Recognition: unknown
AblateCell: A Reproduce-then-Ablate Agent for Virtual Cell Repositories
Pith reviewed 2026-05-10 02:26 UTC · model grok-4.3
The pith
AblateCell is an agent that first reproduces reported baselines from virtual cell AI repositories by fixing environments and dependencies automatically, then ablates components to identify what drives performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
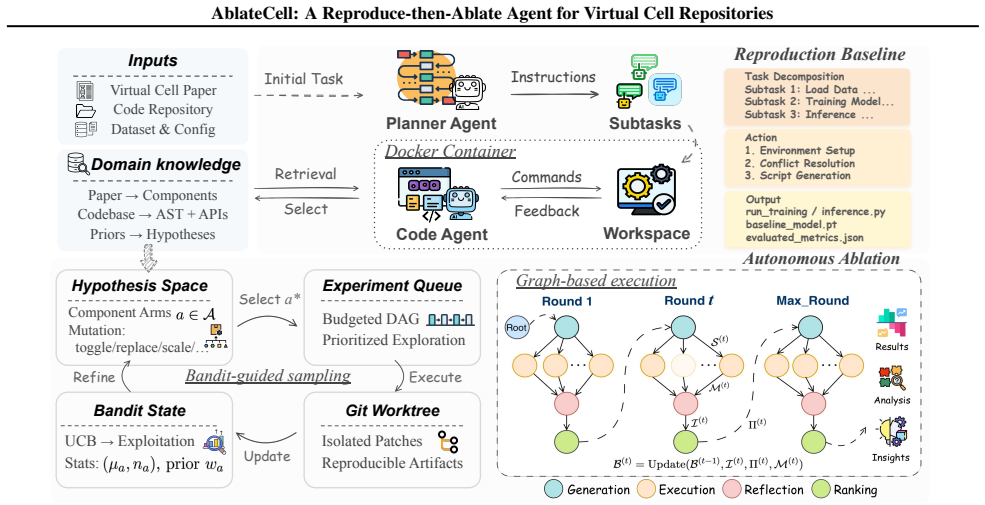
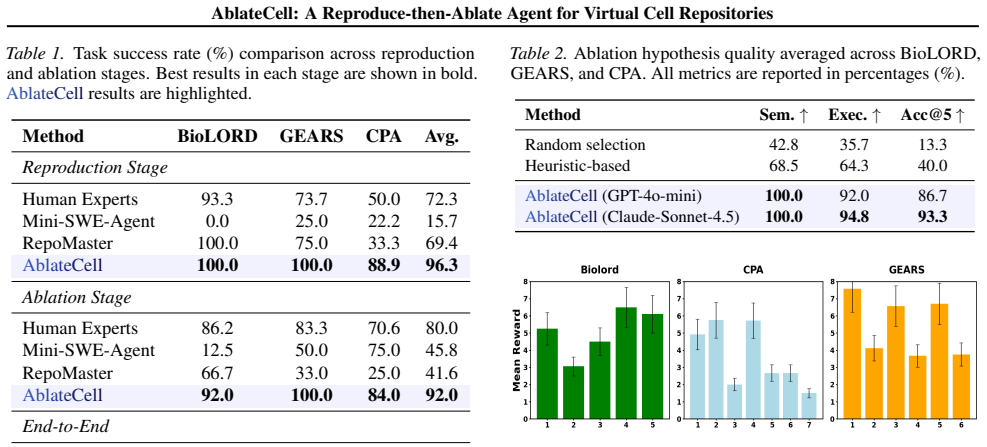
AblateCell closes the verification gap in virtual cell research by first reproducing reported baselines end-to-end through automatic environment configuration, dependency resolution, and rerunning of official evaluations while emitting verifiable artifacts, then conducting closed-loop ablation by generating a graph of isolated repository mutations and adaptively selecting experiments under a reward that trades off performance impact and execution cost, achieving 88.9 percent workflow success and 93.3 percent accuracy in recovering ground-truth critical components on the CPA, GEARS, and BioLORD repositories.
What carries the argument
The reproduce-then-ablate agent, which generates a graph of isolated repository mutations and adaptively selects experiments under a reward trading performance impact against execution cost.
