Recognition: unknown
Normalizing Flows with Iterative Denoising
Pith reviewed 2026-05-10 02:08 UTC · model grok-4.3
The pith
Adding iterative denoising after autoregressive sampling lets normalizing flows reach competitive ImageNet performance at 64, 128, and 256 pixels while keeping exact likelihood training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
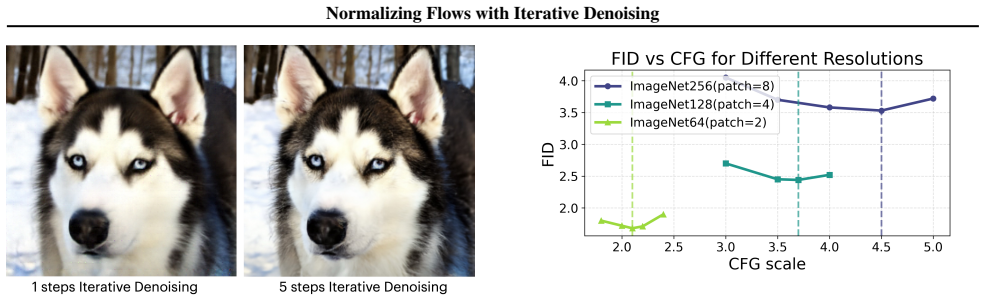
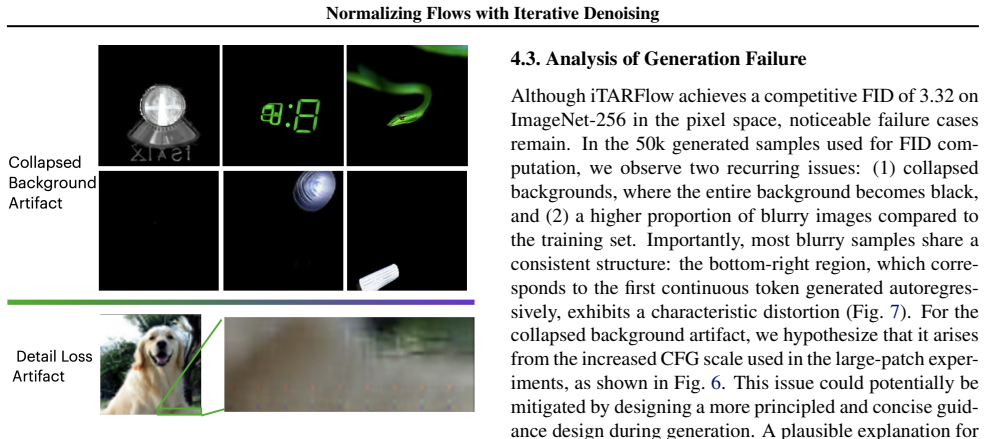
iTARFlow performs autoregressive generation followed by an iterative denoising procedure during sampling. The model is trained entirely with the standard normalizing-flow likelihood objective. On ImageNet at 64, 128, and 256 pixel resolutions the resulting samples are competitive with other contemporary generative models, and the method yields measurable improvements over the base TARFlow architecture.
What carries the argument
The iterative denoising procedure applied after autoregressive generation in the sampling stage, which refines the output while the training objective remains unchanged.
If this is right
- Normalizing flows can incorporate diffusion-style refinement steps at sampling time without retraining or losing the likelihood guarantee.
- Performance on ImageNet scales to 256 pixels with this hybrid procedure, narrowing the gap with non-likelihood models.
- Artifact analysis provides concrete visual diagnostics that can be used to diagnose and correct remaining failure modes in flow-based generators.
- The separation of autoregressive generation and denoising stages allows independent tuning of each component.
Where Pith is reading between the lines
- The same two-stage sampling pattern could be tested on non-image data such as audio or point clouds to check whether the denoising benefit generalizes beyond pixels.
- If the denoising procedure can be expressed as an additional invertible transformation, it might be folded back into the flow itself to restore a single-stage sampler.
- The reported competitiveness on ImageNet suggests that likelihood-based models may benefit from post-hoc refinement modules more broadly, even when those modules are not likelihood-preserving.
Load-bearing premise
The iterative denoising step added at sampling time does not break the validity of the likelihood objective or introduce inconsistencies that make the reported likelihood values unreliable.
What would settle it
An experiment that recomputes exact log-likelihoods on held-out data after disabling the denoising stage and finds that the values no longer match the likelihoods reported for the full iTARFlow pipeline.
