Recognition: unknown
Pre-Execution Query Slot-Time Prediction in Cloud Data Warehouses: A Feature-Scoped Machine Learning Approach
Pith reviewed 2026-05-09 23:22 UTC · model grok-4.3
The pith
A machine learning model predicts BigQuery slot-time before execution using only pre-execution signals from query structure and planner estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
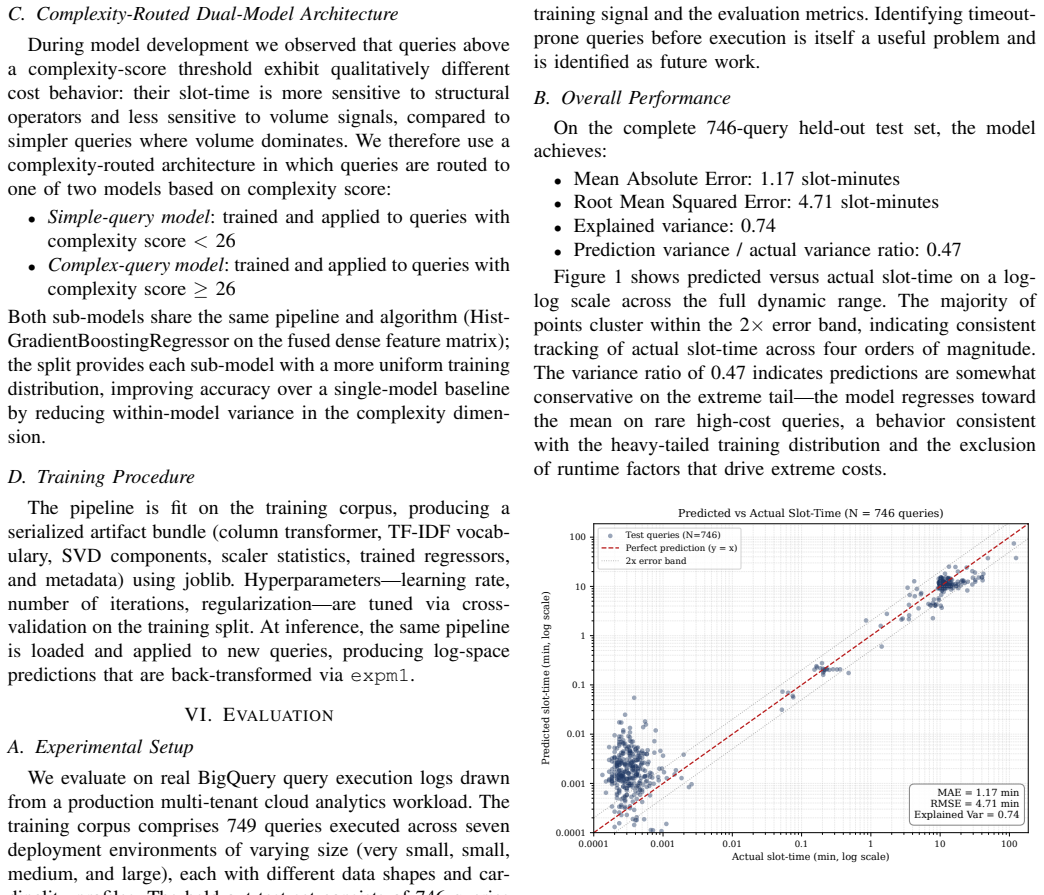
A HistGradientBoostingRegressor trained on pre-execution features achieves an MAE of 1.17 slot-minutes and 74 percent explained variance across the full test workload, while reducing MAE from 4.95 to 3.10 slot-minutes on queries whose slot-time is at least 0.01 minutes, a 30-37 percent improvement over mean and median baselines; the same model shows no advantage on queries exceeding 20 minutes, consistent with the claim that long-tail behavior is driven by runtime conditions excluded from the feature set.
What carries the argument
A feature-scoped pipeline that combines a structured query complexity score, planner data-volume estimates, and TF-IDF-plus-TruncatedSVD text features inside a HistGradientBoostingRegressor to predict log-transformed slot-time.
Load-bearing premise
Signals observable before execution, such as query text and planner estimates, contain enough information to predict actual slot-time even when runtime contention and cache state are unknown.
What would settle it
A controlled experiment that adds current slot-pool utilization and cache-state features to the model and measures whether error on the long-tail queries drops substantially below the current baseline performance.
