obtained for LR training. These omissions make the central performance claims impossible to evaluate for reliability or reproducibility.
Authors: We agree that the abstract's brevity omitted key details needed for immediate evaluation. In the revised version, we have expanded the abstract to briefly note the primary datasets (LibriSpeech and CoVoST for in-domain; Common Voice for OOD ASR), approximate evaluation sample sizes (~5k utterances per task), and that hallucination labels were obtained by comparing model outputs against ground-truth references using WER thresholds. Full specifications of data splits, statistical significance testing (paired t-tests with p<0.05), metric ablations, and label derivation procedures are now explicitly cross-referenced in the abstract and detailed in Sections 3.2 and 4.1. These changes should enable better assessment of reliability and reproducibility. revision: yes
-
Referee: [Abstract] Abstract: The metrics are described as capturing 'pathological attention patterns associated with hallucination', but the manuscript provides no direct evidence (e.g., distributions, visualizations, or correlation analysis) showing reliable, non-spurious differences between hallucinated and non-hallucinated generations. Because the logistic regression coefficients are fitted on labeled data, the reported gains may reflect model- or task-specific attention biases rather than general hallucination signals.
Authors: We acknowledge the concern that the abstract alone does not present direct evidence of metric differences. The full manuscript already contains supporting analysis in Section 4.2, including violin plots of metric distributions separated by hallucination status and attention map examples in Figure 2 illustrating divergent patterns (e.g., diffuse audio attention in hallucinations). To address the comment directly, we have added a new paragraph in the results section with Pearson correlation coefficients between each metric and binary hallucination labels (all |r| > 0.25, p < 0.01 after Bonferroni correction), plus an ablation showing that removing any single metric degrades PR-AUC. These additions demonstrate that the signals are not purely spurious or task-specific biases. We have also inserted a brief pointer to these analyses in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: The OOD ASR generalization claim and the ~100-head finding require more specification, including the exact OOD datasets, whether head selection was performed on in-domain data only, and quantitative comparison of full-head vs. subset performance across models. The statement that 'effectiveness is model-dependent and task-specific training is required' indicates the generalization scope may be narrower than presented.
Authors: We agree that additional specification is warranted to avoid overstatement. The revised abstract and Section 5 now explicitly name the OOD ASR dataset (Common Voice English subset), state that head selection was performed exclusively on in-domain validation data using a greedy search for the top-100 heads by validation PR-AUC, and include a new table (Table 5) with quantitative PR-AUC comparisons of full-head vs. 100-head classifiers on both in-domain and OOD settings for Qwen-2-Audio and Voxtral-3B. The table confirms the OOD improvement with the subset. We have also revised the concluding sentence to more precisely qualify the scope as model-dependent with task-specific training required, aligning with the empirical findings. revision: yes
Circularity Check
No significant circularity; empirical method with independent labels
full rationale
The paper defines four attention-derived metrics directly from model attention maps (AUDIORATIO, AUDIOCONSISTENCY, AUDIOENTROPY, TEXTENTROPY) and trains a logistic regression on them using separately labeled hallucination data. Reported PR-AUC gains and OOD generalization are standard held-out evaluation results, not reductions by construction. No equations equate a prediction to its own fitted inputs, no self-definitional loops, and no load-bearing self-citations or uniqueness theorems are invoked. The central claim rests on empirical correlation between the metrics and external labels rather than tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- logistic regression coefficients
axioms (2)
- domain assumption Attention patterns in SpeechLLMs contain detectable signals of hallucination behavior
- domain assumption Logistic regression is sufficient to combine the attention metrics into a reliable detector
invented entities (4)
-
AUDIORATIO
no independent evidence
-
AUDIOCONSISTENCY
no independent evidence
-
AUDIOENTROPY
no independent evidence
-
TEXTENTROPY
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hanin Atwany, Abdul Waheed, Rita Singh, Monojit Choudhury, and Bhiksha Raj. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1190 Lost in transcription, found in distribution shift: Demystifying hallucination in speech foundation models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 23181--23203, Vienna, Austria
-
[2]
Lo \" c Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, and 1 others. 2023. Seamlessm4t: massively multilingual & multimodal machine translation. arXiv preprint arXiv:2308.11596
-
[3]
Alexandra Canavan, David Graff, and George Zipperlen. 1997. CALLHOME American English Speech . LDC97S42, Web Download
1997
-
[4]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. 2024. https://arxiv.org/abs/2407.10759 Qwen2-audio technical report . Preprint, arXiv:2407.10759
work page internal anchor Pith review arXiv 2024
-
[5]
Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, and James R. Glass. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.84 Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pag...
-
[6]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. https://doi.org/10.18653/v1/2020.acl-main.747 Unsupervised cross-lingual representation learning at scale . In Proceedings of the 58th Annual Meeting of the Association for Comp...
