Recognition: no theorem link
TTKV: Temporal-Tiered KV Cache for Long-Context LLM Inference
Pith reviewed 2026-05-14 23:44 UTC · model grok-4.3
The pith
TTKV divides the KV cache into temporal tiers that give recent states faster higher-precision memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
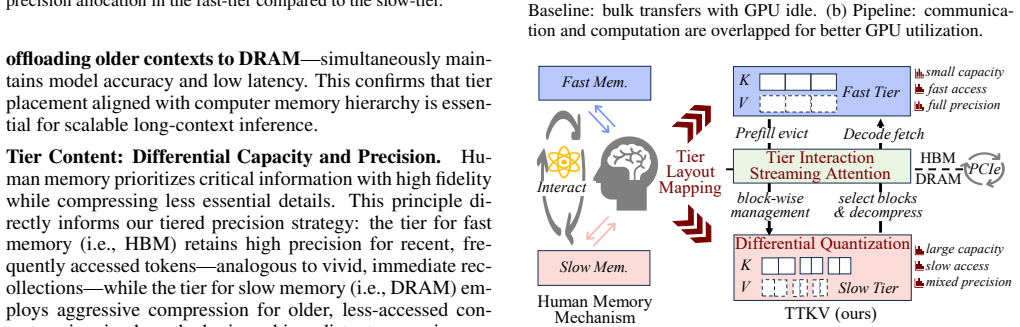
TTKV partitions the KV cache into temporal tiers with heterogeneous capacity and precision. It assigns recent KV states to faster, higher-precision tiers based on temporal proximity, decouples fast and slow memory using HBM and DRAM for tier layout, and employs block-wise streaming attention to overlap communication and computation when accessing slow tiers.
What carries the argument
Temporal tiers that assign KV states to memory layers of differing speed and precision according to how recent each state is.
If this is right
- Long-context inference runs with substantially lower memory bandwidth demand because most traffic stays inside the fast tier.
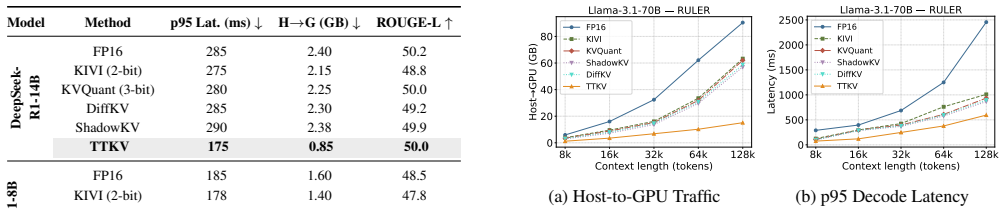
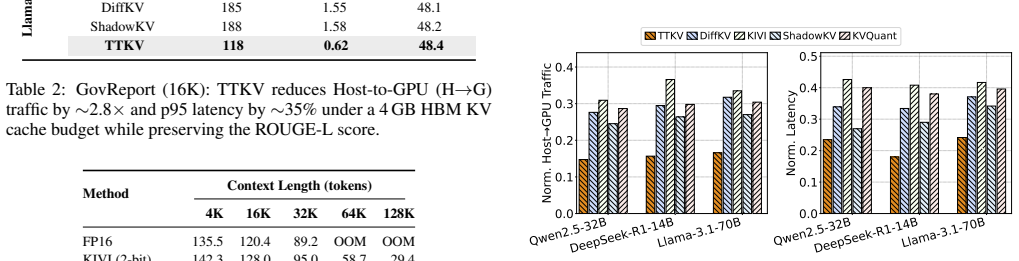
- Latency drops up to 76 percent and throughput doubles on 128K tasks without any model retraining.
- Cross-tier data movement falls by 5.94 times, easing pressure on the memory hierarchy.
- The same tier layout can be applied to existing attention kernels with only changes to the cache manager.
Where Pith is reading between the lines
- The same temporal-tier idea could be tested on non-transformer architectures that also maintain growing state caches.
- Dynamic tier promotion based on attention scores rather than strict recency might further reduce traffic in tasks with long-range dependencies.
- Hardware vendors could add dedicated fast tiers sized exactly for the recent-window fraction that TTKV keeps hot.
- Combining TTKV tiering with existing quantization methods could widen the precision gap between tiers without extra accuracy loss.
Load-bearing premise
Placing recent KV states in faster higher-precision tiers while sending older states to slower lower-precision tiers keeps model output quality essentially unchanged.
What would settle it
Measure end-task accuracy or perplexity on a 128K-context benchmark before and after switching to TTKV; a drop larger than a few percent would falsify the claim that tiering preserves quality.
