Recognition: unknown
A-MAR: Agent-based Multimodal Art Retrieval for Fine-Grained Artwork Understanding
Pith reviewed 2026-05-10 02:09 UTC · model grok-4.3
The pith
Agent-generated reasoning plans guide targeted retrieval to produce more grounded explanations of artworks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
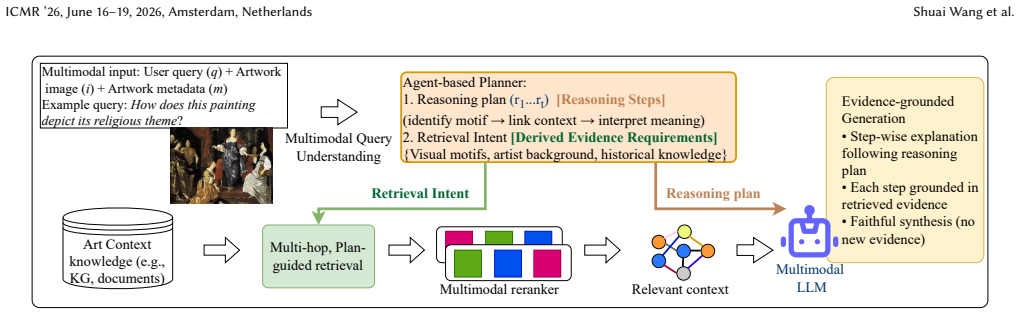
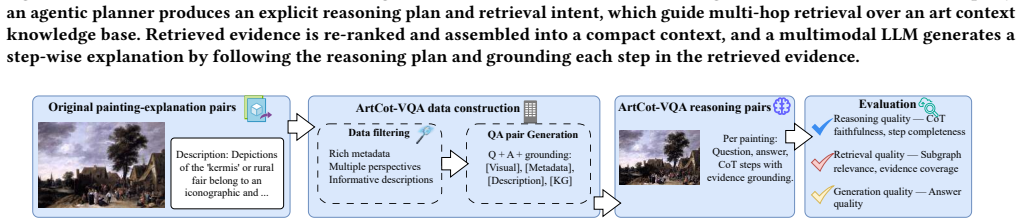
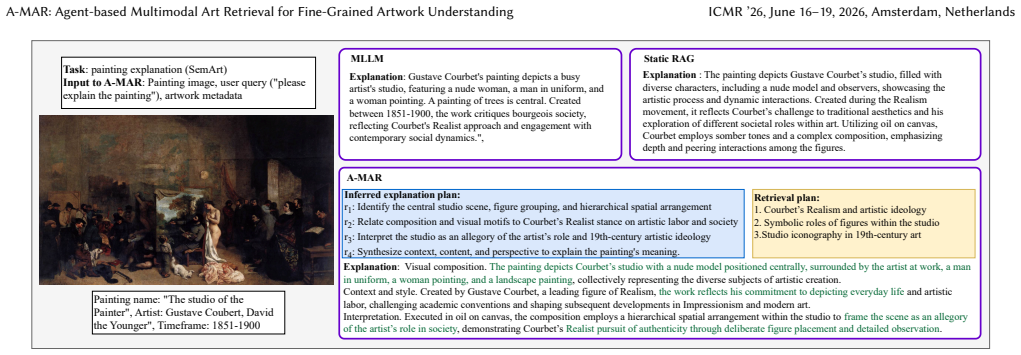
Given an artwork and a user query, A-MAR first decomposes the task into a structured reasoning plan that specifies the goals and evidence requirements for each step. Retrieval is then conditioned on this plan, enabling targeted evidence selection and supporting step-wise, grounded explanations. This produces higher-quality final explanations on SemArt and Artpedia while demonstrating clear advantages in evidence grounding and multi-step reasoning on the new ArtCoT-QA benchmark.
What carries the argument
Structured reasoning plans that specify per-step goals and evidence needs, used to condition the multimodal retrieval process.
If this is right
- A-MAR produces higher-quality final explanations than static retrieval or standard multimodal baselines on SemArt and Artpedia.
- It improves evidence grounding and multi-step reasoning ability when measured on ArtCoT-QA.
- The method supports interpretable, goal-driven retrieval rather than relying solely on internalized model knowledge.
- It is positioned as relevant for knowledge-intensive multimodal tasks in cultural domains.
Where Pith is reading between the lines
- The explicit plans could make it easier to audit or correct AI reasoning in other knowledge-rich domains such as history or material culture.
- If plan quality can be measured independently, the framework might support iterative improvement where weak steps are regenerated before retrieval.
