Recognition: unknown
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
Pith reviewed 2026-05-10 01:59 UTC · model grok-4.3
The pith
UniT creates a shared latent space of physical intents by anchoring human and humanoid actions to their common visual outcomes, allowing direct transfer of human data into robot policies and simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
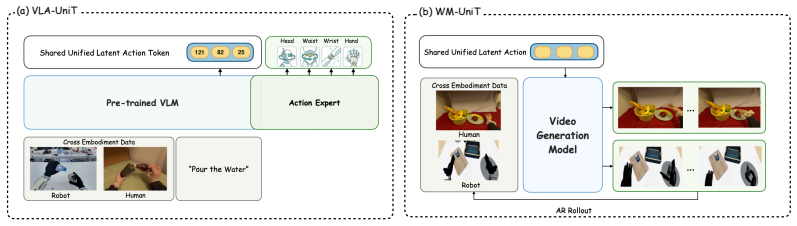
UniT employs a tri-branch cross-reconstruction mechanism in which actions predict vision to ground kinematics in observable outcomes and vision reconstructs actions to remove visual confounders, while a fusion branch merges the purified signals into a single discrete latent space of embodiment-agnostic physical intents; this space then serves as the common language for both policy learning from human data and direct human-to-humanoid transfer in world modeling.
What carries the argument
The tri-branch cross-reconstruction mechanism that forms the Unified Latent Action Tokenizer via Visual Anchoring, which links actions to their visual consequences and filters confounders to yield a shared discrete space of physical intents.
If this is right
- Predicting the unified tokens lets VLA-UniT leverage diverse human data to reach state-of-the-art data efficiency and robust out-of-distribution generalization, including zero-shot task transfer on humanoid simulation benchmarks and real-world deployments.
- Conditioning on the unified tokens lets WM-UniT align cross-embodiment dynamics, enabling direct human-to-humanoid action transfer and higher action controllability in generated humanoid videos.
- The resulting representation is highly aligned, as confirmed by t-SNE plots where human and humanoid features merge into a single manifold.
- The framework supplies a scalable route for converting large volumes of human knowledge into general-purpose humanoid capabilities.
Where Pith is reading between the lines
- The same visual-anchoring principle could be applied to transfer knowledge between other robot body types that differ in kinematics but share observable physical effects.
- Pretraining world models primarily on human video using these tokens might reduce or eliminate the need to collect large-scale robot-specific interaction data.
- The discrete tokens could allow seamless mixing of human and robot demonstrations in a single training run without additional alignment modules.
Load-bearing premise
Different body structures and movement styles still produce the same visual results for the same physical intent, so that vision can reliably link and purify actions across embodiments.
What would settle it
t-SNE visualizations that fail to show human and humanoid features converging into one shared manifold, or policy-learning experiments in which UniT shows no gains in data efficiency or zero-shot transfer relative to baselines that do not use the unified tokens.
