Recognition: unknown
Scaling Worst-Case Optimal Datalog to GPUs
Pith reviewed 2026-05-09 23:37 UTC · model grok-4.3
The pith
SRDatalog is the first GPU Datalog engine built on worst-case optimal joins to handle complex multi-way queries without binary-join memory blowup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SRDatalog is the first GPU Datalog engine based on WCOJ. It uses flat columnar storage and two-phase deterministic memory allocation to avoid the OOM failures of binary joins and the index-rebuild overheads of static WCOJ systems. To mitigate skew and hide hardware stalls, SRDatalog further employs root-level histogram-guided load balancing, structural helper-relation splitting, and stream-aligned rule multiplexing.
What carries the argument
Worst-case optimal join (WCOJ) adapted to GPUs via attribute-at-a-time intersections, combined with histogram-guided load balancing and helper-relation splitting to manage skew on SIMT hardware.
If this is right
- Complex multi-way Datalog queries from tools such as DOOP can now execute on GPUs without asymptotic time and space blowup.
- Datalog engines gain the ability to use two-phase memory allocation instead of static indexes, eliminating index-rebuild costs.
- Stream-aligned rule multiplexing can hide memory stalls during large intersections on SIMT hardware.
- Program-analysis workloads gain geometric-mean speedups of 21x to 47x while remaining within available GPU memory.
Where Pith is reading between the lines
- The same skew-mitigation techniques could be applied to other join-heavy GPU workloads such as graph analytics or SPARQL engines.
- The approach suggests that hybrid CPU-GPU Datalog systems could partition rules based on estimated skew rather than static assignment.
- Production systems might benefit from exposing the histogram and splitting parameters for user-level tuning on new domains.
- The flat columnar representation may simplify integration with existing GPU database libraries for mixed relational and logic workloads.
Load-bearing premise
The root-level histogram-guided load balancing, structural helper-relation splitting, and stream-aligned rule multiplexing sufficiently mitigate key skew and hardware stalls for complex multi-way queries without introducing prohibitive overhead or requiring query-specific tuning.
What would settle it
Executing SRDatalog on a production program-analysis query that triggers extreme key skew and observing either persistent SM underutilization or an out-of-memory failure where binary-join engines already fail.
Figures





read the original abstract
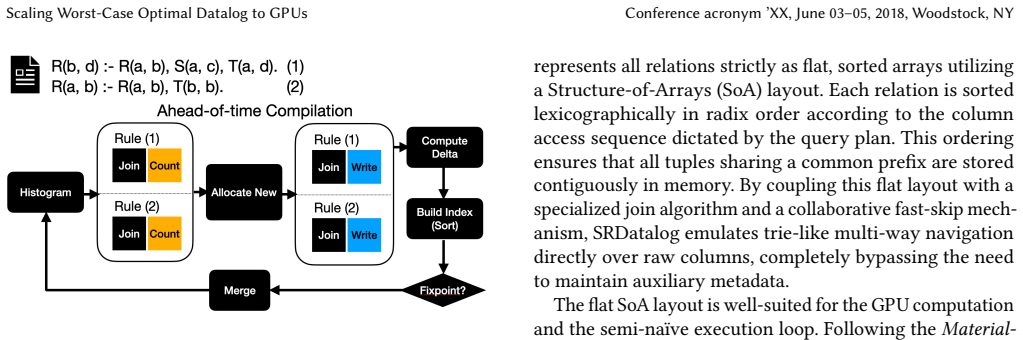
Datalog is a declarative logic-programming language used for complex analytic reasoning workloads such as program analysis and graph analytics. Datalog's popularity is due to its unique price-point, marrying logic-defined specification with the potential for massive data parallelism. While traditional engines are CPU-based, the memory-bound nature of Datalog has led to increasing interest in leveraging GPUs. These engines beat CPU-based engines by operationalizing iterated relational joins via SIMT-friendly join algorithms. Unfortunately, all existing GPU Datalog engines are built on binary joins, which are inadequate for the complex multi-way queries arising in production systems such as DOOP and ddisasm. For these queries, binary decomposition can incur the AGM bound asymptotic blowup in time and space, leading to OOM failures regardless of join order. Worst-Case Optimal Joins (WCOJ) avoid this blowup, but their attribute-at-a-time intersections map poorly to SIMT hardware under key skew, causing severe load imbalance across Streaming Multiprocessors (SMs). We present SRDatalog, the first GPU Datalog engine based