Figures


read the original abstract
Key-value (KV) caching is critical for efficient inference in large language models (LLMs), yet its memory footprint scales linearly with context length, resulting in a severe scalability bottleneck. Existing approaches largely treat KV states as equally important across time, implicitly assuming uniform precision and accessibility. However, this assumption contrasts with human memory systems, where memories vary in clarity, recall frequency, and relevance with temporal proximity.Motivated by this insight, we propose TTKV, a KV cache management framework that maps the human memory system onto the KV cache. TTKV partitions the KV cache into temporal tiers with heterogeneous capacity and precision. The design addresses three aspects: (1) Tier Layout, decoupling fast and slow memory using HBM and DRAM; (2) Tier Content, assigning more recent KV states to faster, higher-precision tiers based on temporal proximity; and (3) Tier Interaction, employing block-wise streaming attention to overlap communication and computation when accessing slow tiers. Experiments show that TTKV reduces cross-tier traffic by 5.94x on 128K-context tasks, achieving up to 76% latency reduction and 2x throughput improvement over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TTKV, a KV cache management framework for long-context LLMs that partitions the cache into temporal tiers with heterogeneous capacity and precision. Recent KV states are assigned to faster, higher-precision HBM tiers while older states move to slower, lower-precision DRAM tiers; block-wise streaming attention is used to overlap communication and computation across tiers. Experiments on 128K-context tasks report a 5.94× reduction in cross-tier traffic, up to 76% latency reduction, and 2× throughput improvement over strong baselines.
Significance. If the tiering preserves output quality, the approach could meaningfully alleviate the memory-bandwidth bottleneck in long-context inference by exploiting temporal locality. The reported speedups are substantial and directly address a practical deployment constraint; however, the absence of quality metrics leaves the net utility of the method unclear.
major comments (1)
- [Abstract] Abstract: The performance claims (5.94× cross-tier traffic reduction, 76% latency reduction, 2× throughput) are presented without any accompanying perplexity, accuracy, or task-specific quality metrics. Because attention scores are query-dependent rather than determined solely by temporal recency, the tiering and implied quantization could alter attention distributions and downstream outputs; this omission is load-bearing for the central claim that the method improves efficiency without compromising model behavior.
minor comments (2)
- [Introduction] The motivation section could benefit from explicit citations to prior work on KV cache compression or tiered memory systems to better situate the novelty of the temporal-tiering heuristic.
- [Method] Notation for tier capacities, precision levels, and the streaming attention schedule is introduced without a consolidated table or diagram, making the Tier Layout and Tier Interaction descriptions harder to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for identifying the critical need for quality metrics to substantiate our efficiency claims. We agree this is essential and will revise the manuscript accordingly by adding perplexity, accuracy, and attention-distribution analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims (5.94× cross-tier traffic reduction, 76% latency reduction, 2× throughput) are presented without any accompanying perplexity, accuracy, or task-specific quality metrics. Because attention scores are query-dependent rather than determined solely by temporal recency, the tiering and implied quantization could alter attention distributions and downstream outputs; this omission is load-bearing for the central claim that the method improves efficiency without compromising model behavior.
Authors: We acknowledge the omission of quality metrics in the current version. In the revised manuscript we will add (1) perplexity evaluations on long-context language modeling tasks, (2) accuracy results on LongBench and similar benchmarks, and (3) quantitative comparisons of attention-score distributions before and after tiering/quantization. Our design rationale is that recent tokens (kept at full precision in HBM) dominate attention weights due to temporal decay, while older tokens (moved to lower-precision DRAM) contribute less; however, we will empirically verify this with attention-difference heatmaps and downstream-task ablations to confirm negligible impact on outputs. revision: yes
Circularity Check
No circularity: empirical systems proposal with no derivations
full rationale
The paper proposes TTKV as an engineering framework that partitions KV cache into temporal tiers (HBM/DRAM) and assigns recent states to faster tiers based on a human-memory analogy. All reported results are direct experimental measurements of traffic, latency, and throughput on 128K-context workloads. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The design choices are presented as motivated heuristics validated by benchmarks, not as outputs that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recent KV states should receive higher precision and faster access than older states
Reference graph
Works this paper leans on
-
[1]
LongBench: A bilingual, multitask benchmark for long context understanding
[Baiet al., 2024 ] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Pro- ceedings of the 62nd Annual Meeting of ...
work page 2024
-
[2]
Association for Computational Linguistics. [Grattafioriet al., 2024 ] Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models,
work page 2024
-
[3]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
[Hooperet al., 2025 ] Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. Kvquant: To- wards 10 million context length llm inference with kv cache quantization,
work page 2025
-
[4]
Ruler: What’s the real context size of your long-context language models?,
[Hsiehet al., 2024 ] Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?,
work page 2024
-
[5]
Qwen2.5-coder technical report,
[Huiet al., 2024 ] Binyuan Hui, Jian Yang, Zeyu Cui, Ji- axi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report,
work page 2024
-
[6]
[Jianget al., 2023 ] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth ´ee Lacroix, and William El Sayed. Mistral 7b,
work page 2023
-
[7]
KVPR: Efficient LLM in- ference with I/O-aware KV cache partial recomputation
[Jianget al., 2025 ] Chaoyi Jiang, Lei Gao, Hossein Entezari Zarch, and Murali Annavaram. KVPR: Efficient LLM in- ference with I/O-aware KV cache partial recomputation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Asso- ciation for Computational Linguistics: ACL 2025, pages 19474–19488, Vienna, Au...
