Recognition: unknown
Pairing Regularization for Mitigating Many-to-One Collapse in GANs
Pith reviewed 2026-05-10 00:52 UTC · model grok-4.3
The pith
A pairing regularizer mitigates many-to-one collapse in GANs by enforcing local consistency between latent variables and generated samples, with effects depending on the dominant training failure mode.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
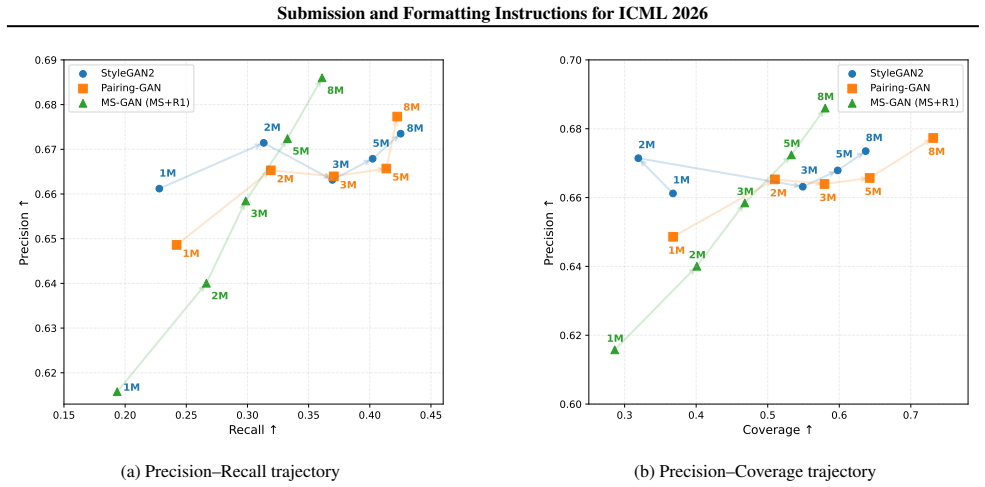
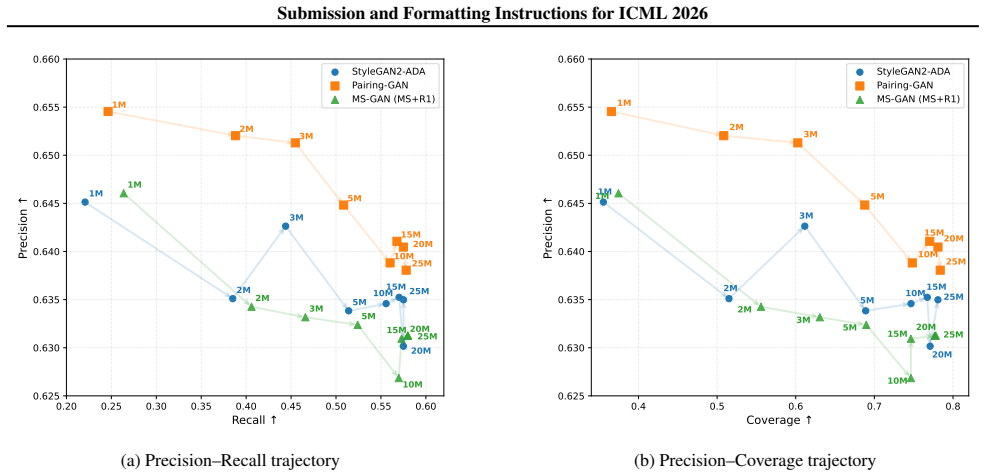
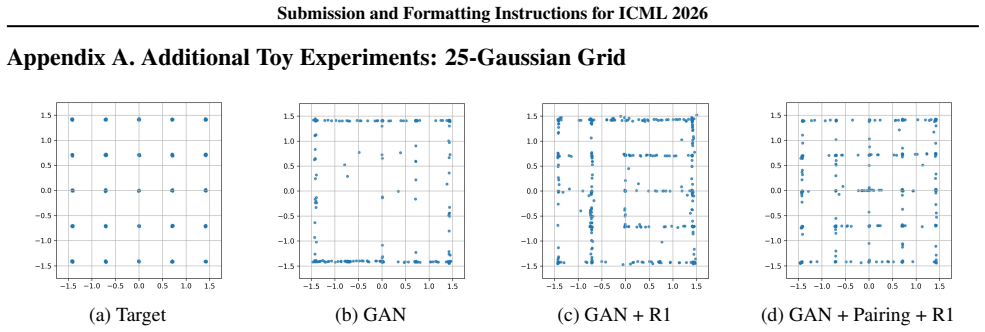
We introduce a pairing regularizer jointly optimized with the generator that mitigates many-to-one collapse by enforcing local consistency between latent variables and generated samples. In collapse-prone regimes with limited exploration the regularizer encourages structured local exploration and raises recall; under stabilized training with sufficient exploration it discourages redundant mappings and improves precision without loss of recall. Experiments on toy distributions and real-image benchmarks confirm that the regularizer complements existing stabilization techniques by directly addressing intra-mode collapse.