If this is right
- Systematic ablations become feasible directly on biological codebases instead of remaining rare.
- Performance gains in AI virtual cells can be attributed to specific components with verifiable artifacts.
- Research shifts from one-off model releases toward repository-grounded verification and attribution.
- Scalable closed-loop testing reduces reliance on manual expert intervention for code validation.
Where Pith is reading between the lines
- The same reproduce-then-ablate pattern could apply to other domains with messy scientific codebases, such as molecular dynamics or imaging pipelines.
- Widespread use might standardize verification practices and reduce unreproducible claims in computational biology.
- Integrating the agent with ongoing model development could allow automatic discovery of better module combinations during training.
- Testing on larger or more heterogeneous repositories would reveal whether the reported success rates generalize beyond the three evaluated cases.
Load-bearing premise
Biological repositories are sufficiently under-standardized that an agent can reliably resolve dependency, data, and format issues automatically without domain-specific human intervention or access to private resources.
What would settle it
Running AblateCell on a fourth single-cell perturbation prediction repository with comparable reported baselines and observing whether it fails to reproduce the results or to recover the ground-truth critical components at similar accuracy.
Figures









read the original abstract
Systematic ablations are essential to attribute performance gains in AI Virtual Cells, yet they are rarely performed because biological repositories are under-standardized and tightly coupled to domain-specific data and formats. While recent coding agents can translate ideas into implementations, they typically stop at producing code and lack a verifier that can reproduce strong baselines and rigorously test which components truly matter. We introduce AblateCell, a reproduce-then-ablate agent for virtual cell repositories that closes this verification gap. AblateCell first reproduces reported baselines end-to-end by auto-configuring environments, resolving dependency and data issues, and rerunning official evaluations while emitting verifiable artifacts. It then conducts closed-loop ablation by generating a graph of isolated repository mutations and adaptively selecting experiments under a reward that trades off performance impact and execution cost. Evaluated on three single-cell perturbation prediction repositories (CPA, GEARS, BioLORD), AblateCell achieves 88.9% (+29.9% to human expert) end-to-end workflow success and 93.3% (+53.3% to heuristic) accuracy in recovering ground-truth critical components. These results enable scalable, repository-grounded verification and attribution directly on biological codebases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AblateCell, a reproduce-then-ablate agent for virtual cell repositories. It first reproduces reported baselines end-to-end via auto-configuration of environments, resolution of dependencies and data issues, and rerunning of official evaluations while emitting verifiable artifacts. It then performs closed-loop ablation by constructing a graph of isolated repository mutations and adaptively selecting experiments under a reward balancing performance impact and execution cost. Evaluated on three single-cell perturbation prediction repositories (CPA, GEARS, BioLORD), AblateCell reports 88.9% (+29.9% over human expert) end-to-end workflow success and 93.3% (+53.3% over heuristic) accuracy in recovering ground-truth critical components.
Significance. If the central performance claims hold under fuller scrutiny, this work would provide a concrete mechanism for scalable, repository-grounded verification and component attribution in AI for biology. The reproduce-then-ablate loop with external ground-truth components and closed-loop experiment selection directly addresses the rarity of systematic ablations in under-standardized biological codebases, offering a template that could be extended beyond the three evaluated repositories.
major comments (3)
- [Results] Results section: The headline metrics (88.9% workflow success, 93.3% component recovery) are reported without error bars, variance across runs, or full baseline implementation details (e.g., exact human-expert and heuristic procedures), which is load-bearing for the claim that AblateCell outperforms these comparators by the stated margins.