Figures




read the original abstract
Normalizing Flows (NFs) are a classical family of likelihood-based methods that have received revived attention. Recent efforts such as TARFlow have shown that NFs are capable of achieving promising performance on image modeling tasks, making them viable alternatives to other methods such as diffusion models. In this work, we further advance the state of Normalizing Flow generative models by introducing iterative TARFlow (iTARFlow). Unlike diffusion models, iTARFlow maintains a fully end-to-end, likelihood-based objective during training. During sampling, it performs autoregressive generation followed by an iterative denoising procedure inspired by diffusion-style methods. Through extensive experiments, we show that iTARFlow achieves competitive performance across ImageNet resolutions of 64, 128, and 256 pixels, demonstrating its potential as a strong generative model and advancing the frontier of Normalizing Flows. In addition, we analyze the characteristic artifacts produced by iTARFlow, offering insights that may shed light on future improvements. Code is available at https://github.com/apple/ml-itarflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces iTARFlow as an extension of TARFlow for normalizing flows on images. Training remains fully end-to-end and likelihood-based, while sampling combines autoregressive generation with an iterative denoising procedure inspired by diffusion models. The authors report competitive performance on ImageNet at 64, 128, and 256 pixel resolutions and analyze characteristic artifacts produced by the model.
Significance. If the added iterative denoising can be shown to preserve exact likelihoods under the trained density, the approach could meaningfully advance normalizing flows as competitive alternatives to diffusion models on high-resolution image synthesis. The public release of code is a clear strength for reproducibility.
major comments (1)
- [Sampling procedure section] The sampling procedure (described after the training objective) adds iterative denoising steps after autoregressive generation. The manuscript must explicitly show that these steps are either absorbed into the invertible flow layers or do not change the base density, so that the reported likelihoods remain valid for the trained model. Without a derivation or empirical verification that the full sampling distribution matches the likelihood objective, the central claim that iTARFlow is a valid normalizing flow is at risk.
minor comments (2)
- [Abstract] The abstract asserts competitive performance across ImageNet resolutions but supplies no numerical metrics, baselines, or error bars; the full manuscript should ensure these appear in the main results tables with clear comparisons.
- [Methods] Notation for the iterative denoising steps should be introduced with explicit equations showing how they interact with the autoregressive components and the original TARFlow layers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify the relationship between training and sampling in iTARFlow. We address the major comment below.
read point-by-point responses
-
Referee: [Sampling procedure section] The sampling procedure (described after the training objective) adds iterative denoising steps after autoregressive generation. The manuscript must explicitly show that these steps are either absorbed into the invertible flow layers or do not change the base density, so that the reported likelihoods remain valid for the trained model. Without a derivation or empirical verification that the full sampling distribution matches the likelihood objective, the central claim that iTARFlow is a valid normalizing flow is at risk.
Authors: We agree that an explicit derivation is required to confirm that the reported likelihoods remain valid. In the current manuscript the training objective is strictly the negative log-likelihood of the autoregressive TARFlow layers, which are fully invertible. The iterative denoising is a post-sampling refinement step. In the revision we will add a dedicated subsection that (i) derives the composite transformation as a composition of the original flow with additional invertible denoising operators whose Jacobian determinant can be computed exactly, and (ii) provides a short empirical check that the likelihood of samples drawn with the full procedure matches the likelihood of the base model within numerical tolerance. This will be placed immediately after the description of the sampling algorithm. revision: yes
Circularity Check
No circularity detected; likelihood objective stated as independent of sampling
full rationale
The provided abstract and context present iTARFlow as maintaining an end-to-end likelihood-based training objective that is explicitly distinguished from the sampling procedure (autoregressive generation plus iterative denoising). No equations, fitted parameters, or self-citations are shown reducing the reported performance or likelihood validity to quantities defined by construction from the inputs. The central claim of competitive performance on ImageNet is supported by experiments rather than by renaming or self-referential definitions. This satisfies the default expectation of a self-contained derivation without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Normalizing Trajectory Models
NTM uses per-step conditional normalizing flows plus a trajectory-wide predictor to achieve exact-likelihood 4-step sampling that matches or exceeds baselines on text-to-image tasks.
-
Normalizing Trajectory Models
NTM models each generative reverse step as a conditional normalizing flow with a hybrid shallow-deep architecture, enabling exact-likelihood training and strong four-step sampling performance on text-to-image tasks.
Reference graph
Works this paper leans on
-
[1]
Diffusion Models Beat GANs on Image Synthesis
Dhariwal, P. and Nichol, A. Diffusion models beat gans on image synthesis.arXiv preprint arXiv:2105.05233,
work page internal anchor Pith review arXiv
-
[2]
Density estimation using Real NVP
Dinh, L., Sohl-Dickstein, J., and Bengio, S. Density esti- mation using real nvp.arXiv preprint arXiv:1605.08803,
work page internal anchor Pith review arXiv
-
[3]
Gu, J., Chen, T., Berthelot, D., Zheng, H., Wang, Y ., Zhang, R., Dinh, L., Bautista, M. A., Susskind, J., and Zhai, S. Starflow: Scaling latent normalizing flows for high-resolution image synthesis.arXiv preprint arXiv:2506.06276, 2025a. Gu, J., Shen, Y ., Chen, T., Dinh, L., Wang, Y ., Bautista, M. ´A., Berthelot, D., Susskind, J. M., and Zhai, S. End- ...
