Recognition: unknown
Statistics, Not Scale: Modular Medical Dialogue with Bayesian Belief Engine
Pith reviewed 2026-05-10 02:24 UTC · model grok-4.3
The pith
Separating language from reasoning in medical AI allows a Bayesian engine to deliver calibrated diagnosis and beat larger standalone models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By restricting the LLM to the role of a language sensor that extracts structured evidence from patient utterances without performing any inference, and delegating all diagnostic reasoning to a deterministic Bayesian engine, the system achieves calibrated selective diagnosis, a statistical separation where low-cost components outperform integrated frontier models, and robustness against adversarial communication that defeats standalone LLMs.
What carries the argument
The Bayesian Medical Belief Engine, a module that receives structured evidence from the LLM sensor and computes posterior probabilities for diagnoses using explicit priors and likelihoods.
If this is right
- Calibrated selective diagnosis with continuously adjustable accuracy-coverage tradeoff.
- Even a cheap sensor paired with the engine outperforms a frontier standalone model at a fraction of the cost.
- Robustness to adversarial patient communication styles that cause standalone models to collapse.
- Patient data never enters the LLM, ensuring privacy by construction.
- The statistical backend can be replaced for different target populations without retraining the language component.
Where Pith is reading between the lines
- This modular design suggests that similar separations could improve reliability in other high-stakes domains requiring both interpretation and precise calculation.
- Replacing the Bayesian engine with other statistical models might extend the benefits to non-medical applications like risk assessment.
Load-bearing premise
An LLM sensor can convert natural language patient statements into accurate structured evidence without systematic biases that the Bayesian engine is unable to compensate for.
What would settle it
Demonstrating cases where the LLM consistently misinterprets patient descriptions of symptoms in a way that leads the Bayesian engine to lower accuracy than a comparable standalone LLM on the same dataset.
Figures




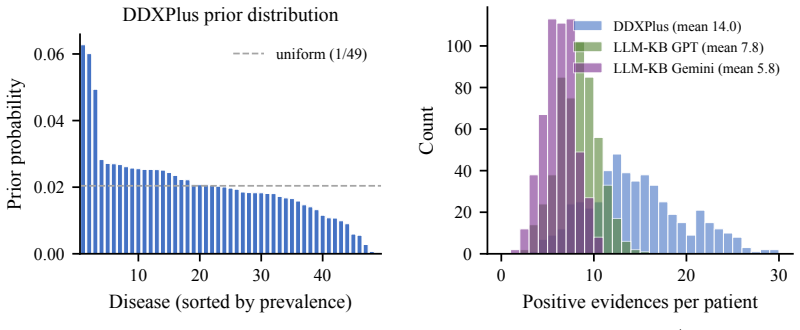



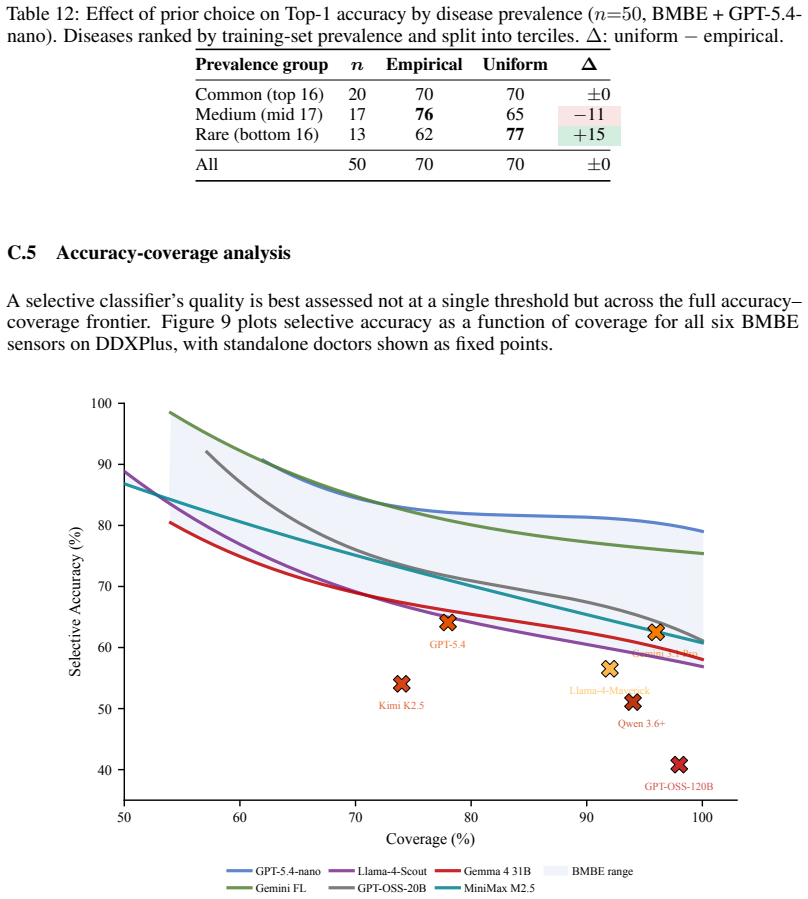

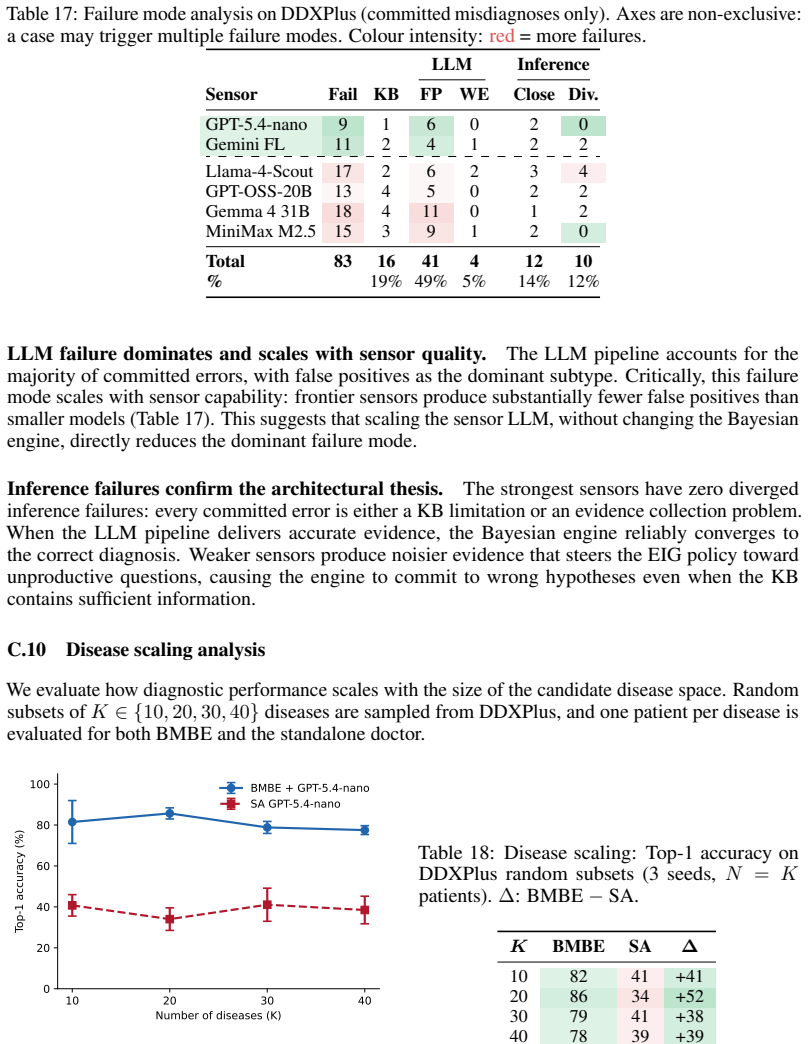

read the original abstract
