Recognition: unknown
LEO: Tracing GPU Stall Root Causes via Cross-Vendor Backward Slicing
Pith reviewed 2026-05-10 00:51 UTC · model grok-4.3
The pith
Backward slicing from stalled GPU instructions reveals root causes and enables optimizations yielding 1.73x to 1.82x speedups across vendors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LEO attributes GPU stalls to source instructions by backward slicing that accounts for register dependencies and vendor-specific synchronization mechanisms. Across 21 workloads on three GPU platforms, optimizations guided by LEO achieve geometric-mean speedups of 1.73×–1.82×. The approach shows that the same kernel can require different optimizations depending on the GPU architecture and that structured diagnostics from LEO improve the effectiveness of large language models in code optimization compared to baselines using only code or raw stall counts.
What carries the argument
Backward slicing from stalled instructions that incorporates register dependencies and vendor-specific synchronization mechanisms to attribute stalls to source code.
If this is right
- LEO-guided optimizations can be applied to improve performance on diverse GPU platforms.
- Different GPU architectures may necessitate distinct optimizations for the same kernel code.
- LEO's root-cause information enhances the optimization capabilities of large language models beyond simple stall data or code inspection.
Where Pith is reading between the lines
- The technique might extend to diagnosing performance issues in other accelerator types such as TPUs or FPGAs.
- Future compilers could integrate similar slicing to automatically suggest stall-reducing transformations.
- Widespread adoption could shift GPU programming from trial-and-error tuning to cause-based debugging.
Load-bearing premise
That the root causes identified by backward slicing from stalled instructions are the actual drivers of the stalls, such that addressing them produces the measured speedups rather than unrelated changes.
What would settle it
Observing that applying the suggested optimizations based on LEO's attributions fails to reduce stall times or achieve the reported speedups on the 21 workloads would indicate the slicing does not accurately capture the root causes.
Figures


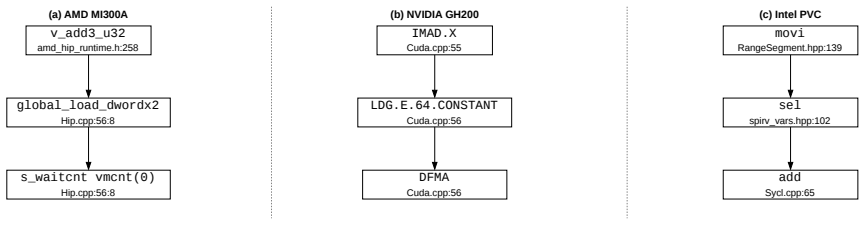




read the original abstract
More than half of the Top 500 supercomputers employ GPUs as accelerators. On GPU-accelerated platforms, developers face a key diagnostic gap: profilers show source lines where stalls occur, but not why they occur. Furthermore, the same kernel may have different stalls and underlying causes on different GPUs. This paper presents LEO, a root-cause analyzer for NVIDIA, AMD, and Intel GPUs that performs backward slicing from stalled instructions, considering dependencies arising from registers as well as vendor-specific synchronization mechanisms. LEO attributes GPU stalls to source instructions with the goal of explaining root causes of these inefficiencies. Across 21 workloads on three GPU platforms, LEO-guided optimizations deliver geometric-mean speedups of 1.73$\times$--1.82$\times$. Our case studies show that (1) the same kernel may require different optimizations for different GPU architectures, and (2) LEO's structured diagnostics improve code optimization with large language models relative to code-only and raw-stall-count baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents LEO, a root-cause analyzer for GPU stalls on NVIDIA, AMD, and Intel platforms. LEO performs backward slicing from stalled instructions while incorporating register dependencies and vendor-specific synchronization mechanisms to attribute stalls to source-level instructions. On 21 workloads, LEO-guided optimizations yield geometric-mean speedups of 1.73×–1.82×; case studies further show architecture-dependent optimizations and improved LLM-assisted tuning relative to code-only and raw-stall-count baselines.
Significance. If the slicing correctly isolates root causes, the work would address a practical diagnostic gap in GPU performance analysis and offer a cross-vendor method that could improve optimization workflows. The reported speedups and the LLM baseline comparisons are concrete empirical contributions; reproducible evaluation artifacts would further strengthen the result.
major comments (2)
- [Evaluation] Evaluation section: the central speedup claims (1.73×–1.82× geometric mean) rest on LEO-guided optimizations, yet no ablation is reported that applies comparable manual or LLM-assisted edits using only raw stall locations or stall counts while omitting the register-dependency and synchronization slicing. Without this control, it is impossible to attribute the measured gains specifically to the backward-slice analysis rather than to any stall-aware editing.
