Recognition: unknown
Heuristic Search Space Partitioning for Low-Latency Multi-Tenant Cloud Queries
Pith reviewed 2026-05-10 01:55 UTC · model grok-4.3
The pith
A heuristic system partitions broad multi-tenant queries on the fly to keep each piece in memory, cutting P95 latency from 61 seconds to 2 seconds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
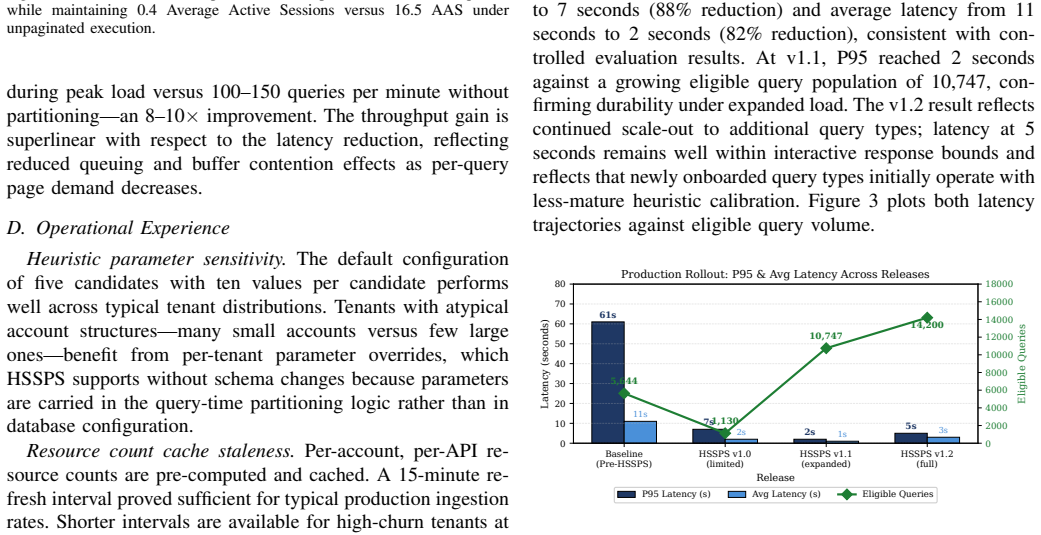
The authors demonstrate that the dominant cause of slow queries is buffer cache pressure from concurrent broad scans, and introduce a system that partitions the query space on the fly by adding temporary filters, chooses the best splits and execution plans with a two-phase heuristic, and tracks progress across partitions using tokens on the client side. In tests this yields large drops in response time and resource use, and in real production traffic the P95 latency falls from 61 seconds to 2 seconds for eligible queries.
What carries the argument
The Heuristic Search Space Partitioning System (HSSPS) that uses dynamic predicate injection to logically divide the search space, a two-phase heuristic engine to select partition keys and score plans, and a client-side page token to maintain cross-partition state without server sessions.
If this is right
- P95 latency falls 50-97 percent across query types, with 95-97 percent gains on high-cardinality queries.
- Throughput rises 8-10 times while average active sessions drop by a factor of 41.
- Production traffic sustains the 61-second to 2-second improvement across more than 14,000 eligible queries per window.
- The method applies to any multi-tenant system running broad queries against large shared tables where schema changes are impractical.
Where Pith is reading between the lines
- Client-side tokens for state could let the same technique scale across replica sets without requiring session stickiness on the database servers.
- If the heuristic remains stable, operators might rely less on per-tenant indexing or materialized views to control cache behavior.
- The approach might extend to analytics workloads on shared data lakes where similar cache-pressure patterns appear during wide scans.
Load-bearing premise
The heuristic can consistently pick partition keys and plans that keep each sub-query's working set memory-resident without missing results or adding prohibitive overhead from repeated executions.
What would settle it
Run the same broad queries on a loaded multi-tenant database both with and without the partitioning layer and check whether P95 latency stays near 2 seconds while returning complete, duplicate-free results.