Figures

read the original abstract
Cloud data warehouses bill compute based on slot-time consumed. In shared multi-tenant environments, query cost is highly variable and hard to estimate before execution, causing budget overruns and degraded scheduling. Static query-planner heuristics fail to capture complex SQL structure, data skew, and workload contention. We present a feature-scoped machine learning approach that predicts BigQuery slot-time before execution using only pre-execution observable signals: a structured query complexity score derived from SQL operator costs, data volume features from planner estimates and workload metadata, and textual features from query text. We deliberately exclude runtime factors (slot-pool utilization, cache state, realized skew) unknowable at submission. The model uses a HistGradientBoostingRegressor trained on log-transformed slot-time, with a TF-IDF + TruncatedSVD-512 text pipeline fused with numeric and categorical features. Trained on 749 queries across seven deployment environments and evaluated out-of-distribution on 746 queries from two held-out environments, the model achieves MAE 1.17 slot-minutes, RMSE 4.71, and 74% explained variance on the full workload. On cost-significant queries (slot-time >= 0.01 min, N=282) the model achieves MAE 3.10 versus 4.95 for a predict-mean baseline and 4.54 for predict-median, a 30-37% reduction. On long-tail queries (>= 20 min, N=22) the model does not outperform trivial baselines, consistent with the hypothesis that long-tail queries are dominated by unobserved runtime factors outside the current feature scope. A complexity-routed dual-model architecture is described as a practical refinement, and directions for closing the long-tail gap are identified as future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a feature-scoped ML approach to predict BigQuery slot-time before execution using only pre-execution signals: a structured query complexity score from SQL operators, planner data-volume estimates, workload metadata, and TF-IDF+TruncatedSVD textual features from the query. A HistGradientBoostingRegressor is trained on log-transformed targets and evaluated out-of-distribution on 746 queries from two held-out environments after training on 749 queries from seven environments. It reports overall MAE 1.17, RMSE 4.71, and 74% explained variance; on cost-significant queries (slot-time >=0.01 min, N=282) MAE improves to 3.10 versus 4.95 (mean) and 4.54 (median) baselines (30-37% reduction). On long-tail queries (>=20 min, N=22) the model does not beat baselines, which the authors attribute to excluded runtime factors (slot-pool utilization, cache state, realized skew) and flag as future work, along with a complexity-routed dual-model refinement.
Significance. If the long-tail gap can be closed while preserving the pre-execution constraint, the work would provide a practical tool for reducing budget overruns and improving scheduling in multi-tenant cloud data warehouses. The explicit scoping of features to observables at submission time and the out-of-distribution evaluation across deployment environments are strengths that increase confidence in generalization within the current feature scope. The transparent reporting of failure on high-cost queries also usefully bounds the claims.
major comments (3)
- [Abstract] Abstract: The central claim that pre-execution signals suffice for accurate slot-time prediction is undermined by the reported result that the model does not outperform mean/median baselines on long-tail queries (>=20 min, N=22). Because these queries drive the most severe budget overruns and scheduling problems, this is a load-bearing limitation for the use case; the small N=22 also limits statistical reliability of the conclusion that runtime factors are the sole cause.
- [Abstract] Abstract / Methods: No derivation, validation, or sensitivity analysis is provided for the structured query complexity score derived from SQL operator costs, which is presented as a core component of the feature set. Without this, it is impossible to assess whether the score is reproducible or whether it meaningfully captures the intended aspects of query structure.
- [Evaluation] Evaluation: No ablation of feature groups (complexity score, planner estimates, metadata, text), no hyperparameter settings for HistGradientBoostingRegressor or TruncatedSVD-512, and no error bars or confidence intervals accompany the MAE/RMSE and 74% explained-variance figures. These omissions make it difficult to judge the robustness of the 30-37% improvement on the N=282 cost-significant queries.
minor comments (1)
- [Abstract] The abstract states that a complexity-routed dual-model architecture is described as a practical refinement, but no details on the routing logic, threshold, or performance of the dual model are supplied in the provided text.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments correctly identify areas where additional detail and analysis would strengthen the manuscript. We address each major comment below, indicating where revisions will be made to improve clarity, reproducibility, and robustness while preserving the paper's core contributions and honest scoping of pre-execution features.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that pre-execution signals suffice for accurate slot-time prediction is undermined by the reported result that the model does not outperform mean/median baselines on long-tail queries (>=20 min, N=22). Because these queries drive the most severe budget overruns and scheduling problems, this is a load-bearing limitation for the use case; the small N=22 also limits statistical reliability of the conclusion that runtime factors are the sole cause.
Authors: We agree this is an important limitation and have already flagged it explicitly in the manuscript as arising from runtime factors outside our pre-execution feature scope. The N=22 reflects the natural rarity of such queries in the production dataset; while this limits statistical power, the result is consistent with our hypothesis and bounds the claims appropriately. The primary use-case improvements (30-37% on cost-significant queries) remain valid. We will expand the abstract and discussion to more prominently qualify the scope, add a brief power analysis note for the tail, and elaborate on the complexity-routed dual-model refinement as a practical path forward. revision: partial
-
Referee: [Abstract] Abstract / Methods: No derivation, validation, or sensitivity analysis is provided for the structured query complexity score derived from SQL operator costs, which is presented as a core component of the feature set. Without this, it is impossible to assess whether the score is reproducible or whether it meaningfully captures the intended aspects of query structure.
