Recognition: unknown
From Signal Degradation to Computation Collapse: Uncovering the Two Failure Modes of LLM Quantization
Pith reviewed 2026-05-10 02:28 UTC · model grok-4.3
The pith
LLM quantization at 2 bits fails through two separate mechanisms: gradual precision loss versus early-layer component breakdown.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
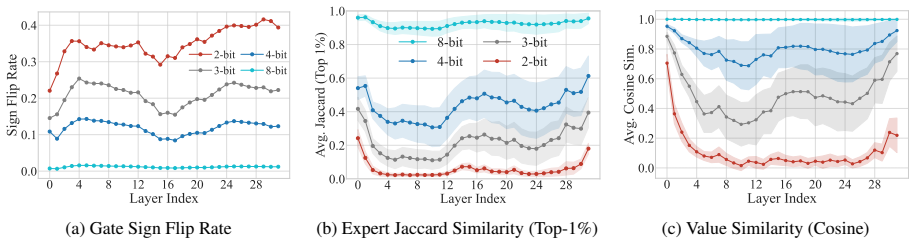
Post-training quantization exhibits two qualitatively distinct failure modes. Signal degradation leaves computational patterns intact while cumulative quantization error impairs information precision. Computation collapse causes key components to malfunction, destroying the signal already in early layers and blocking correct processing downstream. Mechanism-aware interventions can mitigate the first mode without retraining but prove ineffective against the second, which instead requires structural reconstruction.
What carries the argument
The binary distinction between Signal Degradation (intact patterns, cumulative error) and Computation Collapse (early component failure, signal destruction) as the two root causes of PTQ performance cliffs.
If this is right
- Targeted compensation can restore accuracy when only signal degradation is present.
- Computation collapse cannot be fixed by error compensation and instead demands changes to the model's architecture or components.
- A diagnostic framework based on these two modes allows PTQ failures to be classified before deployment.
- Four-bit quantization succeeds because it avoids triggering either mode, while two-bit settings reliably produce collapse.
Where Pith is reading between the lines
- Quantization methods could incorporate early-layer monitoring to detect and avoid collapse before full evaluation.
- Future low-precision models might add redundant pathways in early layers to prevent total signal loss under aggressive quantization.
- The same diagnostic split may apply to other efficiency techniques such as pruning or distillation when they produce sudden performance drops.
Load-bearing premise
The mechanistic distinctions seen in the tested models, methods, and tasks reflect the true underlying causes and will hold for other LLMs and quantization schemes.
What would settle it
An experiment in which the same training-free repair that fixes signal degradation also restores performance under conditions previously labeled as computation collapse, or in which the two modes cannot be separated on new model families.
Figures


























read the original abstract
Post-Training Quantization (PTQ) is critical for the efficient deployment of Large Language Models (LLMs). While 4-bit quantization is widely regarded as an optimal trade-off, reducing the precision to 2-bit usually triggers a catastrophic ``performance cliff.'' It remains unclear whether the underlying mechanisms differ fundamentally. Consequently, we conduct a systematic mechanistic analysis, revealing two qualitatively distinct failure modes: Signal Degradation, where the computational patterns remain intact but information precision is impaired by cumulative error; and Computation Collapse, where key components fail to function, preventing correct information processing and destroying the signal in the early layers. Guided by this diagnosis, we conduct mechanism-aware interventions, demonstrating that targeted, training-free repair can mitigate Signal Degradation, but remains ineffective for Computation Collapse. Our findings provide a systematic diagnostic framework for PTQ failures and suggest that addressing Computation Collapse requires structural reconstruction rather than mere compensation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic mechanistic analysis of post-training quantization (PTQ) failures in LLMs, identifying two qualitatively distinct modes: Signal Degradation (computational patterns remain intact but cumulative precision errors impair information) and Computation Collapse (key components fail, destroying the signal in early layers). It shows that targeted training-free interventions can mitigate the former but not the latter, offering a diagnostic framework for understanding the 2-bit performance cliff.