Large language models are increasingly deployed as autonomous diagnostic agents, yet they conflate two fundamentally different capabilities: natural-language communication and probabilistic reasoning. We argue that this conflation is an architectural flaw, not an engineering shortcoming. We introduce BMBE (Bayesian Medical Belief Engine), a modular diagnostic dialogue framework that enforces a strict separation between language and reasoning: an LLM serves only as a sensor, parsing patient utterances into structured evidence and verbalising questions, while all diagnostic inference resides in a deterministic, auditable Bayesian engine. Because patient data never enters the LLM, the architecture is private by construction; because the statistical backend is a standalone module, it can be replaced per target population without retraining. This separation yields three properties no autonomous LLM can offer: calibrated selective diagnosis with a continuously adjustable accuracy-coverage tradeoff, a statistical separation gap where even a cheap sensor paired with the engine outperforms a frontier standalone model from the same family at a fraction of the cost, and robustness to adversarial patient communication styles that cause standalone doctors to collapse. We validate across empirical and LLM-generated knowledge bases against frontier LLMs, confirming the advantage is architectural, not informational.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BMBE, a modular medical dialogue framework that restricts an LLM to the role of a sensor (parsing utterances into structured evidence and verbalizing questions) while confining all diagnostic inference to a separate deterministic Bayesian engine. It claims this architectural separation delivers three properties unavailable to autonomous LLMs—calibrated selective diagnosis with an adjustable accuracy-coverage tradeoff, a statistical separation gap in which even a cheap sensor plus the engine outperforms a frontier model from the same family, and robustness to adversarial patient communication styles—while also ensuring privacy by construction and modularity across knowledge bases. The abstract asserts validation on both empirical and LLM-generated knowledge bases confirming that the advantage is architectural rather than informational.
Significance. If the empirical claims are substantiated with rigorous metrics, the modular separation of language and probabilistic reasoning offers a concrete, auditable alternative to end-to-end LLM diagnostic agents. The emphasis on replaceable statistical back-ends, privacy guarantees, and continuously tunable calibration could influence the design of reliable medical AI systems, particularly where cost, auditability, and robustness to input variation matter.
