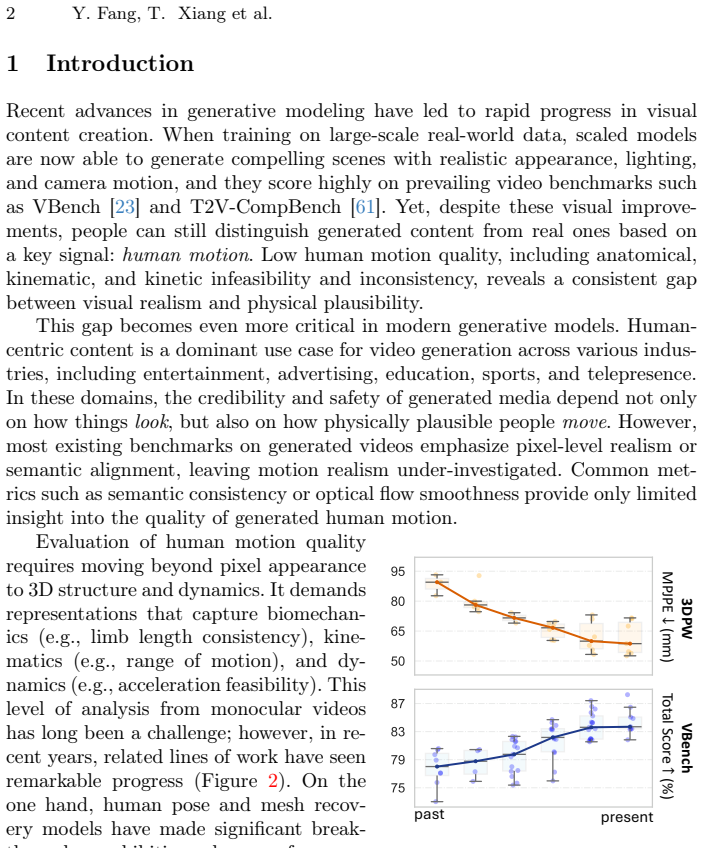
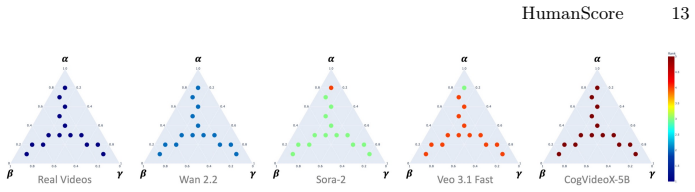
Recognition: unknown
HumanScore: Benchmarking Human Motions in Generated Videos
Pith reviewed 2026-05-10 01:14 UTC · model grok-4.3
The pith
HumanScore metrics show AI video models produce motions that look real but violate biomechanical rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HumanScore defines six interpretable metrics spanning kinematic plausibility, temporal stability, and biomechanical consistency. Applied to videos generated by thirteen state-of-the-art models, the metrics reveal consistent gaps between perceptual plausibility and motion biomechanical fidelity, identify recurrent failure modes including temporal jitter, anatomically implausible poses, and motion drift, and yield robust model rankings derived from quantitative and physically meaningful criteria.
What carries the argument
HumanScore, the set of six metrics based on kinematic and biomechanical principles that quantify motion quality separately from overall visual appearance.
If this is right
- Model rankings shift when evaluation uses physical motion criteria instead of viewer preference alone.
- Developers gain specific targets for fixing temporal jitter and anatomical violations in future architectures.
- Applications that depend on realistic human dynamics, such as virtual training or robotics simulation, can use the metrics for validation beyond visual checks.
- The identified failure modes point to the need for generation methods that enforce longer-term anatomical and physical constraints.
Where Pith is reading between the lines
- Training video generators with direct biomechanical penalties derived from these metrics could reduce reliance on purely perceptual objectives.
- The same metrics could be tested on interactive or multi-person generated scenes to check whether current gaps widen under more complex conditions.
- Correlations between HumanScore values and downstream task performance, such as accurate pose tracking, would indicate practical utility beyond diagnostic ranking.
