Recognition: unknown
Camera Control for Text-to-Image Generation via Learning Viewpoint Tokens
Pith reviewed 2026-05-10 02:51 UTC · model grok-4.3
The pith
Viewpoint tokens learned from mixed 3D and photo data give text-to-image models precise camera control that transfers to new objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
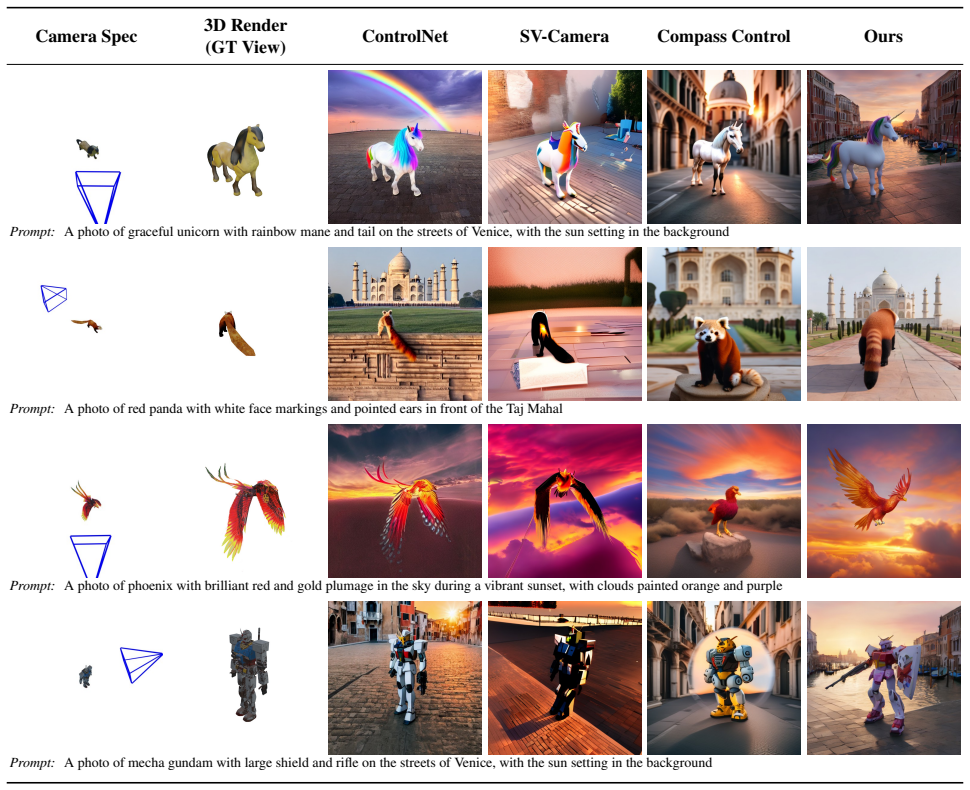
Fine-tuning text-to-image models on viewpoint-conditioned generation using a curated dataset of 3D renders plus photorealistic images produces viewpoint tokens that deliver state-of-the-art camera control accuracy, keep image quality and prompt fidelity intact, and learn factorized geometric representations that transfer to unseen object categories instead of overfitting to appearance correlations.
What carries the argument
Viewpoint tokens: parametric embeddings that encode camera viewpoint parameters and are trained to separate geometric camera information from object appearance and background.
If this is right
- Camera pose can be controlled more accurately than with prior language-only or appearance-tied methods.
- The same tokens work on object categories absent from the training data.
- Text-vision latent spaces acquire explicit 3D camera structure without separate 3D modules.
- Generated images retain original quality and text-prompt alignment while gaining viewpoint control.
Where Pith is reading between the lines
- The same token-learning strategy could be applied to other scene parameters such as focal length or object scale.
- Explicit viewpoint tokens might support generating consistent image sets from multiple specified views.
- Language models could be trained to emit these tokens directly, turning natural descriptions into geometrically precise prompts.
Load-bearing premise
The mixed dataset of 3D-rendered images and photorealistic augmentations is enough to force the tokens to learn factorized geometry rather than spurious object-specific appearance correlations.
What would settle it
Measuring viewpoint control accuracy on a test set of object categories held out from training, and checking whether performance drops or appearance correlations emerge, would show whether the tokens truly factorize geometry.
