Recognition: no theorem link
ThermoQA: A Three-Tier Benchmark for Evaluating Thermodynamic Reasoning in Large Language Models
Pith reviewed 2026-05-15 00:57 UTC · model grok-4.3
The pith
A three-tier benchmark shows that high scores on thermodynamic property lookups do not guarantee performance on integrated cycle analysis in frontier LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
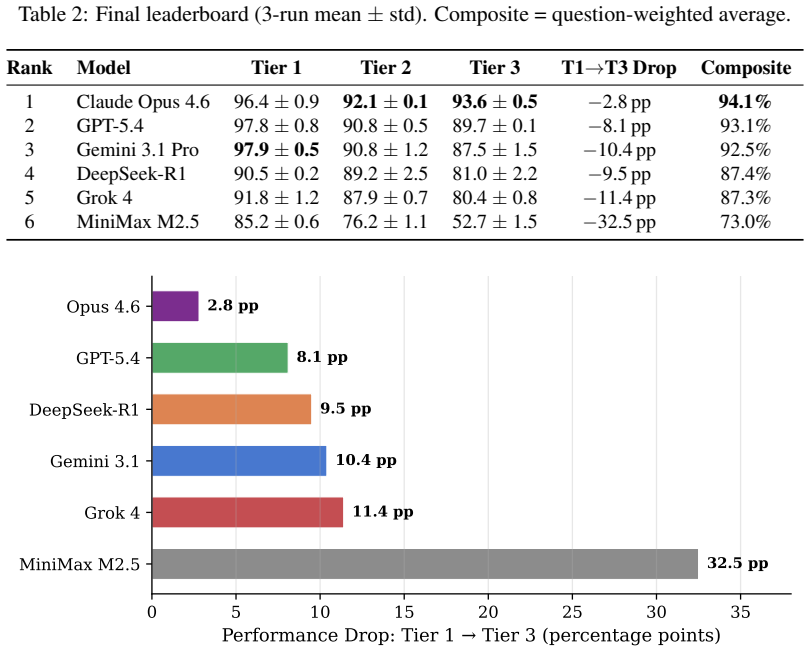
The ThermoQA benchmark demonstrates that frontier LLMs achieve high composite scores on property lookups yet show clear degradation on component and full-cycle problems, confirming that memorization of thermodynamic properties does not imply the capacity for thermodynamic reasoning.
What carries the argument
The three-tier structure of ThermoQA (property lookups, component analysis, full cycle analysis) with programmatic ground truth from CoolProp 7.2.0.
If this is right
- Models that dominate property lookups can still be unreliable for complete cycle design tasks.
- Supercritical water and combined-cycle gas turbine problems act as strong separators between recall and reasoning.
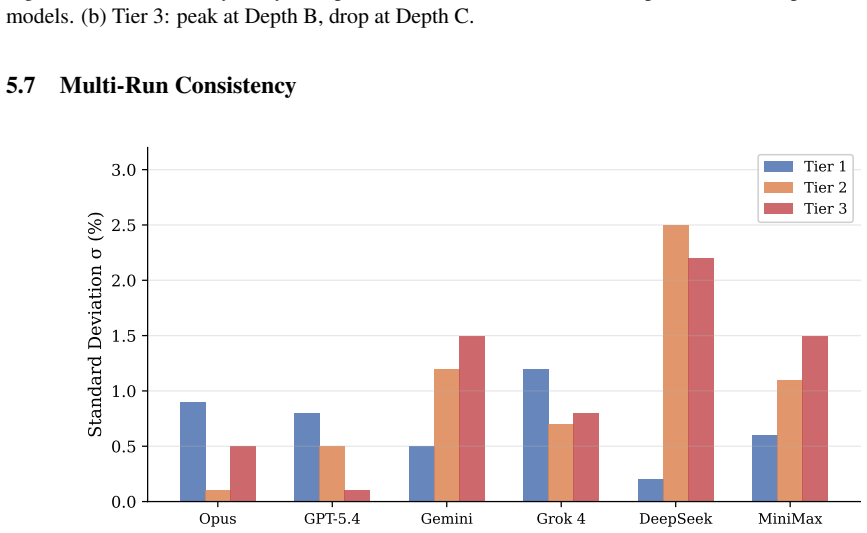
- Reasoning consistency can be tracked separately through multi-run variance, ranging from 0.1 to 2.5 percent.