Load-bearing premise
The six metrics derived from kinematic and biomechanical principles accurately and comprehensively measure human motion quality in generated videos without interference from unrelated visual factors, and the selected prompts represent typical human movements.
What would settle it
A blind rating study by biomechanics experts on motion naturalness for videos scored at opposite ends of the HumanScore distribution, where expert rankings fail to match the metric order, would falsify the claim that the metrics capture biomechanical fidelity.
Figures









read the original abstract
Recent advances in model architectures, compute, and data scale have driven rapid progress in video generation, producing increasingly realistic content. Yet, no prior method systematically measures how faithfully these systems render human bodies and motion dynamics. In this paper, we present HumanScore, a systematic framework to evaluate the quality of human motions in AI-generated videos. HumanScore defines six interpretable metrics spanning kinematic plausibility, temporal stability, and biomechanical consistency, enabling fine-grained diagnosis beyond visual realism alone. Through carefully designed prompts, we elicit a diverse set of movements at varying intensities and evaluate videos generated by thirteen state-of-the-art models. Our analysis reveals consistent gaps between perceptual plausibility and motion biomechanical fidelity, identifies recurrent failure modes (e.g., temporal jitter, anatomically implausible poses, and motion drift), and produces robust model rankings from quantitative and physically meaningful criteria.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HumanScore, a systematic framework to evaluate the quality of human motions in AI-generated videos. It defines six interpretable metrics spanning kinematic plausibility, temporal stability, and biomechanical consistency. The authors apply these to videos generated by thirteen state-of-the-art models using carefully designed prompts that elicit diverse movements, revealing consistent gaps between perceptual plausibility and motion biomechanical fidelity, identifying recurrent failure modes such as temporal jitter, anatomically implausible poses, and motion drift, and producing robust model rankings from quantitative and physically meaningful criteria.
Significance. If the metrics prove to be well-validated and independent of other visual factors, this work could provide a valuable, physically grounded benchmark for video generation research, helping diagnose limitations in current models and guiding improvements in human motion synthesis. The separation of motion fidelity from general visual realism addresses a clear gap in the field.
major comments (1)
- [Abstract] Abstract: The central claims depend on the six metrics accurately capturing human motion quality from kinematic and biomechanical principles, but no exact formulas, computation details from video frames, validation against real motion-capture ground truth, or statistical significance tests for the rankings are provided. This undermines verification of the reported gaps, failure modes, and model rankings.
minor comments (1)
- The abstract refers to 'carefully designed prompts' and 'diverse set of movements' without describing the prompt set, intensity variations, or how representativeness was ensured; this should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The feedback highlights important aspects for improving the transparency and rigor of HumanScore. We address the major comment point-by-point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims depend on the six metrics accurately capturing human motion quality from kinematic and biomechanical principles, but no exact formulas, computation details from video frames, validation against real motion-capture ground truth, or statistical significance tests for the rankings are provided. This undermines verification of the reported gaps, failure modes, and model rankings.
