Recognition: unknown
Efficient Reinforcement Learning using Linear Koopman Dynamics for Nonlinear Robotic Systems
Pith reviewed 2026-05-10 01:37 UTC · model grok-4.3
The pith
Linear dynamics learned via the Koopman operator allow model-based reinforcement learning to optimize policies for nonlinear robots using only one-step predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By lifting the original nonlinear state transitions into a linear system through the Koopman operator, the framework embeds the resulting model inside an actor-critic architecture so that policy gradients can be estimated reliably from one-step predictions. This produces an online mini-batch algorithm that improves policies from interaction data without incurring the compounding errors of long-horizon rollouts, and yields sample efficiency superior to model-free baselines together with control performance comparable to methods that assume perfect knowledge of the system dynamics.
What carries the argument
The Koopman operator that lifts nonlinear robotic dynamics into a linear form in a higher-dimensional space, allowing one-step forward predictions to supply stable gradients for policy optimization inside an actor-critic loop.
If this is right
- Policy updates become feasible from streamed mini-batches without requiring simulated multi-step trajectories.
- Control performance reaches levels previously available only to classical controllers supplied with exact nonlinear dynamics.
- Sample efficiency exceeds that of typical model-free reinforcement learning on the same nonlinear benchmarks.
- The same one-step gradient approach applies directly to real hardware platforms without hand-derived models.
Where Pith is reading between the lines
- If the linear lifting remains reliable, the same structure could be tried on other nonlinear systems such as vehicle dynamics or chemical processes where long rollouts are costly.
- Better choices of lifting functions might further shrink model error and support modest extensions of the planning horizon while keeping the one-step update rule.
- Scaling tests on higher-dimensional robots would show whether the efficiency gain persists when the lifted space grows larger.
Load-bearing premise
The learned linear model stays accurate enough across the states and actions seen during learning that one-step predictions produce consistent policy improvement rather than being overwhelmed by model error.
What would settle it
Running the learned controller on the physical arm or quadruped and finding that closed-loop performance falls below a model-free baseline or becomes unstable once the accumulated prediction error exceeds a small threshold.
Figures






read the original abstract
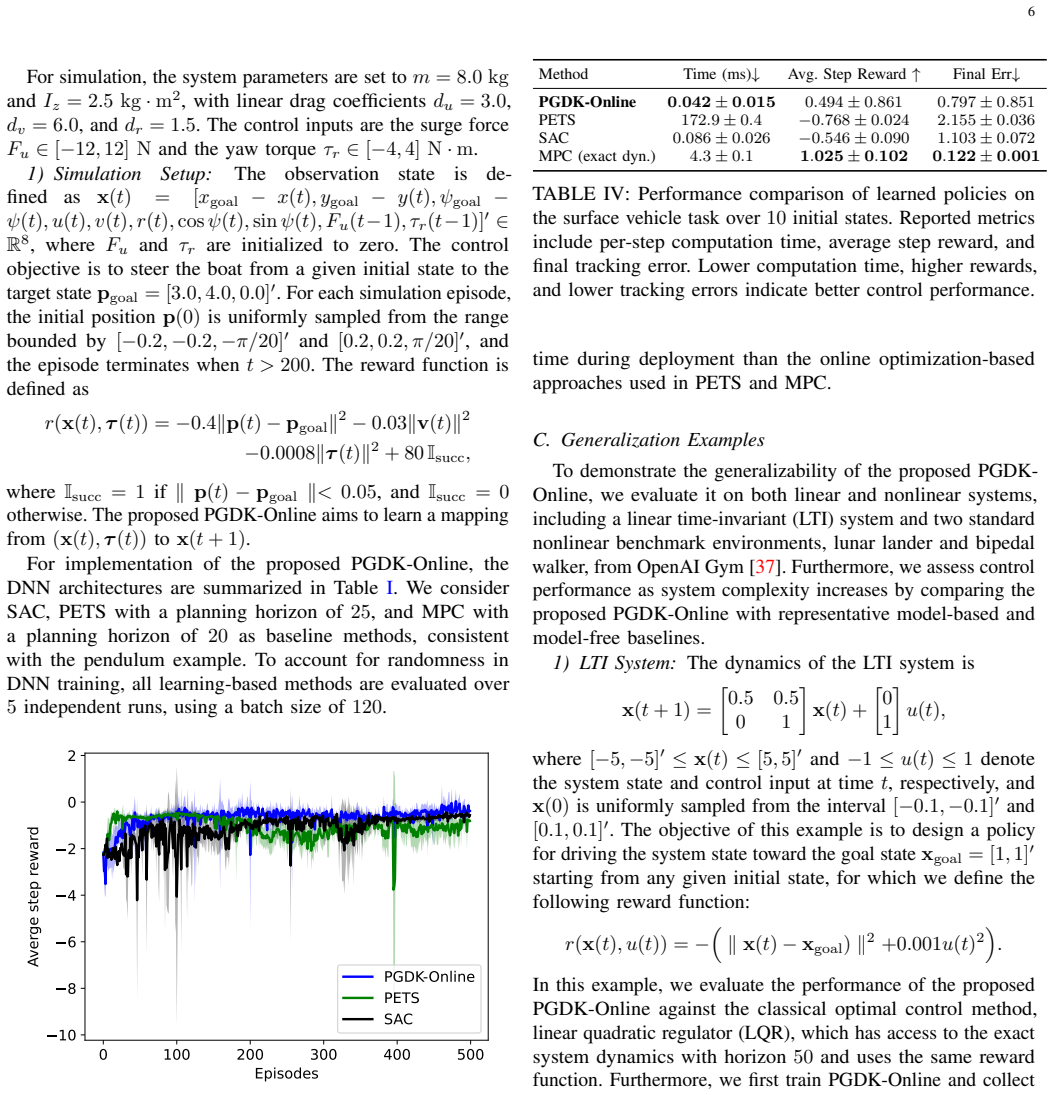
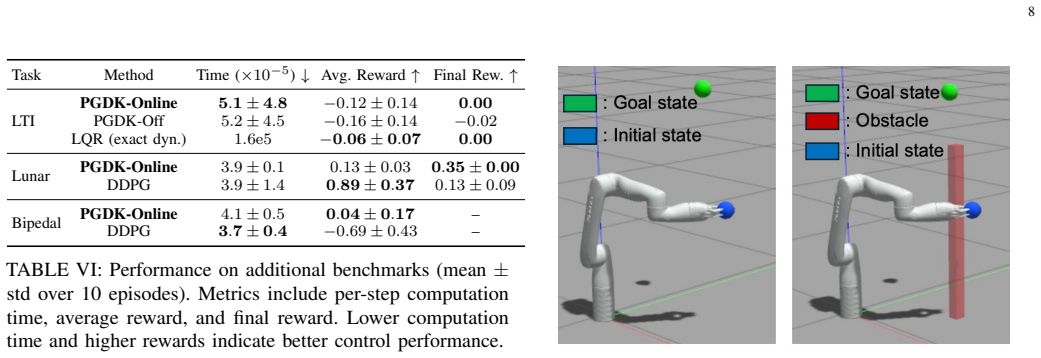
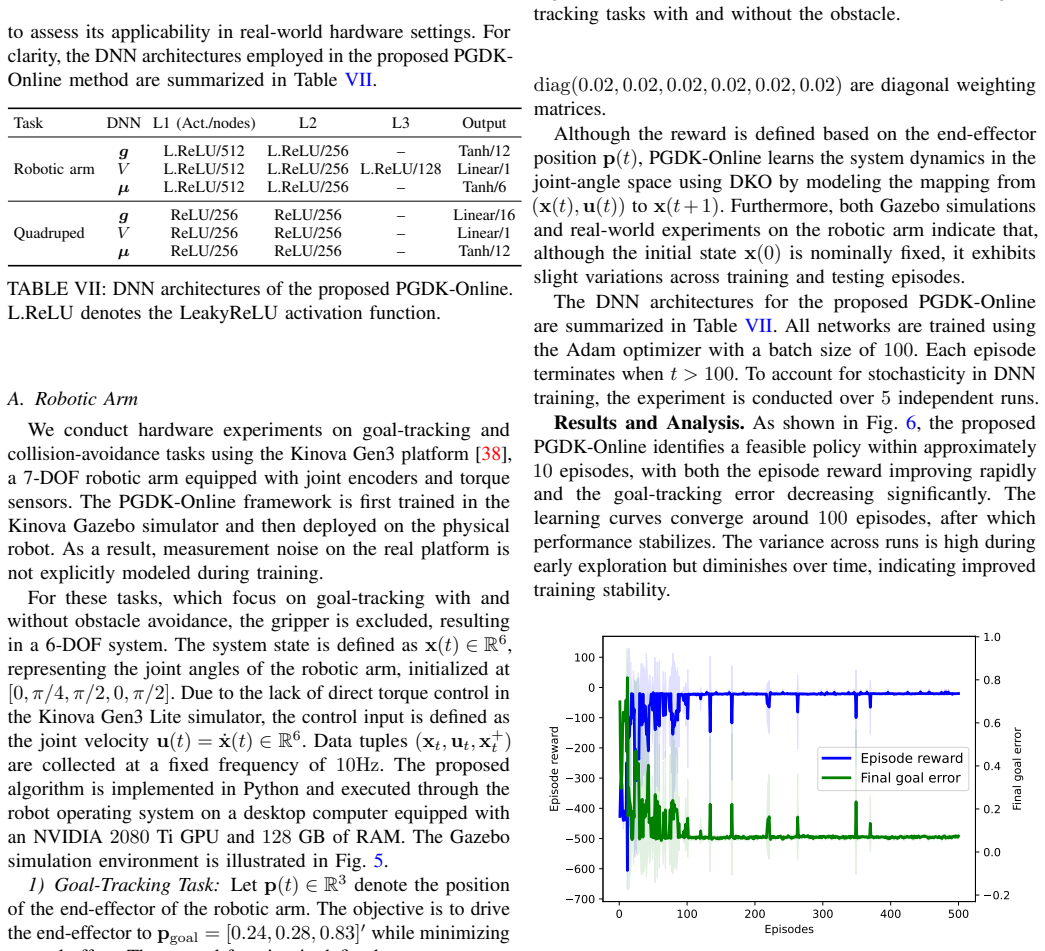
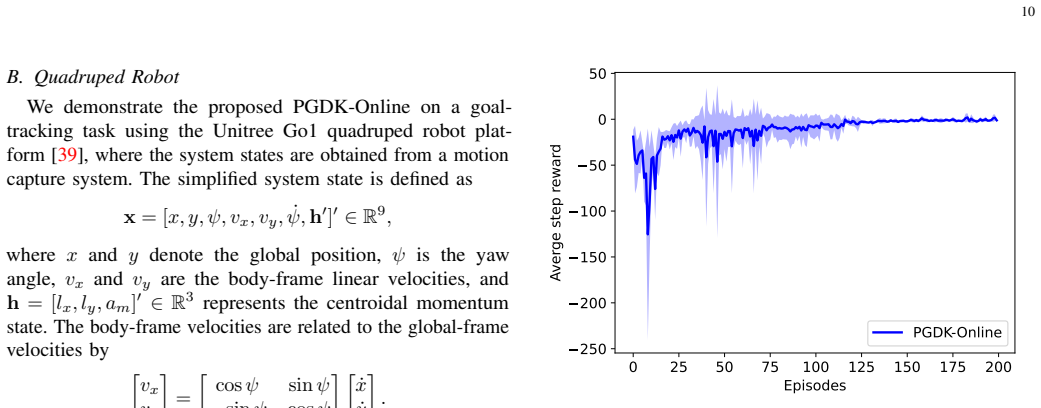
This paper presents a model-based reinforcement learning (RL) framework for optimal closed-loop control of nonlinear robotic systems. The proposed approach learns linear lifted dynamics through Koopman operator theory and integrates the resulting model into an actor-critic architecture for policy optimization, where the policy represents a parameterized closed-loop controller. To reduce computational cost and mitigate model rollout errors, policy gradients are estimated using one-step predictions of the learned dynamics rather than multi-step propagation. This leads to an online mini-batch policy gradient framework that enables policy improvement from streamed interaction data. The proposed framework is evaluated on several simulated nonlinear control benchmarks and two real-world hardware platforms, including a Kinova Gen3 robotic arm and a Unitree Go1 quadruped. Experimental results demonstrate improved sample efficiency over model-free RL baselines, superior control performance relative to model-based RL baselines, and control performance comparable to classical model-based methods that rely on exact system dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a model-based RL framework for nonlinear robotic systems that learns linear lifted dynamics via Koopman operator theory and embeds one-step predictions from this model into an actor-critic policy optimization loop. Policy gradients are computed from single-step model predictions rather than multi-step rollouts to reduce computation and error accumulation. The approach is evaluated on simulated nonlinear control tasks plus real hardware (Kinova Gen3 arm and Unitree Go1 quadruped), with claims of improved sample efficiency versus model-free baselines, better performance than other model-based RL methods, and parity with classical controllers that use exact dynamics.