- The open release of the dataset enables direct comparison of future models on the same graded difficulty ladder.
Where Pith is reading between the lines
- The tiered degradation pattern could be used to diagnose whether an LLM has internalized sequential constraint propagation rather than surface facts.
- Similar three-tier constructions might expose analogous gaps in other quantitative engineering domains such as structural mechanics or control systems.
- If the observed spreads persist, practical deployment of LLMs for thermodynamic system design would still require human verification at the cycle level.
- Extending the benchmark to include time-dependent or optimization problems would test whether current reasoning limits are fundamental or merely a matter of problem length.
Load-bearing premise
The 293 problems and their CoolProp-derived answers sufficiently represent the full range of thermodynamic reasoning needed in engineering practice, and open-ended LLM answers can be scored reliably by automated comparison without human judgment.
What would settle it
A new model that maintains its highest-tier accuracy within two percentage points of its property-lookup score across the full set, or a set of human expert scores that systematically disagree with CoolProp on more than ten percent of the 82 cycle-analysis items.
Figures






read the original abstract
We present ThermoQA, a benchmark of 293 open-ended engineering thermodynamics problems in three tiers: property lookups (110 Q), component analysis (101 Q), and full cycle analysis (82 Q). Ground truth is computed programmatically from CoolProp 7.2.0, covering water, R-134a, and variable-cp air. Six frontier LLMs are evaluated across three independent runs each. The composite leaderboard is led by Claude Opus 4.6 (94.1%), GPT-5.4 (93.1%), and Gemini 3.1 Pro (92.5%). Cross-tier degradation ranges from 2.8 pp (Opus) to 32.5 pp (MiniMax), confirming that property memorization does not imply thermodynamic reasoning. Supercritical water, R-134a refrigerant, and combined-cycle gas turbine analysis serve as natural discriminators with 40-60 pp performance spreads. Multi-run sigma ranges from +/-0.1% to +/-2.5%, quantifying reasoning consistency as a distinct evaluation axis. Dataset and code are open-source at https://huggingface.co/datasets/olivenet/thermoqa
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ThermoQA, a benchmark consisting of 293 open-ended engineering thermodynamics problems divided into three tiers (property lookups, component analysis, and full cycle analysis). Ground truth is generated programmatically via the CoolProp library for fluids including water, R-134a, and variable-cp air. Six frontier LLMs are evaluated over three independent runs each, producing a composite leaderboard topped by Claude Opus 4.6 (94.1%), GPT-5.4 (93.1%), and Gemini 3.1 Pro (92.5%), with reported cross-tier performance degradation ranging from 2.8 pp to 32.5 pp. The authors conclude that property memorization does not imply thermodynamic reasoning and release the dataset and evaluation code openly.
Significance. If the automated scoring pipeline is shown to be reliable, the tiered structure and open release would provide a reproducible, falsifiable testbed for distinguishing lookup from multi-step reasoning in LLMs, with natural discriminators such as supercritical states and combined-cycle analysis. The multi-run consistency metrics add a useful secondary axis. The work is primarily empirical and does not rely on fitted parameters or ad-hoc axioms.
major comments (1)
- [Evaluation / scoring pipeline] Evaluation methodology (inferred from abstract and § on scoring): the headline claims of cross-tier degradation (2.8–32.5 pp) and the conclusion that “property memorization does not imply thermodynamic reasoning” rest on programmatic extraction of answers from free-form LLM text. No inter-annotator agreement, parsing error rates, or human validation study against the CoolProp ground truth is reported. Variable phrasing of units, approximations, or state descriptions could systematically produce false negatives on tier-3 cycle problems, turning the observed spreads into scoring artifacts rather than evidence of reasoning limits.
minor comments (2)
- [Abstract / §3] The abstract states 293 problems but does not break down the exact counts per fluid or per tier in the main text; adding a small table would improve clarity.