major comments (3)
- [Abstract] Abstract: The assertion of validation across knowledge bases and outperformance over frontier LLMs is made without any metrics, experimental protocols, error bars, or result tables; this absence prevents assessment of the claimed statistical separation gap and calibrated selective diagnosis.
- [Bayesian engine description] Bayesian engine description (likely §3 or §4): No equations or explicit likelihood definitions are supplied for how the engine incorporates evidence from the LLM sensor or models sensor noise; without these, it is impossible to verify how posterior calibration or correction of extraction errors is achieved.
- [Validation section] Validation and robustness claims: The central properties (separation gap and adversarial robustness) rest on the untested premise that LLM sensor errors are either negligible or fully correctable by the Bayesian update; the manuscript provides neither error bounds on the sensor mapping nor an explicit noise model in the likelihoods, which directly undermines the architectural-advantage argument.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough and insightful comments, which have helped us identify areas where the manuscript can be strengthened. We address each major comment below, indicating the changes we will implement in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of validation across knowledge bases and outperformance over frontier LLMs is made without any metrics, experimental protocols, error bars, or result tables; this absence prevents assessment of the claimed statistical separation gap and calibrated selective diagnosis.
Authors: We agree that the abstract, as currently written, is too high-level and does not include quantitative details. In the revision, we will update the abstract to incorporate key metrics from our experiments, including the observed performance gaps (e.g., accuracy improvements and cost reductions), calibration error measures, and robustness statistics under adversarial conditions. We will also reference the experimental protocols and tables/figures where these results are presented in detail. This will enable immediate assessment of the claims. revision: yes
-
Referee: [Bayesian engine description] Bayesian engine description (likely §3 or §4): No equations or explicit likelihood definitions are supplied for how the engine incorporates evidence from the LLM sensor or models sensor noise; without these, it is impossible to verify how posterior calibration or correction of extraction errors is achieved.
