Recognition: no theorem link
UniCon3R: Unified Contact-aware 4D Human-Scene Reconstruction from Monocular Video
Pith reviewed 2026-05-12 03:47 UTC · model grok-4.3
The pith
Inferred 4D contact from pose and scene geometry corrects human meshes to eliminate floating and penetration in monocular video reconstructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniCon3R is a unified feed-forward framework for online human-scene 4D reconstruction from monocular video that explicitly infers 4D contact from the human pose and scene geometry and uses the contact as a corrective cue for generating the pose. This enables the model to jointly recover scene geometry and spatially aligned 4D humans within the scene. Experiments on standard human-centric video benchmarks show that UniCon3R outperforms state-of-the-art baselines on physical plausibility and global human motion estimation while preserving fast, feed-forward inference speeds. The results validate the central claim that contact serves as a powerful internal prior for physically grounded joint 4D
What carries the argument
4D contact inference from estimated human pose and scene geometry, used as an online corrective cue to refine the pose estimate and enforce physical alignment.
If this is right
- Human and scene meshes are recovered together in one forward pass with explicit spatial alignment.
- Physical plausibility scores rise on existing human-centric video test sets.
- Global trajectory accuracy improves while inference speed stays unchanged.
- Contact is shown to function as an internal prior sufficient to ground the entire reconstruction.
Where Pith is reading between the lines
- The same contact-correction loop could be tested on multi-person scenes to see whether inter-human contacts also stabilize the output.
- Real-time deployment in mobile AR would become feasible if the feed-forward speed holds under varying lighting and camera motion.
- The approach hints that contact priors might transfer to other interaction tasks such as hand-object reconstruction without retraining the core network.
Load-bearing premise
That contact points estimated from pose and geometry alone supply reliable correction signals that improve reconstruction without creating new artifacts or requiring separate tuning steps.
What would settle it
A video sequence in which adding the contact-based correction step increases measured penetration depth or ground clearance error relative to the identical model run without the contact cue.
Figures


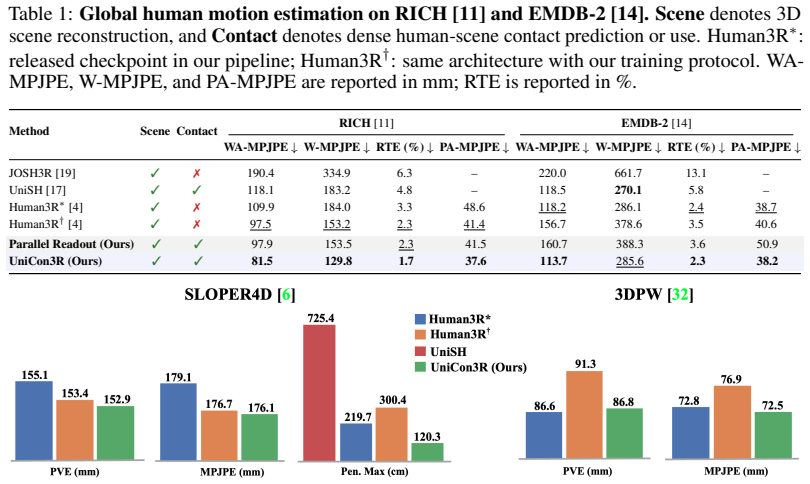




read the original abstract
We introduce UniCon3R, a unified feed-forward framework for online human-scene 4D reconstruction from monocular video. Current feed-forward human-scene reconstruction methods suffer from artifacts, where bodies float above the ground or penetrate parts of the scene. A key reason is the lack of effective interaction modelling between the human and the environment. Our goal is to exploit contact between the human and the scene during inference to actively improve the human mesh reconstruction. To that end, we explicitly model interaction by inferring 4D contact from the human pose and scene geometry and use the contact as a corrective cue for generating the pose. This enables UniCon3R to jointly recover scene geometry and spatially aligned 4D humans within the scene. Experiments on standard human-centric video benchmarks show that UniCon3R outperforms state-of-the-art baselines on physical plausibility and global human motion estimation while preserving fast, feed-forward inference speeds. The results validate our central claim: contact serves as a powerful internal prior, thus establishing a new paradigm for physically grounded joint human-scene reconstruction. Project page is available at https://surtantheta.github.io/UniCon3R .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniCon3R, a unified feed-forward framework for online 4D human-scene reconstruction from monocular video. It explicitly models human-scene interaction by inferring 4D contact from estimated human pose and scene geometry, then uses this contact as a corrective cue during pose generation to reduce artifacts such as floating or penetration. The method jointly recovers scene geometry and spatially aligned 4D humans, with claimed outperformance over baselines on physical plausibility and global motion estimation while preserving fast inference speeds.