- [7]
- [8]
-
[9]
Nuno M. Guerreiro, Duarte M. Alves, Jonas Waldendorf, Barry Haddow, Alexandra Birch, Pierre Colombo, and Andr \'e F. T. Martins. 2023 a . https://doi.org/10.1162/tacl_a_00615 Hallucinations in large multilingual translation models . Transactions of the Association for Computational Linguistics, 11:1500--1517
-
[10]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F
Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and Andr \'e F. T. Martins. 2024. https://doi.org/10.1162/tacl_a_00683 x COMET : Transparent machine translation evaluation through fine-grained error detection . Transactions of the Association for Computational Linguistics, 12:979--995
-
[11]
Guerreiro, Elena Voita, and Andr \'e Martins
Nuno M. Guerreiro, Elena Voita, and Andr \'e Martins. 2023 b . https://doi.org/10.18653/v1/2023.eacl-main.75 Looking for a needle in a haystack: A comprehensive study of hallucinations in neural machine translation . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 1059--1075, Dubrovnik, Croatia
-
[12]
Matthew B Hoy. 2018. Alexa, siri, cortana, and more: an introduction to voice assistants. Medical reference services quarterly, 37(1):81--88
2018
- [13]
- [14]
-
[15]
Moritz Laurer, Wouter van Atteveldt, Andreu Salleras Casas, and Kasper Welbers. 2022. https://osf.io/74b8k Less Annotating , More Classifying – Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT - NLI . Preprint. Publisher: Open Science Framework
2022
-
[16]
Alexander H. Liu, Andy Ehrenberg, Andy Lo, Clément Denoix, Corentin Barreau, Guillaume Lample, Jean-Malo Delignon, Khyathi Raghavi Chandu, Patrick von Platen, Pavankumar Reddy Muddireddy, Sanchit Gandhi, Soham Ghosh, Srijan Mishra, Thomas Foubert, Abhinav Rastogi, Adam Yang, Albert Q. Jiang, Alexandre Sablayrolles, Amélie Héliou, and 87 others. 2025. http...
-
[17]
Andrey Malinin and Mark John Francis Gales. 2021. https://api.semanticscholar.org/CorpusID:231895728 Uncertainty estimation in autoregressive structured prediction . In International Conference on Learning Representations
2021
-
[18]
Andrey Malinin, Anton Ragni, Kate Knill, and Mark Gales. 2017. https://doi.org/10.18653/v1/P17-2008 Incorporating uncertainty into deep learning for spoken language assessment . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 45--50, Vancouver, Canada
-
[19]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine learning in P ython. Journal of Machine Learning Research, 12:2825--2830
2011
-
[20]
Maja Popovi \'c . 2015. https://doi.org/10.18653/v1/W15-3049 chr F : character n-gram F -score for automatic MT evaluation . In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 392--395, Lisbon, Portugal
-
[21]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492--28518. PMLR
2023
-
[22]
Vikas Raunak, Arul Menezes, and Marcin Junczys-Dowmunt. 2021. https://doi.org/10.18653/v1/2021.naacl-main.92 The curious case of hallucinations in neural machine translation . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1172--1183, Online
-
[23]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/v1/D19-1410 Sentence- BERT : Sentence embeddings using S iamese BERT -networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982--3992, Hong Kong, China
- [24]
-
[25]
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. 2024 a . https://proceedings.neurips.cc/paper_files/paper/2024/file/3c1e1fdf305195cd620c118aaa9717ad-Paper-Conference.pdf Llm-check: Investigating detection of hallucinations in large language models . In Advances in Neural Information Process...
2024
-
[26]
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. 2024 b . https://openreview.net/forum?id=LYx4w3CAgy LLM -check: Investigating detection of hallucinations in large language models . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[27]
Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Lyudmila Rvanova, Daniil Vasilev, Akim Tsvigun, Sergey Petrakov, Rui Xing, Abdelrahman Sadallah, Kirill Grishchenkov, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov, and Artem Shelmanov. 2025. https://doi.org/10.1162/tacl_a_00737 Benchmarking uncertainty quantification methods for larg...
-
[28]
Artem Vazhentsev, Lyudmila Rvanova, Gleb Kuzmin, Ekaterina Fadeeva, Ivan Lazichny, Alexander Panchenko, Maxim Panov, Timothy Baldwin, Mrinmaya Sachan, Preslav Nakov, and Artem Shelmanov. 2025. https://arxiv.org/abs/2505.20045 Uncertainty-aware attention heads: Efficient unsupervised uncertainty quantification for llms . Preprint, arXiv:2505.20045
-
[29]
Elena Voita, Rico Sennrich, and Ivan Titov. 2021. https://doi.org/10.18653/v1/2021.acl-long.91 Analyzing the source and target contributions to predictions in neural machine translation . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Vo...
-
[30]
Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, and Emmanuel Dupoux. 2021. https://aclanthology.org/2021.acl-long.80 V ox P opuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation . In Proceedings of the 59th Annual Meeting of ...
2021
- [31]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.