work page 2025
-
[8]
[Jianget al., 2026 ] Bo Jiang, Taolue Yang, Youyuan Liu, Xubin He, Sheng Di, and Sian Jin
Association for Computational Linguistics. [Jianget al., 2026 ] Bo Jiang, Taolue Yang, Youyuan Liu, Xubin He, Sheng Di, and Sian Jin. Packkv: Reducing kv cache memory footprint through llm-aware lossy com- pression,
work page 2026
-
[9]
Reformer: The efficient transformer,
[Kitaevet al., 2020 ] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer,
work page 2020
-
[10]
Cachegen: Kv cache compression and streaming for fast large language model serving
[Liuet al., 2024a ] Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference, ACM ...
work page 2024
-
[11]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Associa- tion for Computing Machinery. [Liuet al., 2024b ] Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asym- metric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Freekv: Boosting kv cache retrieval for efficient llm inference,
[Liuet al., 2026 ] Guangda Liu, Chengwei Li, Zhenyu Ning, Jing Lin, Yiwu Yao, Danning Ke, Minyi Guo, and Jieru Zhao. Freekv: Boosting kv cache retrieval for efficient llm inference,
work page 2026
-
[13]
[Sharmaet al., 2025 ] Akshat Sharma, Hangliang Ding, Jian- ping Li, Neel Dani, and Minjia Zhang. MiniKV: Pushing the limits of 2-bit KV cache via compression and system co-design for efficient long context inference. In Wanxi- ang Che, Joyce Nabende, Ekaterina Shutova, and Moham- mad Taher Pilehvar, editors,Findings of the Association for Computational Li...
work page 2025
-
[14]
Association for Com- putational Linguistics. [Shenget al., 2023 ] Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Re, Ion Stoica, and Ce Zhang. Flex- Gen: High-throughput generative inference of large lan- guage models with a single GPU. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engel...
work page 2023
-
[15]
Shadowkv: Kv cache in shadows for high-throughput long-context llm inference,
[Sunet al., 2025 ] Hanshi Sun, Li-Wen Chang, Wenlei Bao, Size Zheng, Ningxin Zheng, Xin Liu, Harry Dong, Yuejie Chi, and Beidi Chen. Shadowkv: Kv cache in shadows for high-throughput long-context llm inference,
work page 2025
-
[16]
Llama 2: Open foundation and fine-tuned chat models,
[Touvronet al., 2023 ] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Can- ton Ferrer, Moya Chen, Guillem Cucurull, et al. Llama 2: Open foundation and fine-tuned chat models,
work page 2023
-
[17]
Leave no document behind: Benchmarking long-context LLMs with extended multi-doc QA
[Wanget al., 2024 ] Minzheng Wang, Longze Chen, Fu Cheng, Shengyi Liao, Xinghua Zhang, Bingli Wu, Haiyang Yu, Nan Xu, Lei Zhang, Run Luo, Yunshui Li, Min Yang, Fei Huang, and Yongbin Li. Leave no document behind: Benchmarking long-context LLMs with extended multi-doc QA. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024...
work page 2024
-
[18]
Association for Computational Linguistics. [Wanget al., 2025 ] Dongwei Wang, Zijie Liu, Song Wang, Yuxin Ren, Jianing Deng, Jingtong Hu, Tianlong Chen, and Huanrui Yang. Fier: Fine-grained and efficient kv cache retrieval for long-context llm inference,
work page 2025
-
[19]
Efficient streaming language models with attention sinks,
[Xiaoet al., 2024 ] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks,
work page 2024
-
[20]
H 2o: Heavy-hitter oracle for efficient generative inference of large language models,
[Zhanget al., 2023 ] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R ´e, Clark Barrett, Zhangyang Wang, and Beidi Chen. H 2o: Heavy-hitter oracle for efficient generative inference of large language models,
work page 2023
-
[21]
[Zhanget al., 2025 ] Yanqi Zhang, Yuwei Hu, Runyuan Zhao, John C. S. Lui, and Haibo Chen. Diffkv: Differ- entiated memory management for large language models with parallel kv compaction,
work page 2025
-
[22]
ProcessBench: Identify- ing process errors in mathematical reasoning
[Zhenget al., 2025 ] Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. ProcessBench: Identify- ing process errors in mathematical reasoning. In Wanxi- ang Che, Joyce Nabende, Ekaterina Shutova, and Moham- mad Taher Pilehvar, editors,Proceedings of the 63rd An- nual Meeting of the Associ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.