Significance. If the contact-based correction proves robust, the work could advance physically grounded joint human-scene reconstruction by establishing contact as an internal prior rather than a post-processing step. The feed-forward design and emphasis on online processing from monocular video represent practical strengths for real-world applications in computer vision.
major comments (2)
- [Abstract] Abstract: The central claim that 'contact serves as a powerful internal prior' rests on inferring 4D contact from human pose and scene geometry to correct pose generation. However, because both pose and geometry are themselves outputs of the monocular pipeline, this creates a potential circular dependency not resolved by the described feed-forward design. No mention is made of an iterative refinement loop, auxiliary supervision, or architectural mechanism (e.g., separate contact prediction head with frozen initial estimates) that would prevent initial estimation errors from contaminating the contact map and amplifying artifacts.
- [Methods] Methods (inferred from abstract description): The claim of using contact 'as a corrective cue for generating the pose' requires explicit evidence that the contact inference does not simply propagate noise from the initial pose/scene estimates. Without details on the network architecture, loss terms, or training procedure that decouples these quantities, the improvement in physical plausibility cannot be attributed to the contact prior rather than other unstated factors.
minor comments (2)
- [Abstract] Abstract: The statement that UniCon3R 'outperforms state-of-the-art baselines' lacks any quantitative metrics, error bars, or ablation results, making it difficult to assess the magnitude or reliability of the claimed gains in physical plausibility and motion estimation.
- The manuscript would benefit from a clear statement on code and model release to support reproducibility of the feed-forward pipeline.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive comments. We address the concerns regarding potential circular dependency and the need for explicit architectural and training details below. We will revise the manuscript to improve clarity on these points while preserving the feed-forward nature of the approach.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'contact serves as a powerful internal prior' rests on inferring 4D contact from human pose and scene geometry to correct pose generation. However, because both pose and geometry are themselves outputs of the monocular pipeline, this creates a potential circular dependency not resolved by the described feed-forward design. No mention is made of an iterative refinement loop, auxiliary supervision, or architectural mechanism (e.g., separate contact prediction head with frozen initial estimates) that would prevent initial estimation errors from contaminating the contact map and amplifying artifacts.
Authors: We agree the abstract is brief and does not detail the decoupling mechanisms. The full manuscript (Section 3) describes a dedicated contact inference module that receives initial pose and geometry features but is trained with auxiliary supervision on contact labels obtained from external 4D datasets and rendered contact maps. The final pose is generated by a separate corrective head that fuses the contact cue; end-to-end training with a contact-consistency loss encourages the network to learn corrections rather than propagate errors. This is not iterative but relies on the learned prior. We will revise the abstract to briefly note the separate contact head and auxiliary supervision. revision: yes
-
Referee: [Methods] Methods (inferred from abstract description): The claim of using contact 'as a corrective cue for generating the pose' requires explicit evidence that the contact inference does not simply propagate noise from the initial pose/scene estimates. Without details on the network architecture, loss terms, or training procedure that decouples these quantities, the improvement in physical plausibility cannot be attributed to the contact prior rather than other unstated factors.