on WCOJ. SRDatalog uses flat columnar storage and two-phase deterministic memory allocation to avoid the OOM failures of binary joins and the index-rebuild overheads of static WCOJ systems. To mitigate skew and hide hardware stalls, SRDatalog further employs root-level histogram-guided load balancing, structural helper-relation splitting, and stream-aligned rule multiplexing. On real-world program-analysis workloads, SRDatalog achieves geometric-mean speedups of 21x to 47x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SRDatalog as the first GPU Datalog engine based on Worst-Case Optimal Joins (WCOJ). It describes flat columnar storage and two-phase deterministic memory allocation to avoid OOM failures and index-rebuild costs associated with binary-join GPU engines and static WCOJ systems. To address SIMT load imbalance and hardware stalls under key skew, it introduces root-level histogram-guided load balancing, structural helper-relation splitting, and stream-aligned rule multiplexing. The central empirical claim is that these techniques enable geometric-mean speedups of 21x to 47x over existing GPU Datalog engines on real-world program-analysis workloads such as those from DOOP and ddisasm.
Significance. If the reported speedups prove robust and generalizable, the work would represent a meaningful advance in scaling declarative logic programming to GPUs for complex multi-way queries that suffer from AGM-bound blowup under binary decomposition. The explicit focus on production-style Datalog workloads and the attempt to make attribute-at-a-time WCOJ viable on SIMT hardware are positive contributions; the paper also earns credit for grounding its claims in concrete performance numbers on real workloads rather than synthetic microbenchmarks alone.
major comments (2)
- [Abstract] Abstract: the headline claim of 21x–47x geometric-mean speedups is presented without workload counts, skew statistics, error bars, hardware details, or any quantitative breakdown of the individual contributions (or overheads) of root-level histogram-guided load balancing, structural helper-relation splitting, and stream-aligned rule multiplexing. This information is load-bearing for the central assertion that the three techniques suffice to keep SM occupancy high on high-skew production relations without prohibitive preprocessing cost.
- [Techniques for skew mitigation] Description of the three mitigation techniques: while the mechanisms are outlined, the manuscript supplies no ablation studies, failure-case analysis, or occupancy/stall measurements showing that they prevent load imbalance for the complex, multi-way rules arising in DOOP/ddisasm-style workloads. Without such evidence it is impossible to assess whether the techniques are generally sufficient or require query-specific tuning.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named the exact baselines (binary-join GPU engines) and the number of distinct workloads used for the geometric mean.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of SRDatalog for scaling WCOJ-based Datalog on GPUs. We address each major comment below and will revise the manuscript to strengthen the presentation of our claims and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 21x–47x geometric-mean speedups is presented without workload counts, skew statistics, error bars, hardware details, or any quantitative breakdown of the individual contributions (or overheads) of root-level histogram-guided load balancing, structural helper-relation splitting, and stream-aligned rule multiplexing. This information is load-bearing for the central assertion that the three techniques suffice to keep SM occupancy high on high-skew production relations without prohibitive preprocessing cost.
