Recognition: unknown
Environmental Understanding Vision-Language Model for Embodied Agent
Pith reviewed 2026-05-10 03:34 UTC · model grok-4.3
The pith
Fine-tuning vision-language models on four environmental skills plus recovery steps raises embodied agent success rates by 8.86 percent on ALFRED tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
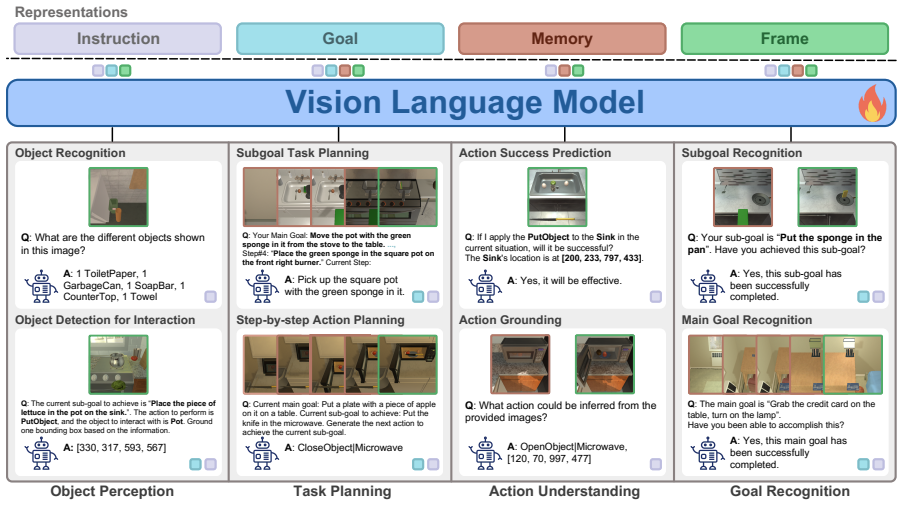
We propose the Environmental Understanding Embodied Agent (EUEA) framework that fine-tunes VLMs on four core skills: object perception for identifying relevant objects, task planning for generating interaction subgoals, action understanding for judging success likelihood, and goal recognition for determining goal completion. By incorporating a recovery step that samples alternative actions to correct failures and a group relative policy optimization (GRPO) stage to refine inconsistent predictions, the model achieves an 8.86% improvement in average success rate over a behavior-cloning baseline on ALFRED tasks, with an additional 3.03% gain from the recovery and GRPO stages.
What carries the argument
The EUEA framework consisting of four fine-tuned skills (object perception, task planning, action understanding, goal recognition), a recovery step that samples alternative actions, and a GRPO stage that refines inconsistent predictions.
If this is right
- The VLM executes instruction-following tasks more reliably across ALFRED benchmarks.
- The recovery step corrects failure cases by sampling alternative actions.
- The GRPO stage reduces inconsistent skill predictions and adds further performance gains.
- Skill-level analysis reveals specific limitations in closed- and open-source VLMs for agent-environment interaction.
Where Pith is reading between the lines
- The same four-skill fine-tuning pattern could be tested in other embodied simulation suites to check whether the gains transfer.
- Emphasizing targeted environmental skills might lower the volume of behavior-cloning data needed to train capable agents.
- Combining these skills with additional sensing modalities could address remaining failure modes in more complex settings.
Load-bearing premise
That fine-tuning the four core skills together with the recovery step and GRPO stage will produce reliable task execution without continued reliance on environment metadata or external supervision.
What would settle it
Running the trained model in new test environments where it still fails on interactions or requires environment metadata would falsify the claim of reliable execution.
Figures



read the original abstract
Vision-language models (VLMs) have shown strong perception and reasoning abilities for instruction-following embodied agents. However, despite these abilities and their generalization performance, they still face limitations in environmental understanding, often failing on interactions or relying on environment metadata during execution. To address this challenge, we propose a novel framework named Environmental Understanding Embodied Agent (EUEA), which fine-tunes four core skills: 1) object perception for identifying relevant objects, 2) task planning for generating interaction subgoals, 3) action understanding for judging success likelihood, and 4) goal recognition for determining goal completion. By fine-tuning VLMs with EUEA skills, our framework enables more reliable task execution for instruction-following. We further introduce a recovery step that leverages these core skills and a group relative policy optimization (GRPO) stage that refines inconsistent skill predictions. The recovery step samples alternative actions to correct failure cases, and the GRPO stage refines inconsistent skill predictions. Across ALFRED tasks, our VLM significantly outperforms a behavior-cloning baseline, achieving an 8.86% improvement in average success rate. The recovery and GRPO stages provide an additional 3.03% gain, further enhancing overall performance. Finally, our skill-level analyses reveal key limitations in the environmental understanding of closed- and open-source VLMs and identify the capabilities necessary for effective agent-environment interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Environmental Understanding Embodied Agent (EUEA) framework, which fine-tunes a VLM on four core skills (object perception, task planning, action understanding, goal recognition) plus a recovery step and GRPO stage to improve environmental understanding and reduce reliance on metadata for instruction-following embodied agents. On ALFRED tasks the approach reports an 8.86% average success-rate gain over a behavior-cloning baseline, with an additional 3.03% from recovery/GRPO; skill-level analyses are also presented.