- [Methods] Methods / §3 (slicing algorithm): the description of how backward slicing traverses complex control flow, memory operations, and vendor-specific barriers is insufficient to verify that the produced slices accurately identify the true root causes whose removal produces the observed speedups. Concrete examples or pseudocode showing handling of indirect branches and shared-memory synchronization would be required.
minor comments (2)
- [Abstract] Abstract and evaluation tables: report the per-platform workload counts and any error bars or statistical significance for the geometric-mean speedups.
- [Case Studies] Case-study figures: clarify whether the LLM prompts were identical across the LEO, code-only, and raw-stall baselines or whether prompt engineering differed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to strengthen the evaluation and methods sections.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central speedup claims (1.73×–1.82× geometric mean) rest on LEO-guided optimizations, yet no ablation is reported that applies comparable manual or LLM-assisted edits using only raw stall locations or stall counts while omitting the register-dependency and synchronization slicing. Without this control, it is impossible to attribute the measured gains specifically to the backward-slice analysis rather than to any stall-aware editing.
Authors: We agree that an explicit ablation isolating the contribution of the register-dependency and synchronization slicing would strengthen attribution of the reported speedups. The current LLM baselines compare against raw-stall-count inputs, but the primary LEO-guided optimizations are manual edits. In the revised manuscript we will add a new ablation that applies both manual and LLM-assisted edits guided solely by raw stall locations and counts (without slicing) and directly compare the resulting speedups against the LEO-guided results on the same 21 workloads. revision: yes
-
Referee: [Methods] Methods / §3 (slicing algorithm): the description of how backward slicing traverses complex control flow, memory operations, and vendor-specific barriers is insufficient to verify that the produced slices accurately identify the true root causes whose removal produces the observed speedups. Concrete examples or pseudocode showing handling of indirect branches and shared-memory synchronization would be required.
Authors: We acknowledge that §3 would benefit from additional detail to enable independent verification of slice accuracy. In the revision we will expand the slicing algorithm description with concrete examples of traversal over complex control flow and memory operations, plus pseudocode for key cases including indirect branches and vendor-specific shared-memory synchronization primitives. These additions will clarify how dependencies and barriers are handled across the three vendors. revision: yes
Circularity Check
No circularity: empirical tool evaluation with direct performance measurements
full rationale
The paper introduces LEO as a backward-slicing analyzer for GPU stalls across vendors and evaluates it via measured speedups (1.73–1.82× geometric mean) from LEO-guided optimizations on 21 workloads. No equations, fitted parameters, predictions, or self-citations appear in the provided text that could reduce the central claims to inputs by construction. The performance results derive from end-to-end runtime measurements rather than any self-definitional or fitted-input mechanism, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TOP500 list – November 2025,
TOP500, “TOP500 list – November 2025,” 2025, accessed: 2026-04-02. [Online]. Available: https://www.top500.org/lists/top500/2025/11/
2025
-
[2]
[Online]
NVIDIA Corporation,NVIDIA Nsight Compute Documentation, 2024. [Online]. Available: https://docs.nvidia.com/nsight-compute/
2024
-
[3]
[Online]
Advanced Micro Devices, Inc.,Using rocprofv3, 2024. [Online]. Available: https://rocm.docs.amd.com/projects/rocprofiler-sdk/en/latest/ how-to/using-rocprofv3.html
2024
-
[4]
[Online]
Intel Corporation,Intel VTune Profiler User Guide, 2024. [Online]. Available: https://www.intel.com/content/www/us/en/docs/vtune-profiler/ user-guide/
2024
-
[5]
PTI-GPU: Kernel profiling and assessment on Intel GPUs,
M. Umar and M. Jong, “PTI-GPU: Kernel profiling and assessment on Intel GPUs,” inWorkshops of the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC-W), 2023, pp. 681–684. [Online]. Available: https://doi.org/10.1145/3624062. 3624144
-
[6]
MLIR: Scaling Compiler Infrastructure for Domain Specific Computation
K. Zhou, X. Meng, R. Sai, and J. M. Mellor-Crummey, “GPA: A GPU performance advisor based on instruction sampling,” in IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2021, pp. 115–125. [Online]. Available: https://doi.org/10.1109/CGO51591.2021.9370339
-
[7]
Taking GPU programming models to task for performance portability,
J. H. Davis, P. Sivaraman, J. Kitson, K. Parasyris, H. Menon, I. Minn, G. Georgakoudis, and A. Bhatele, “Taking GPU programming models to task for performance portability,” inProceedings of the 39th ACM International Conference on Supercomputing, 2025, pp. 776–791. [Online]. Available: https://doi.org/10.1145/3721145.3730423
-
[8]
Beckingsale, Jason Burmark, Rich Hornung, Holger Jones, William Killian, Adam J
D. A. Beckingsale, J. Burmark, R. Hornung, H. Jones, W. Killian, A. J. Kunen, O. Pearce, P. Robinson, B. S. Ryujin, and T. R. W. Scogland, “RAJA: Portable performance for large-scale scientific applications,” in 2019 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC), 2019, pp. 71–81. [Online]. Available: https://d...