Authors: We thank the referee for this observation. The six metrics are defined with exact mathematical formulations in Section 3 of the manuscript, derived from standard kinematic and biomechanical principles (e.g., joint angle constraints based on anatomical ranges, temporal derivatives for stability, and center-of-mass trajectory analysis for consistency). Computation proceeds by first applying a pose estimator (OpenPose) to extract 2D keypoints per frame, then computing the metrics from the resulting time-series trajectories. However, we acknowledge that the current version lacks (i) explicit pseudocode or expanded derivation steps for each metric, (ii) direct validation against MoCap ground-truth datasets, and (iii) statistical significance tests (e.g., paired t-tests or Wilcoxon rank-sum tests with p-values and effect sizes) on the model rankings. In the revised manuscript we will add a dedicated subsection in Section 3 with full equations, pseudocode, and implementation details; include a validation experiment on real videos from Human3.6M/AMASS to confirm metric alignment with expected biomechanical properties; and report statistical tests supporting the observed gaps and rankings. These changes will make the claims fully verifiable while preserving the original experimental results and conclusions. revision: yes
Circularity Check
No significant circularity detected in the derivation or evaluation chain
full rationale
The paper defines HumanScore as a new benchmark consisting of six metrics drawn from standard kinematic and biomechanical principles, then applies them directly to a set of generated videos elicited via prompts. Model rankings and gap analysis follow from straightforward computation of these metrics on the outputs; no equations, predictions, or first-principles claims are shown to reduce by construction to fitted parameters, self-citations, or the target results themselves. The framework is self-contained as an empirical measurement tool without load-bearing internal loops or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://research.google.com/youtube8m/(2016) 4 HumanScore 15
Abu-El-Haija, S., Kothari, N., Lee, J., Natsev, P., Toderici, G., Varadarajan, B., Vijayanarasimhan, S.: Youtube-8m: A large-scale video classification benchmark. https://research.google.com/youtube8m/(2016) 4 HumanScore 15
2016
-
[2]
AI, K.K.: Kling 2.5 turbo pro video generation model.https://app.klingai.com/ (2025), accessed: 2025-11-14 9, 10, 13, 16
2025
-
[3]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Akhter, I., Black, M.J.: Pose-conditioned joint angle limits for 3d human pose reconstruction. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1446–1455 (2015) 12
2015
-
[4]
Accessed: 2026-03-03 10, 16
Alibaba Cloud Community: Model studio: Wan 2.6 & wan 2.5 video generation prompt guide.https://www.alibabacloud.com/blog/602776(Jan 2026), us- age/prompting guide for the WAN 2.6/2.5 series. Accessed: 2026-03-03 10, 16
2026
-
[5]
Arkhipkin, V., Korviakov, V., Gerasimenko, N., Parkhomenko, D., Vasilev, V., Letunovskiy, A., Vaulin, N., Kovaleva, M., Kirillov, I., Novitskiy, L., Koposov, D., Kiselev, N., Varlamov, A., Mikhailov, D., Polovnikov, V., Shutkin, A., Agafonova, J., Vasiliev, I., Kargapoltseva, A., Dmitrienko, A., Maltseva, A., Averchenkova, A., Kim, O., Nikulina, T., Dimit...
-
[6]
Journal of neuroengineering and rehabilitation 12(1), 112 (2015) 13
Balasubramanian, S., Melendez-Calderon, A., Roby-Brami, A., Burdet, E.: On the analysis of movement smoothness. Journal of neuroengineering and rehabilitation 12(1), 112 (2015) 13
2015
-
[7]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Baumgartner, T., Klatt, S.: Monocular 3d human pose estimation for sports broad- casts using partial sports field registration. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 5109–5118 (2023) 5
2023
-
[8]
Bilibili: Bilibili.https://www.bilibili.com/(2025) 4
2025
-
[9]
IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 11
Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: Openpose: Realtime multi- person 2d pose estimation using part affinity fields. IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 11