Significance. If the empirical claims hold after clarification, the work would demonstrate that targeted skill fine-tuning plus recovery/GRPO can measurably improve VLM-based embodied performance on ALFRED. The skill analyses could usefully expose VLM limitations for agent-environment interaction. No machine-checked proofs or parameter-free derivations are present, but the framework is directly falsifiable via the reported benchmark numbers.
major comments (2)
- [Abstract] Abstract: the headline claim of an 8.86% + 3.03% success-rate improvement is presented without any information on training-set size, exact fine-tuning procedure, number of runs, or statistical significance. This information is load-bearing for interpreting the central empirical result.
- [Evaluation setup (ALFRED experiments)] Evaluation setup (ALFRED experiments): the manuscript does not explicitly state whether VLM inference receives only raw visual observations and language instructions or still receives ALFRED-provided object positions, states, or scene graphs. If metadata remains available at test time, the measured gains cannot be attributed to learned environmental understanding, directly undermining the paper's motivating claim.
minor comments (2)
- [Abstract] Abstract: the recovery step and GRPO stage are described twice in consecutive sentences; a single concise statement would improve readability.
- [Abstract] The abstract mentions 'skill-level analyses' but does not indicate where these results appear or how they are quantified (e.g., per-skill accuracy tables).
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of an 8.86% + 3.03% success-rate improvement is presented without any information on training-set size, exact fine-tuning procedure, number of runs, or statistical significance. This information is load-bearing for interpreting the central empirical result.
Authors: We agree these details are essential. The revised abstract now specifies the ALFRED training split size used for fine-tuning, the exact fine-tuning procedure (including LoRA rank and learning rate), the number of independent runs performed with reported means and standard deviations, and a note on statistical significance via paired t-tests. These elements have also been expanded in the methods and experiments sections. revision: yes
-
Referee: [Evaluation setup (ALFRED experiments)] Evaluation setup (ALFRED experiments): the manuscript does not explicitly state whether VLM inference receives only raw visual observations and language instructions or still receives ALFRED-provided object positions, states, or scene graphs. If metadata remains available at test time, the measured gains cannot be attributed to learned environmental understanding, directly undermining the paper's motivating claim.
Authors: We thank the referee for identifying this ambiguity. Our framework performs VLM inference using only raw visual observations and language instructions, with no ALFRED-provided metadata (object positions, states, or scene graphs) at test time. This design directly supports the claim of learned environmental understanding. We have added an explicit statement to this effect in the Evaluation Setup section of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark results with no derivation chain
full rationale
The paper presents an empirical framework for fine-tuning VLMs on four skills plus recovery and GRPO stages, then reports direct success-rate improvements on ALFRED tasks (8.86% + 3.03%). No equations, functional forms, predictions, or first-principles derivations appear in the abstract or described content. All performance claims are measured outcomes from experiments rather than quantities constructed from fitted inputs or self-citations. The central claims therefore remain independent of the input data by construction and receive no circularity penalty.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-tuning VLMs on object perception, task planning, action understanding, and goal recognition produces reliable instruction-following behavior.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebo- tar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
A persistent spatial semantic representation for high-level natural language instruction execution
Valts Blukis, Chris Paxton, Dieter Fox, Animesh Garg, and Yoav Artzi. A persistent spatial semantic representation for high-level natural language instruction execution. InCon- ference on Robot Learning, pages 706–717. PMLR, 2022. 2
2022
-
[6]
Object goal navigation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems, 33:4247–4258, 2020
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhi- nav Gupta, and Russ R Salakhutdinov. Object goal navigation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems, 33:4247–4258, 2020. 2
2020
-
[7]
William Chen, Suneel Belkhale, Suvir Mirchandani, Oier Mees, Danny Driess, Karl Pertsch, and Sergey Levine. Train- ing strategies for efficient embodied reasoning.arXiv preprint arXiv:2505.08243, 2025. 1