What carries the argument
The pairing regularizer, which enforces local consistency between latent variables and generated samples to reduce many-to-one mappings.
If this is right
- In collapse-prone regimes the regularizer improves coverage and raises recall.
- Under stabilized training the regularizer improves precision without reducing recall.
- The regularizer can be added to existing GAN stabilization methods to address intra-mode collapse directly.
- The same pairing approach yields measurable gains on both toy distributions and real-image datasets.
Where Pith is reading between the lines
- The regime-dependent behavior implies that monitoring collapse indicators during training could decide when to activate the regularizer.
- Pairing ideas might transfer to other latent-variable models that suffer from output redundancy.
- The local-consistency term could be combined with latent-space regularization techniques to further control mapping diversity.
Load-bearing premise
The pairing regularizer can be jointly optimized with the standard GAN objective without introducing new training instabilities or requiring regime-specific hyperparameter schedules.
What would settle it
Run identical GAN training runs with and without the pairing term on a benchmark known to exhibit intra-mode collapse and measure whether recall rises in unstable settings or precision rises in stable settings while recall stays flat.
Figures





read the original abstract
Mode collapse remains a fundamental challenge in training generative adversarial networks (GANs). While existing works have primarily focused on inter-mode collapse, such as mode dropping, intra-mode collapse-where many latent variables map to the same or highly similar outputs-has received significantly less attention. In this work, we propose a pairing regularizer jointly optimized with the generator to mitigate the many-to-one collapse by enforcing local consistency between latent variables and generated samples. We show that the effect of pairing regularization depends on the dominant failure mode of training. In collapse-prone regimes with limited exploration, pairing encourages structured local exploration, leading to improved coverage and higher recall. In contrast, under stabilized training with sufficient exploration, pairing refines the generator's induced data density by discouraging redundant mappings, thereby improving precision without sacrificing recall. Extensive experiments on both toy distributions and real-image benchmarks demonstrate that the proposed regularizer effectively complements existing stabilization techniques by directly addressing intra-mode collapse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a pairing regularizer that is jointly optimized with the standard GAN generator objective to mitigate intra-mode (many-to-one) collapse. It claims that the regularizer produces qualitatively different benefits depending on the dominant training failure mode: in collapse-prone regimes it promotes structured local exploration and raises recall, while in stabilized regimes it discourages redundant mappings and raises precision without harming recall. The method is evaluated on toy distributions and real-image benchmarks and is presented as complementary to existing stabilization techniques.
Significance. Intra-mode collapse has received less attention than inter-mode collapse; a simple, jointly optimized regularizer that demonstrably improves coverage or fidelity according to training regime would be a useful practical contribution. If the regime-dependent mechanism is shown to be robust and the improvements are supported by quantitative metrics and ablations, the work could influence how practitioners combine regularization with existing GAN stabilizers.
major comments (2)
- [Abstract] The central claim that the pairing regularizer yields recall gains in collapse-prone regimes and precision gains in stabilized regimes is load-bearing, yet the manuscript provides no a-priori diagnostic for identifying the dominant failure mode nor a schedule for the pairing coefficient. Without such a mechanism, the reported improvements cannot be unambiguously attributed to the claimed interaction rather than to post-hoc hyper-parameter selection (see Abstract and the description of joint optimization).
- [Abstract] The weakest assumption—that the regularizer can be added to the standard GAN objective without introducing new instabilities or requiring regime-specific tuning—is not supported by any analysis of training dynamics or sensitivity to the pairing strength. If the coefficient is fixed across all experiments, the regime-dependent narrative remains non-operational.
minor comments (2)
- [Abstract] The abstract states that 'extensive experiments' were performed but supplies no quantitative metrics, ablation tables, or implementation details; these should be summarized with specific numbers and baselines even in the abstract.