Figures


read the original abstract
Large-scale cloud security platforms must continuously query millions of structured cloud resource records distributed across thousands of tenant accounts. Broad, account-spanning queries saturate database infrastructure, producing P95 latencies exceeding 60 seconds. We identify buffer cache pressure as the dominant latency driver: in a controlled experiment, the same query executing with the same plan completed in 3.7 seconds when its working set was memory-resident and 94 seconds when concurrent load had evicted those pages. No query plan optimization can address this; the only effective intervention is reducing the number of pages each query must touch. We present the Heuristic Search Space Partitioning System (HSSPS), a query-time optimization layer that logically partitions the search space through dynamic predicate injection, without schema modification. A two-phase heuristic engine selects partition key values and scores candidate query plans before execution. A client-side page token maintains cross-partition traversal state without server-side sessions, enabling horizontal scalability. Controlled evaluation across representative query types demonstrates 50-97% P95 latency reduction (95-97% on high-cardinality queries), 8-10x throughput improvement, and 41x reduction in average active sessions. Production rollout across live multi-tenant traffic reduced P95 latency from 61s to 2s across successive releases, sustained over 14,000 eligible queries per measurement window. The technique generalizes to any multi-tenant system where broad queries execute against large shared databases and physical schema modification is impractical.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Heuristic Search Space Partitioning System (HSSPS), a query-time optimization layer for broad, account-spanning queries over large multi-tenant cloud resource databases. It attributes high P95 latencies primarily to buffer cache pressure and proposes logical partitioning of the search space via dynamic predicate injection, driven by a two-phase heuristic that selects partition keys and scores plans, combined with client-side page tokens for stateless cross-partition traversal. Controlled experiments on representative workloads report 50-97% P95 latency reductions (95-97% for high-cardinality queries), 8-10x throughput gains, and 41x fewer active sessions; a production rollout across successive releases is reported to have lowered P95 latency from 61s to 2s on over 14,000 eligible queries per window.
Significance. If the empirical claims hold under controlled conditions, the work provides a practical, schema-agnostic technique for mitigating buffer-cache-induced latency in shared multi-tenant databases, which could generalize to other large-scale query systems where physical partitioning is impractical. The emphasis on client-side state management for horizontal scalability and the identification of cache pressure as the dominant factor (supported by the 3.7s vs. 94s controlled contrast) are notable strengths for systems-oriented database research.
major comments (2)
- [Abstract / Production rollout description] Abstract and production evaluation: the headline claim that rollout 'across successive releases' reduced P95 latency from 61s to 2s on >14,000 queries does not isolate the contribution of HSSPS. Successive releases typically include concurrent changes (schema tweaks, index additions, query rewrites, or infrastructure updates), so the before/after observational comparison cannot confidently attribute the 30x improvement to the two-phase heuristic and predicate injection alone. The controlled experiments (50-97% reductions) use synthetic or representative workloads rather than the exact live traffic mix and lack a toggle/rollback design.
- [Heuristic engine / two-phase selection] Heuristic description (likely §3 or §4): the two-phase heuristic engine is central to the approach yet the manuscript provides insufficient detail on partition-key selection logic, the exact scoring function for candidate plans, data-skew handling, and mechanisms ensuring result completeness without repeated executions or missed tuples. These omissions are load-bearing because the core claim is that the heuristic consistently keeps each sub-query's working set memory-resident; without them, reproducibility and verification of the 95-97% high-cardinality gains are limited.
minor comments (1)
- [Evaluation sections] The abstract and evaluation sections would benefit from explicit statistical controls or variance reporting for the latency measurements (e.g., number of runs, confidence intervals) to strengthen the buffer-cache contrast (3.7s vs. 94s).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We address each major comment below, agreeing where the manuscript requires clarification or expansion and outlining the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract / Production rollout description] Abstract and production evaluation: the headline claim that rollout 'across successive releases' reduced P95 latency from 61s to 2s on >14,000 queries does not isolate the contribution of HSSPS. Successive releases typically include concurrent changes (schema tweaks, index additions, query rewrites, or infrastructure updates), so the before/after observational comparison cannot confidently attribute the 30x improvement to the two-phase heuristic and predicate injection alone. The controlled experiments (50-97% reductions) use synthetic or representative workloads rather than the exact live traffic mix and lack a toggle/rollback design.
Authors: We agree that the production rollout description is observational and cannot isolate HSSPS from other concurrent changes across releases. The controlled experiments constitute the primary quantitative evidence. In the revised manuscript we will revise the abstract and production section to explicitly distinguish the observational before/after numbers from the controlled results, note the lack of a toggle/rollback design as a limitation of the live deployment data, and avoid implying direct attribution of the full 30x reduction solely to HSSPS. revision: yes
-
Referee: [Heuristic engine / two-phase selection] Heuristic description (likely §3 or §4): the two-phase heuristic engine is central to the approach yet the manuscript provides insufficient detail on partition-key selection logic, the exact scoring function for candidate plans, data-skew handling, and mechanisms ensuring result completeness without repeated executions or missed tuples. These omissions are load-bearing because the core claim is that the heuristic consistently keeps each sub-query's working set memory-resident; without them, reproducibility and verification of the 95-97% high-cardinality gains are limited.