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 1, 5, 6, 7
work page internal anchor Pith review arXiv 2024
-
[9]
Lota-bench: Benchmarking language- oriented task planners for embodied agents
Jae-Woo Choi, Youngwoo Yoon, Hyobin Ong, Jaehong Kim, and Minsu Jang. Lota-bench: Benchmarking language- oriented task planners for embodied agents. InInternational Conference on Learning Representations (ICLR), 2024. 2
2024
-
[10]
arXiv preprint arXiv:2410.00371 , year=
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation. arXiv preprint arXiv:2410.00371, 2024. 1, 2, 3, 7
-
[11]
Prompter: Utilizing large language model prompt- ing for a data efficient embodied instruction following.arXiv,
Inoue et al. Prompter: Utilizing large language model prompt- ing for a data efficient embodied instruction following.arXiv,
-
[12]
Epo: Hierarchical llm agents with environment preference optimization.EMNLP, 2024
Zhao et al. Epo: Hierarchical llm agents with environment preference optimization.EMNLP, 2024. 1
2024
-
[13]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group- in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[14]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
-
[15]
Are you looking? ground- ing to multiple modalities in vision-and-language navigation
Ronghang Hu, Daniel Fried, Anna Rohrbach, Dan Klein, Trevor Darrell, and Kate Saenko. Are you looking? ground- ing to multiple modalities in vision-and-language navigation. arXiv preprint arXiv:1906.00347, 2019. 2
-
[16]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mor- datch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR,
-
[17]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Gal- liker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
2025
-
[18]
EQA-MX: Embodied question answering using multi- modal expression
Md Mofijul Islam, Alexi Gladstone, Riashat Islam, and Tariq Iqbal. EQA-MX: Embodied question answering using multi- modal expression. InThe Twelfth International Conference on Learning Representations, 2024. 3
2024
-
[19]
Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134,
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134,
-
[20]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474,
work page internal anchor Pith review arXiv
-
[21]
End-to-end training of deep visuomotor policies
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research, 17(39):1–40, 2016. 1
2016
-
[22]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chun- yuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024. 1, 6
work page internal anchor Pith review arXiv 2024
-
[23]
Embodied agent interface: Bench- marking llms for embodied decision making.Advances in Neural Information Processing Systems, 37:100428–100534,
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Erran Li 9 Li, Ruohan Zhang, et al. Embodied agent interface: Bench- marking llms for embodied decision making.Advances in Neural Information Processing Systems, 37:100428–100534,
-
[24]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Haus- man, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. arXiv preprint arXiv:2209.07753, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[25]
V olumetric envi- ronment representation for vision-language navigation
Rui Liu, Wenguan Wang, and Yi Yang. V olumetric envi- ronment representation for vision-language navigation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16317–16328, 2024. 2
2024
-
[26]
Openeqa: Embodied question answering in the era of foundation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mc- vay, Oleksandr Maksymets, Sergio Arnaud, Karmesh Yadav, Qiyang Li, Ben Newman, Mohit Sharma, Vincent Berges, Shiqi Zhang, Pulkit Agrawal, Yonatan Bisk, Dhruv Batra, Mri- nal Kalakrishnan, Franziska Meier, Chris Paxton, Alexander Sax, and Arav...
2024
-
[27]
Georgios Pantazopoulos, Malvina Nikandrou, Amit Parekh, Bhathiya Hemanthage, Arash Eshghi, Ioannis Konstas, Ver- ena Rieser, Oliver Lemon, and Alessandro Suglia. Multitask multimodal prompted training for interactive embodied task completion.arXiv preprint arXiv:2311.04067, 2023. 2
-
[28]
Sentence-bert: Sentence embeddings using siamese bert-networks, 2019
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks, 2019. 5, 6, 8
2019
-
[29]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 1, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural In- formation Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural In- formation Processing Systems, 36:8634–8652, 2023. 1, 2, 7
2023
-
[31]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020. 2, 4, 5, 6
2020
-
[32]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020. 5, 7
work page internal anchor Pith review arXiv 2010
-
[33]
Llm-planner: Few-shot grounded planning for embodied agents with large language models
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 2998–3009, 2023. 2
2023
-
[34]
Adaplanner: Adaptive planning from feedback with language models.Advances in neural information pro- cessing systems, 36:58202–58245, 2023