- Notation for the pairing loss and its integration into the generator objective should be introduced with an equation in the main text rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting key aspects of our claims on the pairing regularizer. We address each major comment below and propose revisions to clarify the regime-dependent effects and provide supporting analyses.
read point-by-point responses
-
Referee: [Abstract] The central claim that the pairing regularizer yields recall gains in collapse-prone regimes and precision gains in stabilized regimes is load-bearing, yet the manuscript provides no a-priori diagnostic for identifying the dominant failure mode nor a schedule for the pairing coefficient. Without such a mechanism, the reported improvements cannot be unambiguously attributed to the claimed interaction rather than to post-hoc hyper-parameter selection (see Abstract and the description of joint optimization).
Authors: We agree that an explicit a-priori diagnostic would strengthen attribution of the observed effects. In the revised manuscript, we will add a dedicated subsection discussing practical identification of the dominant failure mode, for example via monitoring of recall or sample diversity metrics during training. The pairing coefficient is fixed across all reported experiments to emphasize general applicability without regime-specific schedules; we will include a new ablation study demonstrating robustness of the benefits over a range of coefficient values. These additions will help distinguish the regularizer's interaction with training regimes from hyperparameter selection. revision: yes
-
Referee: [Abstract] The weakest assumption—that the regularizer can be added to the standard GAN objective without introducing new instabilities or requiring regime-specific tuning—is not supported by any analysis of training dynamics or sensitivity to the pairing strength. If the coefficient is fixed across all experiments, the regime-dependent narrative remains non-operational.
Authors: We acknowledge the absence of explicit training dynamics analysis in the current version. The revised manuscript will add training curve visualizations and sensitivity ablations on the pairing strength to confirm that the regularizer integrates without introducing instabilities and that a single fixed coefficient produces the reported benefits in both collapse-prone and stabilized setups. The regime-dependent narrative is operationalized through separate experimental protocols (base GAN with vs. without stabilization), where quantitative recall and precision metrics show the distinct effects; the added analyses will further substantiate this without requiring per-regime retuning. revision: yes
Circularity Check
Empirical proposal with no derivation chain or self-referential predictions
full rationale
The paper introduces a pairing regularizer as a practical addition to the GAN objective and reports its observed effects on recall and precision across different training regimes. These effects are presented as empirical outcomes from experiments on toy distributions and image benchmarks, not as quantities derived from equations, fitted parameters renamed as predictions, or self-citations that close a logical loop. No mathematical derivation, uniqueness theorem, or ansatz is invoked in the provided text, so the central claims remain independent of the inputs by construction. The regime-dependent distinction is framed observationally rather than as a load-bearing prediction that reduces to the regularizer itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
2009 , journal=
Learning multiple layers of features from tiny images , author=. 2009 , journal=
2009
-
[3]
Advances in neural information processing systems , volume=
UniGAN: Reducing mode collapse in GANs using a uniform generator , author=. Advances in neural information processing systems , volume=
-
[4]
International Conference on Artificial Intelligence and Statistics , pages=
Testing Generated Distributions in GANs to Penalize Mode Collapse , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[6]
Artificial Intelligence , volume=
DivGAN: A diversity enforcing generative adversarial network for mode collapse reduction , author=. Artificial Intelligence , volume=. 2023 , publisher=
2023
-
[7]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Seeing what a gan cannot generate , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[10]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scaling up gans for text-to-image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[11]
Advances in neural information processing systems , volume=
Differentiable augmentation for data-efficient gan training , author=. Advances in neural information processing systems , volume=
-
[12]
Advances in neural information processing systems , volume=
Improved precision and recall metric for assessing generative models , author=. Advances in neural information processing systems , volume=
-
[13]
International conference on machine learning , pages=
Reliable fidelity and diversity metrics for generative models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[15]
International conference on machine learning , pages=
Which training methods for GANs do actually converge? , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[16]
Advances in neural information processing systems , volume=
Infogan: Interpretable representation learning by information maximizing generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[17]