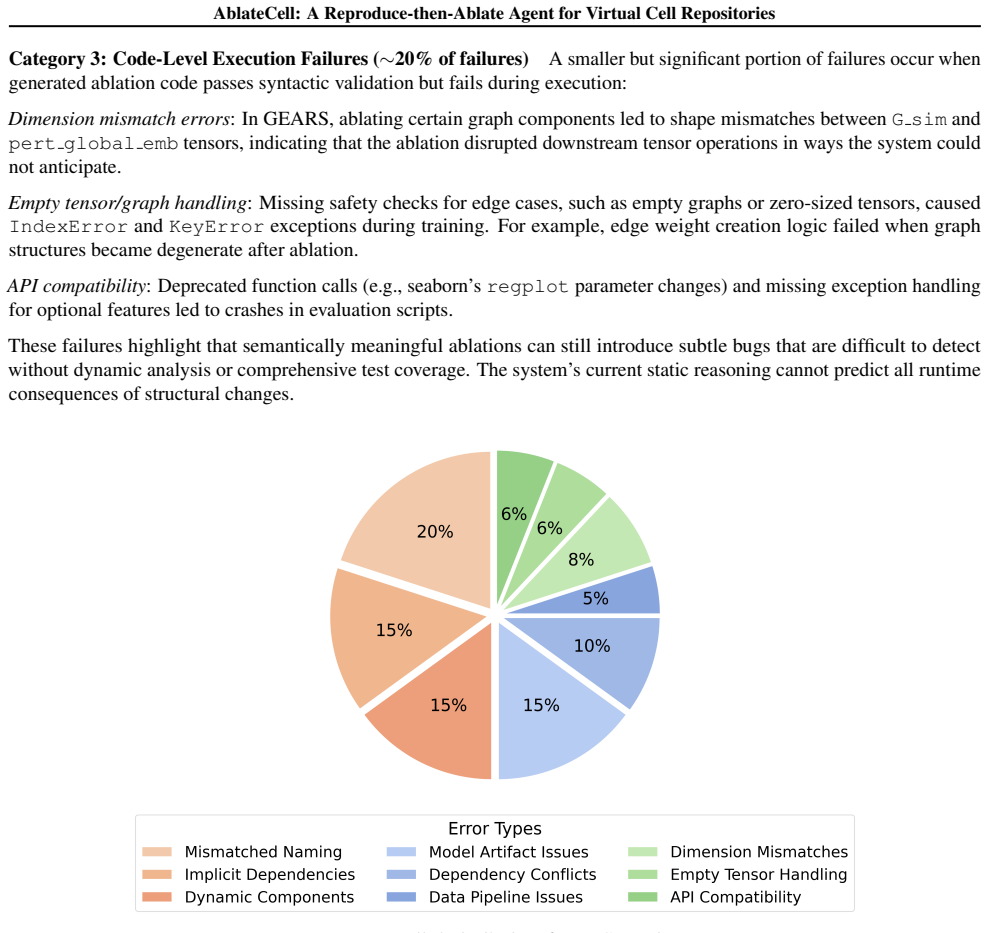
- [Evaluation] Evaluation section: The manuscript evaluates exclusively on CPA, GEARS, and BioLORD without describing systematic attempts on additional repositories or quantifying failure modes when data access requires licenses, private resources, or when the initial reproduction step fails; this directly limits support for the broader claim of scalable verification across under-standardized biological codebases.
- [Methods] Methods section: The closed-loop ablation procedure (graph construction, adaptive selection under the performance-cost reward) lacks sufficient algorithmic detail or pseudocode to allow reproduction of the experiment-selection logic, which is central to the agent's claimed advantage over non-adaptive ablations.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the three repositories at the outset rather than only in the evaluation paragraph.
- [Figures] Figure captions for the ablation graphs should include the exact reward function formulation and stopping criteria used in the closed-loop selection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving clarity, rigor, and support for our claims. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Results] Results section: The headline metrics (88.9% workflow success, 93.3% component recovery) are reported without error bars, variance across runs, or full baseline implementation details (e.g., exact human-expert and heuristic procedures), which is load-bearing for the claim that AblateCell outperforms these comparators by the stated margins.
Authors: We agree that the absence of error bars, variance reporting, and detailed baseline procedures weakens the substantiation of the performance margins. In the revised manuscript, we will add variance measures (standard deviation across runs where multiple executions were feasible) to the headline metrics. We will also expand the description of the human-expert and heuristic baselines with exact procedural steps, including how each was implemented and evaluated, to allow direct comparison and verification of the +29.9% and +53.3% improvements. revision: yes
-
Referee: [Evaluation] Evaluation section: The manuscript evaluates exclusively on CPA, GEARS, and BioLORD without describing systematic attempts on additional repositories or quantifying failure modes when data access requires licenses, private resources, or when the initial reproduction step fails; this directly limits support for the broader claim of scalable verification across under-standardized biological codebases.