Figures














read the original abstract
Scaling humanoid foundation models is bottlenecked by the scarcity of robotic data. While massive egocentric human data offers a scalable alternative, bridging the cross-embodiment chasm remains a fundamental challenge due to kinematic mismatches. We introduce UniT (Unified Latent Action Tokenizer via Visual Anchoring), a framework that establishes a unified physical language for human-to-humanoid transfer. Grounded in the philosophy that heterogeneous kinematics share universal visual consequences, UniT employs a tri-branch cross-reconstruction mechanism: actions predict vision to anchor kinematics to physical outcomes, while vision reconstructs actions to filter out irrelevant visual confounders. Concurrently, a fusion branch synergies these purified modalities into a shared discrete latent space of embodiment-agnostic physical intents. We validate UniT across two paradigms: 1) Policy Learning (VLA-UniT): By predicting these unified tokens, it effectively leverages diverse human data to achieve state-of-the-art data efficiency and robust out-of-distribution (OOD) generalization on both humanoid simulation benchmark and real-world deployments, notably demonstrating zero-shot task transfer. 2) World Modeling (WM-UniT): By aligning cross-embodiment dynamics via unified tokens as conditions, it realizes direct human-to-humanoid action transfer. This alignment ensures that human data seamlessly translates into enhanced action controllability for humanoid video generation. Ultimately, by inducing a highly aligned cross-embodiment representation (empirically verified by t-SNE visualizations revealing the convergence of human and humanoid features into a shared manifold), UniT offers a scalable path to distill vast human knowledge into general-purpose humanoid capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UniT (Unified Latent Action Tokenizer via Visual Anchoring), a tri-branch cross-reconstruction framework that anchors actions to visual outcomes and reconstructs actions from vision to produce a shared discrete latent space of embodiment-agnostic physical intents. It applies this to policy learning (VLA-UniT) for claimed SOTA data efficiency, OOD generalization, and zero-shot humanoid task transfer from human data, and to world modeling (WM-UniT) for direct human-to-humanoid action transfer in video generation, with cross-embodiment alignment verified via t-SNE visualizations of converging human and humanoid features.
Significance. If the tri-branch mechanism and resulting unified tokens genuinely enable embodiment-agnostic transfer without kinematic confounders, the approach could meaningfully address humanoid data scarcity by distilling human egocentric data into scalable policies and world models.
major comments (2)
- [Abstract] Abstract: claims of state-of-the-art performance, zero-shot task transfer, robust OOD generalization, and enhanced action controllability are asserted without any quantitative metrics, baselines, error bars, dataset sizes, or ablation results, preventing assessment of whether the tri-branch mechanism delivers the stated improvements.
- [Abstract] Abstract: the central claim of a highly aligned cross-embodiment representation rests on t-SNE visualizations showing convergence into a shared manifold; t-SNE is sensitive to perplexity, initialization, and metrics and can produce apparent alignment even when representations remain distinguishable by embodiment, with no quantitative corroboration (e.g., embodiment classification accuracy or distribution distances) referenced.
minor comments (1)
- The manuscript would benefit from explicit definitions of the tri-branch loss terms, the discrete latent tokenizer, and the fusion branch architecture, including any equations governing the action-to-vision and vision-to-action reconstruction.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. We address the major comments point by point below, clarifying the role of the abstract and the supporting evidence in the full paper while committing to revisions that improve the presentation of quantitative results and alignment metrics.
read point-by-point responses
-
Referee: [Abstract] Abstract: claims of state-of-the-art performance, zero-shot task transfer, robust OOD generalization, and enhanced action controllability are asserted without any quantitative metrics, baselines, error bars, dataset sizes, or ablation results, preventing assessment of whether the tri-branch mechanism delivers the stated improvements.
Authors: The abstract is written as a concise high-level summary of the contributions and key outcomes. Comprehensive quantitative support—including SOTA comparisons, baselines, error bars, dataset sizes, and ablations demonstrating the tri-branch mechanism's contributions—is provided in the main text (Sections 4.2–4.4, Tables 1–5, and Figures 4–8). To directly address the concern and make the abstract more self-contained, we will revise it to incorporate representative quantitative highlights (e.g., data-efficiency gains and zero-shot success rates) with pointers to the detailed experiments. revision: yes
-
Referee: [Abstract] Abstract: the central claim of a highly aligned cross-embodiment representation rests on t-SNE visualizations showing convergence into a shared manifold; t-SNE is sensitive to perplexity, initialization, and metrics and can produce apparent alignment even when representations remain distinguishable by embodiment, with no quantitative corroboration (e.g., embodiment classification accuracy or distribution distances) referenced.