-
[9]
Carter Edwards and Christian R
H. C. Edwards, C. R. Trott, and D. Sunderland, “Kokkos: Enabling manycore performance portability through polymorphic memory access patterns,”Journal of Parallel and Distributed Computing, vol. 74, no. 12, pp. 3202–3216, 2014. [Online]. Available: https://doi.org/10.1016/j.jpdc.2014.07.003
-
[10]
Implications of a metric for performance portability,
S. J. Pennycook, J. D. Sewall, and V . W. Lee, “Implications of a metric for performance portability,”Future Generation Computer Systems, vol. 92, pp. 947–958, 2019. [Online]. Available: https: //doi.org/10.1016/j.future.2017.08.007
-
[11]
J. Kwacket al., “AI and HPC applications on leadership computing platforms: Performance and scalability studies,” in 2025 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2025, pp. 210–222. [Online]. Available: https://doi.org/10.1109/IPDPS64566.2025.00027
-
[12]
Refining HPCToolkit for application performance analysis at exascale,
L. Adhianto, J. Anderson, R. M. Barnett, D. Grbic, V . Indic, M. Krentel, Y . Liu, S. Milakovi ´c, W. Phan, and J. Mellor- Crummey, “Refining HPCToolkit for application performance analysis at exascale,”The International Journal of High Performance Computing Applications, vol. 38, no. 6, pp. 612–632, 2024. [Online]. Available: https://doi.org/10.1177/1094...
-
[13]
Q. Zhao, H. Wu, Y . Hao, Z. Ye, J. Li, X. Liu, and K. Zhou, “DeepContext: A context-aware, cross-platform, and cross-framework tool for performance profiling and analysis of deep learning workloads,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2025, pp. 48–63. [...
-
[14]
InIEEE/ACM International Symposium on Code Generation and Optimization (CGO)
M. Lin, H. Jeon, and K. Zhou, “PASTA: A modular program analysis tool framework for accelerators,” in2026 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2026, pp. 520–534. [Online]. Available: https://doi.org/10.1109/CGO68049.2026.11395237
-
[15]
GPUscout: Locating data movement-related bottlenecks on GPUs,
S. Sen, S. Vanecek, and M. Schulz, “GPUscout: Locating data movement-related bottlenecks on GPUs,” inProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, 2023, pp. 1392–1402. [Online]. Available: https://doi.org/10.1145/3624062.3624208
-
[16]
Lightweight kubernetes distributions: A performance comparison of microk8s, k3s, k0s, and microshift
Y . Hao, N. Jain, R. V . der Wijngaart, N. Saxena, Y . Fan, and X. Liu, “DrGPU: A top-down profiler for GPU applications,” inProceedings of the 2023 ACM/SPEC International Conference on Performance Engineering, ICPE 2023, Coimbra, Portugal, April 15-19, 2023. ACM, 2023, pp. 43–53. [Online]. Available: https://doi.org/10.1145/3578244.3583736
-
[17]
RAJA per- formance suite,
R. Hornung, J. Keasler, A. Kunen, and D. Beckingsale, “RAJA per- formance suite,” https://github.com/LLNL/RAJAPerf, 2024, lawrence Livermore National Laboratory, LLNL-CODE-738930, v2024.07.0
2024
-
[18]
Quicksilver: A proxy app for the Monte Carlo transport code Mercury,
D. F. Richards, R. C. Bleile, P. S. Brantley, S. A. Dawson, M. S. McKinley, and M. J. O’Brien, “Quicksilver: A proxy app for the Monte Carlo transport code Mercury,” in2017 IEEE International Conference on Cluster Computing (CLUSTER), 2017, pp. 866–873. [Online]. Available: https://doi.org/10.1109/CLUSTER.2017.121
-
[19]
KRIPKE – a massively parallel transport mini-app,
A. J. Kunen, T. S. Bailey, and P. N. Brown, “KRIPKE – a massively parallel transport mini-app,” inANS Joint International Conference on Mathematics and Computation (M&C), Nashville, TN, USA, 2015. [Online]. Available: https://github.com/LLNL/Kripke
