Recognition: unknown
FASTER: Value-Guided Sampling for Fast RL
Pith reviewed 2026-05-10 02:43 UTC · model grok-4.3
The pith
FASTER models denoising of action candidates as an MDP so a learned value function can filter poor samples early and cut compute in diffusion RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
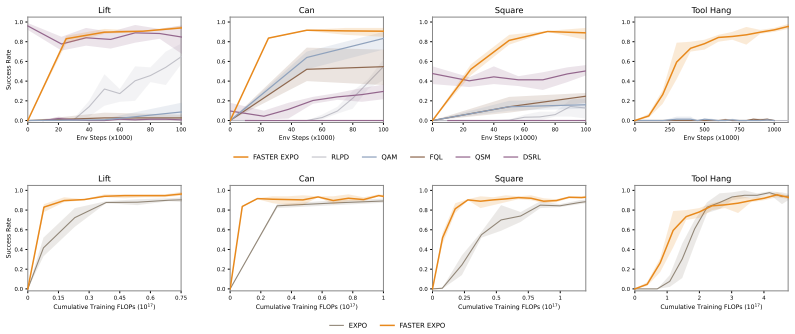
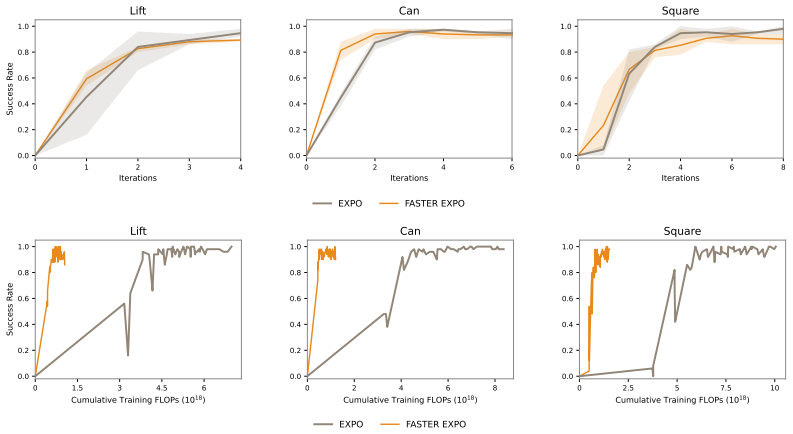
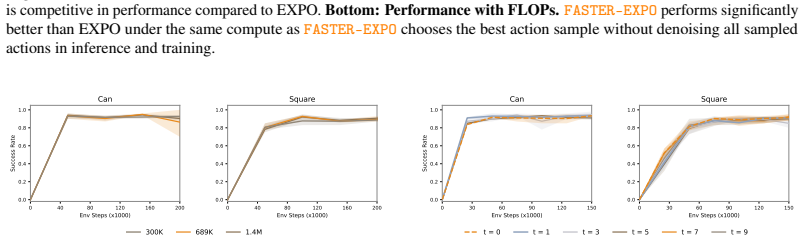
FASTER treats the denoising of multiple action candidates together with the selection of the best one as a Markov Decision Process defined directly in the space of partially denoised actions. A value function learned in this MDP predicts the eventual return of each candidate from its current denoising state and enables progressive filtering that discards low-value trajectories before they are fully denoised. The resulting lightweight module plugs into existing generative RL algorithms, improves policy performance on long-horizon manipulation tasks in both online and batch-online regimes, and matches the performance of a pretrained vision-language-action model while substantially lowering the
What carries the argument
The denoising-space MDP that frames progressive filtering of action candidates according to their predicted downstream returns.
If this is right
- FASTER improves the underlying policies across challenging long-horizon manipulation tasks in both online and batch-online RL.
- It achieves the best overall performance among the compared methods on those tasks.
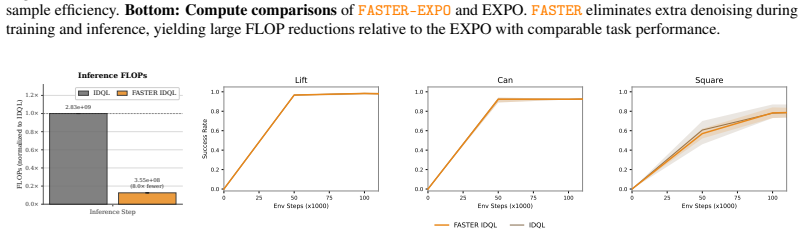
- When applied to a pretrained VLA it reaches the same final performance while reducing both training and inference compute.