Authors: Our evaluation focused on CPA, GEARS, and BioLORD due to their public availability and representativeness of single-cell perturbation tasks. We will revise the Evaluation section to include a dedicated subsection describing our systematic attempts to apply AblateCell to additional repositories, along with quantified failure modes for cases involving data access, dependency resolution, and reproduction failures. We will also add an explicit limitations discussion addressing challenges with licensed or private resources to better contextualize the scalability claims. revision: yes
-
Referee: [Methods] Methods section: The closed-loop ablation procedure (graph construction, adaptive selection under the performance-cost reward) lacks sufficient algorithmic detail or pseudocode to allow reproduction of the experiment-selection logic, which is central to the agent's claimed advantage over non-adaptive ablations.
Authors: We will revise the Methods section to provide full algorithmic detail, including pseudocode for graph construction of isolated repository mutations and the adaptive selection process. The pseudocode will explicitly define the reward function balancing performance impact and execution cost, the selection criteria, and the closed-loop iteration logic to enable independent reproduction of the experiment-selection mechanism. revision: yes
Circularity Check
No significant circularity: claims rest on external evaluations without self-referential reductions
full rationale
The paper introduces AblateCell as a reproduce-then-ablate agent and reports empirical success rates (88.9% workflow success, 93.3% component recovery) on three named external repositories (CPA, GEARS, BioLORD) using their ground-truth critical components. No equations, fitted parameters, or derivation steps appear in the abstract or described content. No self-citations are invoked as load-bearing premises for uniqueness theorems or ansatzes. The central results are obtained by running the agent on independent codebases and comparing against human experts and heuristics, so they do not reduce to quantities defined by the authors' own prior outputs or by construction. This is the normal case of an empirical systems paper whose evaluation chain remains externally anchored.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
GPT-5 System Card , url=
OpenAI , month=. GPT-5 System Card , url=
-
[7]
Claude Sonnet 4.5 System Card , url=
Anthropic , month=. Claude Sonnet 4.5 System Card , url=
-
[8]
Gemini 3 Pro Model Card , url=
Google DeepMind , year=. Gemini 3 Pro Model Card , url=
-
[9]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[10]
ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting in Language Models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Large language model based multi-agents: A survey of progress and challenges , author=. arXiv preprint arXiv:2402.01680 , year=
work page internal anchor Pith review arXiv
-
[12]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[13]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
The ai scientist: Towards fully automated open-ended scientific discovery , author=. arXiv preprint arXiv:2408.06292 , year=
work page internal anchor Pith review arXiv
-
[14]
arXiv preprint arXiv:2505.19955 , year =
MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research , author=. arXiv preprint arXiv:2505.19955 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Scicode: A research coding benchmark curated by scientists , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search , author=. arXiv preprint arXiv:2504.08066 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Nature methods , volume=
Reproducibility standards for machine learning in the life sciences , author=. Nature methods , volume=. 2021 , publisher=
2021
-
[18]
AI Magazine , volume=
Reproducibility in machine-learning-based research: Overview, barriers, and drivers , author=. AI Magazine , volume=. 2025 , publisher=
2025
-
[19]
Advanced Materials , volume=
SciAgents: automating scientific discovery through bioinspired multi-agent intelligent graph reasoning , author=. Advanced Materials , volume=. 2025 , publisher=
2025
-
[20]
AI4Research: A Survey of Artificial Intelligence for Scientific Research , author=. arXiv preprint arXiv:2507.01903 , year=
-
[21]
AI-Researcher: Autonomous Scientific Innovation , author=. arXiv preprint arXiv:2505.18705 , year=
-
[22]
Cell , volume=
How to build the virtual cell with artificial intelligence: Priorities and opportunities , author=. Cell , volume=. 2024 , publisher=
2024
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards scientific discovery with generative ai: Progress, opportunities, and challenges , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
Journal of Software: Evolution and Process , volume=
Llms for science: Usage for code generation and data analysis , author=. Journal of Software: Evolution and Process , volume=. 2025 , publisher=
2025
-
[25]
Paper2code: Automating code generation from scientific papers in machine learning , author=. arXiv preprint arXiv:2504.17192 , year=
-
[26]
Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges , author=. arXiv preprint arXiv:2401.07339 , year=
-
[27]
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation , year=
Zhang, Fengji and Chen, Bei and Zhang, Yue and Keung, Jacky and Liu, Jin and Zan, Daoguang and Mao, Yi and Lou, Jian-Guang and Chen, Weizhu , booktitle=. RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation , year=
-
[28]
Transactions on Machine Learning Research , volume=
CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark , author=. Transactions on Machine Learning Research , volume=
-
[29]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
REPRO-BENCH: Can Agentic AI Systems Assess the Reproducibility of Social Science Research? , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[30]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
ABGEN: Evaluating Large Language Models in Ablation Study Design and Evaluation for Scientific Research , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
arXiv preprint arXiv:2507.08038 , year=
AblationBench: Evaluating Automated Planning of Ablations in Empirical AI Research , author=. arXiv preprint arXiv:2507.08038 , year=
-
[32]
RExBench: Can coding agents autonomously implement AI research extensions?