Authors: We agree that the abstract would be stronger with additional context for the headline numbers. In the revised version we will expand the abstract to state the exact number of workloads (from DOOP and ddisasm), the target GPU hardware, and a brief note that per-technique contribution breakdowns, skew statistics, and error bars appear in Sections 5–6. Because abstracts are length-constrained, we will keep the added material concise while ensuring the central claim is better supported without relying solely on the body text. revision: yes
-
Referee: [Techniques for skew mitigation] Description of the three mitigation techniques: while the mechanisms are outlined, the manuscript supplies no ablation studies, failure-case analysis, or occupancy/stall measurements showing that they prevent load imbalance for the complex, multi-way rules arising in DOOP/ddisasm-style workloads. Without such evidence it is impossible to assess whether the techniques are generally sufficient or require query-specific tuning.
Authors: We acknowledge that the current manuscript lacks explicit ablation studies, occupancy/stall measurements, and dedicated failure-case analysis for the three skew-mitigation techniques. Sections 4.2–4.4 describe the mechanisms and their motivation from SIMT execution characteristics, but do not isolate their individual effects. In the revision we will add ablation experiments that measure performance with each technique enabled or disabled, include any available SM occupancy and stall data from the GPU profiler, and discuss potential failure modes for high-skew multi-way rules. These additions will allow readers to evaluate generality versus query-specific tuning. revision: yes
Circularity Check
No circularity in empirical performance claims
full rationale
The paper describes an implementation of SRDatalog, a GPU Datalog engine using worst-case optimal joins (WCOJ) with three engineering techniques (root-level histogram-guided load balancing, structural helper-relation splitting, and stream-aligned rule multiplexing) to address skew and SIMT stalls. All central claims consist of measured geometric-mean speedups (21x-47x) on real-world program-analysis workloads such as DOOP and ddisasm. These are direct experimental outcomes from running the system, not predictions derived from fitted parameters, self-referential equations, or self-citation chains. No load-bearing step reduces a result to its own inputs by construction, and the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Relational joins can be evaluated via attribute-at-a-time intersections without changing semantics
- domain assumption GPU memory allocation can be made deterministic via two-phase planning
Reference graph
Works this paper leans on
-
[1]
1995.Foundations of Databases
Serge Abiteboul, Richard Hull, and Victor Vianu. 1995.Foundations of Databases. Vol. 8. Addison-Wesley, Reading, MA
1995
-
[2]
Albert Atserias, Martin Grohe, and Dániel Marx. 2008. Size Bounds and Query Plans for Relational Joins. InProceedings of the 2008 49th Annual IEEE Symposium on Foundations of Computer Science (FOCS ’08). IEEE Computer Society, USA, 739–748. doi:10.1109/FOCS.2008.43
-
[3]
Albert Atserias, Martin Grohe, and Dániel Marx. 2013. Size bounds and query plans for relational joins.SIAM J. Comput.42, 4 (2013), 1737–1767
2013
-
[4]
Paul Biberstein, Ziyang Li, Joseph Devietti, and Mayur Naik. 2025. Lob- ster: A GPU-Accelerated Framework for Neurosymbolic Programming. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 (USA)(ASPLOS ’26). Association for Computing Machinery, New York, NY, USA, 147–162...