2019
-
[10]
A short note on the kinetics-700 human action dataset
Carreira, J., Noland, E., Hillier, C., Zisserman, A.: A short note on the kinetics-700 human action dataset. arXiv preprint arXiv:1907.06987 (2019) 5
-
[11]
Computer methods in biomechanics and biomedical engineering22(1), 21–24 (2019) 8
Catelli, D.S., Wesseling, M., Jonkers, I., Lamontagne, M.: A musculoskeletal model customized for squatting task. Computer methods in biomechanics and biomedical engineering22(1), 21–24 (2019) 8
2019
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Davydov, A., Engilberge, M., Salzmann, M., Fua, P.: Cloaf: Collision-aware hu- man flow. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1176–1185 (2024) 13
2024
-
[13]
IEEE transactions on biomedical engineering 54(11), 1940–1950 (2007) 8
Delp, S.L., Anderson, F.C., Arnold, A.S., Loan, P., Habib, A., John, C.T., Guen- delman, E., Thelen, D.G.: Opensim: open-source software to create and analyze dynamic simulations of movement. IEEE transactions on biomedical engineering 54(11), 1940–1950 (2007) 8
1940
-
[14]
Duan, H., Yu, H.X., Chen, S., Fei-Fei, L., Wu, J.: Worldscore: A unified evaluation benchmark for world generation. arXiv preprint arXiv:2504.00983 (2025) 3, 14
-
[15]
Accessed: 2026-03-03 10, 16
fal.ai: Pixverse v5.5 developer guide.https://fal.ai/learn/devs/pixverse- v5-5-developer-guide(Dec 2025), aPI usage guide for PixVerse v5.5. Accessed: 2026-03-03 10, 16
2025
-
[16]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025) 9, 10, 13, 16
work page internal anchor Pith review arXiv 2025
-
[17]
Goel, S., Pavlakos, G., Rajasegaran, J., Kanazawa, A., Malik, J.: Humans in 4d: Reconstructing and tracking humans with transformers. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 14737–14748 (2023). https://doi.org/10.1109/ICCV51070.2023.013584, 13 16 Y. Fang, T. Xiang et al
-
[18]
Grimmer, M.: Human lower limb joint biomechanics in daily life activities: A lit- erature based requirement analysis for anthropomorphic robot design. Frontiers in Robotics and AI7, 13 (2020).https://doi.org/10.3389/frobt.2020.00013, https://www.frontiersin.org/articles/10.3389/frobt.2020.00013/full9, 10
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating di- verse and natural 3d human motions from text. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5152–5161 (June 2022) 4
2022
-
[20]
Lippincott Williams & Wilkins (2006) 7
Hamill, J., Knutzen, K.M.: Biomechanical basis of human movement. Lippincott Williams & Wilkins (2006) 7
2006
-
[21]
Syntab-llava: Enhancing multimodal table understanding with decou- pled synthesis
Han, H., Li, S., Chen, J., Yuan, Y., Wu, Y., Deng, Y., Leong, C.T., Du, H., Fu, J., Li, Y., Zhang, J., Zhang, C., Li, L.j., Ni, Y.: Video-bench: Human-aligned video generation benchmark. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18858–18868 (2025).https://doi.org/10. 1109/CVPR52734.2025.017573
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hong, W., Cheng, Y., Yang, Z., Wang, W., Wang, L., Gu, X., Huang, S., Dong, Y., Tang, J.: Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8450–8460 (2025) 3
2025
-
[23]
Retrieval-Augmented Embodied Agents
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: Vbench: Comprehensive benchmark suite for video generative models. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 21807– 21818 (2024).https://doi.org/10.1109/CVP...
-
[24]
Vbench++: Comprehensive and versatile benchmark suite for video generative models
Huang, Z., Zhang, F., Xu, X., He, Y., Yu, J., Dong, Z., Ma, Q., Chanpaisit, N., Si, C., Jiang, Y., et al.: Vbench++: Comprehensive and versatile benchmark suite for video generative models. arXiv preprint arXiv:2411.13503 (2024) 3
-
[25]
In: Computer Vision and Pattern Recognition (CVPR) (2018) 11
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: Computer Vision and Pattern Recognition (CVPR) (2018) 11
2018
-
[26]
arXiv preprint arXiv:2403.09669 (2024) 3
Kim,P.J.,Kim,S.,Yoo,J.:Stream:Spatio-temporalevaluationandanalysismetric for video generative models. arXiv preprint arXiv:2403.09669 (2024) 3
-
[27]