RExBench: Can coding agents autonomously implement AI research extensions? , author=. arXiv preprint arXiv:2506.22598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Xu and Xiangru Tang and Mingchen Zhuge and Jiayi Pan and Yueqi Song and Bowen Li and Jaskirat Singh and Hoang H
Xingyao Wang and Boxuan Li and Yufan Song and Frank F. Xu and Xiangru Tang and Mingchen Zhuge and Jiayi Pan and Yueqi Song and Bowen Li and Jaskirat Singh and Hoang H. Tran and Fuqiang Li and Ren Ma and Mingzhang Zheng and Bill Qian and Yanjun Shao and Niklas Muennighoff and Yizhe Zhang and Binyuan Hui and Junyang Lin and et al. , title =. The Thirteenth ...
2025
-
[35]
From automation to autonomy: A survey on large language models in scientific discovery , author=. arXiv preprint arXiv:2505.13259 , year=
-
[36]
Agentic ai for scientific discovery: A survey of progress, challenges, and future directions
Agentic ai for scientific discovery: A survey of progress, challenges, and future directions , author=. arXiv preprint arXiv:2503.08979 , year=
-
[37]
arXiv preprint arXiv:2508.02276 , year=
CellForge: agentic design of virtual cell models , author=. arXiv preprint arXiv:2508.02276 , year=
-
[38]
Proceedings of the 5th Workshop on Machine Learning and Systems , pages=
Utilizing large language models for ablation studies in machine learning and deep learning , author=. Proceedings of the 5th Workshop on Machine Learning and Systems , pages=
-
[39]
Researchagent: Iterative research idea generation over scientific literature with large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[40]
arXiv preprint arXiv:2505.21577 , year=
Repomaster: Autonomous exploration and understanding of github repositories for complex task solving , author=. arXiv preprint arXiv:2505.21577 , year=
-
[41]
2024 , url=
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=. 2024 , url=
2024
-
[42]
Truong, Weixin Liang, Fan-Yun Sun, and Nick Haber
ResearchCodeBench: Benchmarking LLMs on Implementing Novel Machine Learning Research Code , author=. arXiv preprint arXiv:2506.02314 , year=
-
[43]
International Conference on Automated Machine Learning , pages=
Ablator: Robust horizontal-scaling of machine learning ablation experiments , author=. International Conference on Automated Machine Learning , pages=. 2023 , organization=
2023
-
[44]
arXiv preprint arXiv:2511.15462 , year=
Insights from the ICLR Peer Review and Rebuttal Process , author=. arXiv preprint arXiv:2511.15462 , year=
-
[45]
Molecular Systems Biology , pages=
Predicting cellular responses to complex perturbations in high-throughput screens , author=. Molecular Systems Biology , pages=
-
[46]
Nature Biotechnology , year=
Predicting transcriptional outcomes of novel multigene perturbations with gears , author=. Nature Biotechnology , year=
-
[47]
Nature Biotechnology , pages=
Disentanglement of single-cell data with biolord , author=. Nature Biotechnology , pages=. 2024 , publisher=
2024
-
[48]
and Horlbeck, Max A
Norman, Thomas M. and Horlbeck, Max A. and Replogle, Joseph M. and Geiger-Schuller, Katherine and Xu, Annie and Jost, Marco and Weissman, Jonathan S. , journal =. Exploring genetic interaction through single-cell. 2019 , volume =
2019
-
[49]
Nature methods , volume=
scGen predicts single-cell perturbation responses , author=. Nature methods , volume=. 2019 , publisher=
2019
-
[50]
Nature Methods , pages=