Authors: We acknowledge that the current description of the two-phase heuristic lacks the level of detail needed for reproducibility. In the revised manuscript we will expand the relevant sections to specify: the partition-key selection criteria (including cardinality thresholds and skew detection via histogram analysis), the precise scoring function (including the cost model and weighting of memory residency estimates), skew-handling logic (adaptive bucket sizing and fallback to finer-grained keys), and completeness guarantees (deterministic ordering combined with client-side page tokens that ensure exhaustive, duplicate-free traversal without re-execution). revision: yes
Circularity Check
No circularity; purely empirical system description with no derivation chain
full rationale
The paper presents HSSPS as a heuristic query optimization layer relying on dynamic predicate injection and a two-phase engine. All claims rest on controlled experiments (50-97% P95 reductions) and an observational production rollout (61s to 2s P95). No equations, parameters fitted to data, self-definitional constructs, or load-bearing self-citations appear. The central results are direct measurements rather than any chain that reduces to its own inputs by construction. This is the expected non-finding for an applied systems paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Pre-Execution Query Slot-Time Prediction in Cloud Data Warehouses: A Feature-Scoped Machine Learning Approach
A HistGradientBoosting model predicts pre-execution BigQuery slot-time from query complexity, volume, and text features, cutting error 30-37% versus baselines on significant queries while failing on long-tail outliers.
Reference graph
Works this paper leans on
-
[1]
Eddies: Continuously adaptive query processing,
R. Avnur and J. M. Hellerstein, “Eddies: Continuously adaptive query processing,” inProc. ACM SIGMOD, 2000, pp. 261–272
2000
-
[2]
Spanner: Google’s globally-distributed database,
J. C. Corbett et al., “Spanner: Google’s globally-distributed database,” inProc. USENIX OSDI, 2012, pp. 251–264
2012
-
[3]
Schism: A workload- driven approach to database replication and partitioning,
C. Curino, E. Jones, Y . Zhang, and S. Madden, “Schism: A workload- driven approach to database replication and partitioning,”PVLDB, vol. 3, no. 1, pp. 48–57, 2010
2010
-
[4]
Towards multi-tenant performance SLOs,
W. Lang, S. Shankar, J. M. Patel, and A. Kalhan, “Towards multi-tenant performance SLOs,” inProc. IEEE ICDE, 2012, pp. 702–713
2012
-
[5]
Access path selection in a relational database management system,
P. G. Selinger et al., “Access path selection in a relational database management system,” inProc. ACM SIGMOD, 1979, pp. 23–34
1979
-
[6]
Neo: A learned query optimizer,
R. Marcus et al., “Neo: A learned query optimizer,”PVLDB, vol. 12, no. 11, pp. 1705–1718, 2019
2019
-
[7]
F1: A distributed SQL database that scales,
J. Shute et al., “F1: A distributed SQL database that scales,”PVLDB, vol. 6, no. 11, pp. 1068–1079, 2013
2013
-
[8]
Opti- mizing queries with materialized views,
S. Chaudhuri, R. Krishnamurthy, S. Potamianos, and K. Shim, “Opti- mizing queries with materialized views,” inProc. IEEE ICDE, 1995, pp. 190–200
1995
-
[9]
Bao: Making learned query optimization practical,
R. Marcus et al., “Bao: Making learned query optimization practical,” inProc. ACM SIGMOD, 2021, pp. 1275–1288
2021
-
[10]
Learned cardinalities: Estimating correlated joins with deep learning,
A. Kipf, T. Kipf, B. Radke, V . Leis, P. Boncz, and A. Kemper, “Learned cardinalities: Estimating correlated joins with deep learning,” inProc. CIDR, 2019
2019
-
[11]
Amazon Aurora: Design considerations for high throughput cloud-native relational databases,
A. Verbitski et al., “Amazon Aurora: Design considerations for high throughput cloud-native relational databases,” inProc. ACM SIGMOD, 2017, pp. 1041–1052
2017
-
[12]
Heuristic database querying with dynamic partitioning,
P. K. Pathak and C. B. Mouleeswaran, “Heuristic database querying with dynamic partitioning,” U.S. Patent US11941006B2, Mar. 26, 2024
2024
-
[13]
Heuristic database querying with dynamic partitioning,
C. B. Mouleeswaran, A. Agarwal, P. K. Pathak, and X. Wang, “Heuristic database querying with dynamic partitioning,” U.S. Patent US12373434B2, Jul. 29, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.