In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020) 11
Kocabas, M., Athanasiou, N., Black, M.J.: Vibe: Video inference for human body pose and shape estimation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020) 11
2020
-
[28]
Li, B., Lin, Z., Pathak, D., Li, J., Fei, Y., Wu, K., Ling, T., Xia, X., Zhang, P., Neubig, G., Ramanan, D.: Genai-bench: Evaluating and improving compositional text-to-visual generation. arXiv preprint arXiv:2406.13743 (2024) 3
-
[29]
Lin, J., Wang, R., Lu, J., Huang, Z., Song, G., Zeng, A., Liu, X., Wei, C., Yin, W., Sun, Q., et al.: The quest for generalizable motion generation: Data, model, and evaluation. arXiv preprint arXiv:2510.26794 (2025) 4
-
[30]
Advances in Neural Information Processing Systems (2023) 4
Lin, J., Zeng, A., Lu, S., Cai, Y., Zhang, R., Wang, H., Zhang, L.: Motion-x: A large-scale 3d expressive whole-body human motion dataset. Advances in Neural Information Processing Systems (2023) 4
2023
-
[31]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014) 5
2014
-
[32]
Towards un- derstanding camera motions in any video.arXiv preprint arXiv:2504.15376,
Lin, Z., Cen, S., Jiang, D., Karhade, J., Wang, H., Mitra, C., Ling, Y.T.T., Huang, Y., Liu, S., Chen, M., Zawar, R., Bai, X., Du, Y., Gan, C., Ramanan, D.: Towards HumanScore 17 understanding camera motions in any video. arXiv preprint arXiv:2504.15376 (2025) 3
-
[33]
Evaluating text-to-visual generation with image-to-text generation
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. arXiv preprint arXiv:2404.01291 (2024) 3
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ling, X., Zhu, C., Wu, M., Li, H., Feng, X., Yang, C., Hao, A., Zhu, J., Wu, J., Chu, X.: Vmbench: A benchmark for perception-aligned video motion generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13087–13098 (2025) 3
2025
-
[35]
com/content/ICCV2025/supplemental/Ling_VMBench_A_Benchmark_ICCV_2025_ supplemental.pdf, supplemental material available athttps://openaccess
Ling, X., Zhu, C., Wu, M., Li, H., Feng, X., Yang, C., Hao, A., Zhu, J., Wu, J., Chu, X.: Vmbench: A benchmark for perception-aligned video mo- tion generation (supplemental material) (2025),https://openaccess.thecvf. com/content/ICCV2025/supplemental/Ling_VMBench_A_Benchmark_ICCV_2025_ supplemental.pdf, supplemental material available athttps://openacces...
2025
-
[36]
Fr\’echet video motion distance: A metric for evaluating motion consistency in videos,
Liu, J., Qu, Y., Yan, Q., Zeng, X., Wang, L., Liao, R.: Fréchet video motion distance: A metric for evaluating motion consistency in videos. arXiv preprint arXiv:2407.16124 (2024) 4
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Y., Cun, X., Liu, X., Wang, X., Zhang, Y., Chen, H., Liu, Y., Zeng, T., Chan, R., Shan, Y.: Evalcrafter: Benchmarking and evaluating large video generation models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22139–22149 (2024) 3
2024
-
[38]
LLC, G.: Veo 3.1 video generation model.https://ai.google.dev/gemini-api/ video-generation(2025), accessed: 2025-11-14 9, 10, 13, 16
2025
-
[39]
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinnedmulti-personlinearmodel.ACMTrans.Graphics(Proc.SIGGRAPHAsia) 34(6), 248:1–248:16 (Oct 2015) 4, 5
2015
-
[40]
ACM Transactions on Graphics (TOG)34(6), 1–16 (2015) 5
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: a skinned multi-person linear model. ACM Transactions on Graphics (TOG)34(6), 1–16 (2015) 5
2015
-
[41]
ai/ray(2026), product/model page for Ray3
Luma AI: Ai video generation with ray3 & dream machine.https://lumalabs. ai/ray(2026), product/model page for Ray3. Accessed: 2026-03-03 10, 15
2026
-
[42]
In: Proceedings of the IEEE/CVF international conference on computer vision
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: Amass: Archive of motion capture as surface shapes. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5442–5451 (2019) 4
2019
-
[43]
In: Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games