Authors: The full paper provides these details in Section 3.2 and Figure 2: separate encoders produce initial pose and scene features; a contact prediction head is pre-trained on synthetic contact supervision before joint fine-tuning; the corrective pose module uses a contact-aware loss that penalizes penetrations and floating based on the inferred contact. Staged training (contact module first, then end-to-end) and the explicit contact loss term help decouple the quantities. Ablations in the paper show that removing the contact cue degrades physical plausibility, supporting attribution to the prior. We will expand the methods section with additional pseudocode and a noise-robustness discussion to make this explicit. revision: partial
Circularity Check
No circularity; derivation remains self-contained
full rationale
The provided abstract and description present a feed-forward network that infers 4D contact from estimated pose and scene geometry, then applies it as a corrective cue during pose generation. No equations, self-citations, or fitted-parameter renamings are quoted that would reduce the contact prior or final reconstruction to a tautological re-expression of the inputs. The central claim is validated against external benchmarks rather than by internal redefinition, satisfying the requirement for independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-hmr: Multi-person whole-body human mesh recovery in a single shot
Fabien Baradel, Matthieu Armando, Salma Galaaoui, Romain Brégier, Philippe Weinzaepfel, Grégory Rogez, and Thomas Lucas. Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. InProc. of the European Conf. on Computer Vision (ECCV), 2024
work page 2024
-
[2]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. InEuropean conference on computer vision, pages 561–578. Springer, 2016
work page 2016
-
[3]
Zhongang Cai, Wanqi Yin, Ailing Zeng, Chen Wei, Qingping Sun, Wang Yanjun, Hui En Pang, Haiyi Mei, Mingyuan Zhang, Lei Zhang, et al. Smpler-x: Scaling up expressive human pose and shape estimation.Advances in Neural Information Processing Systems, 36:11454–11468, 2023
work page 2023
-
[4]
Human3r: Everyone everywhere all at once
Yue Chen, Xingyu Chen, Yuxuan Xue, Anpei Chen, Yuliang Xiu, and Gerard Pons-Moll. Human3r: Everyone everywhere all at once. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[5]
Pico: Reconstructing 3d people in contact with objects
Alpár Cseke, Shashank Tripathi, Sai Kumar Dwivedi, Arjun S Lakshmipathy, Agniv Chatterjee, Michael J Black, and Dimitrios Tzionas. Pico: Reconstructing 3d people in contact with objects. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1783–1794, 2025
work page 2025
-
[6]
Sloper4d: A scene-aware dataset for global 4d human pose estimation in urban environments
Yudi Dai, YiTai Lin, XiPing Lin, Chenglu Wen, Lan Xu, Hongwei Yi, Siqi Shen, Yuexin Ma, and Cheng Wang. Sloper4d: A scene-aware dataset for global 4d human pose estimation in urban environments. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 682–692, 2023
work page 2023
-
[7]
Tokenhmr: Advancing human mesh recovery with a tokenized pose representation
Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Yao Feng, and Michael J Black. Tokenhmr: Advancing human mesh recovery with a tokenized pose representation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1323–1333, 2024. 12
work page 2024
-
[8]
Interactvlm: 3d interaction reasoning from 2d foun- dational models
Sai Kumar Dwivedi, Dimitrije Anti ´c, Shashank Tripathi, Omid Taheri, Cordelia Schmid, Michael J Black, and Dimitrios Tzionas. Interactvlm: 3d interaction reasoning from 2d foun- dational models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22605–22615, 2025
work page 2025
-
[9]
Humans in 4d: Reconstructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Reconstructing and tracking humans with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023
work page 2023
-
[10]
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. InProceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017
work page 2017
-
[11]
Capturing and inferring dense full-body human-scene contact