- The method can be inserted as a lightweight addition into existing generative RL algorithms without changing their training procedure.
Where Pith is reading between the lines
- The same early-filtering logic could be tested on other iterative generative processes used inside RL, such as autoregressive token models.
- Dynamic adjustment of the candidate budget at each denoising step, rather than a fixed number, becomes feasible once value predictions are available.
- If the denoising-space value function transfers across tasks, it might reduce the need to retrain large policies from scratch when only inference efficiency is required.
Load-bearing premise
A value function trained inside the denoising-space MDP will rank partially denoised action candidates by their true eventual return without systematic bias introduced by early filtering decisions or by distribution shift between training and test-time trajectories.
What would settle it
An experiment in which FASTER is run on the same tasks but the early-filtered trajectories produce lower returns than full denoising of all candidates, or produce no net reduction in compute for equivalent final performance.
Figures






read the original abstract
Some of the most performant reinforcement learning algorithms today can be prohibitively expensive as they use test-time scaling methods such as sampling multiple action candidates and selecting the best one. In this work, we propose FASTER, a method for getting the benefits of sampling-based test-time scaling of diffusion-based policies without the computational cost by tracing the performance gain of action samples back to earlier in the denoising process. Our key insight is that we can model the denoising of multiple action candidates and selecting the best one as a Markov Decision Process (MDP) where the goal is to progressively filter action candidates before denoising is complete. With this MDP, we can learn a policy and value function in the denoising space that predicts the downstream value of action candidates in the denoising process and filters them while maximizing returns. The result is a method that is lightweight and can be plugged into existing generative RL algorithms. Across challenging long-horizon manipulation tasks in online and batch-online RL, FASTER consistently improves the underlying policies and achieves the best overall performance among the compared methods. Applied to a pretrained VLA, FASTER achieves the same performance while substantially reducing training and inference compute requirements. Code is available at https://github.com/alexanderswerdlow/faster .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FASTER, a method that reformulates the denoising process of multiple action candidates from a diffusion-based policy as a Markov Decision Process (MDP) in denoising space. A policy and value function are learned to progressively filter low-value candidates early in the denoising trajectory, with the value function predicting downstream returns to maximize performance while reducing the number of full denoising steps required. The approach is presented as a lightweight plug-in for existing generative RL algorithms. Empirical claims include consistent policy improvements and best-in-class performance on long-horizon manipulation tasks in both online and batch-online RL settings, plus equivalent performance to a pretrained VLA with substantially lower training and inference compute.
Significance. If the empirical claims hold under the distribution-shift concerns, FASTER would provide a practical mechanism for test-time scaling in diffusion policies without proportional compute cost, which is relevant for robotics and long-horizon control. Code availability supports reproducibility and potential follow-up work.
major comments (2)
- [Method (MDP formulation and value-function training)] The central claim rests on the value function accurately ranking partially denoised candidates by eventual return. However, because the filtering policy alters the distribution of denoising trajectories at test time relative to the (unfiltered or differently filtered) trajectories used to train the value function, systematic bias in value estimates is possible. This distribution-shift issue is load-bearing for the filtering decisions and is not addressed by additional analysis or targeted ablations in the experiments section.
- [Experiments] Table 1 and Figure 3 (performance comparisons): while the paper states that FASTER achieves the best overall performance, the reported gains are not accompanied by statistical significance tests or sufficient error analysis across seeds to confirm that improvements are not attributable to variance in the underlying base policies.
minor comments (2)
- [Abstract] The abstract would benefit from one or two key quantitative results (e.g., success-rate deltas or compute-reduction factors) to allow readers to assess the magnitude of the claimed improvements without reading the full experiments section.
- [Background / Method] Notation for the denoising-space state and action spaces is introduced without an explicit comparison table to the original MDP; a small diagram or table would improve clarity for readers unfamiliar with diffusion policies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below, providing clarifications and indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Method (MDP formulation and value-function training)] The central claim rests on the value function accurately ranking partially denoised candidates by eventual return. However, because the filtering policy alters the distribution of denoising trajectories at test time relative to the (unfiltered or differently filtered) trajectories used to train the value function, systematic bias in value estimates is possible. This distribution-shift issue is load-bearing for the filtering decisions and is not addressed by additional analysis or targeted ablations in the experiments section.