Figures


















read the original abstract
Current text-to-image models struggle to provide precise camera control using natural language alone. In this work, we present a framework for precise camera control with global scene understanding in text-to-image generation by learning parametric camera tokens. We fine-tune image generation models for viewpoint-conditioned text-to-image generation on a curated dataset that combines 3D-rendered images for geometric supervision and photorealistic augmentations for appearance and background diversity. Qualitative and quantitative experiments demonstrate that our method achieves state-of-the-art accuracy while preserving image quality and prompt fidelity. Unlike prior methods that overfit to object-specific appearance correlations, our viewpoint tokens learn factorized geometric representations that transfer to unseen object categories. Our work shows that text-vision latent spaces can be endowed with explicit 3D camera structure, offering a pathway toward geometrically-aware prompts for text-to-image generation. Project page: https://randdl.github.io/viewtoken_control/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes learning parametric viewpoint tokens to provide precise camera control in text-to-image generation. The core method fine-tunes a pre-trained generative model on a curated dataset that mixes 3D-rendered images (for geometric supervision) with photorealistic augmentations (for appearance and background diversity). Experiments are said to demonstrate state-of-the-art camera-control accuracy while preserving image quality and text-prompt fidelity, with the central claim that the tokens learn factorized geometric representations that transfer to unseen object categories, unlike prior methods that overfit to appearance correlations.
Significance. If the transfer results and factorization hold under scrutiny, the work would offer a practical way to inject explicit 3D camera structure into existing text-to-vision latent spaces without major architectural overhaul. This could improve reliability for viewpoint-specified generation in graphics, design, and simulation pipelines.
major comments (2)
- [§3.2] §3.2 (Training Objective): The fine-tuning loss is described as standard reconstruction plus camera conditioning but contains no auxiliary term, information bottleneck, or adversarial objective to enforce disentanglement of viewpoint tokens from object appearance. This directly bears on the abstract claim that the tokens 'learn factorized geometric representations' rather than spurious correlations from the photorealistic augmentations.
- [§4.3] §4.3 (Transfer Experiments): The reported accuracy gains on unseen object categories are presented without ablations that isolate the contribution of 3D geometric supervision versus the photorealistic data mixture, nor with statistical tests across a broader set of categories. This leaves open whether the transfer stems from true factorization or from dataset curation choices.
minor comments (3)
- [Abstract] Abstract: The phrase 'global scene understanding' is introduced without elaboration; the method appears limited to viewpoint conditioning, so clarifying this distinction would prevent misinterpretation.
- [§2] §2 (Related Work): A short comparison table or explicit contrast with other token-based conditioning approaches (e.g., those using learned embeddings for style or layout) would better position the novelty of viewpoint tokens.
- [Figure 4] Figure 4: The qualitative camera-control examples would be more convincing if they included failure cases or edge-case viewpoints (e.g., extreme elevations) alongside the successful ones.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with honest responses and indicate planned revisions where the manuscript can be improved without misrepresenting our results.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Training Objective): The fine-tuning loss is described as standard reconstruction plus camera conditioning but contains no auxiliary term, information bottleneck, or adversarial objective to enforce disentanglement of viewpoint tokens from object appearance. This directly bears on the abstract claim that the tokens 'learn factorized geometric representations' rather than spurious correlations from the photorealistic augmentations.
Authors: We agree that the loss is standard reconstruction with viewpoint conditioning and includes no explicit auxiliary term to enforce disentanglement. Factorization is not directly imposed by the objective but arises from training on 3D-rendered images (providing geometric supervision) paired with photorealistic augmentations (for appearance diversity), with viewpoint tokens as the sole additional input. The transfer results to unseen categories serve as our primary evidence for factorization. We will revise the abstract, introduction, and method sections to clarify that factorization is empirically demonstrated rather than explicitly enforced by the loss, and we will add a limitations paragraph discussing this design choice. revision: partial
-
Referee: [§4.3] §4.3 (Transfer Experiments): The reported accuracy gains on unseen object categories are presented without ablations that isolate the contribution of 3D geometric supervision versus the photorealistic data mixture, nor with statistical tests across a broader set of categories. This leaves open whether the transfer stems from true factorization or from dataset curation choices.
Authors: The referee correctly notes the absence of ablations isolating 3D supervision from the photorealistic mixture and the lack of statistical tests over more categories. Our reported transfer results use a fixed set of unseen categories and show consistent gains over baselines, but without these controls the contribution of each data component cannot be fully isolated. We will revise §4.3 and add a limitations section to discuss dataset composition and its role in transfer, and we will report per-category variance for the tested set. However, new ablations are not feasible at this stage. revision: partial
- We cannot conduct or report new ablations isolating the 3D geometric supervision from photorealistic augmentations or perform statistical tests across a broader set of categories without additional experiments.