Significance. If the central claims hold after addressing validation gaps, the work would demonstrate a practical route to sample-efficient model-based RL for high-dimensional nonlinear robots by exploiting Koopman lifting to obtain linear dynamics suitable for one-step gradient estimation. This could be valuable in robotics where exact models are unavailable and multi-step model rollouts are unreliable, provided the one-step approximation remains faithful on-policy.
major comments (2)
- [Method (one-step policy gradient estimation) and Experiments] The core assumption that one-step predictions from the learned Koopman model suffice for unbiased policy gradients (without model error dominating) is load-bearing for all performance claims, yet no quantitative one-step prediction error bounds, on-policy error analysis, or ablation isolating model mismatch effects on gradient direction are provided in the method or experiments sections.
- [Experiments] Experimental results claim superior sample efficiency and control performance, but the manuscript provides no details on model fitting procedure, hyperparameter selection, statistical significance tests, or data exclusion criteria, which prevents confirmation that reported gains are robust (as noted in the abstract's favorable comparisons).
minor comments (2)
- [Method] Clarify the precise definition of the lifted state space and the Koopman operator approximation method (e.g., which dictionary functions or EDMD variant is used) to aid reproducibility.
- [Experiments] Figure captions for hardware experiments should explicitly state the number of trials, seeds, and whether results are mean ± std.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Method (one-step policy gradient estimation) and Experiments] The core assumption that one-step predictions from the learned Koopman model suffice for unbiased policy gradients (without model error dominating) is load-bearing for all performance claims, yet no quantitative one-step prediction error bounds, on-policy error analysis, or ablation isolating model mismatch effects on gradient direction are provided in the method or experiments sections.
Authors: We acknowledge that the one-step gradient estimation is central to the approach and that additional analysis is required to substantiate it. The original manuscript motivates one-step predictions primarily through reduced error accumulation and computational cost, with empirical support from hardware and simulation results. In revision, we will add: (i) quantitative one-step prediction error bounds (e.g., normalized MSE on held-out and on-policy data), (ii) on-policy error analysis comparing predicted vs. observed trajectories during policy optimization, and (iii) an ablation isolating model mismatch by contrasting gradients from the learned model against those from ground-truth dynamics on simulated tasks. These will appear in the revised Method and Experiments sections. revision: yes
-
Referee: [Experiments] Experimental results claim superior sample efficiency and control performance, but the manuscript provides no details on model fitting procedure, hyperparameter selection, statistical significance tests, or data exclusion criteria, which prevents confirmation that reported gains are robust (as noted in the abstract's favorable comparisons).
Authors: We agree that these experimental details are necessary for reproducibility and to confirm robustness. The revised manuscript will expand the Experiments section with: a full description of the Koopman model fitting procedure (data collection, loss, optimizer); hyperparameter tables with selection methodology; performance metrics reported as mean ± std over multiple random seeds together with statistical significance tests (e.g., paired t-tests or Wilcoxon rank-sum); and an explicit statement that no data were excluded. These additions will directly support the abstract claims. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper learns a Koopman operator-based linear lifted model from interaction data and integrates one-step predictions of this model into an actor-critic policy gradient update. The reported improvements in sample efficiency and control performance are measured via direct experiments on simulated benchmarks and physical hardware (Kinova Gen3 arm and Unitree Go1 quadruped), using actual closed-loop trajectories rather than model-predicted quantities. No equation or claim reduces the final performance metrics to the fitted Koopman parameters by construction, and the method description contains no load-bearing self-citations, imported uniqueness theorems, or ansatzes that collapse the central result to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B. D. Anderson and J. B. Moore,Optimal control: linear quadratic methods. Courier Corporation, 2007