Authors: We appreciate the referee highlighting this potential distribution shift. The value function is trained exclusively on trajectories sampled from the base diffusion policy (without filtering), which exposes it to a wide range of denoising paths and their associated returns. At test time the filtering policy uses these estimates to prune low-value candidates early; because the policy is trained to maximize the same return objective, the selected trajectories are biased toward high-value paths by design. Nevertheless, we agree that an explicit analysis of any resulting bias would improve the manuscript. In the revision we will add an ablation that measures the correlation between predicted values and realized returns on both filtered and unfiltered trajectory sets, together with a short discussion of observed discrepancies. These results will be placed in the experiments section. revision: partial
-
Referee: [Experiments] Table 1 and Figure 3 (performance comparisons): while the paper states that FASTER achieves the best overall performance, the reported gains are not accompanied by statistical significance tests or sufficient error analysis across seeds to confirm that improvements are not attributable to variance in the underlying base policies.
Authors: We agree that the current presentation would benefit from formal statistical analysis. While the reported numbers are already averages over multiple random seeds, we did not include error bars or significance tests. In the revised manuscript we will augment Table 1 and Figure 3 with standard-deviation error bars across seeds and add p-values from paired statistical tests (e.g., Wilcoxon signed-rank) comparing FASTER against each baseline. These additions will be described in the experimental protocol subsection. revision: yes
Circularity Check
No circularity: standard RL value learning on explicitly defined denoising MDP
full rationale
The paper models denoising + selection as an MDP, then trains a value function on trajectories from that MDP to estimate downstream return for early filtering. This is a conventional critic-learning step whose training signal comes from environment returns, not from the filtering policy itself. No equation reduces the learned value to a tautology or renames a fitted parameter as a prediction; no self-citation supplies a uniqueness theorem or ansatz; the empirical claims rest on task performance measured after training, which is externally falsifiable. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- Value function and policy parameters in denoising space
axioms (1)
- domain assumption The process of denoising multiple action candidates can be faithfully represented as an MDP whose states are partial trajectories and whose actions are keep/discard decisions.
Reference graph
Works this paper leans on
-
[1]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.CoRR, abs/2203.11171, 2022. doi: 10.48550/arXiv.2203.11171. URL https:// arxiv.org/abs/2203.11171
-
[2]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters.CoRR, abs/2408.03314, 2024. doi: 10.48550/arXiv.2408.03314. URLhttps://arxiv.org/abs/2408.03314
-
[3]
Yinlam Chow, Guy Tennenholtz, Izzeddin Gur, Vincent Zhuang, Bo Dai, Sridhar Thiagarajan, Craig Boutilier, Rishabh Agarwal, Aviral Kumar, and Aleksandra Faust. Inference-aware fine-tuning for best-of-N sampling in large language models.CoRR, abs/2412.15287, 2024. doi: 10.48550/arXiv.2412.15287. URLhttps://arxiv.org/abs/2412.15287
-
[4]
Inference-time scaling for diffusion models beyond scaling denoising steps
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, and Saining Xie. Inference-time scaling for diffusion models beyond scaling denoising steps.CoRR, abs/2501.09732, 2025. doi: 10.48550/arXiv.2501.09732. URLhttps://arxiv.org/abs/2501.09732
-
[5]
EXPO: Stable Reinforcement Learning with Expressive Policies
Perry Dong, Qiyang Li, Dorsa Sadigh, and Chelsea Finn. EXPO: Stable reinforcement learning with expressive policies.CoRR, abs/2507.07986, 2025. doi: 10.48550/arXiv.2507.07986. URL https://arxiv.org/abs/2507.07986
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.07986 2025
-
[6]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. IDQL: Implicit q-learning as an actor-critic method with diffusion policies.CoRR, abs/2304.10573, 2023. doi: 10.48550/arXiv.2304.10573. URL https://arxiv.org/abs/ 2304.10573
work page internal anchor Pith review doi:10.48550/arxiv.2304.10573 2023
-
[7]
arXiv preprint arXiv:2510.07650 , year=
Perry Dong, Chongyi Zheng, Chelsea Finn, Dorsa Sadigh, and Benjamin Eysenbach. Value flows, 2026. URLhttps://arxiv.org/abs/2510.07650
-
[8]
Offline reinforcement learning via high-fidelity generative behavior modeling
Huayu Chen, Cheng Lu, Chengyang Ying, Hang Su, and Jun Zhu. Offline reinforcement learning via high-fidelity generative behavior modeling, 2023. URL https://arxiv.org/ abs/2209.14548
-
[9]
Zhendong Wang, Jonathan J. Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning.CoRR, abs/2208.06193, 2022. doi: 10.48550/ arXiv.2208.06193. URLhttps://arxiv.org/abs/2208.06193
-
[10]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.CoRR, abs/2303.04137, 2023. doi: 10.48550/arXiv.2303.04137. URL https://arxiv.org/abs/ 2303.04137
work page internal anchor Pith review doi:10.48550/arxiv.2303.04137 2023
-
[11]
arXiv preprint arXiv:2305.13122 , year=
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning, 2023. URLhttps://arxiv.org/abs/2305.13122
-
[12]
Flow q-learning
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, Proceedings of Machine Learning Research. PMLR / O...