Advances in neural information processing systems , volume=
Improved training of wasserstein gans , author=. Advances in neural information processing systems , volume=
-
[18]
2017 , eprint=
Wasserstein GAN , author=. 2017 , eprint=
2017
-
[19]
arXiv preprint arXiv:1807.00734 , year =
The Relativistic Discriminator: A Key Element Missing from Standard GAN , author =. arXiv preprint arXiv:1807.00734 , year =
-
[20]
Advances in Neural Information Processing Systems , volume=
The gan is dead; long live the gan! a modern gan baseline , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[22]
On the Convergence and Stability of
Mescheder, Lars and Geiger, Andreas and Nowozin, Sebastian , booktitle =. On the Convergence and Stability of. 2018 , editor =
2018
-
[23]
Advances in Neural Information Processing Systems , year=
Assessing Generative Models via Precision and Recall , author=. Advances in Neural Information Processing Systems , year=
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Training Generative Adversarial Networks with Limited Data , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[26]
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle=
-
[27]
Consistency Models , author=. arXiv:2303.01469 , year=
work page internal anchor Pith review arXiv
-
[28]
ICLR , year=
Flow Matching for Generative Modeling , author=. ICLR , year=
-
[29]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Large Scale GAN Training for High Fidelity Natural Image Synthesis , author=. arXiv preprint arXiv:1809.11096 , year=
work page internal anchor Pith review arXiv
-
[30]
Jiang, Yifan and Chang, Shiyu and Wang, Zhangyang , booktitle=
-
[31]
Lee, Kwonjoon and Chang, Huiwen and Jiang, Lu and Zhang, Han and Tu, Zhuowen and Liu, Ce , booktitle=
-
[32]
Tackling the Generative Learning Trilemma with Denoising Diffusion
Xiao, Zhisheng and Kreis, Karsten and Vahdat, Arash , booktitle=. Tackling the Generative Learning Trilemma with Denoising Diffusion
-
[33]
Wang, Zhendong and Zheng, Huangjie and He, Pengcheng and Chen, Weizhu and Zhou, Mingyuan , booktitle=
-
[34]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Alias-Free Generative Adversarial Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[35]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Denoising Diffusion Probabilistic Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[36]
International Conference on Learning Representations (ICLR) , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[37]
International Conference on Learning Representations (ICLR) , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations (ICLR) , year=
-
[38]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Improved Techniques for Training Score-Based Generative Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[39]
The Role of ImageNet Classes in Fr
Kynk. The Role of ImageNet Classes in Fr. International Conference on Learning Representations (ICLR) , year=
-
[40]
Sauer, Axel and Schwarz, Katja and Geiger, Andreas , booktitle=
-
[41]
2025 , eprint=
The GAN is dead; long live the GAN! A Modern GAN Baseline , author=. 2025 , eprint=
2025
-
[42]
International Conference on Learning Representations (ICLR) , year=
Unsupervised representation learning with deep convolutional generative adversarial networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[43]
Advances in Neural Information Processing Systems (NeurIPS) , year=
VEEGAN: Reducing mode collapse in GANs using implicit variational learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Improved training of Wasserstein GANs , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[45]
Advances in Neural Information Processing Systems (NeurIPS) , year=
PacGAN: The power of two samples in generative adversarial networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[46]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Analyzing and improving the image quality of StyleGAN , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[47]
International Conference on Learning Representations (ICLR) , year=
PresGAN: Towards probabilistic generative adversarial networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[48]
Uncertainty in Artificial Intelligence (UAI) , year=
Sliced score matching: A scalable approach to density and score estimation , author=. Uncertainty in Artificial Intelligence (UAI) , year=
-
[49]
Advances in Neural Information Processing Systems (NeurIPS) , year=
VAEBM: A symbiosis between variational autoencoders and energy-based models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) , year=
DDGAN: Denoising diffusion GANs , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[51]
Advances in Neural Information Processing Systems (NeurIPS) , year=
MEG: Masked Energy-based Generative Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[52]
Communications of the ACM , volume=
Generative adversarial networks , author=. Communications of the ACM , volume=. 2020 , publisher=
2020
-
[53]
International Conference on Learning Representations (ICLR) , year =
Takeru Miyato and Toshiki Kataoka and Masanori Koyama and Yuichi Yoshida , title =. International Conference on Learning Representations (ICLR) , year =
-
[54]
Dai and Shakir Mohamed and Ian Goodfellow , title =
William Fedus and Mihaela Rosca and Balaji Lakshminarayanan and Andrew M. Dai and Shakir Mohamed and Ian Goodfellow , title =. International Conference on Learning Representations (ICLR) , year =