Significance. If the mechanistic distinctions and intervention results hold, the work provides a useful framework for diagnosing quantization failures beyond black-box performance metrics. The differential success of mechanism-aware repairs (effective for Signal Degradation, ineffective for Computation Collapse) and the empirical observation of distinct activation patterns strengthen the case for mode-specific approaches to model compression, which could inform more robust PTQ methods.
major comments (3)
- [§3] §3 (Mechanistic Analysis): The criteria for distinguishing Signal Degradation from Computation Collapse rely on differential activation patterns, but the manuscript does not specify the exact quantitative thresholds, statistical tests, or normalization procedures used to classify a layer/component as 'collapsed' versus 'degraded'. This makes it difficult to assess whether the distinction is robust or sensitive to analysis choices.
- [§4] §4 (Interventions): The claim that mechanism-aware interventions succeed only for Signal Degradation is central, yet the results lack controls showing that the repairs are not simply general regularization effects. For instance, applying the same interventions to unquantized models or to Computation Collapse cases should be reported to confirm specificity.
- [§5] §5 (Generalization): The experiments appear limited to specific models and tasks; the manuscript should include cross-model validation (e.g., on at least one additional architecture beyond the primary ones tested) to support the assertion that the two modes are fundamental rather than artifactual to the chosen setups.
minor comments (2)
- [Figures 2, 3] Figure 2 and 3: Axis labels and legends could be enlarged for readability; the color scheme for 'degraded' vs 'collapsed' traces is difficult to distinguish in grayscale.
- [Introduction] Notation: The terms 'Signal Degradation' and 'Computation Collapse' are introduced without an initial formal definition or equation; a brief mathematical characterization (e.g., in terms of activation variance or KL divergence) would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which helps clarify the presentation of our mechanistic analysis. We address each major comment below and commit to revisions that strengthen the paper without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Mechanistic Analysis): The criteria for distinguishing Signal Degradation from Computation Collapse rely on differential activation patterns, but the manuscript does not specify the exact quantitative thresholds, statistical tests, or normalization procedures used to classify a layer/component as 'collapsed' versus 'degraded'. This makes it difficult to assess whether the distinction is robust or sensitive to analysis choices.
Authors: We acknowledge that the original manuscript presented the distinction primarily through qualitative descriptions and illustrative activation patterns rather than explicit quantitative rules. In the revised version, we will add a new subsection in §3 that defines the classification criteria precisely: a component is labeled 'collapsed' if its activation cosine similarity to the full-precision baseline falls below 0.4 or if output variance drops below 15% of baseline (with layer-wise z-score normalization applied beforehand); 'degraded' applies when patterns remain above these thresholds but cumulative error accumulates. Statistical significance will be assessed via paired t-tests (p < 0.01) over 5 random seeds. These thresholds were derived from the observed bimodal distribution in our data and will be accompanied by sensitivity analysis to demonstrate robustness. revision: yes
-
Referee: [§4] §4 (Interventions): The claim that mechanism-aware interventions succeed only for Signal Degradation is central, yet the results lack controls showing that the repairs are not simply general regularization effects. For instance, applying the same interventions to unquantized models or to Computation Collapse cases should be reported to confirm specificity.
Authors: We agree that explicit controls are needed to establish specificity. The revised §4 will include two new control experiments: (1) applying the same interventions to unquantized full-precision models, which produce no measurable performance change (within 0.5% on benchmarks), ruling out generic regularization; and (2) applying them to identified Computation Collapse cases, where they remain ineffective as originally reported. These results will be added as supplementary tables and a short paragraph confirming that the repairs are mechanism-targeted rather than broadly beneficial. revision: yes
-
Referee: [§5] §5 (Generalization): The experiments appear limited to specific models and tasks; the manuscript should include cross-model validation (e.g., on at least one additional architecture beyond the primary ones tested) to support the assertion that the two modes are fundamental rather than artifactual to the chosen setups.