2025
-
[13]
Posterior behavioral cloning: Pretraining bc policies for efficient rl finetuning,
Andrew Wagenmaker, Perry Dong, Raymond Tsao, Chelsea Finn, and Sergey Levine. Posterior behavioral cloning: Pretraining bc policies for efficient rl finetuning, 2025. URL https: //arxiv.org/abs/2512.16911
-
[14]
Learning a diffusion model policy from rewards via q-score matching
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching. InProceedings of the 41st International Conference on Machine Learning, 2024. 11
2024
-
[15]
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. Steering your generalists: Improving robotic foundation models via value guidance.CoRR, abs/2410.13816, 2024. doi: 10.48550/arXiv.2410.13816. URLhttps://arxiv.org/abs/2410.13816
-
[16]
Jacky Kwok, Christopher Agia, Rohan Sinha, Matthew Foutter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models.CoRR, abs/2506.17811, 2025. doi: 10.48550/arXiv.2506.17811. URLhttps://arxiv.org/abs/2506.17811
-
[17]
Zhendong Wang, Zhaoshuo Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj Narang, Linxi Fan, Yuke Zhu, Yogesh Balaji, Mingyuan Zhou, Ming-Yu Liu, and Yu Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion distillation.CoRR, abs/2410.21257,
-
[18]
doi: 10.48550/arXiv.2410.21257. URLhttps://arxiv.org/abs/2410.21257
-
[19]
Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Nagabandi, Abhishek Gupta, and Sergey Levine. Steering your diffusion policy with latent space reinforcement learning.CoRR, abs/2506.15799, 2025. doi: 10.48550/arXiv.2506. 15799. URLhttps://arxiv.org/abs/2506.15799
-
[20]
arXiv preprint arXiv:2406.01970 (2024)
Yuanhao Ban, Ruochen Wang, Tianyi Zhou, Boqing Gong, Cho-Jui Hsieh, and Minhao Cheng. The crystal ball hypothesis in diffusion models: Anticipating object positions from initial noise. CoRR, abs/2406.01970, 2024. doi: 10.48550/arXiv.2406.01970. URL https://arxiv.org/ abs/2406.01970
-
[21]
Zipeng Qi, Lichen Bai, Haoyi Xiong, and Zeke Xie. Not all noises are created equally: Diffusion noise selection and optimization.CoRR, abs/2407.14041, 2024. doi: 10.48550/arXiv.2407. 14041. URLhttps://arxiv.org/abs/2407.14041
-
[22]
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. InitNO: Boosting text-to-image diffusion models via initial noise optimization.CoRR, abs/2404.04650,
-
[23]
doi: 10.48550/arXiv.2404.04650. URLhttps://arxiv.org/abs/2404.04650
-
[24]
Changgu Chen, Libing Yang, Xiaoyan Yang, Lianggangxu Chen, Gaoqi He, Changbo Wang, and Yang Li. FIND: Fine-tuning initial noise distribution with policy optimization for diffusion models.CoRR, abs/2407.19453, 2024. doi: 10.48550/arXiv.2407.19453. URL https:// arxiv.org/abs/2407.19453
-
[25]
Zikai Zhou, Shitong Shao, Lichen Bai, Zhiqiang Xu, Bo Han, and Zeke Xie. Golden noise for diffusion models: A learning framework.CoRR, abs/2411.09502, 2024. doi: 10.48550/arXiv. 2411.09502. URLhttps://arxiv.org/abs/2411.09502
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[26]
A noise is worth diffusion guidance, 2024
Donghoon Ahn, Jiwon Kang, Sanghyun Lee, Jaewon Min, Minjae Kim, Wooseok Jang, Hyoungwon Cho, Sayak Paul, SeonHwa Kim, Eunju Cha, Kyong Hwan Jin, and Seun- gryong Kim. A noise is worth diffusion guidance.CoRR, abs/2412.03895, 2024. doi: 10.48550/arXiv.2412.03895. URLhttps://arxiv.org/abs/2412.03895
-
[27]
arXiv preprint arXiv:2509.13936 , year=
Harvey Mannering, Zhiwu Huang, and Adam Prügel-Bennett. Noise-level diffusion guidance: Well begun is half done.CoRR, abs/2509.13936, 2025. doi: 10.48550/arXiv.2509.13936. URL https://arxiv.org/abs/2509.13936