- The same conditioning idea could be tested on non-art visual domains that require external context, such as scientific diagrams or archaeological finds.
Load-bearing premise
The agent can reliably generate structured reasoning plans that correctly identify needed evidence without introducing errors that degrade retrieval quality.
What would settle it
A controlled test on ArtCoT-QA in which retrieval uses the same model but ignores or replaces the generated reasoning plans, and the resulting explanations show equal or better grounding and multi-step accuracy than the full A-MAR system.
Figures


read the original abstract
Understanding artworks requires multi-step reasoning over visual content and cultural, historical, and stylistic context. While recent multimodal large language models show promise in artwork explanation, they rely on implicit reasoning and internalized knowl- edge, limiting interpretability and explicit evidence grounding. We propose A-MAR, an Agent-based Multimodal Art Retrieval framework that explicitly conditions retrieval on structured reasoning plans. Given an artwork and a user query, A-MAR first decomposes the task into a structured reasoning plan that specifies the goals and evidence requirements for each step. Retrieval is then conditionedon this plan, enabling targeted evidence selection and supporting step-wise, grounded explanations. To evaluate agent-based multi- modal reasoning within the art domain, we introduce ArtCoT-QA. This diagnostic benchmark features multi-step reasoning chains for diverse art-related queries, enabling a granular analysis that extends beyond simple final answer accuracy. Experiments on SemArt and Artpedia show that A-MAR consistently outperforms static, non planned retrieval and strong MLLM baselines in final explanation quality, while evaluations on ArtCoT-QA further demonstrate its advantages in evidence grounding and multi-step reasoning ability. These results highlight the importance of reasoning-conditioned retrieval for knowledge-intensive multimodal understanding and position A-MAR as a step toward interpretable, goal-driven AI systems, with particular relevance to cultural industries. The code and data are available at: https://github.com/ShuaiWang97/A-MAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes A-MAR, an agent-based multimodal art retrieval framework that first decomposes an artwork query into a structured reasoning plan specifying goals and evidence needs per step, then conditions retrieval on this plan to produce step-wise grounded explanations. It introduces the ArtCoT-QA diagnostic benchmark for multi-step art reasoning and reports that A-MAR outperforms static non-planned retrieval and strong MLLM baselines on SemArt and Artpedia for explanation quality, as well as on ArtCoT-QA for evidence grounding and reasoning ability. Code and data are released.
Significance. If the results hold after addressing validation gaps, the work advances interpretable multimodal reasoning by making retrieval explicitly goal-driven rather than implicit, with clear relevance to cultural heritage and fine-grained visual understanding tasks. The public release of code and the ArtCoT-QA benchmark is a concrete strength that supports reproducibility and further research.
major comments (2)
- [§3.2] §3.2 (Reasoning Plan Generation): The central claim that conditioning retrieval on agent-generated structured plans produces superior targeted evidence requires direct validation of plan quality. No quantitative metrics are reported on plan accuracy (e.g., fraction of plans with incorrect evidence requirements or logical gaps on ArtCoT-QA examples), leaving open whether outperformance arises from the planning mechanism itself.
- [§4.3] §4.3 (Ablation Studies): The manuscript lacks an oracle-plan ablation that replaces agent-generated plans with gold-standard plans while holding retrieval and generation steps fixed. Without this, it is impossible to isolate the causal role of the reasoning plan in the reported gains on explanation quality and grounding, as improvements could stem from extra LLM calls or retrieval volume.
minor comments (2)
- [Abstract] Abstract: 'conditionedon' is missing a space and should read 'conditioned on'.
- [§4] §4 (Experiments): The abstract and results sections claim 'consistent outperformance' without referencing specific quantitative deltas, tables, or statistical significance tests in the main text, which reduces clarity on the magnitude of improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our approach and indicating revisions to strengthen the validation of the reasoning plan mechanism.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Reasoning Plan Generation): The central claim that conditioning retrieval on agent-generated structured plans produces superior targeted evidence requires direct validation of plan quality. No quantitative metrics are reported on plan accuracy (e.g., fraction of plans with incorrect evidence requirements or logical gaps on ArtCoT-QA examples), leaving open whether outperformance arises from the planning mechanism itself.