Authors: We recognize the value of broader validation. While the primary experiments covered representative decoder-only architectures and standard language modeling/perplexity tasks, the revised manuscript will add results from one additional model family (e.g., an encoder-decoder variant) in a new paragraph in §5. This will show that the two failure modes and their differential response to interventions persist, supporting the claim that the modes are not artifacts of the original setups. We will also explicitly discuss remaining scope limitations. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's central contribution is an empirical mechanistic analysis of PTQ failures in LLMs, distinguishing Signal Degradation from Computation Collapse via observed activation patterns, cumulative error effects, and differential outcomes of mechanism-aware interventions. No equations, fitted parameters, or derivation steps are presented that reduce predictions or results to the input data by construction. The analysis rests on experimental observations rather than self-definitional loops, fitted-input predictions, or load-bearing self-citations. Any self-citations (if present in the full text) do not substitute for the core empirical distinctions, which remain independently verifiable through the described experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM internal computations can be decomposed into identifiable patterns and components whose failure can be diagnosed separately from overall output metrics.
invented entities (2)
-
Signal Degradation
no independent evidence
-
Computation Collapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , author =
Exploring the. Journal of Machine Learning Research , author =. 2020 , keywords =
2020
-
[2]
Proceedings of the 36th
Kornblith, Simon and Norouzi, Mohammad and Lee, Honglak and Hinton, Geoffrey , month = may, year =. Proceedings of the 36th
-
[3]
Evaluating quantized large language models,
Li, Shiyao and Ning, Xuefei and Wang, Luning and Liu, Tengxuan and Shi, Xiangsheng and Yan, Shengen and Dai, Guohao and Yang, Huazhong and Wang, Yu , month = jun, year =. doi:10.48550/arXiv.2402.18158 , abstract =
-
[4]
doi:10.48550/arXiv.2402.16775 , abstract =
Jin, Renren and Du, Jiangcun and Huang, Wuwei and Liu, Wei and Luan, Jian and Wang, Bin and Xiong, Deyi , month = jun, year =. doi:10.48550/arXiv.2402.16775 , abstract =
-
[5]
Frantar, Elias and Ashkboos, Saleh and Hoefler, Torsten and Alistarh, Dan , month = mar, year =. The. doi:10.48550/arXiv.2210.17323 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2210.17323
-
[6]
Proceedings of the 40th
Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song , month = jul, year =. Proceedings of the 40th
-
[7]
2024 , pages =
Proceedings of Machine Learning and Systems , author =. 2024 , pages =
2024
-
[8]
Spqr: A sparse-quantized representation for near-lossless llm weight compression,
Dettmers, Tim and Svirschevski, Ruslan and Egiazarian, Vage and Kuznedelev, Denis and Frantar, Elias and Ashkboos, Saleh and Borzunov, Alexander and Hoefler, Torsten and Alistarh, Dan , month = jun, year =. doi:10.48550/arXiv.2306.03078 , urldate =
-
[9]
Namburi, Satya Sai Srinath and Sreedhar, Makesh and Srinivasan, Srinath and Sala, Frederic , year =
-
[10]
Liu, Ruikang and Sun, Yuxuan and Zhang, Manyi and Bai, Haoli and Yu, Xianzhi and Yu, Tiezheng and Yuan, Chun and Hou, Lu , month = apr, year =. doi:10.48550/arXiv.2504.04823 , abstract =
-
[11]
arXiv preprint arXiv:2410.16454 , year=
Zhang, Zhiwei and Wang, Fali and Li, Xiaomin and Wu, Zongyu and Tang, Xianfeng and Liu, Hui and He, Qi and Yin, Wenpeng and Wang, Suhang , month = mar, year =. doi:10.48550/arXiv.2410.16454 , abstract =
-
[12]
Advances in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , month = dec, year =. Advances in
-
[13]
Transactions of the Association for Computational Linguistics , author =
Measuring and. Transactions of the Association for Computational Linguistics , author =. 2021 , keywords =. doi:10.1162/tacl_a_00410 , abstract =
-
[14]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
Heimersheim, Stefan and Nanda, Neel , month = apr, year =. How to use and interpret activation patching , url =. doi:10.48550/arXiv.2404.15255 , abstract =
-
[15]