-
[28]
Noise hypernetworks: Amortizing test-time compute in diffusion models.CoRR, abs/2508.09968,
Luca Eyring, Shyamgopal Karthik, Alexey Dosovitskiy, Nataniel Ruiz, and Zeynep Akata. Noise hypernetworks: Amortizing test-time compute in diffusion models.CoRR, abs/2508.09968,
-
[29]
Noise hypernetworks: Amortizing test-time compute in diffusion models.CoRR, abs/2508.09968,
doi: 10.48550/arXiv.2508.09968. URLhttps://arxiv.org/abs/2508.09968
-
[30]
TTSnap: Test-time scaling of diffusion models via noise-aware pruning.CoRR, abs/2511.22242, 2025
Qingtao Yu, Changlin Song, Minghao Sun, Zhengyang Yu, Vinay Kumar Verma, Soumya Roy, Sumit Negi, Hongdong Li, and Dylan Campbell. TTSnap: Test-time scaling of diffusion models via noise-aware pruning.CoRR, abs/2511.22242, 2025. doi: 10.48550/arXiv.2511.22242. URL https://arxiv.org/abs/2511.22242
-
[31]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022. URLhttps://arxiv.org/abs/2209.03003
work page internal anchor Pith review arXiv 2022
-
[32]
One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models, 2025. URLhttps://arxiv.org/abs/2410.12557. 12
-
[33]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A Vision- Language-Action Model with Open-World Generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URL https://arxiv.org/abs/ 2403.03206
work page internal anchor Pith review arXiv 2024
-
[35]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, Wei Liu, Yichun Shi, Shiqi Sun, Yu Tian, Zhi Tian, Peng Wang, Rui Wang, Xuanda Wang, Xun Wang, Ye Wang, Guofeng Wu, Jie Wu, Xin Xia, Xuefeng Xiao, Zhonghua Zhai, Xinyu Zhang, Qi Zhang, Yuwei Zhang, Shijia Zhao, Jianchao Yang, and Weilin Hu...
work page internal anchor Pith review arXiv 2025
-
[36]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine Glossop, Thomas Godden, Ivan Goryachev, Lachy Groom, Hunter Hancock, Karol Hausman, Gashon Hussein, Brian Ichter, Szym...
work page Pith review arXiv 2025
-
[38]
Perry Dong, Suvir Mirchandani, Dorsa Sadigh, and Chelsea Finn. What matters for batch online reinforcement learning in robotics?, 2025. URLhttps://arxiv.org/abs/2505.08078
-
[39]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
2023
-
[40]
Q-learning with adjoint matching,
Qiyang Li and Sergey Levine. Q-learning with adjoint matching, 2026. URL https://arxiv. org/abs/2601.14234
work page internal anchor Pith review arXiv 2026
-
[41]
Perry Dong, Alec M. Lessing, Annie S. Chen, and Chelsea Finn. Reinforcement learning via implicit imitation guidance, 2025. URLhttps://arxiv.org/abs/2506.07505
-
[42]
Perry Dong, Kuo-Han Hung, Alexander Swerdlow, Dorsa Sadigh, and Chelsea Finn. Tql: Scaling q-functions with transformers by preventing attention collapse, 2026. URL https: //arxiv.org/abs/2602.01439
-
[43]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review arXiv 2026
-
[44]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, Y...
work page internal anchor Pith review arXiv 2025
-
[45]
World action models are zero-shot policies,
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
-
[46]
URLhttps://arxiv.org/abs/2602.15922
work page internal anchor Pith review arXiv
-
[47]
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic-video: Video-action models for generalizable robot control beyond vlas, 2025. URLhttps://arxiv.org/abs/2512.15692. 14 A Additional Experiments A natural question is whether the best-of- N sampling benefits observed in EXPO and IDQL can be recovered by a sing...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.