Maiorca, A., Bohy, H., Yoon, Y., Dutoit, T.: Objective evaluation metric for motion generative models: Validating fréchet motion distance on foot skating and over- smoothing artifacts. In: Proceedings of the 16th ACM SIGGRAPH Conference on Motion, Interaction and Games. pp. 1–11 (2023) 4
2023
- [44]
-
[45]
MiniMax Hailuo 02 Fan-site: Minimax hailuo 02 | world’s #2 ai video generation model.https://www.hailuo02.net/(2025), accessed: 2026-03-04 9, 10, 16
2025
-
[46]
OpenAI: Sora 2 system card.https://openai.com/index/sora-2-system-card/ (Sep 2025), accessed: 2025-11-14 9, 10, 13, 16
2025
-
[47]
In: Proceedings IEEE Conf
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3D hands, face, and body from a single image. In: Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). pp. 10975–10985 (2019) 4, 5 18 Y. Fang, T. Xiang et al
2019
-
[48]
arXiv preprint arXiv:2507.08268 (2025) 7
Peiffer, J., Shah, K., Djuraskovic, I., Anarwala, S., Abdou, K., Patel, R., Jaya- balan, P., Pennicooke, B., Cotton, R.J.: Portable biomechanics laboratory: Clin- ically accessible movement analysis from a handheld smartphone. arXiv preprint arXiv:2507.08268 (2025) 7
-
[49]
Pika Community: Pika 2.2.https://pikalabs.org/pika-2-2/(Mar 2025), ac- cessed: 2026-03-04 9, 10, 16
2025
-
[50]
Plappert, M., Mandery, C., Asfour, T.: The kit motion-language dataset. Big Data 4(4), 236–252 (Dec 2016).https://doi.org/10.1089/big.2016.0028,http:// dx.doi.org/10.1089/big.2016.00284
-
[51]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 5
2021
-
[52]
IEEE transactions on biomedical engineering63(10), 2068–2079 (2016) 8, 5
Rajagopal, A., Dembia, C.L., DeMers, M.S., Delp, D.D., Hicks, J.L., Delp, S.L.: Full-body musculoskeletal model for muscle-driven simulation of human gait. IEEE transactions on biomedical engineering63(10), 2068–2079 (2016) 8, 5
2068
-
[53]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10084 (2019) 5
work page internal anchor Pith review arXiv 1908
-
[54]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M
Rempe, D., Guibas, L.J., Hertzmann, A., Russell, B., Villegas, R., Yang, J.: Con- tact and human dynamics from monocular video. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (eds.) Computer Vision – ECCV 2020. pp. 71–87. Springer International Publishing, Cham (2020) 4
2020
-
[55]
a pilot study
Roren, A., Mazarguil, A., Vaquero-Ramos, D., Deloose, J.B., Vidal, P.P., Nguyen, C., Rannou, F., Wang, D., Oudre, L., Lefèvre-Colau, M.M.: Assessing smoothness of arm movements with jerk: a comparison of laterality, contraction mode and plane of elevation. a pilot study. Frontiers in Bioengineering and Biotechnology9, 782740 (2022) 13
2022
-
[56]
In: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2023) 7
Sárándi, I., Hermans, A., Leibe, B.: Learning 3D human pose estimation from dozens of datasets using a geometry-aware autoencoder to bridge between skeleton formats. In: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2023) 7
2023
-
[57]
IEEE Transactions on Biometrics, Behavior, and Identity Science3(1), 16–30 (2020) 8
Sárándi, I., Linder, T., Arras, K.O., Leibe, B.: Metrabs: metric-scale truncation- robust heatmaps for absolute 3d human pose estimation. IEEE Transactions on Biometrics, Behavior, and Identity Science3(1), 16–30 (2020) 8
2020
-
[58]
In: SIGGRAPH Asia Conference Proceedings (2024) 13
Shen,Z.,Pi,H.,Xia,Y.,Cen,Z.,Peng,S.,Hu,Z.,Bao,H.,Hu,R.,Zhou,X.:World- grounded human motion recovery via gravity-view coordinates. In: SIGGRAPH Asia Conference Proceedings (2024) 13
2024
-
[59]
ACM Transactions on Graphics39(6) (dec 2020) 4
Shimada, S., Golyanik, V., Xu, W., Theobalt, C.: Physcap: Physically plausible monocular 3d motion capture in real time. ACM Transactions on Graphics39(6) (dec 2020) 4
2020
-
[60]
Singh, S., Bible, J., Liu, Z., Zhang, Z., Singapogu, R.: Motion smoothness metrics for cannulation skill assessment: What factors matter? Frontiers in Robotics and AI8, 625003 (2021) 13
2021
-
[61]
Syntab-llava: Enhancing multimodal table understanding with decou- pled synthesis
Sun, K., Huang, K., Liu, X., Wu, Y., Xu, Z., Li, Z., Liu, X.: T2v-compbench: A comprehensive benchmark for compositional text-to-video generation. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8406–8416 (2025).https://doi.org/10.1109/CVPR52734.2025.007872, 3