Authors: Thank you for pointing this out. While Section 3 provides a high-level description of the Bayesian engine, we acknowledge the absence of explicit mathematical formulations. We will add the necessary equations in a new subsection, defining the likelihood function that maps sensor outputs to evidence probabilities, incorporating a noise model to account for potential LLM extraction errors (e.g., via beta-distributed or Bernoulli noise parameters). This will explicitly show how the posterior updates correct for sensor inaccuracies and achieve calibration. The revised manuscript will include these details to allow full verification. revision: yes
-
Referee: [Validation section] Validation and robustness claims: The central properties (separation gap and adversarial robustness) rest on the untested premise that LLM sensor errors are either negligible or fully correctable by the Bayesian update; the manuscript provides neither error bounds on the sensor mapping nor an explicit noise model in the likelihoods, which directly undermines the architectural-advantage argument.
Authors: We appreciate the referee's concern regarding the foundational assumptions. Our experiments do demonstrate the separation gap and robustness across multiple knowledge bases, but we agree that without quantified sensor error analysis and an explicit noise model, the explanation of how the Bayesian engine corrects errors remains incomplete. In the revision, we will include sensor error rate measurements from our LLM sensor evaluations, introduce an explicit noise model in the likelihood definitions (as noted in the response to the previous comment), and provide error bounds. We will also add ablation studies showing the impact of sensor errors on the final posteriors. This will substantiate that the architectural separation enables correction and robustness. revision: partial
Circularity Check
No circularity: claims rest on architectural separation, not derivations or self-referential fits
full rationale
The paper presents BMBE as an architectural framework enforcing LLM-as-sensor and standalone Bayesian engine, claiming three properties (calibrated selective diagnosis, statistical separation gap, adversarial robustness) follow directly from this separation. No equations, parameter fits, or derivation chains are exhibited in the provided text that reduce these properties to inputs by construction. Validation uses empirical/LLM-generated knowledge bases against frontier models, but the advantage is explicitly framed as architectural rather than informational or fitted. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. This is the common honest case of a self-contained architectural argument with no reduction to its own fitted values or prior author results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM can function as a pure sensor that extracts structured evidence without introducing uncorrectable bias into downstream Bayesian inference
invented entities (1)
-
Bayesian Medical Belief Engine (BMBE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shortliffe.Computer-Based Medical Consultations: MYCIN
Edward H. Shortliffe.Computer-Based Medical Consultations: MYCIN. Elsevier, 1976
1976
-
[2]
F. T. de Dombal, D. J. Leaper, J. R. Staniland, A. P. McCann, and Jane C. Horrocks. Computer- aided diagnosis of acute abdominal pain.British Medical Journal, 2(5804):9–13, 1972
1972
-
[3]
Miller, Harry E
Randolph A. Miller, Harry E. Pople, and Jack D. Myers. Internist-I, an experimental computer- based diagnostic consultant for general internal medicine.New England Journal of Medicine, 307(8):468–476, 1982
1982
-
[4]
Octo Barnett, James J
G. Octo Barnett, James J. Cimino, Jon A. Hupp, and Edward P. Hoffer. DXplain: An evolving diagnostic decision-support system.JAMA, 258(1):67–74, 1987