2007
-
[2]
Model predictive control,
B. Kouvaritakis and M. Cannon, “Model predictive control,”Switzerland: Springer International Publishing, vol. 38, no. 13-56, p. 7, 2016
2016
-
[3]
Anymal-a highly mobile and dynamic quadrupedal robot,
M. Hutter, C. Gehring, D. Jud, A. Lauber, C. D. Bellicoso, V . Tsounis, J. Hwangbo, K. Bodie, P. Fankhauser, M. Bloeschet al., “Anymal-a highly mobile and dynamic quadrupedal robot,” in2016 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2016, pp. 38–44
2016
-
[4]
Reinforcement learning in continuous time and space,
K. Doya, “Reinforcement learning in continuous time and space,”Neural computation, vol. 12, no. 1, pp. 219–245, 2000
2000
-
[5]
Neural network modeling and an extended dmc algorithm to control nonlinear systems,
E. Hernandaz and Y . Arkun, “Neural network modeling and an extended dmc algorithm to control nonlinear systems,” inAmerican Control Conference. IEEE, 1990, pp. 2454–2459
1990
-
[6]
Real-time dynamic control of an industrial manipulator using a neural network-based learning controller,
W. Miller, R. Hewes, F. Glanz, and L. Kraft, “Real-time dynamic control of an industrial manipulator using a neural network-based learning controller,”Transactions on Robotics and Automation, vol. 6, no. 1, pp. 1–9, 1990
1990
-
[7]
Model predictive control using neural networks,
A. Draeger, S. Engell, and H. Ranke, “Model predictive control using neural networks,”Control Systems Magazine, vol. 15, no. 5, pp. 61–66, 1995
1995
-
[8]
End-to-end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,”The Journal of Machine Learning Research, vol. 17, no. 1, pp. 1334–1373, 2016
2016
-
[9]
Learning to control a low-cost manipulator using data-efficient reinforcement learning,
M. P. Deisenroth, C. E. Rasmussen, and D. Fox, “Learning to control a low-cost manipulator using data-efficient reinforcement learning,” Robotics: Science and Systems VII, vol. 7, pp. 57–64, 2011
2011
-
[10]
Deep reinforcement learning in a handful of trials using probabilistic dynamics models,
K. Chua, R. Calandra, R. McAllister, and S. Levine, “Deep reinforcement learning in a handful of trials using probabilistic dynamics models,” Advances in neural information processing systems, vol. 31, 2018
2018
-
[11]
Model predictive inferential control of neural state-space models for autonomous vehicle motion planning,
I. Askari, A. Vaziri, X. Tu, S. Zeng, and H. Fang, “Model predictive inferential control of neural state-space models for autonomous vehicle motion planning,”IEEE Transactions on Robotics, 2025
2025
-
[12]
An approach to stability criteria of neural-network control systems,
K. Tanaka, “An approach to stability criteria of neural-network control systems,”Transactions on Neural Networks, vol. 7, no. 3, pp. 629–642, 1996
1996
-
[13]
Survey of model-based reinforce- ment learning: Applications on robotics,
A. S. Polydoros and L. Nalpantidis, “Survey of model-based reinforce- ment learning: Applications on robotics,”Journal of Intelligent & Robotic Systems, vol. 86, no. 2, pp. 153–173, 2017
2017
-
[14]
Hamiltonian systems and transformation in hilbert space,
B. O. Koopman, “Hamiltonian systems and transformation in hilbert space,”Proceedings of the national academy of sciences of the united states of america, vol. 17, no. 5, p. 315, 1931
1931
-
[15]
On applications of the spectral theory of the koopman operator in dynamical systems and control theory,
I. Mezi´c, “On applications of the spectral theory of the koopman operator in dynamical systems and control theory,” inConference on Decision and Control. IEEE, 2015, pp. 7034–7041
2015
-
[16]
Dynamic mode decom- position with control,
J. L. Proctor, S. L. Brunton, and J. N. Kutz, “Dynamic mode decom- position with control,”SIAM Journal on Applied Dynamical Systems, vol. 15, no. 1, pp. 142–161, 2016
2016
-
[17]
Linear identification of nonlinear systems: A lifting technique based on the koopman operator,
A. Mauroy and J. Goncalves, “Linear identification of nonlinear systems: A lifting technique based on the koopman operator,” inConference on Decision and Control. IEEE, 2016, pp. 6500–6505. 12