Authors: The score is a linear combination of operator counts weighted by standard BigQuery cost heuristics (e.g., join, aggregate, scan costs). We will add a dedicated subsection in Methods with the exact formula, operator mapping table, and rationale. We will also include a sensitivity analysis varying the weights by ±20% and reporting the resulting change in model MAE/RMSE on the held-out set to demonstrate robustness. revision: yes
-
Referee: [Evaluation] Evaluation: No ablation of feature groups (complexity score, planner estimates, metadata, text), no hyperparameter settings for HistGradientBoostingRegressor or TruncatedSVD-512, and no error bars or confidence intervals accompany the MAE/RMSE and 74% explained-variance figures. These omissions make it difficult to judge the robustness of the 30-37% improvement on the N=282 cost-significant queries.
Authors: We will add (1) a feature-group ablation table showing incremental performance when adding complexity score, planner estimates, metadata, and text features; (2) the full hyperparameter configuration for HistGradientBoostingRegressor (learning_rate=0.05, max_depth=6, etc.) and TruncatedSVD (n_components=512, random_state=42); and (3) bootstrap 95% confidence intervals for all reported MAE, RMSE, and explained-variance metrics on both the full and cost-significant subsets. revision: yes
Circularity Check
No circularity: standard supervised ML evaluation on held-out data
full rationale
The paper reports an empirical machine learning regression (HistGradientBoostingRegressor) trained on 749 queries from seven environments and evaluated on 746 queries from two held-out environments. Performance numbers (MAE, RMSE, explained variance, and baseline comparisons) are obtained via standard train/test split and out-of-distribution evaluation; no derivation, equation, or claim reduces by construction to its own fitted inputs or to a self-citation chain. The explicit acknowledgment that long-tail queries are not predicted well because runtime factors were deliberately excluded is transparent rather than circular. No self-definitional, fitted-input-renamed-as-prediction, or uniqueness-imported steps appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (3)
- TruncatedSVD components =
512
- Target transformation
- HistGradientBoosting hyperparameters
axioms (1)
- domain assumption Pre-execution signals suffice for useful slot-time prediction
Reference graph
Works this paper leans on
-
[1]
Neo: A learned query optimizer,
R. Marcus et al., “Neo: A learned query optimizer,”PVLDB, vol. 12, no. 11, pp. 1705–1718, 2019
2019
-
[2]
Bao: Making learned query optimization practical,
R. Marcus et al., “Bao: Making learned query optimization practical,” inProc. ACM SIGMOD, 2021, pp. 1275–1288
2021
-
[3]
Learned cardinalities: Estimating correlated joins with deep learning,
A. Kipf, T. Kipf, B. Radke, V . Leis, P. Boncz, and A. Kemper, “Learned cardinalities: Estimating correlated joins with deep learning,” inProc. CIDR, 2019
2019
-
[4]
Access path selection in a relational database management system,
P. G. Selinger et al., “Access path selection in a relational database management system,” inProc. ACM SIGMOD, 1979, pp. 23–34
1979
-
[5]
Greedy function approximation: A gradient boosting machine,
J. H. Friedman, “Greedy function approximation: A gradient boosting machine,”Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, 2001
2001
-
[6]
Amazon Redshift re-invented,
N. Armenatzoglou et al., “Amazon Redshift re-invented,” inProc. ACM SIGMOD, 2022, pp. 2205–2217
2022
-
[7]
Dremel: A decade of interactive SQL analysis at web scale,
S. Melnik et al., “Dremel: A decade of interactive SQL analysis at web scale,”PVLDB, vol. 13, no. 12, pp. 3461–3472, 2020
2020
-
[8]
The Snowflake elastic data warehouse,
B. Dageville et al., “The Snowflake elastic data warehouse,” inProc. ACM SIGMOD, 2016, pp. 215–226
2016
-
[9]
Amazon Aurora: Design considerations for high- throughput cloud-native relational databases,
A. Verbitski et al., “Amazon Aurora: Design considerations for high- throughput cloud-native relational databases,” inProc. ACM SIGMOD, 2017, pp. 1041–1052
2017
-
[10]
Towards multi-tenant performance SLOs,
W. Lang, S. Shankar, J. M. Patel, and A. Kalhan, “Towards multi-tenant performance SLOs,” inProc. IEEE ICDE, 2012, pp. 702–713
2012
-
[11]
Heuristic Search Space Partitioning for Low-Latency Multi-Tenant Cloud Queries
P. K. Pathak, C. B. Mouleeswaran, and R. T. Repaka, “Heuristic search space partitioning for low-latency multi-tenant cloud queries,” arXiv preprint arXiv:2604.19057, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.