1987
-
[5]
Heckerman, Eric J
David E. Heckerman, Eric J. Horvitz, and Bharat N. Nathwani. Toward normative expert systems: Part I. The Pathfinder project.Methods of Information in Medicine, 31(2):90–105, 1992
1992
-
[6]
Greek Oracle
Randolph A. Miller and Fred E. Masarie. The demise of the “Greek Oracle” model for medical diagnostic systems.Methods of Information in Medicine, 29(01):1–2, 1990
1990
-
[7]
Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Towards expert-level medical question answering with large language models.Nature Medicine, 2025
2025
-
[8]
Capabilities of Gemini Models in Medicine
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, et al. Capabilities of Gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Towards conversational diagnostic AI
Tao Tu, Anil Palepu, Mike Schaekermann, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Nenad Tober, et al. Towards conversational diagnostic AI. Nature, 2025
2025
-
[10]
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
Subhajit Choudhury, Sinead Williamson, Omar Rivasplata, and Tom Rainforth. BED-LLM: Intelligent information gathering with LLMs and Bayesian experimental design.arXiv preprint arXiv:2508.21184, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
DeLLMa: Decision making under uncertainty with large language models
Ollie Liu, Deqing Fu, Dani Levy, Maryam Fazel, Adith Swaminathan, and Willie Neiswanger. DeLLMa: Decision making under uncertainty with large language models. InProceedings of the International Conference on Learning Representations (ICLR), 2025. Spotlight. 12
2025
-
[12]
Yu Feng, Ben Zhou, Weidong Lin, and Dan Roth. BIRD: A trustworthy Bayesian inference framework for large language models.arXiv preprint arXiv:2404.12494, 2024
-
[13]
Ask patients with patience: Enabling LLMs for human-centric medical dialogue with grounded reasoning
Jiayuan Zhu, Jiazhen Pan, Yuyuan Liu, Fenglin Liu, and Junde Wu. Ask patients with patience: Enabling LLMs for human-centric medical dialogue with grounded reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2846–2857, 2025
2025
-
[14]
Ilgen, Emma Pierson, Pang Wei Koh, and Yulia Tsvetkov
Shuyue Stella Li, Vidhisha Balachandran, Shangbin Feng, Jonathan S. Ilgen, Emma Pierson, Pang Wei Koh, and Yulia Tsvetkov. MediQ: Question-asking LLMs and a benchmark for reliable interactive clinical reasoning. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[15]
Fine-tuning large language models with medical data: Can safety be ensured?NEJM AI, 2(1), 2025
Minkyoung Kim, Yunha Kim, Hee Jun Kang, Hyeram Seo, Heejung Choi, JiYe Han, Gaeun Kee, Seohyun Park, Soyoung Ko, Hyoje Jung, Byeolhee Kim, Tae Joon Jun, and Young-Hak Kim. Fine-tuning large language models with medical data: Can safety be ensured?NEJM AI, 2(1), 2025. doi: 10.1056/AIcs2400390
-
[16]
Yu, Lawrence M
Victor L. Yu, Lawrence M. Fagan, Sharon M. Wraith, William J. Clancey, A. Carlisle Scott, John Hannigan, Robert L. Blum, Bruce G. Buchanan, and Stanley N. Cohen. Antimicrobial selection by a computer: A blinded evaluation by infectious diseases experts.JAMA, 242(12): 1279–1282, 1979
1979
-
[17]
Weiss, Casimir A
Sholom M. Weiss, Casimir A. Kulikowski, Saul Amarel, and Aran Safir. A model-based method for computer-aided medical decision-making.Artificial Intelligence, 11(1–2):145–172, 1978
1978
-
[18]
Abdelzaher
Xinyi Liu, Dachun Sun, Yi Fung, Dilek Hakkani-Tür, and Tarek F. Abdelzaher. DocCHA: Towards LLM-augmented interactive online diagnosis system. InProceedings of the 26th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDial), pages 609–619, 2025
2025
-
[19]
Reasoning like a doctor: Improving medical dialogue systems via diagnostic reasoning process alignment