-
[5]
Cameron Bradley, Ghadeer Ahmed H Alabandi, and Martin Burtscher
-
[6]
KAMI: Communication- avoiding general matrix multiplication within a node,
Fringe-SGC: Counting Subgraphs with Fringe Vertices. InPro- ceedings of the International Conference for High Performance Comput- ing, Networking, Storage and Analysis (SC ’25). Association for Comput- ing Machinery, New York, NY, USA, 1510–1523. doi:10.1145/3712285. 3759839
-
[7]
Martin Bravenboer and Yannis Smaragdakis. 2009. Strictly declarative specification of sophisticated points-to analyses. InProceedings of the 24th ACM SIGPLAN Conference on Object Oriented Programming Sys- tems Languages and Applications(Orlando, Florida, USA)(OOPSLA ’09). Association for Computing Machinery, New York, NY, USA, 243–262. doi:10.1145/1640089.1640108
-
[8]
Stefano Ceri, Georg Gottlob, LUIGI ANTONIO Lavazza, et al . 1986. Translation and optimization of logic queries: The algebraic approach. InProceedings of the 12th International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc., 395–402
1986
-
[9]
Stefano Ceri, Georg Gottlob, Letizia Tanca, et al . 1989. What you always wanted to know about Datalog(and never dared to ask).IEEE transactions on knowledge and data engineering1, 1 (1989), 146–166
1989
-
[10]
Antonio Flores-Montoya and Eric Schulte. 2020. Datalog disassembly. In29th USENIX Security Symposium (USENIX Security 20). 1075–1092
2020
-
[11]
Oded Green, Robert McColl, and David A Bader. 2012. GPU merge path: a GPU merging algorithm. InProceedings of the 26th ACM international conference on Supercomputing. 331–340
2012
- [12]
-
[13]
Joseph M Hellerstein and Peter Alvaro. 2020. Keeping CALM: when distributed consistency is easy.Commun. ACM63, 9 (2020), 72–81
2020
-
[14]
Kijae Hong, Kyoungmin Kim, Young-Koo Lee, Yang-Sae Moon, Sourav S Bhowmick, and Wook-Shin Han. 2024. Themis: A GPU- Accelerated Relational Query Execution Engine.Proc. VLDB Endow. 18, 2 (Oct. 2024), 426–438. doi:10.14778/3705829.3705856
-
[15]
Farzin Houshmand, Mohsen Lesani, and Keval Vora. 2021. Grafs: declarative graph analytics.Proc. ACM Program. Lang.5, ICFP, Article 83 (Aug. 2021), 32 pages. doi:10.1145/3473588
-
[16]
Ioannidis
Yannis E. Ioannidis. 1986. On the Computation of the Transitive Closure of Relational Operators. InProceedings of the 12th International Conference on Very Large Data Bases (VLDB ’86). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 403–411
1986
-
[17]
Kasra Jamshidi, Rakesh Mahadasa, and Keval Vora. 2020. Peregrine: a pattern-aware graph mining system. InProceedings of the Fifteenth European Conference on Computer Systems(Heraklion, Greece)(Eu- roSys ’20). Association for Computing Machinery, New York, NY, USA, Article 13, 16 pages. doi:10.1145/3342195.3387548
-
[18]
Herbert Jordan, Bernhard Scholz, and Pavle Subotić. 2016. Soufflé: On synthesis of program analyzers. InInternational Conference on Computer Aided Verification. Springer, 422–430
2016
- [19]
-
[20]
Farzad Khorasani, Keval Vora, Rajiv Gupta, and Laxmi N. Bhuyan
-
[21]
Enabling Work-Efficiency for High Performance Vertex-Centric Graph Analytics on GPUs. InProceedings of the Seventh Workshop on Irregular Applications: Architectures and Algorithms(Denver, CO, USA) (IA3’17). Association for Computing Machinery, New York, NY, USA, Article 11, 4 pages. doi:10.1145/3149704.3149762
-
[22]
Zhuohang Lai, Xibo Sun, Qiong Luo, and Xiaolong Xie. 2022. Accel- erating multi-way joins on the GPU.The VLDB Journal31, 3 (2022), 529–553
2022
-
[23]
Yinan Li, Bailu Ding, Ziyun Wei, Lukas M. Maas, Momin Al-Ghosien, Spyros Blanas, Nicolas Bruno, Carlo Curino, Matteo Interlandi, Craig Scaling Worst-Case Optimal Datalog to GPUs Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Peeper, Kaushik Rajan, Surajit Chaudhuri, and Johannes Gehrke. 2025. Scaling GPU-Accelerated Databases Beyond GPU Memory Si...