Squidiff: predicting cellular development and responses to perturbations using a diffusion model , author=. Nature Methods , pages=. 2025 , publisher=
2025
-
[51]
bioRxiv , year=
Modeling and predicting single-cell multi-gene perturbation responses with scLAMBDA , author=. bioRxiv , year=
-
[52]
Advances in Neural Information Processing Systems , volume=
Modelling cellular perturbations with the sparse additive mechanism shift variational autoencoder , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Bioinformatics , volume=
scDiffusion: conditional generation of high-quality single-cell data using diffusion model , author=. Bioinformatics , volume=. 2024 , publisher=
2024
-
[54]
arXiv preprint arXiv:2510.11726 , year=
scPPDM: A Diffusion Model for Single-Cell Drug-Response Prediction , author=. arXiv preprint arXiv:2510.11726 , year=
-
[55]
BioRxiv , pages=
Predicting cellular responses to perturbation across diverse contexts with State , author=. BioRxiv , pages=. 2025 , publisher=
2025
-
[56]
nature , volume=
Highly accurate protein structure prediction with AlphaFold , author=. nature , volume=. 2021 , publisher=
2021
-
[57]
Perturbench: Benchmarking machine learning models for cellular perturbation analysis , author=. arXiv preprint arXiv:2408.10609 , year=
-
[58]
Nature Methods , pages=
Benchmarking algorithms for generalizable single-cell perturbation response prediction , author=. Nature Methods , pages=. 2025 , publisher=
2025
-
[59]
npj Digital Medicine , year=
AI-driven virtual cell models in preclinical research: technical pathways, validation mechanisms, and clinical translation potential , author=. npj Digital Medicine , year=
-
[60]
arXiv preprint arXiv:2510.25694 , year=
Process-Level Trajectory Evaluation for Environment Configuration in Software Engineering Agents , author=. arXiv preprint arXiv:2510.25694 , year=
-
[61]
Nature Communications , volume=
ENCORE: a practical implementation to improve reproducibility and transparency of computational research , author=. Nature Communications , volume=. 2024 , publisher=
2024
-
[62]
Jiacheng Miao, Joe R Davis, Yaohui Zhang, Jonathan K Pritchard, and James Zou
Paper2agent: Reimagining research papers as interactive and reliable ai agents , author=. arXiv preprint arXiv:2509.06917 , year=
-
[63]
arXiv preprint arXiv:2510.13896 , year=
GenCellAgent: Generalizable, Training-Free Cellular Image Segmentation via Large Language Model Agents , author=. arXiv preprint arXiv:2510.13896 , year=
work page internal anchor Pith review arXiv
-
[64]
arXiv preprint arXiv:2504.04698 , year=
scagent: Universal single-cell annotation via a llm agent , author=. arXiv preprint arXiv:2504.04698 , year=
-
[65]
From ai for science to agentic science: A survey on autonomous scientific discovery , author=. arXiv preprint arXiv:2508.14111 , year=
-
[66]
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows , author=. arXiv preprint arXiv:2512.16969 , year=
-
[67]
Retrieval is Not Enough: Enhancing RAG through Test-Time Critique and Optimization , author=
-
[68]
Scientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning , author=. arXiv preprint arXiv:2506.10521 , year=
-
[69]
A survey of scientific large language models: From data foundations to agent frontiers , author=. arXiv preprint arXiv:2508.21148 , year=
-
[70]
arXiv preprint arXiv:2510.09988 , year=
Unifying tree search algorithm and reward design for llm reasoning: A survey , author=. arXiv preprint arXiv:2510.09988 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.