Authors: We agree that direct quantitative metrics on plan quality would provide stronger support for the central claim. While ArtCoT-QA's focus on evidence grounding and multi-step reasoning offers indirect validation through end-to-end performance, it does not explicitly measure plan correctness. In the revised manuscript, we will add a new analysis in §3.2 and §4 reporting plan accuracy on a manually annotated sample of ArtCoT-QA examples, including the fraction of plans with correct evidence requirements and logical structure, along with common error categories. This will help confirm the reliability of the planning step. revision: yes
-
Referee: [§4.3] §4.3 (Ablation Studies): The manuscript lacks an oracle-plan ablation that replaces agent-generated plans with gold-standard plans while holding retrieval and generation steps fixed. Without this, it is impossible to isolate the causal role of the reasoning plan in the reported gains on explanation quality and grounding, as improvements could stem from extra LLM calls or retrieval volume.
Authors: We concur that an oracle-plan ablation is the most direct way to isolate the causal effect of the planning component. In the revised §4.3, we will add this ablation by adapting the gold multi-step reasoning chains from ArtCoT-QA into our structured plan format to serve as oracles. Performance will be compared against agent-generated plans while fixing the retrieval and generation modules and matching retrieval volume across conditions. We will also report on any differences in computational overhead to address concerns about extra LLM calls. revision: yes
Circularity Check
No circularity: A-MAR method and evaluations are independent of inputs
full rationale
The paper presents A-MAR as a novel agent-based framework that first generates a structured reasoning plan from artwork and query, then conditions multimodal retrieval on that plan to produce grounded explanations. This is evaluated empirically on SemArt, Artpedia, and the newly introduced ArtCoT-QA benchmark using standard metrics for explanation quality, evidence grounding, and multi-step reasoning. No equations, fitted parameters, or self-citations are used to define the core mechanism; the claimed superiority is asserted via experimental comparisons to static retrieval and MLLM baselines rather than by construction or renaming. The derivation chain therefore remains self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Panos Achlioptas, Maks Ovsjanikov, Kilichbek Haydarov, Mohamed Elhoseiny, and Leonidas Guibas. 2021. ArtEmis: Affective Language for Visual Art. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2021
-
[2]
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. 2016. SPICE: Semantic Propositional Image Caption Evaluation. InComputer Vision – ECCV 2016
2016
-
[3]
Anthropic. 2025. Introducing Claude Haiku 4.5. https://www.anthropic.com/ news/claude-haiku-4-5. 15-10-2025
2025
-
[4]
Anthropic. 2025. Introducing Claude Sonnet 4.5. https://www.anthropic.com/ news/claude-sonnet-4-5. 29-09-2025
2025
-
[5]
Zechen Bai, Yuta Nakashima, and Noa García. 2021. Explain Me the Paint- ing: Multi-Topic Knowledgeable Art Description Generation.2021 IEEE/CVF International Conference on Computer Vision (ICCV)(2021), 5402–5412. https: //api.semanticscholar.org/CorpusID:237490413
2021
-
[6]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization
2005
-
[7]
1988.Painting and experience in fifteenth century Italy: a primer in the social history of pictorial style
Michael Baxandall. 1988.Painting and experience in fifteenth century Italy: a primer in the social history of pictorial style. Oxford Paperbacks
1988
-
[8]
Yi Bin, Wenhao Shi, Yujuan Ding, Zhiqiang Hu, Zheng Wang, Yang Yang, See- Kiong Ng, and Heng Tao Shen. 2024. GalleryGPT: Analyzing Paintings with Large Multimodal Models. InProceedings of the 32nd ACM International Conference on Multimedia
2024
-
[9]
Tom et al. Brown. 2020. Language Models are Few-Shot Learners. InAdvances in Neural Information Processing Systems
2020
-
[10]
Gustavo Carneiro, Nuno Pinho da Silva, Alessio Del Bue, and João Paulo Costeira
-
[11]
In Proceedings of the 12th European Conference on Computer Vision (ECCV’12)
Artistic image classification: an analysis on the PRINTART database. In Proceedings of the 12th European Conference on Computer Vision (ECCV’12)
-
[12]
Eva Cetinic. 2021. Iconographic Image Captioning for Artworks. InPattern Recognition. ICPR International Workshops and Challenges, Alberto Del Bimbo, Rita Cucchiara, Stan Sclaroff, Giovanni Maria Farinella, Tao Mei, Marco Bertini, Hugo Jair Escalante, and Roberto Vezzani (Eds.)