2015
-
[20]
llama.cpp: LLM inference in C/C++,
G. Gerganovet al., “llama.cpp: LLM inference in C/C++,” https://github. com/ggml-org/llama.cpp, 2023
2023
-
[21]
Fu, Ryann Swann, Muhammad Osama, Christopher Ré, and Simran Arora
W. Hu, D. Wadsworth, S. Siddens, S. Winata, D. Y . Fu, R. Swann, M. Osama, C. R ´e, and S. Arora, “HipKittens: Fast and furious AMD kernels,” 2025. [Online]. Available: https://arxiv.org/abs/2511.08083
-
[22]
[Online]
NVIDIA Corporation,CUPTI User’s Guide, 2024. [Online]. Available: https://docs.nvidia.com/cupti/
2024
-
[23]
[Online]
Advanced Micro Devices, Inc.,ROCprofiler-SDK Documentation, 2024. [Online]. Available: https://rocm.docs.amd.com/projects/rocprofiler-sdk/ en/latest/
2024
-
[24]
Level Zero specification: Tools programming guide,
UXL Foundation, “Level Zero specification: Tools programming guide,” https://oneapi-src.github.io/level-zero-spec/level-zero/latest/tools/ PROG.html, 2024
2024
-
[25]
[Online]
Intel Corporation,GTPin – A Dynamic Binary Instrumentation Framework, 2024. [Online]. Available: https://www.intel.com/content/ www/us/en/developer/articles/tool/gtpin.html
2024
-
[26]
Intraprocedural static slicing of binary executables,
C. Cifuentes and A. Fraboulet, “Intraprocedural static slicing of binary executables,” in1997 Proceedings International Conference on Software Maintenance. IEEE, 1997, pp. 188–195. [Online]. Available: https://doi.org/10.1109/ICSM.1997.624245
-
[27]
An improved algorithm for slicing machine code,
V . Srinivasan and T. Reps, “An improved algorithm for slicing machine code,”ACM SIGPLAN Notices, vol. 51, no. 10, pp. 378–393, 2016. [Online]. Available: https://doi.org/10.1145/2983990.2984003
-
[28]
Analyzing the Performance of Applications at Exascale,
D. Grbic and J. Mellor-Crummey, “Analyzing the performance of applications at exascale,” inProceedings of the 39th ACM International Conference on Supercomputing, 2025, pp. 792–806. [Online]. Available: https://doi.org/10.1145/3721145.3730417
-
[29]
Parallel binary code analysis,
X. Meng, J. M. Anderson, J. Mellor-Crummey, M. W. Krentel, B. P. Miller, and S. Milakovi ´c, “Parallel binary code analysis,” inProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2021, pp. 76–89. [Online]. Available: https://doi.org/10.1145/3437801.3441604
-
[30]
Loki: A system for serving ml inference pipelines with hardware and accuracy scaling,
D. Nichols, J. H. Davis, Z. Xie, A. Rajaram, and A. Bhatele, “Can large language models write parallel code?” inProceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing, 2024, pp. 281–294. [Online]. Available: https://doi.org/10.1145/3625549.3658689
-
[31]
Learning performance-improving code edits,
A. Shypula, A. Madaan, Y . Zeng, U. Alon, J. Gardner, M. Hashemi, G. Neubig, P. Ranganathan, O. Bastani, and A. Yazdanbakhsh, “Learning performance-improving code edits,” inInternational Conference on Learning Representations (ICLR), 2024. [Online]. Available: https://openreview.net/forum?id=ix7rLVHXyY
2024
-
[32]
Integrating performance tools in model reasoning for gpu kernel optimization,
D. Nichols, K. Parasyris, C. Jekel, A. Bhatele, and H. Menon, “Integrating performance tools in model reasoning for GPU kernel optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2510.17158
-
[33]
SwizzlePerf: Hardware-aware LLMs for GPU kernel performance optimization,
A. Tschand, M. Awad, R. Swann, K. Ramakrishnan, J. Ma, K. Lowery, G. Dasika, and V . J. Reddi, “SwizzlePerf: Hardware-aware LLMs for GPU kernel performance optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2508.20258