Authors: We agree that t-SNE visualizations are inherently qualitative and sensitive to parameter choices, and that they should not stand alone as evidence of alignment. The manuscript presents the t-SNE plots as illustrative of observed feature convergence, which is corroborated by the downstream empirical results in cross-embodiment policy learning and world modeling. To strengthen the claim, we will add quantitative corroboration in the revision, including linear-probe embodiment classification accuracy and distribution-distance metrics (e.g., MMD or Wasserstein distance) between human and humanoid latent features, to be reported in Section 4.4. revision: yes
Circularity Check
No significant circularity; empirical framework without self-referential derivations or fitted predictions
full rationale
The paper introduces UniT as an architectural framework (tri-branch cross-reconstruction plus fusion branch) grounded in an explicit philosophical premise about universal visual consequences of kinematics. No equations, parameter-fitting procedures, or predictive claims that reduce to fitted inputs appear in the abstract or described content. Alignment is asserted via t-SNE visualizations as external empirical verification rather than a quantity defined in terms of the model's own outputs. No self-citations, uniqueness theorems, or ansatzes imported from prior author work are referenced as load-bearing. The central claims rest on design choices and reported experimental outcomes, not on any step that equates to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous kinematics share universal visual consequences
invented entities (1)
-
Unified Latent Action Tokenizer (UniT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.15704 (2025)
Xiongyi Cai, Ri-Zhao Qiu, Geng Chen, Lai Wei, Isabella Liu, Tianshu Huang, Xuxin Cheng, and Xiaolong Wang. In-n-on: Scaling egocentric manipulation with in-the-wild and on-task data.arXiv preprint arXiv:2511.15704, 2025
-
[2]
Tony Tao, Mohan Kumar Srirama, Jason Jingzhou Liu, Kenneth Shaw, and Deepak Pathak. Dexwild: Dexterous human interactions for in-the-wild robot policies.arXiv preprint arXiv:2505.07813, 2025
-
[3]
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
-
[4]
Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
-
[5]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Action tokenizer matters in in-context imitation learning
An Dinh Vuong, Minh Nhat Vu, Dong An, and Ian Reid. Action tokenizer matters in in-context imitation learning. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13490–13496. IEEE, 2025
2025
-
[7]
Quest: Self-supervised skill abstractions for learning continuous control, 2024.URL https://arxiv
Atharva Mete, Haotian Xue, Albert Wilcox, Yongxin Chen, and Animesh Garg. Quest: Self-supervised skill abstractions for learning continuous control, 2024.URL https://arxiv. org/abs/2407.15840, 2024
-
[8]
Vq-vla: Improving vision-language-action models via scaling vector-quantized action tokenizers
Yating Wang, Haoyi Zhu, Mingyu Liu, Jiange Yang, Hao-Shu Fang, and Tong He. Vq-vla: Improving vision-language-action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11089–11099, 2025
2025
-
[9]
Moto: Latent motion token as the bridging language for learning robot manipulation from videos
Yi Chen, Yuying Ge, Weiliang Tang, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, and Xihui Liu. Moto: Latent motion token as the bridging language for learning robot manipulation from videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19752–19763, 2025
2025
-
[10]
Latent Action Pretraining from Videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
work page Pith review arXiv 2024
-
[11]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Xindong He, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025
2025
-
[13]
Yankai Fu, Ning Chen, Junkai Zhao, Shaozhe Shan, Guocai Yao, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Metis: Multi-source egocentric training for integrated dexterous vision-language-action model.arXiv preprint arXiv:2511.17366, 2025
-
[14]
arXiv preprint arXiv:2203.12601 (2022)
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
-
[15]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022
work page internal anchor Pith review arXiv 2022
-
[16]
Real-world robot learning with masked visual pre-training
Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real-world robot learning with masked visual pre-training. InConference on Robot Learning, pages 416–426. PMLR, 2023
2023
-
[17]
Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers.Advances in neural information processing systems, 37:124420– 124450, 2024
Lirui Wang, Xinlei Chen, Jialiang Zhao, and Kaiming He. Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers.Advances in neural information processing systems, 37:124420– 124450, 2024
2024
-
[18]
Humanoid policy˜ human policy,
Ri-Zhao Qiu, Shiqi Yang, Xuxin Cheng, Chaitanya Chawla, Jialong Li, Tairan He, Ge Yan, David J Yoon, Ryan Hoque, Lars Paulsen, et al. Humanoid policy˜ human policy.arXiv preprint arXiv:2503.13441, 2025. 19
-
[19]
Chengbo Yuan, Rui Zhou, Mengzhen Liu, Yingdong Hu, Shengjie Wang, Li Yi, Chuan Wen, Shanghang Zhang, and Yang Gao. Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies.arXiv preprint arXiv:2509.17759, 2025
-
[20]
Egomimic: Scaling imitation learning via egocentric video
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
-
[21]
H-rdt: Human manipulation enhanced bimanual robotic manipulation
Hongzhe Bi, Lingxuan Wu, Tianwei Lin, Hengkai Tan, Zhizhong Su, Hang Su, and Jun Zhu. H-rdt: Human manipulation enhanced bimanual robotic manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18135–18143, 2026
2026
-
[22]
arXiv preprint arXiv:2512.22414 (2025)
Simar Kareer, Karl Pertsch, James Darpinian, Judy Hoffman, Danfei Xu, Sergey Levine, Chelsea Finn, and Suraj Nair. Emergence of human to robot transfer in vision-language-action models.arXiv preprint arXiv:2512.22414, 2025
-
[23]
Villa-x: enhancing latent action modeling in vision-language-action models,
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language- action models.arXiv preprint arXiv:2507.23682, 2025
-
[24]
Shichao Fan, Kun Wu, Zhengping Che, Xinhua Wang, Di Wu, Fei Liao, Ning Liu, Yixue Zhang, Zhen Zhao, Zhiyuan Xu, et al. Xr-1: Towards versatile vision-language-action models via learning unified vision-motion representations.arXiv preprint arXiv:2511.02776, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[26]
GR00T N1: An open foundation model for generalist humanoid robots
NVIDIA, Johan Bjorck, Nikita Cherniadev Fernando Castañeda, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You L...
2025
-
[27]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[30]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
Irasim: A fine-grained world model for robot manipulation
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. Irasim: A fine-grained world model for robot manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9834–9844, 2025
2025
-
[32]
Ctrl-world: A controllable generative world model for robot manipulation, 2026
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025
-
[33]
Evaluating robot policies in a world model.arXiv e-prints, pages arXiv–2506, 2025
Julian Quevedo, Percy Liang, and Sherry Yang. Evaluating robot policies in a world model.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[34]
NVIDIA, Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, Prithvijit Chattopadhyay, Mike Chen, Yongxin Chen, Yu Chen, Shuai Cheng, Yin Cui, Jenna Diamond, Yifan Ding, Jiaojiao Fan, Linxi Fan, Liang Feng, Francesco Ferroni, Sanja Fidler, Xiao Fu, Ruiyuan Gao, Yunhao Ge, Jin...
2025
-
[35]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Gr00t n1: An open foundation model for generalist humanoid robots, 2025
NVIDIA, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You ...
2025
-
[38]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,
Ryan Hoque, Peide Huang, David J Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
-
[39]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abraham Lee, You...
2024
-
[40]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review arXiv 2025
-
[41]
Flare: Robot learning with implicit world modeling, 2025
Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Yu Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Loic Magne, et al. Flare: Robot learning with implicit world modeling.arXiv preprint arXiv:2505.15659, 2025
-
[42]
Gr00t n1.6: An improved open foundation model for generalist humanoid robots
NVIDIA GEAR Team, Allison Azzolini, Johan Bjorck, Valts Blukis, et al. Gr00t n1.6: An improved open foundation model for generalist humanoid robots. https://research.nvidia.com/labs/gear/ gr00t-n1_6/, December 2025
2025
-
[43]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[44]
Fvd: A new metric for video generation
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019
2019
-
[45]
Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605, 2008. 21
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.