2021
-
[13]
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. 2024. Mllm-as-a- judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In Forty-first International Conference on Machine Learning
2024
-
[14]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. 2024. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision
2024
-
[15]
Conde and Kerem Turgutlu
Marcos V. Conde and Kerem Turgutlu. 2021. CLIP-Art: Contrastive Pre-training for Fine-Grained Art Classification. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, Nashville, TN, USA
2021
-
[16]
Elliot Crowley and Andrew Zisserman. 2014. The State of the Art: Object Retrieval in Paintings using Discriminative Regions. InProceedings of the British Machine Vision Conference. BMVA Press
2014
-
[17]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. https://arxiv.org/abs/2404.16130
work page internal anchor Pith review arXiv 2025
- [18]
-
[19]
Athanasios Efthymiou, Stevan Rudinac, Monika Kackovic, Marcel Worring, and Nachoem Wijnberg. 2021. Graph Neural Networks for Knowledge Enhanced Visual Representation of Paintings. InProceedings of the 29th ACM International Conference on Multimedia
2021
-
[20]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24)
2024
-
[21]
Noa Garcia and George Vogiatzis. 2018. How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval. InProceedings of the European Con- ference in Computer Vision Workshops
2018
-
[22]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al . 2024. A survey on llm-as-a-judge.The Innovation(2024)
2024
-
[23]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2025. LightRAG: Simple and Fast Retrieval-Augmented Generation. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, Suzhou, China
2025
-
[24]
Kazuki Hayashi, Yusuke Sakai, Hidetaka Kamigaito, Katsuhiko Hayashi, and Taro Watanabe. [n. d.]. Towards Artwork Explanation in Large-scale Vision Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
-
[25]
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi
-
[26]
In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.)
CLIPScore: A Reference-free Evaluation Metric for Image Captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). https://aclanthology.org/2021.emnlp-main.595
2021
-
[27]
de Vries, Maarten de Rijke, and Faegheh Hasibi
Mohanna Hoveyda, Harrie Oosterhuis, Arjen P. de Vries, Maarten de Rijke, and Faegheh Hasibi. 2025. Adaptive Orchestration of Modular Generative Information Access Systems. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25)
2025
-
[28]
Jia-Hong Huang, Hongyi Zhu, Yixian Shen, Stevan Rudinac, and Evangelos Kanoulas. 2025. Image2text2image: A novel framework for label-free evaluation of image-to-text generation with text-to-image diffusion models. InInternational Conference on Multimedia Modeling. Springer, 413–427
2025
-
[29]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Trans. Inf. Syst.(2025)
2025
-
[30]
Gautier Izacard and Edouard Grave. 2021. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume
2021
-
[31]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of Hallucination in Natural Language Generation.ACM Comput. Surv., Article 248 (March 2023), 38 pages
2023
-
[32]
Ehinger, and Jey Han Lau
Yanbei Jiang, Krista A. Ehinger, and Jey Han Lau. 2024. KALE: An Artwork Image Captioning System Augmented with Heterogeneous Graph. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24. International Joint Conferences on Artificial Intelligence Organization
2024
-
[33]
Sergey Karayev, Matthew Trentacoste, Helen Han, Aseem Agarwala, Trevor Darrell, Aaron Hertzmann, and Holger Winnemoeller. 2014. Recognizing Image Style. InProceedings of the British Machine Vision Conference. BMVA Press
2014
-
[34]
Omar Shahbaz Khan, Ujjwal Sharma, Hongyi Zhu, Stevan Rudinac, and Björn Þór Jónsson. 2024. Exquisitor at the lifelog search challenge 2024: Blending conversa- tional search with user relevance feedback. InProceedings of the 7th Annual ACM Workshop on the Lifelog Search Challenge. 117–121
2024
-
[35]
Omar Shahbaz Khan, Hongyi Zhu, Ujjwal Sharma, Evangelos Kanoulas, Stevan Rudinac, and Björn Þór Jónsson. 2024. Exquisitor at the video browser showdown 2024: relevance feedback meets conversational search. InInternational Conference on Multimedia Modeling. Springer, 347–355
2024
-
[36]
Junlin Lee, Yequan Wang, Jing Li, and Min Zhang. 2024. Multimodal Reasoning with Multimodal Knowledge Graph. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand
2024
- [37]
-
[38]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Boot- strapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. InProceedings of the 40th International Conference on Machine Learning
2023
-
[39]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics
2004
-
[40]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruc- tion Tuning. InAdvances in Neural Information Processing Systems, Vol. 36
2023
-