-
[34]
XSBench – the development and verification of a performance abstraction for Monte Carlo reactor analysis,
J. R. Tramm, A. R. Siegel, T. Islam, and M. Schulz, “XSBench – the development and verification of a performance abstraction for Monte Carlo reactor analysis,” inPHYSOR 2014: The Role of Reactor Physics toward a Sustainable Future, Kyoto, Japan, 2014. [Online]. Available: https://www.mcs.anl.gov/papers/P5064-0114.pdf
2014
-
[35]
Artemis: Automatic runtime tuning of parallel execution parameters using machine learning,
A. Poenaru, W.-C. Lin, and S. McIntosh-Smith, “A performance analysis of modern parallel programming models using a compute-bound application,” inISC High Performance 2021, ser. Lecture Notes in Computer Science, vol. 12728. Springer, 2021, pp. 332–350. [Online]. Available: https://doi.org/10.1007/978-3-030-78713-4 18
-
[36]
LULESH 2.0 updates and changes,
I. Karlin, J. Keasler, and R. Neely, “LULESH 2.0 updates and changes,” Lawrence Livermore National Laboratory, Tech. Rep. LLNL-TR-641973,
-
[37]
Available: https://doi.org/10.2172/1090032
[Online]. Available: https://doi.org/10.2172/1090032
-
[38]
Tools for top-down performance analysis of GPU-accelerated applications,
K. Zhou, M. W. Krentel, and J. Mellor-Crummey, “Tools for top-down performance analysis of GPU-accelerated applications,” inProceedings of the 34th ACM International Conference on Supercomputing (ICS), 2020, pp. 1–12. [Online]. Available: https://doi.org/10.1145/3392717.3392752
-
[39]
Measurement and analysis of GPU-accelerated applications with HPCToolkit,
K. Zhou, L. Adhianto, J. Anderson, A. Cherian, D. Grubisic, M. Krentel, Y . Liu, X. Meng, and J. Mellor-Crummey, “Measurement and analysis of GPU-accelerated applications with HPCToolkit,” Parallel Computing, vol. 108, p. 102837, 2021. [Online]. Available: https://doi.org/10.1016/j.parco.2021.102837
-
[40]
Precise event sampling on AMD versus intel: Quantitative and qualitative comparison,
M. A. Sasongko, M. Chabbi, P. H. J. Kelly, and D. Unat, “Precise event sampling on AMD versus intel: Quantitative and qualitative comparison,” IEEE Trans. Parallel Distributed Syst., vol. 34, no. 5, pp. 1594–1608,
-
[41]
Available: https://doi.org/10.1109/TPDS.2023.3257105
[Online]. Available: https://doi.org/10.1109/TPDS.2023.3257105
-
[42]
Flexible software profiling of GPU architectures,
M. Stephenson, S. K. S. Hari, Y . Lee, E. Ebrahimi, D. R. Johnson, D. Nellans, M. O’Connor, and S. W. Keckler, “Flexible software profiling of GPU architectures,” inProceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA), 2015, pp. 185–197. [Online]. Available: https://doi.org/10.1145/2749469.2750375
-
[43]
Tell, Yanqing Zhang, William J
O. Villa, M. Stephenson, D. W. Nellans, and S. W. Keckler, “NVBit: A dynamic binary instrumentation framework for NVIDIA GPUs,” in Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). ACM, 2019, pp. 372–383. [Online]. Available: https://doi.org/10.1145/3352460.3358307
-
[44]
GPU instruction hotspots detection based on binary instrumentation approach,
A. V . Gorshkov, M. Berezalsky, J. Fedorova, K. Levit-Gurevich, and N. Itzhaki, “GPU instruction hotspots detection based on binary instrumentation approach,”IEEE Transactions on Computers, vol. 68, no. 8, pp. 1213–1224, 2019. [Online]. Available: https: //doi.org/10.1109/TC.2019.2896628
-
[45]
Understanding latency hiding on GPUs,
V . V olkov, “Understanding latency hiding on GPUs,” Ph.D. dissertation, University of California, Berkeley, 2016. [Online]. Available: https: //www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-143.html