-
[62]
In: Proceedings of the IEEE international conference on computer vision
Sun, X., Shang, J., Liang, S., Wei, Y.: Compositional human pose regression. In: Proceedings of the IEEE international conference on computer vision. pp. 2602– 2611 (2017) 7, 9, 10 HumanScore 19
2017
-
[63]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tang, S., Chen, C., Xie, Q., Chen, M., Wang, Y., Ci, Y., Bai, L., Zhu, F., Yang, H., Yi, L., et al.: Humanbench: Towards general human-centric perception with projector assisted pretraining. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21970–21982 (2023) 3
2023
-
[64]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2023) 4
Tripathi, S., Müller, L., Huang, C.H.P., Omid, T., Black, M.J., Tzionas, D.: 3D human pose estimation via intuitive physics. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2023) 4
2023
-
[65]
In: Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 4
Ugrinovic, N., Pan, B., Pavlakos, G., Paschalidou, D., Shen, B., Sanchez-Riera, J., Moreno-Noguer, F., Guibas, L.: Multiphys: Multi-person physics-aware 3d motion estimation. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 4
2024
-
[66]
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges (2019), https://arxiv.org/abs/1812.017174
work page internal anchor Pith review arXiv 2019
-
[67]
In: Proceedings of the European conference on computer vision (ECCV)
Von Marcard, T., Henschel, R., Black, M.J., Rosenhahn, B., Pons-Moll, G.: Re- covering accurate 3d human pose in the wild using imus and a moving camera. In: Proceedings of the European conference on computer vision (ECCV). pp. 601–617 (2018) 2
2018
-
[68]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 9, 10, 13, 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Detecting human artifacts from text-to- image models.arXiv preprint arXiv:2411.13842, 2024
Wang, K., Zhang, L., Zhang, J.: Detecting human artifacts from text-to-image models. arXiv preprint arXiv:2411.13842 (2024) 7, 4
-
[70]
In: Proceedings of the computer vision and pattern recognition conference
Wang, Y., Sun, Y., Patel, P., Daniilidis, K., Black, M.J., Kocabas, M.: Prompthmr: Promptable human mesh recovery. In: Proceedings of the computer vision and pattern recognition conference. pp. 1148–1159 (2025) 8, 12, 4, 9
2025
-
[71]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang,Z.,Li,P.,Liu,H.,Deng,Z.,Wang,C.,Liu,J.,Yuan,J.,Liu,M.:Recognizing actions from robotic view for natural human-robot interaction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14218–14227 (2025) 3
2025
-
[72]
HunyuanVideo 1.5 Technical Report
Wu, B., Zou, C., Li, C., Huang, D., Yang, F., Tan, H., Peng, J., Wu, J., Xiong, J., Jiang, J., et al.: Hunyuanvideo 1.5 technical report. arXiv preprint arXiv:2511.18870 (2025) 9, 10, 13, 15
work page internal anchor Pith review arXiv 2025
-
[73]
In: 2025 International Conference on 3D Vision (3DV)
Xiang, T., Wang, K.C., Heo, J., Adeli, E., Yeung, S., Delp, S., Fei-Fei, L.: Neuhmr: Neural rendering-guided human motion reconstruction. In: 2025 International Con- ference on 3D Vision (3DV). pp. 1518–1528 (2025).https://doi.org/10.1109/ 3DV66043.2025.001424
-
[74]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024) 9, 10, 13, 15
work page internal anchor Pith review arXiv 2024
-
[75]
Youtube: Youtube.https://www.youtube.com/(2025) 4
2025
-
[76]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, Y., Kephart, J.O., Cui, Z., Ji, Q.: Physpt: Physics-aware pretrained trans- former for estimating human dynamics from monocular videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2305–2317 (June 2024) 4
2024
-
[77]
Zheng, C., Wu, W., Chen, C., Yang, T., Zhu, S., Shen, J., Kehtarnavaz, N., Shah, M.: Deep learning-based human pose estimation: A survey. ACM Comput. Surv. (jun 2023).https://doi.org/10.1145/3603618,https://doi.org/10.1145/ 360361811 HumanScore: Benchmarking Human Motions in Generated Videos Supplementary Material Table of Contents A Teaser..................
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.