Kaishuai Xu, Yi Cheng, Wenjun Hou, Qiaoyu Tan, and Wenjie Li. Reasoning like a doctor: Improving medical dialogue systems via diagnostic reasoning process alignment. InFindings of the Association for Computational Linguistics: ACL 2024, pages 6796–6814, 2024
2024
-
[20]
Thomas Savage, John Wang, Robert Gallo, Abdessalem Boukil, Vishwesh Patel, Seyed Amir Safavi-Naini, Ali Soroush, and Jonathan H. Chen. Large language model uncertainty proxies: Discrimination and calibration for medical diagnosis and treatment.Journal of the American Medical Informatics Association, 32(1):139–149, 2025
2025
-
[21]
Collins, David Reich, Robert Freeman, and Eyal Klang
Mahmud Omar, Vera Sorin, Jeremy D. Collins, David Reich, Robert Freeman, and Eyal Klang. Multi-model assurance analysis: LLMs highly vulnerable to adversarial hallucination attacks during clinical decision support.Communications Medicine, 5(1):97, 2025
2025
-
[22]
Omiye, Jenna C
Jesutofunmi A. Omiye, Jenna C. Lester, Simon Spichak, Veronica Rotemberg, and Roxana Daneshjou. Large language models propagate race-based medicine.npj Digital Medicine, 6(1): 195, 2023
2023
-
[23]
Tobi Olatunji, Charles Nimo, Abraham Owodunni, et al. AfriMed-QA: A pan-African, multi- specialty, medical question-answering benchmark dataset.arXiv preprint arXiv:2411.15640,
-
[24]
ACL 2025, Best Social Impact Award
2025
-
[25]
Zhoujian Sun, Chenghua Luo, Liangzhi Jiang, Linlin Liu, Xiaohan Yang, Junfan Shi, Tangjie Lv, Benyou Zhang, and Kezhi Mao. Conversational disease diagnosis via external planner-controlled large language models.arXiv preprint arXiv:2404.04292, 2024
-
[26]
DDXPlus: A new dataset for automatic medical diagnosis
Arsene Fansi Tchango, Rishab Goel, Zhi Wen, Julien Martel, and Joumana Ghosn. DDXPlus: A new dataset for automatic medical diagnosis. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[27]
Jeffrey.The Logic of Decision
Richard C. Jeffrey.The Logic of Decision. McGraw-Hill, 1965. 13
1965
-
[28]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[29]
MedAgentSim: Self-Evolving Multi-Agent Simulations for Realistic Clinical Interactions
Mohammad Almansoori, Komal Kumar, and Hisham Cholakkal. MedAgentSim: Self-Evolving Multi-Agent Simulations for Realistic Clinical Interactions . Inproceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2025, volume LNCS 15968. Springer Nature Switzerland, September 2025
2025
-
[30]
AI hospital: Benchmarking large language models in a multi-agent medical interaction simulator
Zhihao Fan, Lai Wei, Jialong Tang, Wei Chen, Wang Siyuan, Zhongyu Wei, and Fei Huang. AI hospital: Benchmarking large language models in a multi-agent medical interaction simulator. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Compu-...
2025
-
[31]
PatientSim: A persona-driven simulator for realistic doctor-patient interactions
Daeun Kyung, Hyunseung Chung, Seongsu Bae, Jiho Kim, Jae Ho Sohn, Taerim Kim, Soo Kyung Kim, and Edward Choi. PatientSim: A persona-driven simulator for realistic doctor-patient interactions. InAdvances in Neural Information Processing Systems, volume 38, 2025
2025
-
[32]
Yusheng Liao, Yutong Meng, Yuhao Wang, Hongcheng Liu, Yanfeng Wang, and Yu Wang. Automatic interactive evaluation for large language models with state aware patient simula- tor.ArXiv, abs/2403.08495, 2024. URL https://api.semanticscholar.org/CorpusID: 268379575
-
[33]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[34]
I think I had a fever
Yifan Zhao, Yixiao Hua, Dan Roth, and Jinhao Chen. Probing the multi-turn planning capa- bilities of LLMs via 20 question games. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. 14 Appendix overview This supplementary material is organized as follows: A. Theoretical foundations. . . . . . . . . . . . ....