2016
-
[46]
GCStack: A GPU cycle accounting mechanism for providing accurate insight into GPU performance,
H. Cha, S. Lee, Y . Ha, H. Jang, J. Kim, and Y . Kim, “GCStack: A GPU cycle accounting mechanism for providing accurate insight into GPU performance,”IEEE Computer Architecture Letters, vol. 23, no. 2, pp. 235–238, 2024. [Online]. Available: https://doi.org/10.1109/LCA.2024.3476909
-
[47]
H. Cha, S. Lee, J. Lee, Y . Ha, J. Kim, and Y . Kim, “GCStack+GCScaler: Fast and accurate GPU performance analyses using fine-grained stall cycle accounting and interval analysis,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 1509–1523. [Online]. Available: https://doi.org/10.1145/3695053.3731068
-
[48]
Sparsetir: Composable abstractions for sparse compilation in deep learning,
M. Lin, K. Zhou, and P. Su, “DrGPUM: Guiding memory optimization for GPU-accelerated applications,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 (ASPLOS), 2023, pp. 164–178. [Online]. Available: https://doi.org/10.1145/3582016.3582044
-
[49]
Splitwise: Efficient generative llm inference using phase splitting
I. Chaturvedi, B. R. Godala, Y . Wu, Z. Xu, K. Iliakis, P.-E. Eleftherakis, S. Xydis, D. Soudris, T. Sorensen, S. Campanoniet al., “GhOST: A GPU out-of-order scheduling technique for stall reduction,” in 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 1–16. [Online]. Available: https://doi.org/10.1109/ISC...
-
[50]
A. Nayak and A. Basu, “Over-synchronization in GPU programs,” inProceedings of the 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2024, pp. 795–809. [Online]. Available: https://doi.org/10.1109/MICRO61859.2024.00064
-
[51]
A Top-Down Method for Performance Analysis and Counters Architecture,
A. Yasin, “A top-down method for performance analysis and counters architecture,” in2014 IEEE International Symposium on Performance Analysis of Systems and Software, ISPASS 2014, Monterey, CA, USA, March 23-25, 2014. IEEE Computer Society, 2014, pp. 35–44. [Online]. Available: https://doi.org/10.1109/ISPASS.2014.6844459
-
[52]
Hierarchical cycle accounting: A new method for application performance tuning,
A. Nowak, D. Levinthal, and W. Zwaenepoel, “Hierarchical cycle accounting: A new method for application performance tuning,” in2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 2015, pp. 112–123. [Online]. Available: https://doi.org/10.1109/ISPASS.2015.7095790
-
[53]
Top-Down Performance Profiling on NVIDIA’s GPUs
A. Saiz, P. Prieto, P. A. Fidalgo, J. Gregorio, and V . Puente, “Top-down performance profiling on NVIDIA’s GPUs,” in2022 IEEE International Parallel and Distributed Processing Symposium, IPDPS 2022, Lyon, France, May 30 - June 3, 2022. IEEE, 2022, pp. 179–189. [Online]. Available: https://doi.org/10.1109/IPDPS53621.2022.00026
-
[54]
M. Weiser, “Program slicing,”IEEE Transactions on Software Engineering, vol. SE-10, no. 4, pp. 352–357, 1984. [Online]. Available: https://doi.org/10.1109/TSE.1984.5010248
-
[55]
Interprocedural slicing using dependence graphs,
S. Horwitz, T. Reps, and D. Binkley, “Interprocedural slicing using dependence graphs,”ACM Transactions on Programming Languages and Systems, vol. 12, no. 1, pp. 26–60, 1990. [Online]. Available: https://doi.org/10.1145/77606.77608
-
[56]
[Online]
Anthropic, “Claude,” 2026, accessed: 2026-04-06. [Online]. Available: https://www.anthropic.com/claude
2026
-
[57]
[Online]
Google, “Gemini,” 2026, accessed: 2026-04-06. [Online]. Available: https://gemini.google.com
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.