-
[24]
Ziyang Li, Jiani Huang, and Mayur Naik. 2023. Scallop: A language for neurosymbolic programming.Proceedings of the ACM on Programming Languages7, PLDI (2023), 1463–1487
2023
-
[25]
Mugilan Mariappan, Joanna Che, and Keval Vora. 2021. DZiG: sparsity- aware incremental processing of streaming graphs. InProceedings of the Sixteenth European Conference on Computer Systems(Online Event, United Kingdom)(EuroSys ’21). Association for Computing Machinery, New York, NY, USA, 83–98. doi:10.1145/3447786.3456230
-
[26]
Mugilan Mariappan and Keval Vora. 2019. GraphBolt: Dependency- Driven Synchronous Processing of Streaming Graphs. InProceedings of the Fourteenth EuroSys Conference 2019(Dresden, Germany)(Eu- roSys ’19). Association for Computing Machinery, New York, NY, USA, Article 25, 16 pages. doi:10.1145/3302424.3303974
-
[27]
Carlos Alberto Martínez-Angeles, Inês Dutra, Vítor Santos Costa, and Jorge Buenabad-Chávez. 2013. A datalog engine for gpus. InInter- national Conference on Applications of Declarative Programming and Knowledge Management. Springer, 152–168
2013
-
[28]
Frank McSherry, Derek Gordon Murray, Rebecca Isaacs, and Michael Isard. 2013. Differential dataflow.. InCIDR
2013
-
[29]
Amine Mhedhbi, Matteo Lissandrini, Laurens Kuiper, Jack Waudby, and Gábor Szárnyas. 2021. LSQB: a large-scale subgraph query bench- mark. InProceedings of the 4th ACM SIGMOD Joint International Work- shop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA)(Virtual Event, China)(GRADES- NDA ’21). Association for Computi...
-
[30]
Yavor Nenov, Robert Piro, Boris Motik, Ian Horrocks, Zhe Wu, and Jay Banerjee. 2015. RDFox: A highly-scalable RDF store. InInternational Semantic Web Conference. Springer, 3–20
2015
-
[31]
Hung Q Ngo, Ely Porat, Christopher Ré, and Atri Rudra. 2018. Worst- case optimal join algorithms.Journal of the ACM (JACM)65, 3 (2018), 1–40
2018
-
[32]
Hung Q Ngo, Christopher Ré, and Atri Rudra. 2014. Skew strikes back: new developments in the theory of join algorithms.Acm Sigmod Record42, 4 (2014), 5–16
2014
-
[33]
Sungwoo Park, Seyeon Oh, and Min-Soo Kim. 2025. cuMatch: A GPU- based Memory-Efficient Worst-case Optimal Join Processing Method for Subgraph Queries with Complex Patterns.Proc. ACM Manag. Data 3, 3, Article 143 (June 2025), 28 pages. doi:10.1145/3725398
-
[34]
Ran Rui and Yi-Cheng Tu. 2017. Fast Equi-Join Algorithms on GPUs: Design and Implementation. InProceedings of the 29th International Conference on Scientific and Statistical Database Management(Chicago, IL, USA)(SSDBM ’17). Association for Computing Machinery, New York, NY, USA, Article 17, 12 pages. doi:10.1145/3085504.3085521
-
[35]
Arash Sahebolamri, Thomas Gilray, and Kristopher Micinski. 2022. Seamless deductive inference via macros. InProceedings of the 31st ACM SIGPLAN International Conference on Compiler Construction. 77– 88
2022
-
[36]
Nadathur Satish, Mark Harris, and Michael Garland. 2009. Designing efficient sorting algorithms for manycore GPUs. In2009 IEEE Interna- tional Symposium on Parallel & Distributed Processing. IEEE, 1–10
2009
-
[37]
Bernhard Scholz, Herbert Jordan, Pavle Subotić, and Till Westmann
-
[38]
InProceedings of the 25th International Conference on Compiler Construction
On fast large-scale program analysis in datalog. InProceedings of the 25th International Conference on Compiler Construction. 196–206
-
[39]
Jiwon Seo, Stephen Guo, and Monica S Lam. 2013. SociaLite: Datalog extensions for efficient social network analysis. In2013 IEEE 29th International Conference on Data Engineering (ICDE). IEEE, 278–289
2013
-
[40]
Bishal Sharma and Martin Burtscher. 2025. Profiling Application- Specific Properties of Irregular Graph Algorithms on GPUs. InPro- ceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC Workshops ’25). Association for Computing Machinery, New York, NY, USA, 784–792. doi:10.1145...