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical fine-tuning procedure on an externally curated dataset that mixes 3D-rendered images with photorealistic augmentations. The central claims about viewpoint tokens learning factorized geometric representations and transferring to unseen categories are presented as experimental outcomes of this training, not as quantities defined into the method by construction or reduced via self-citation. No equations, uniqueness theorems, or ansatzes are invoked that loop back to the inputs; the derivation chain remains self-contained against the external data and standard fine-tuning objective.
Axiom & Free-Parameter Ledger
free parameters (1)
- viewpoint tokens
axioms (1)
- domain assumption 3D-rendered images supply accurate geometric supervision that transfers to photorealistic images.
invented entities (1)
-
viewpoint tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep Learning using Rectified Linear Units (ReLU)
Abien Fred Agarap. Deep learning using rectified linear units (relu).arXiv preprint arXiv:1803.08375, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Precisecam: Precise camera control for text-to- image generation
Edurne Bernal-Berdun, Ana Serrano, Belen Masia, Matheus Gadelha, Yannick Hold-Geoffroy, Xin Sun, and Diego Gutierrez. Precisecam: Precise camera control for text-to- image generation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 2724–2733, 2025. 3
2025
-
[3]
Viewpoint textual inversion: Discovering scene representa- tions and 3d view control in 2d diffusion models
James Burgess, Kuan-Chieh Wang, and Serena Yeung-Levy. Viewpoint textual inversion: Discovering scene representa- tions and 3d view control in 2d diffusion models. InEu- ropean Conference on Computer Vision, pages 416–435. Springer, 2025. 1, 2, 3
2025
-
[4]
Chan, Connor Z
Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3D generative adversarial networks. InCVPR, 2022. 3
2022
-
[5]
Mvsnerf: Fast general- izable radiance field reconstruction from multi-view stereo
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. Mvsnerf: Fast general- izable radiance field reconstruction from multi-view stereo. InProceedings of the IEEE/CVF international conference on computer vision, pages 14124–14133, 2021. 3
2021
-
[6]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[7]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[8]
Geneval: An object-focused framework for evaluating text- to-image alignment
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text- to-image alignment. InAdvances in Neural Information Pro- cessing Systems, 2023. 4, 6
2023
-
[9]
Gemini 2.5 flash image (nano banana).https: //aistudio.google.com/models/gemini- 2- 5-flash-image
Google. Gemini 2.5 flash image (nano banana).https: //aistudio.google.com/models/gemini- 2- 5-flash-image. Accessed: 2025-11-11. 1, 4, 8, 2
2025
-
[10]
Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–12, 2025. 3
2025
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2
2016
-
[12]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023. 3
2023
-
[13]
One diffusion to generate them all
Duong H Le, Tuan Pham, Sangho Lee, Christopher Clark, Aniruddha Kembhavi, Stephan Mandt, Ranjay Krishna, and Jiasen Lu. One diffusion to generate them all. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2671–2682, 2025. 2, 3
2025
-
[14]
Autoregressive image generation without vec- tor quantization.Advances in Neural Information Processing Systems, 2024
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vec- tor quantization.Advances in Neural Information Processing Systems, 2024. 2, 4
2024
-
[15]
Gligen: Open-set grounded text-to-image generation.CVPR,
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation.CVPR,
-
[16]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 300–309, 2023. 3
2023
-
[17]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF International Conference on Computer Vision,
-
[18]
arXiv preprint arXiv:2309.03453 , year=
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Gen- erating multiview-consistent images from a single-view im- age.arXiv preprint arXiv:2309.03453, 2023. 3
-
[19]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jian- feng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[20]
Wonder3d: Sin- gle image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Sin- gle image to 3d using cross-domain diffusion. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9970–9980, 2024. 1, 2, 3
2024
-
[21]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 4
2019
-
[22]
Laconic: A 3d layout adapter for con- trollable image creation
L ´eopold Maillard, Tom Durand, Adrien Ramanana Rahary, and Maks Ovsjanikov. Laconic: A 3d layout adapter for con- trollable image creation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18046– 18057, 2025. 2
2025
-
[23]
Nerf: Representing scenes as neural radiance fields for view syn- thesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. InEuropean Conference on Computer Vision, pages 405–421, 2020. 3
2020
-
[24]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.arXiv preprint arXiv:2302.08453, 2023. 2
-
[25]
Multidiff: Consistent novel view synthesis from a single image