Chun-Hao P Huang, Hongwei Yi, Markus Höschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J Black. Capturing and inferring dense full-body human-scene contact. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13274–13285, 2022
work page 2022
-
[12]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InEuropean conference on computer vision, pages 709–727. Springer, 2022
work page 2022
-
[13]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7122–7131, 2018
work page 2018
-
[14]
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Manuel Kaufmann, Jie Song, Chen Guo, Kaiyue Shen, Tianjian Jiang, Chengcheng Tang, Juan José Zárate, and Otmar Hilliges. EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. InInternational Conference on Computer Vision (ICCV), 2023
work page 2023
-
[15]
Pace: Human and camera motion estimation from in- the-wild videos
Muhammed Kocabas, Ye Yuan, Pavlo Molchanov, Yunrong Guo, Michael J Black, Otmar Hilliges, Jan Kautz, and Umar Iqbal. Pace: Human and camera motion estimation from in- the-wild videos. In2024 International Conference on 3D Vision (3DV), pages 397–408. IEEE, 2024
work page 2024
-
[16]
Coin: Control-inpainting diffusion prior for human and camera motion estimation
Jiefeng Li, Ye Yuan, Davis Rempe, Haotian Zhang, Pavlo Molchanov, Cewu Lu, Jan Kautz, and Umar Iqbal. Coin: Control-inpainting diffusion prior for human and camera motion estimation. InEuropean Conference on Computer Vision, pages 426–446. Springer, 2024
work page 2024
-
[17]
Unish: Unifying scene and human reconstruction in a feed-forward pass
Mengfei Li, Peng Li, Zheng Zhang, Jiahao Lu, Chengfeng Zhao, Wei Xue, Qifeng Liu, Sida Peng, Wenxiao Zhang, Wenhan Luo, et al. Unish: Unifying scene and human reconstruction in a feed-forward pass. InConference on Computer Vision and Pattern Recognition (CVPR), 2026
work page 2026
-
[18]
Cliff: Carrying location information in full frames into human pose and shape estimation
Zhihao Li, Jianzhuang Liu, Zhensong Zhang, Songcen Xu, and Youliang Yan. Cliff: Carrying location information in full frames into human pose and shape estimation. InEuropean Conference on Computer Vision, pages 590–606. Springer, 2022
work page 2022
-
[19]
Joint optimization for 4d human-scene reconstruction in the wild
Zhizheng Liu, Joe Lin, Wayne Wu, and Bolei Zhou. Joint optimization for 4d human-scene reconstruction in the wild. InThe Fourteenth International Conference on Learning Represen- tations, 2025
work page 2025
-
[20]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
work page 2023
-
[21]
Reconstructing people, places, and cameras
Lea Müller, Hongsuk Choi, Anthony Zhang, Brent Yi, Jitendra Malik, and Angjoo Kanazawa. Reconstructing people, places, and cameras. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21948–21958, 2025
work page 2025
-
[22]
Camerahmr: Aligning people with perspective
Priyanka Patel and Michael J Black. Camerahmr: Aligning people with perspective. InProc. of the International Conf. on 3D Vision (3DV), 2025. 13
work page 2025
-
[23]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019
work page 2019
-
[24]
The one where they reconstructed 3d humans and environments in tv shows
Georgios Pavlakos, Ethan Weber, Matthew Tancik, and Angjoo Kanazawa. The one where they reconstructed 3d humans and environments in tv shows. InEuropean Conference on Computer Vision, pages 732–749. Springer, 2022
work page 2022
-
[25]
Hamst3r: Human-aware multi-view stereo 3d reconstruction.arXiv preprint arXiv:2508.16433, 2025
Sara Rojas, Matthieu Armando, Bernard Ghamen, Philippe Weinzaepfel, Vincent Leroy, and Gregory Rogez. Hamst3r: Human-aware multi-view stereo 3d reconstruction.arXiv preprint arXiv:2508.16433, 2025
-
[26]
Wham: Reconstructing world- grounded humans with accurate 3d motion
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J Black. Wham: Reconstructing world- grounded humans with accurate 3d motion. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[27]
Putting people in their place: Monocular regression of 3d people in depth
Yu Sun, Wu Liu, Qian Bao, Yili Fu, Tao Mei, and Michael J Black. Putting people in their place: Monocular regression of 3d people in depth. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13243–13252, 2022