-
[41]
Ahmedur Rahman Shovon, Yihao Sun, Kristopher Micinski, Thomas Gilray, and Sidharth Kumar. 2025. Multi-node multi-gpu datalog. In Proceedings of the 39th ACM International Conference on Supercomput- ing. 822–836
2025
-
[42]
Yihao Sun, Sidharth Kumar, Thomas Gilray, and Kristopher Micinski
-
[43]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
Column-Oriented Datalog on the GPU. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 15177–15185
-
[44]
Yihao Sun, Sidharth Kumar, Thomas Gilray, and Kristopher Micin- ski. 2025. Column-oriented datalog on the GPU. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty- Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelli- gence (AAAI’2...
-
[45]
Yihao Sun, Ahmedur Rahman Shovon, Thomas Gilray, Sidharth Kumar, and Kristopher Micinski. 2025. Optimizing Datalog for the GPU. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 762–776
2025
-
[46]
Todd L Veldhuizen. 2014. Leapfrog triejoin: A simple, worst-case optimal join algorithm. InProc. International Conference on Database Theory
2014
-
[47]
Junxiong Wang, Immanuel Trummer, Ahmet Kara, and Dan Olteanu
-
[48]
VLDB Endow.16, 11 (July 2023), 2805–2817
ADOPT: Adaptively Optimizing Attribute Orders for Worst-Case Optimal Join Algorithms via Reinforcement Learning.Proc. VLDB Endow.16, 11 (July 2023), 2805–2817. doi:10.14778/3611479.3611489
-
[49]
Yisu Remy Wang, Max Willsey, and Dan Suciu. 2023. Free join: Unify- ing worst-case optimal and traditional joins.Proceedings of the ACM on Management of Data1, 2 (2023), 1–23
2023
-
[50]
John Whaley, Dzintars Avots, Michael Carbin, and Monica S. Lam. 2005. Using datalog with binary decision diagrams for program analysis. In Proceedings of the Third Asian Conference on Programming Languages and Systems(Tsukuba, Japan)(APLAS’05). Springer-Verlag, Berlin, Heidelberg, 97–118. doi:10.1007/11575467_8
-
[51]
Bowen Wu, Dimitrios Koutsoukos, and Gustavo Alonso. 2025. Effi- ciently Processing Joins and Grouped Aggregations on GPUs.Proc. ACM Manag. Data3, 1, Article 39 (Feb. 2025), 27 pages. doi:10.1145/ 3709689
2025
-
[52]
Jiacheng Wu and Dan Suciu. 2025. HoneyComb: A Parallel Worst-Case Optimal Join on Multicores.Proceedings of the ACM on Management of Data3, 3 (2025), 1–27
2025
-
[53]
Bobbi Yogatama, Weiwei Gong, and Xiangyao Yu. 2024. Scaling your Hybrid CPU-GPU DBMS to Multiple GPUs.Proc. VLDB Endow.17, 13 (Sept. 2024), 4709–4722. doi:10.14778/3704965.3704977
-
[54]
Yogatama, Weiwei Gong, and Xiangyao Yu
Bobbi W. Yogatama, Weiwei Gong, and Xiangyao Yu. 2022. Or- chestrating data placement and query execution in heterogeneous CPU-GPU DBMS.Proc. VLDB Endow.15, 11 (July 2022), 2491–2503. doi:10.14778/3551793.3551809
- [55]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.