[41]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore
2023
-
[42]
Mistral. 2025. Introducing Mistral 3. https://mistral.ai/news/mistral-3. 25-12- 2025
2025
-
[43]
Youssef Mohamed, Faizan Farooq Khan, Kilichbek Haydarov, and Mohamed Elhoseiny. 2022. It is Okay to Not Be Okay: Overcoming Emotional Bias in Affective Image Captioning by Contrastive Data Collection. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, New Orleans, LA, USA, 21231–21240. doi:10.1109/CVPR52688.2022.02058
-
[44]
OpenAI. 2025. Introducing GPT -5.2. https://openai.com/index/introducing-gpt- 5-2/. 11-12-2025. ICMR ’26, June 16–19, 2026, Amsterdam, Netherlands Shuai Wang et al
2025
-
[45]
Panofsky
E. Panofsky. 1955.Meaning in the Visual Arts. University of Chicago Press. https://books.google.nl/books?id=Qsa00QEACAAJ
1955
-
[46]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics
2002
-
[47]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Cynthia Rudin. 2019. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature machine intelligence1, 5 (2019), 206–215
2019
-
[49]
Shurong Sheng and Marie-Francine Moens. 2019. Generating Captions for Images of Ancient Artworks. InProceedings of the 27th ACM International Conference on Multimedia
2019
-
[50]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agen- tic Retrieval-Augmented Generation: A Survey on Agentic RAG.ArXiv abs/2501.09136 (2025)
work page internal anchor Pith review arXiv 2025
-
[51]
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Massimiliano Corsini, and Rita Cucchiara. 2019. Artpedia: A New Visual-Semantic Dataset with Visual and Contextual Sentences in the Artistic Domain. InImage Analysis and Processing – ICIAP 2019
2019
-
[52]
Gjorgji Strezoski, Lucas Fijen, Jonathan Mitnik, Dániel László, Pieter de Marez Oyens, Yoni Schirris, and Marcel Worring. 2020. TindART: A personal visual arts recommender. InProceedings of the 28th ACM International Conference on Multimedia
2020
-
[53]
Gjorgji Strezoski and Marcel Worring. 2018. OmniArt: A Large-scale Artistic Benchmark.ACM Trans. Multimedia Comput. Commun. Appl.(2018)
2018
-
[54]
Wei Ren Tan, Chee Seng Chan, Hernán E. Aguirre, and Kiyoshi Tanaka. 2016. Ceci n’est pas une pipe: A deep convolutional network for fine-art paintings classification. In2016 IEEE International Conference on Image Processing (ICIP). 3703–3707. doi:10.1109/ICIP.2016.7533051
-
[55]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. https://arxiv.org/abs/2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Shuai Wang, Ivona Najdenkoska, Hongyi Zhu, Stevan Rudinac, Monika Kackovic, Nachoem Wijnberg, and Marcel Worring. 2025. ArtRAG: Retrieval-Augmented Generation with Structured Context for Visual Art Understanding. InProceedings of the 33rd ACM International Conference on Multimedia (MM ’25)
2025
-
[57]
Shuai Wang, Jiayi Shen, Athanasios Efthymiou, Stevan Rudinac, Monika Kackovic, Nachoem Wijnberg, and Marcel Worring. 2024. Prototype-Enhanced Hypergraph Learning for Heterogeneous Information Networks. InMultiMedia Modeling
2024
- [58]
-
[59]
Zixun Wu. 2022. Artwork interpretation.Master’s thesis, University of Melbourne (2022)
2022
-
[60]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
- [61]
-
[62]
Zheng Yuan, HU Xue, Xinyi Wang, Yongming Liu, Zhuanzhe Zhao, and Kun Wang
-
[63]
InProceedings of conference on language modelling
ArtGPT-4: Towards Artistic-understanding Large Vision-Language Models with Enhanced Adapter. InProceedings of conference on language modelling
-
[64]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. 2024. Retrieval-Augmented Generation for AI-Generated Content: A Survey.ArXivabs/2402.19473 (2024)
work page internal anchor Pith review arXiv 2024
-
[65]
Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Xuan Long Do, Cheng- wei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, and Shafiq Joty
-
[67]
Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Do Xuan Long, Cheng- wei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, and Shafiq R. Joty
-
[68]
Retrieving Multimodal Information for Augmented Generation: A Survey. ArXivabs/2303.10868 (2023)
-
[69]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2025. A Survey of Large Language Models. arXiv:2303.18223 [cs.CL] https://ar...
work page internal anchor Pith review arXiv 2025
-
[70]
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, and Evangelos Kanoulas. 2024. Enhancing interactive image retrieval with query rewriting using large language models and vision language models. InProceedings of the 2024 International Conference on Multimedia Retrieval. 978–987
2024
-
[71]
Hongyi Zhu, Jia-Hong Huang, Yixian Shen, Stevan Rudinac, and Evangelos Kanoulas. 2025. Interactive Image Retrieval Meets Query Rewriting with Large Language and Vision Language Models.ACM Trans. Multimedia Comput. Com- mun. Appl., Article 286 (Oct. 2025), 23 pages
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.