2016
-
[18]
On convergence of extended dynamic mode decomposition to the koopman operator,
M. Korda and I. Mezi ´c, “On convergence of extended dynamic mode decomposition to the koopman operator,”Journal of Nonlinear Science, vol. 28, no. 2, pp. 687–710, 2018
2018
-
[19]
Generalizing koopman theory to allow for inputs and control,
J. L. Proctor, S. L. Brunton, and J. N. Kutz, “Generalizing koopman theory to allow for inputs and control,”SIAM Journal on Applied Dynamical Systems, vol. 17, no. 1, pp. 909–930, 2018
2018
-
[20]
Data-driven discovery of koopman eigenfunctions using deep learning,
B. Lusch, S. L. Brunton, and J. N. Kutz, “Data-driven discovery of koopman eigenfunctions using deep learning,”Bulletin of the American Physical Society, 2017
2017
-
[21]
Deep dynamical modeling and control of unsteady fluid flows,
J. Morton, A. Jameson, M. J. Kochenderfer, and F. Witherden, “Deep dynamical modeling and control of unsteady fluid flows,”Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[22]
Learning deep neural network representations for koopman operators of nonlinear dynamical systems,
E. Yeung, S. Kundu, and N. Hodas, “Learning deep neural network representations for koopman operators of nonlinear dynamical systems,” inAmerican Control Conference (ACC). IEEE, 2019, pp. 4832–4839
2019
-
[23]
Deep learning for universal linear embeddings of nonlinear dynamics,
B. Lusch, J. N. Kutz, and S. L. Brunton, “Deep learning for universal linear embeddings of nonlinear dynamics,”Nature communications, vol. 9, no. 1, pp. 1–10, 2018
2018
-
[24]
Deep learning of koopman representa- tion for control,
Y . Han, W. Hao, and U. Vaidya, “Deep learning of koopman representa- tion for control,” inConference on Decision and Control. IEEE, 2020, pp. 1890–1895
2020
-
[25]
Koopmanizingflows: Diffeomorphically learning stable koopman opera- tors,
P. Bevanda, M. Beier, S. Kerz, A. Lederer, S. Sosnowski, and S. Hirche, “Koopmanizingflows: Diffeomorphically learning stable koopman opera- tors,”arXiv preprint arXiv:2112.04085, 2021
-
[26]
Online dynamic mode decomposition for time-varying systems,
H. Zhang, C. W. Rowley, E. A. Deem, and L. N. Cattafesta, “Online dynamic mode decomposition for time-varying systems,”SIAM Journal on Applied Dynamical Systems, vol. 18, no. 3, pp. 1586–1609, 2019
2019
-
[27]
Deep koopman learning of nonlinear time-varying systems,
W. Hao, B. Huang, W. Pan, D. Wu, and S. Mou, “Deep koopman learning of nonlinear time-varying systems,”Automatica, vol. 159, p. 111372, 2024
2024
-
[28]
C. O’Neill, J. Terrones, and H. H. Asada, “Koopman global linearization of contact dynamics for robot locomotion and manipulation enables elaborate control,”arXiv preprint arXiv:2511.06515, 2025
-
[29]
Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control,
M. Korda and I. Mezi ´c, “Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control,”Automatica, vol. 93, pp. 149–160, 2018
2018
-
[30]
Actor-critic–type learning algorithms for markov decision processes,
V . R. Konda and V . S. Borkar, “Actor-critic–type learning algorithms for markov decision processes,”SIAM Journal on control and Optimization, vol. 38, no. 1, pp. 94–123, 1999
1999
-
[31]
Continuous control with deep reinforcement learning,
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” International Conference on Learning Representations, 2016
2016
-
[32]
On the theory of the brownian motion,
G. E. Uhlenbeck and L. S. Ornstein, “On the theory of the brownian motion,”Physical review, vol. 36, no. 5, p. 823, 1930
1930
-
[33]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wier- stra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review arXiv 2013
-
[34]
Learning to predict by the methods of temporal differences,
R. S. Sutton, “Learning to predict by the methods of temporal differences,” Machine learning, vol. 3, pp. 9–44, 1988
1988
-
[35]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[37]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba, “Openai gym,”arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review arXiv 2016
-
[38]
[Online]
Kinova Inc.,KINOVA® GEN3 Ultra lightweight robot User Guide, Kinova Inc., 2023. [Online]. Available: https://www.kinovarobotics.com
2023
-
[39]
Unitree go1,
U. Robotics, “Unitree go1,” https://shop.unitree.com, 2021, accessed: 2026-04-11
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.