Haotian Sun, Yuchen Zhuang, Lingkai Kong, Bo Dai, and Chao Zhang. Adaplanner: Adaptive planning from feedback with language models.Advances in neural information pro- cessing systems, 36:58202–58245, 2023. 1, 3, 7
2023
-
[35]
Habitat 2.0: Training home assistants to rearrange their habitat.Advances in neural information processing systems, 34:251–266, 2021
Andrew Szot, Alexander Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Singh Chaplot, Oleksandr Maksymets, et al. Habitat 2.0: Training home assistants to rearrange their habitat.Advances in neural information processing systems, 34:251–266, 2021. 4
2021
-
[36]
Large language models as generalizable policies for embodied tasks
Andrew Szot, Max Schwarzer, Harsh Agrawal, Bogdan Ma- zoure, Rin Metcalf, Walter Talbott, Natalie Mackraz, R Devon Hjelm, and Alexander T Toshev. Large language models as generalizable policies for embodied tasks. InThe Twelfth International Conference on Learning Representations, 2023. 1, 2, 4, 5, 6, 7
2023
-
[37]
Grounding multi- modal large language models in actions.Advances in Neural Information Processing Systems, 37:20198–20224, 2024
Andrew Szot, Bogdan Mazoure, Harsh Agrawal, R Devon Hjelm, Zsolt Kira, and Alexander Toshev. Grounding multi- modal large language models in actions.Advances in Neural Information Processing Systems, 37:20198–20224, 2024
2024
-
[38]
From multimodal llms to generalist embodied agents: Methods and lessons
Andrew Szot, Bogdan Mazoure, Omar Attia, Aleksei Tim- ofeev, Harsh Agrawal, Devon Hjelm, Zhe Gan, Zsolt Kira, and Alexander Toshev. From multimodal llms to generalist embodied agents: Methods and lessons. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10644–10655, 2025. 1
2025
-
[39]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[40]
Hanlin Wang, Chak Tou Leong, Jian Wang, and Wenjie Li. E2cl: exploration-based error correction learning for embod- ied agents.arXiv preprint arXiv:2409.03256, 2024. 3, 7
-
[41]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai, 2023
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, Xihui Liu, Cewu Lu, Dahua Lin, and Jiangmiao Pang. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai, 2023. 3
2023
-
[42]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents.arXiv preprint arXiv:2502.09560, 2025. 2, 7
-
[43]
Embodied multi-modal agent trained by an llm from a parallel textworld
Yijun Yang, Tianyi Zhou, Kanxue Li, Dapeng Tao, Lusong Li, Li Shen, Xiaodong He, Jing Jiang, and Yuhui Shi. Embodied multi-modal agent trained by an llm from a parallel textworld. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26275–26285, 2024. 1, 5, 6, 7
2024
-
[44]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. 7
2023
-
[45]
Exploratory retrieval-augmented planning for continual em- bodied instruction following.Advances in Neural Information Processing Systems, 37:67034–67060, 2025
Minjong Yoo, Jinwoo Jang, Wei-Jin Park, and Honguk Woo. Exploratory retrieval-augmented planning for continual em- bodied instruction following.Advances in Neural Information Processing Systems, 37:67034–67060, 2025. 2
2025
-
[46]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforce- 10 ment learning system at scale, 2025.URL https://arxiv. org/abs/2503.14476, 2025. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Mfe-etp: A com- prehensive evaluation benchmark for multi-modal foundation models on embodied task planning, 2024
Min Zhang, Xian Fu, Jianye Hao, Peilong Han, Hao Zhang, Lei Shi, Hongyao Tang, and Yan Zheng. Mfe-etp: A com- prehensive evaluation benchmark for multi-modal foundation models on embodied task planning, 2024. 3
2024
-
[48]
Yichi Zhang and Joyce Chai. Hierarchical task learning from language instructions with unified transformers and self- monitoring.arXiv preprint arXiv:2106.03427, 2021. 2
-
[49]
Danli: Deliberative agent for following natural lan- guage instructions
Yichi Zhang, Jianing Yang, Jiayi Pan, Shane Storks, Nikhil Devraj, Ziqiao Ma, Keunwoo Yu, Yuwei Bao, and Joyce Chai. Danli: Deliberative agent for following natural lan- guage instructions. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1280–1298, 2022. 2
2022
-
[50]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafac- tory: Unified efficient fine-tuning of 100+ language models. arXiv preprint arXiv:2403.13372, 2024. 5
work page internal anchor Pith review arXiv 2024
-
[51]
Embodied understanding of driving scenarios
Yunsong Zhou, Linyan Huang, Qingwen Bu, Jia Zeng, Tianyu Li, Hang Qiu, Hongzi Zhu, Minyi Guo, Yu Qiao, and Hongyang Li. Embodied understanding of driving scenarios. InEuropean Conference on Computer Vision, pages 129–148. Springer, 2024. 2
2024
-
[52]
Vision-language navigation with self-supervised auxiliary rea- soning tasks
Fengda Zhu, Yi Zhu, Xiaojun Chang, and Xiaodan Liang. Vision-language navigation with self-supervised auxiliary rea- soning tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10012–10022,
-
[53]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 1, 5, 6 11
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.