work page 2022
-
[28]
Deco: Dense estimation of 3d human-scene contact in the wild
Shashank Tripathi, Agniv Chatterjee, Jean-Claude Passy, Hongwei Yi, Dimitrios Tzionas, and Michael J Black. Deco: Dense estimation of 3d human-scene contact in the wild. InProceedings of the IEEE/CVF international conference on computer vision, pages 8001–8013, 2023
work page 2023
-
[29]
Shashank Tripathi, Lea Müller, Chun-Hao P. Huang, Taheri Omid, Michael J. Black, and Dimitrios Tzionas. 3D human pose estimation via intuitive physics. InConference on Computer Vision and Pattern Recognition (CVPR), pages 4713–4725, 2023. URL https://ipman.is. tue.mpg.de
work page 2023
-
[30]
Humos: Human motion model conditioned on body shape
Shashank Tripathi, Omid Taheri, Christoph Lassner, Michael Black, Daniel Holden, and Carsten Stoll. Humos: Human motion model conditioned on body shape. InEuropean Conference on Computer Vision, pages 133–152. Springer, 2024
work page 2024
-
[31]
Contact-aware retargeting of skinned motion
Ruben Villegas, Duygu Ceylan, Aaron Hertzmann, Jimei Yang, and Jun Saito. Contact-aware retargeting of skinned motion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9720–9729, 2021
work page 2021
-
[32]
Recovering accurate 3d human pose in the wild using imus and a moving camera
Timo V on Marcard, Roberto Henschel, Michael J Black, Bodo Rosenhahn, and Gerard Pons- Moll. Recovering accurate 3d human pose in the wild using imus and a moving camera. In Proceedings of the European conference on computer vision (ECCV), pages 601–617, 2018
work page 2018
-
[33]
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. 2025
work page 2025
-
[34]
Refit: Recurrent fitting network for 3d human recovery
Yufu Wang and Kostas Daniilidis. Refit: Recurrent fitting network for 3d human recovery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14644– 14654, 2023
work page 2023
-
[35]
Tram: Global trajectory and motion of 3d humans from in-the-wild videos
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. Tram: Global trajectory and motion of 3d humans from in-the-wild videos. InProc. of the European Conf. on Computer Vision (ECCV), 2024
work page 2024
-
[36]
Holistic 3d human and scene mesh estimation from single view images
Zhenzhen Weng and Serena Yeung. Holistic 3d human and scene mesh estimation from single view images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 334–343, 2021
work page 2021
-
[37]
Xiangyu Xu, Lijuan Liu, and Shuicheng Yan. Smpler: Taming transformers for monocular 3d human shape and pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3275–3289, 2023
work page 2023
-
[38]
Hsr: holistic 3d human-scene reconstruction from monocular videos
Lixin Xue, Chen Guo, Chengwei Zheng, Fangjinghua Wang, Tianjian Jiang, Hsuan-I Ho, Manuel Kaufmann, Jie Song, and Otmar Hilliges. Hsr: holistic 3d human-scene reconstruction from monocular videos. InEuropean Conference on Computer Vision, pages 429–448. Springer, 2024. 14
work page 2024
-
[39]
Physic: Physically plausible 3d human-scene interaction and contact from a single image
Pradyumna Yalandur Muralidhar, Yuxuan Xue, Xianghui Xie, Margaret Kostyrko, and Gerard Pons-Moll. Physic: Physically plausible 3d human-scene interaction and contact from a single image. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025
work page 2025
-
[40]
Wanqi Yin, Zhongang Cai, Ruisi Wang, Ailing Zeng, Chen Wei, Qingping Sun, Haiyi Mei, Yanjun Wang, Hui En Pang, Mingyuan Zhang, et al. Smplest-x: Ultimate scaling for expressive human pose and shape estimation.arXiv preprint arXiv:2501.09782, 2025
-
[41]
Yiwen Zhao, Ce Zheng, Yufu Wang, Hsueh-Han Daniel Yang, Liting Wen, and Laszlo A. Jeni. Onlinehmr: Video-based online world-grounded human mesh recovery. InCVPR, 2026
work page 2026
-
[42]
Synergistic global-space camera and human reconstruction from videos
Yizhou Zhao, Tuanfeng Yang Wang, Bhiksha Raj, Min Xu, Jimei Yang, and Chun-Hao Paul Huang. Synergistic global-space camera and human reconstruction from videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1216–1226, 2024. 15
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.