Norman M ¨uller, Katja Schwarz, Barbara R ¨ossle, Lorenzo Porzi, Samuel Rota Bulo, Matthias Nießner, and Peter Kontschieder. Multidiff: Consistent novel view synthesis from a single image. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 10258–10268, 2024. 1, 3
2024
-
[26]
Chatgpt (gpt-5).https://chat.openai
OpenAI. Chatgpt (gpt-5).https://chat.openai. com/, 2025. Large language model. 2
2025
-
[27]
Compass control: Multi object orientation control for text-to-image generation
Rishubh Parihar, Vaibhav Agrawal, Sachidanand VS, and Venkatesh Babu Radhakrishnan. Compass control: Multi object orientation control for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2791–2801, 2025. 1, 2, 3, 4, 5, 6, 7, 8, 9
2025
-
[28]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[29]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[30]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[31]
Richdreamer: A generalizable normal-depth diffusion model for detail richness in text-to- 3d
Lingteng Qiu, Guanying Chen, Xiaodong Gu, Qi Zuo, Mu- tian Xu, Yushuang Wu, Weihao Yuan, Zilong Dong, Liefeng Bo, and Xiaoguang Han. Richdreamer: A generalizable normal-depth diffusion model for detail richness in text-to- 3d. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 9914–9925,
-
[32]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 4
2021
-
[33]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 2
work page internal anchor Pith review arXiv 2022
-
[34]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 2, 3, 6, 7
2022
-
[35]
arXiv preprint arXiv:2310.15110 , year=
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: a single image to consistent multi-view dif- fusion base model.arXiv preprint arXiv:2310.15110, 2023. 1, 3
-
[36]
arXiv preprint arXiv:2308.16512 , year=
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d gen- eration.arXiv preprint arXiv:2308.16512, 2023. 3
-
[37]
Score-based generative modeling through stochastic differential equa- tions
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions. InInternational Conference on Learning Represen- tations, 2021. 2
2021
-
[38]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024. 3
2024
-
[39]
Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion
Shitao Tang, Fuayng Zhang, Jiacheng Chen, Peng Wang, and Furukawa Yasutaka. Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion. arXiv preprint 2307.01097, 2023. 1, 3
-
[40]
Ibr- net: Learning multi-view image-based rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibr- net: Learning multi-view image-based rendering. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2021. 3
2021
-
[41]
Size Wu, Zhonghua Wu, Zerui Gong, Qingyi Tao, Sheng Jin, Qinyue Li, Wei Li, and Chen Change Loy. Openuni: A sim- ple baseline for unified multimodal understanding and gen- eration.arXiv preprint arXiv:2505.23661, 2025. 2
-
[42]
Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Zhonghua Wu, Qingyi Tao, Wentao Liu, Wei Li, and Chen Change Loy. Harmonizing visual representations for unified mul- timodal understanding and generation.arXiv preprint arXiv:2503.21979, 2025. 2, 3, 4, 6, 8, 1
-
[43]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[44]
Reconstruction alignment improves unified multimodal models.arXiv preprint arXiv:2509.07295, 2025a
Ji Xie, Trevor Darrell, Luke Zettlemoyer, and XuDong Wang. Reconstruction alignment improves unified multi- modal models.arXiv preprint arXiv:2509.07295, 2025. 4, 6
-
[45]
ControlNetPlus: All-in-one controlnet for im- age generation and editing.https://github.com/ xinsir6/ControlNetPlus, 2024
xinsir6. ControlNetPlus: All-in-one controlnet for im- age generation and editing.https://github.com/ xinsir6/ControlNetPlus, 2024. 6, 2
2024
-
[46]
3d-aware image synthesis via learning struc- tural and textural representations
Yinghao Xu, Sida Peng, Ceyuan Yang, Yujun Shen, and Bolei Zhou. 3d-aware image synthesis via learning struc- tural and textural representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18430–18439, 2022. 3
2022
-
[47]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jian- wei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfen...
work page internal anchor Pith review arXiv 2024
-
[48]
Scenecraft: Layout-guided 3d scene generation
Xiuyu Yang, Yunze Man, Junkun Chen, and Yu-Xiong Wang. Scenecraft: Layout-guided 3d scene generation. Advances in Neural Information Processing Systems, 37: 82060–82084, 2024. 2
2024
-
[49]
pixelnerf: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4578–4587, 2021. 3
2021
-
[50]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2, 5, 6, 7, 8, 9
2023
-
[51]
Yibo Zhang, Shaoxiang Zhang, Size Wu, Kejun Qian, Dazhong Ji, Chen Change Loy, Wenbin Yang, and Guosheng Lin. Texverse: A universe of 3d objects with high-resolution textures.arXiv preprint arXiv:2508.10868, 2025. 4
-
[52]
Jensen (Jinghao) Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Gen- erative view synthesis with diffusion models.arXiv preprint arXiv:2503.14489, 2025. 1, 2, 3, 5, 6, 7, 8, 9 Camera Control for Text-to-Image Generation via Learning Viewpoint Tokens Su...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.