-
[55]
Diffusion- GAN: Training gans with diffusion
Diffusion-GAN: Training GANs with Diffusion , author =. arXiv preprint arXiv:2206.02262 , year =
-
[56]
Towards Principled Methods for Training Generative Adversarial Networks , booktitle =
Mart. Towards Principled Methods for Training Generative Adversarial Networks , booktitle =. 2017 , publisher =
2017
-
[57]
Amortised
Casper Kaae S. Amortised. 5th International Conference on Learning Representations (ICLR) , year =
-
[58]
5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings , year=
Towards Principled Methods for Training Generative Adversarial Networks , author=. 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings , year=
2017
-
[59]
arXiv preprint arXiv:1610.04490 , year=
Amortised MAP Inference for Image Super-resolution , author=. arXiv preprint arXiv:1610.04490 , year=
-
[60]
Proceedings of the 35th International Conference on Machine Learning , volume=
Which Training Methods for GANs do actually Converge? , author=. Proceedings of the 35th International Conference on Machine Learning , volume=. 2018 , url=
2018
-
[61]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[62]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[63]
M. J. Kearns , title =
-
[64]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[65]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[66]
Suppressed for Anonymity , author=
-
[67]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[68]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[69]
Divgan: A diversity enforcing generative adversarial network for mode collapse reduction
Allahyani, M., Alsulami, R., Alwafi, T., Alafif, T., Ammar, H., Sabban, S., and Chen, X. Divgan: A diversity enforcing generative adversarial network for mode collapse reduction. Artificial Intelligence, 317: 0 103863, 2023
2023
-
[70]
Wasserstein gan, 2017
Arjovsky, M., Chintala, S., and Bottou, L. Wasserstein gan, 2017
2017
-
[71]
Seeing what a gan cannot generate
Bau, D., Zhu, J.-Y., Wulff, J., Peebles, W., Strobelt, H., Zhou, B., and Torralba, A. Seeing what a gan cannot generate. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 4502--4511, 2019
2019
-
[72]
Infogan: Interpretable representation learning by information maximizing generative adversarial nets
Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., and Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Advances in neural information processing systems, 29, 2016
2016
-
[73]
arXiv preprint arXiv:1605.09782 , year=
Donahue, J., Kr \"a henb \"u hl, P., and Darrell, T. Adversarial feature learning. arXiv preprint arXiv:1605.09782, 2016
-
[74]
Testing generated distributions in gans to penalize mode collapse
Gong, Y., Xie, Z., Xie, M., and Ma, X. Testing generated distributions in gans to penalize mode collapse. In International Conference on Artificial Intelligence and Statistics, pp.\ 442--450. PMLR, 2024
2024
-
[75]
Generative adversarial networks
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial networks. Communications of the ACM, 63 0 (11): 0 139--144, 2020
2020
-
[76]
The gan is dead; long live the gan! a modern gan baseline
Huang, N., Gokaslan, A., Kuleshov, V., and Tompkin, J. The gan is dead; long live the gan! a modern gan baseline. Advances in Neural Information Processing Systems, 37: 0 44177--44215, 2024
2024
-
[77]
Scaling up gans for text-to-image synthesis
Kang, M., Zhu, J.-Y., Zhang, R., Park, J., Shechtman, E., Paris, S., and Park, T. Scaling up gans for text-to-image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10124--10134, 2023
2023
-
[78]
Training generative adversarial networks with limited data
Karras, T., Aittala, M., Hellsten, J., Laine, S., Lehtinen, J., and Aila, T. Training generative adversarial networks with limited data. In Advances in Neural Information Processing Systems (NeurIPS), 2020 a
2020
-
[79]
Analyzing and improving the image quality of stylegan
Karras, T., Laine, S., and Aila, T. Analyzing and improving the image quality of stylegan. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020 b
2020
-
[80]
Learning multiple layers of features from tiny images
Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. Thesis, 2009
2009
-
[81]
Improved precision and recall metric for assessing generative models
Kynk \"a \"a nniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. Improved precision and recall metric for assessing generative models. Advances in neural information processing systems, 32, 2019
2019
-
[82]
Mode seeking generative adversarial networks for diverse image synthesis
Mao, Q., Lee, H.-Y., Tseng, H.-Y., Ma, S., and Yang, M.-H. Mode seeking generative adversarial networks for diverse image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[83]
Which training methods for gans do actually converge? In International conference on machine learning, pp.\ 3481--3490
Mescheder, L., Geiger, A., and Nowozin, S. Which training methods for gans do actually converge? In International conference on machine learning, pp.\ 3481--3490. PMLR, 2018 a
2018
- [84]
-
[85]
Spectral Normalization for Generative Adversarial Networks
Miyato, T., Kataoka, T., Koyama, M., and Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018
work page Pith review arXiv 2018
-
[86]
F., Oh, S
Naeem, M. F., Oh, S. J., Uh, Y., Choi, Y., and Yoo, J. Reliable fidelity and diversity metrics for generative models. In International conference on machine learning, pp.\ 7176--7185. PMLR, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.