-
[4]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review arXiv
-
[5]
Denoising Diffusion Probabilistic Models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion proba- bilistic models.arXiv preprint arXiv:2006.11239,
work page internal anchor Pith review arXiv 2006
-
[6]
Hoogeboom, E., Mensink, T., Heek, J., Lamerigts, K., Gao, R., and Salimans, T. Simpler diffusion (sid2): 1.5 fid on imagenet512 with pixel-space diffusion.arXiv preprint arXiv:2410.19324,
-
[7]
Scalable adaptive computation for iterative generation,
Jabri, A., Fleet, D., and Chen, T. Scalable adaptive computation for iterative generation.arXiv preprint arXiv:2212.11972,
-
[8]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[9]
Fractal generative models.arXiv:2502.17437, 2025
9 Normalizing Flows with Iterative Denoising Li, T., Sun, Q., Fan, L., and He, K. Fractal generative models.arXiv preprint arXiv:2502.17437,
-
[10]
Scaling laws for diffusion transformers.CoRR, abs/2410.08184, 2024
Liang, Z., He, H., Yang, C., and Dai, B. Scal- ing laws for diffusion transformers.arXiv preprint arXiv:2410.08184,
-
[11]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Improved denois- ing diffusion probabilistic models.arXiv preprint arXiv:2102.09672,
Nichol, A. and Dhariwal, P. Improved denoising diffusion probabilistic models.arXiv preprint arXiv:2102.09672,
-
[13]
2017, arXiv e-prints, arXiv:1705.07057
Papamakarios, G., Pavlakou, T., and Murray, I. Masked au- toregressive flow for density estimation.arXiv preprint arXiv:1705.07057,
-
[14]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
work page internal anchor Pith review arXiv
-
[15]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion im- plicit models.arXiv preprint arXiv:2010.02502, 2020a. Song, Y . and Dhariwal, P. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. Song, Y ., Dhariwal, P., Chen, M., and Sutskever, I. Consis- tency models.arXiv preprint arXiv:2303.01469,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[17]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review arXiv
-
[18]
Givt: Gen- erative infinite-vocabulary transformers
Tschannen, M., Eastwood, C., and Mentzer, F. Givt: Gen- erative infinite-vocabulary transformers. InEuropean Conference on Computer Vision, pp. 292–309. Springer, 2024a. Tschannen, M., Pinto, A. S., and Kolesnikov, A. Jetformer: An autoregressive generative model of raw images and text.arXiv preprint arXiv:2411.19722, 2024b. Van den Oord, A., Kalchbrenner...
-
[19]
Pixnerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268,
Wang, S., Gao, Z., Zhu, C., Huang, W., and Wang, L. Pixnerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268,
-
[20]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Yu, J., Xu, Y ., Koh, J. Y ., Luong, T., Baid, G., Wang, Z., Vasudevan, V ., Ku, A., Yang, Y ., Ayan, B. K., et al. Scaling autoregressive models for content-rich text-to- image generation.arXiv preprint arXiv:2206.10789, 2 (3):5,
work page internal anchor Pith review arXiv
-
[21]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
10 Normalizing Flows with Iterative Denoising Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., and Xie, S. Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940,
work page internal anchor Pith review arXiv
-
[22]
A., Jaitly, N., and Susskind, J
Zhai, S., Zhang, R., Nakkiran, P., Berthelot, D., Gu, J., Zheng, H., Chen, T., Bautista, M. A., Jaitly, N., and Susskind, J. Normalizing flows are capable generative models.arXiv preprint arXiv:2412.06329,
-
[23]
A., Susskind, J., and Jaitly, N
Zhang, R., Zhai, S., Gu, J., Zhang, Y ., Zheng, H., Chen, T., Bautista, M. A., Susskind, J., and Jaitly, N. Flexible language modeling in continuous space with transformer-based autoregressive flows.arXiv preprint arXiv:2507.00425,
-
[24]
Farmer: Flow autoregressive transformer over pixels.arXiv preprint arXiv:2510.23588,
Zheng, G., Zhao, Q., Yang, T., Xiao, F., Lin, Z., Wu, J., Deng, J., Zhang, Y ., and Zhu, R. Farmer: Flow autoregressive transformer over pixels.arXiv preprint arXiv:2510.23588,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.