2024
-
[35]
Classify the user response into one of the Allowed Values
-
[36]
Yes", "Not really
Assess confidence: very_likely, likely, uncertain, unlikely, very_unlikely KEY RULES: – Direct answer ("Yes", "Not really"): map to closest value. – Unrelated response: return "unknown|likely". – Uncertain language ("I think so", "maybe"): use "uncertain". – Prefer "unknown" over hard negative when partial/vague. Return format: "value|confidence_level" Ex...
-
[37]
f_fever",
NEVER use technical IDs (e.g., "f_fever", "d_flu")
-
[38]
Speak naturally and empathetically
-
[39]
Do NOT mention probabilities or internal values
-
[40]
{narrative}
If clarifying a previous confusion, keep it brief. Bulk intake prompt.At session start, a single bulk intake call maps the patient’s opening narrative to multiple(f, v, c)triples simultaneously, reducing the number of follow-up questions needed. Bulk Intake Prompt System: You are an expert medical intake specialist. User Text: "{narrative}" TASK: Extract ...
-
[41]
Only extract explicitly mentioned or strongly implied features. 18
-
[42]
Extract demographics (age, gender, location) if present
-
[43]
Do NOT infer negatives from silence; omit unlisted features
-
[44]
feature_id
Assess confidence for each extracted feature. Return JSON: {"feature_id": {"value": "...", "confidence": "likely"}, "demographics": {"age": N, ...}} Patient simulator prompt.The patient simulator receives the full clinical profile (demographics, chief complaint, symptoms, medical history, observed findings) and persona instructions. Crucially, the patient...
-
[45]
Answer based on KNOWN OBSERVED FINDINGS and patient profile
-
[46]
If asked about something listed: answer faithfully (including denials)
-
[47]
I’m not sure
If NOT listed: say “I’m not sure” or “I don’t know”. Do not invent symptoms
-
[48]
NEVER reveal your diagnosis directly
-
[49]
Keep responses concise (1–3 sentences). PERSONA: – Language: {CEFR level A/B/C} – Personality: {plain|verbose|overanxious|distrustful} – Memory: {high|low recall} – Alertness: {normal|moderate daze|high daze} Standalone doctor prompt.The standalone LLM doctor receives no external reasoning support. It conducts the full diagnostic interview and outputs a d...
-
[50]
Acute exacerbation of COPD
{prediction_2} ... REFERENCE DISEASE LIST: – {disease_name_1} – {disease_name_2} ... Output ONLY a numbered list with the matched disease name (exactly as written in the reference list) or NO_MATCH. LLM-generated KB prompts.The LLM-generated KB is constructed via two sequential prompts. Thefeature generation promptasks the model to propose clinically plau...
2073
-
[51]
We then measure the posterior gap between the oracle’s top-1 and top-2 diseases
KB Failure.We run anoracletest: all ground-truth features are supplied at confidence c=1.0. We then measure the posterior gap between the oracle’s top-1 and top-2 diseases. If this gap falls below a thresholdγ(γ=0.80), the KB cannot reliably discriminate the disease pair
-
[52]
Two subtypes: • False Positive (FP): the engine asks about a featureabsentfrom the patient’s ground-truth profile; the pipeline returns yes
LLM Failure.The LLM pipeline (verbaliser + patient simulator + parser) injected incorrect evidence into the engine. Two subtypes: • False Positive (FP): the engine asks about a featureabsentfrom the patient’s ground-truth profile; the pipeline returns yes. If more than 2 such turns occur in a session, the case is flagged. The threshold reflects the empiri...
-
[53]
I have chest pain even at rest, upper chest pain, and pleuritic chest pain
Inference Failure.The KB is adequate and the evidence pipeline introduced no detectable errors, yet the engine converged to the wrong diagnosis. Two subtypes: •Close: the ground truth remains in the top-3 posterior at session end, but the question budget or EIG policy did not resolve the differential. • Diverged: the ground truth is not in the top-3. The ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.