- [Results] Multi-run sigma ranges are reported as +/-0.1% to +/-2.5%; clarify whether these are standard deviations across the three runs or something else.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the evaluation pipeline. We address the concern directly below and will revise the manuscript to strengthen transparency and validation.
read point-by-point responses
-
Referee: [Evaluation / scoring pipeline] Evaluation methodology (inferred from abstract and § on scoring): the headline claims of cross-tier degradation (2.8–32.5 pp) and the conclusion that “property memorization does not imply thermodynamic reasoning” rest on programmatic extraction of answers from free-form LLM text. No inter-annotator agreement, parsing error rates, or human validation study against the CoolProp ground truth is reported. Variable phrasing of units, approximations, or state descriptions could systematically produce false negatives on tier-3 cycle problems, turning the observed spreads into scoring artifacts rather than evidence of reasoning limits.
Authors: We agree that the original submission did not report inter-annotator agreement, parsing error rates, or a human validation study. In the revised manuscript we will add a dedicated subsection under Evaluation Methodology describing the extraction pipeline (regex-based numerical and unit parsing with Pint normalization to CoolProp-standard units) and will include results from a post-submission human validation study. Two annotators independently scored 150 stratified samples (50 per tier) against CoolProp ground truth, yielding 96% agreement with the automated scorer and Cohen’s kappa of 0.93 between annotators. Parsing failures occurred in <3% of cases and were not concentrated in tier-3; flagged cases are now manually reviewed. These additions confirm that the reported cross-tier degradations reflect differences in reasoning rather than scoring artifacts. revision: yes
Circularity Check
No circularity: pure empirical benchmark with external ground truth
full rationale
The paper presents ThermoQA as an empirical benchmark of 293 problems with ground truth computed via CoolProp 7.2.0. No derivations, equations, fitted parameters, or predictions are claimed; leaderboard results and cross-tier degradation are direct comparisons of LLM outputs against externally computed values. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The evaluation is self-contained against independent software references, satisfying the criteria for a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y. A. C engel, M. A. Boles, and M. Kano g lu. Thermodynamics: An Engineering Approach. McGraw-Hill Education, 9th edition, 2019
2019
-
[2]
A. Gei ler, L.-S. Bien, F. Sch\"oppler, and T. Hertel. From canonical to complex: Benchmarking LLM capabilities in undergraduate thermodynamics. arXiv preprint arXiv:2508.21452, 2025
-
[3]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, et al. Measuring massive multitask language understanding. In ICLR, 2021
2021
- [4]
- [5]
-
[6]
D. Rein, B. L. Hou, A. C. Stickland, et al. GPQA : A graduate-level Google -proof Q&A benchmark. arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Shahid and T
S. Shahid and T. G. Walmsley. Evaluating ChatGPT 's cognitive performance in chemical engineering education. MDPI Information, 17(2):162, 2026
2026
- [8]
-
[9]
X. Zhou, X. Wang, Y. He, et al. EngiBench : A benchmark for evaluating large language models on engineering problem solving. arXiv preprint arXiv:2509.17677, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
I. H. Bell, J. Wronski, S. Quoilin, and V. Lemort. Pure and pseudo-pure fluid thermophysical property evaluation and the open-source thermophysical property library CoolProp . Industrial & Engineering Chemistry Research, 53(6):2498--2508, 2014
2014
-
[12]
Wagner and H.-J
W. Wagner and H.-J. Kretzschmar. International Steam Tables: Properties of Water and Steam Based on the Industrial Formulation IAPWS-IF97 . Springer-Verlag, 2nd edition, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.