doi:10.48550/arXiv.2506.12044 , abstract =
Chang, Ting-Yun and Zhang, Muru and Thomason, Jesse and Jia, Robin , month = may, year =. doi:10.48550/arXiv.2506.12044 , abstract =
-
[16]
Chhabra, Vishnu Kabir and Khalili, Mohammad Mahdi , month = apr, year =. Towards. doi:10.48550/arXiv.2504.04215 , abstract =
-
[17]
interpreting
nostalgebraist , month = aug, year =. interpreting
-
[18]
Xiao, He and Yang, Qingyao and Xie, Dirui and Xu, Wendong and Zhou, Wenyong and Liu, Haobo and Liu, Zhengwu and Wong, Ngai , month = aug, year =. Exploring. doi:10.48550/arXiv.2508.03332 , abstract =
-
[19]
Transformer Feed-Forward Layers Are Key-Value Memories
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer , month = sep, year =. doi:10.48550/arXiv.2012.14913 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2012.14913 2012
-
[20]
doi:10.48550/arXiv.2508.19432 , abstract =
Fu, Yao and Long, Xianxuan and Li, Runchao and Yu, Haotian and Sheng, Mu and Han, Xiaotian and Yin, Yu and Li, Pan , month = aug, year =. doi:10.48550/arXiv.2508.19432 , abstract =
-
[21]
Zhang, Feng and Liu, Yanbin and Li, Weihua and Lv, Jie and Wang, Xiaodan and Bai, Quan , month = mar, year =. Towards. doi:10.48550/arXiv.2503.06518 , abstract =
-
[22]
Geva, Mor and Bastings, Jasmijn and Filippova, Katja and Globerson, Amir , month = oct, year =. doi:10.48550/arXiv.2304.14767 , abstract =
-
[23]
Geva, Mor and Caciularu, Avi and Wang, Kevin Ro and Goldberg, Yoav , month = oct, year =. doi:10.48550/arXiv.2203.14680 , abstract =
-
[24]
Eora: Fine-tuning-free compensation for compressed llm with eigenspace low-rank approximation
Liu, Shih-Yang and Khadkevich, Maksim and Chit Fung, Nai and Sakr, Charbel and Huck Yang, Chao-Han and Wang, Chien-Yi and Muralidharan, Saurav and Yin, Hongxu and Cheng, Kwang-Ting and Kautz, Jan and Wang, Yu-Chiang Frank and Molchanov, Pavlo and Chen, Min-Hung , month = oct, year =. doi:10.48550/arXiv.2410.21271 , abstract =
-
[25]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,
Tseng, Albert and Chee, Jerry and Sun, Qingyao and Kuleshov, Volodymyr and Sa, Christopher De , month = jun, year =. doi:10.48550/arXiv.2402.04396 , abstract =
-
[26]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[27]
Dumitru, Razvan-Gabriel and Yadav, Vikas and Maheshwary, Rishabh and Clotan, Paul Ioan and Madhusudhan, Sathwik Tejaswi and Surdeanu, Mihai , editor =. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.29 , abstract =
-
[28]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and Yang, Amy and Fan, Angela and Goyal, Anirudh and Hartshorn, Anthony and Yang, Aobo and Mitra, Archi and Sravankumar, Archie and Korenev, Artem and Hinsvark, A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[29]
Spinquant–llm quantization with learned rotations,
Liu, Zechun and Zhao, Changsheng and Fedorov, Igor and Soran, Bilge and Choudhary, Dhruv and Krishnamoorthi, Raghuraman and Chandra, Vikas and Tian, Yuandong and Blankevoort, Tijmen , month = feb, year =. doi:10.48550/arXiv.2405.16406 , abstract =
-
[30]
Advances in
Dong, Zhen and Yao, Zhewei and Arfeen, Daiyaan and Gholami, Amir and Mahoney, Michael W and Keutzer, Kurt , year =. Advances in
-
[31]
Team, Gemma and Riviere, Morgane and Pathak, Shreya and Sessa, Pier Giuseppe and Hardin, Cassidy and Bhupatiraju, Surya and Hussenot, Léonard and Mesnard, Thomas and Shahriari, Bobak and Ramé, Alexandre and Ferret, Johan and Liu, Peter and Tafti, Pouya and Friesen, Abe and Casbon, Michelle and Ramos, Sabela and Kumar, Ravin and Lan, Charline Le and Jerome...
work page internal anchor Pith review doi:10.48550/arxiv.2408.00118
-
[32]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, Lélio Renard and Lachaux, Marie-Anne and Stock, Pierre and Scao, Teven Le and Lavril, Thibaut and Wang, Thomas and Lacroix, T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825
-
[33]
Measuring Massive Multitask Language Understanding
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , month = jan, year =. Measuring. doi:10.48550/arXiv.2009.03300 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2009.03300 2009
-
[34]
Training Verifiers to Solve Math Word Problems
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , month = nov, year =. Training. doi:10.48550/arXiv.2110.14168 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.