Recognition: unknown
Aligning Human-AI-Interaction Trust for Mental Health Support: Survey and Position for Multi-Stakeholders
Pith reviewed 2026-05-10 00:41 UTC · model grok-4.3
The pith
A three-layer trust framework organizes human, AI, and interaction perspectives to align stakeholders on trustworthy AI for mental health support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
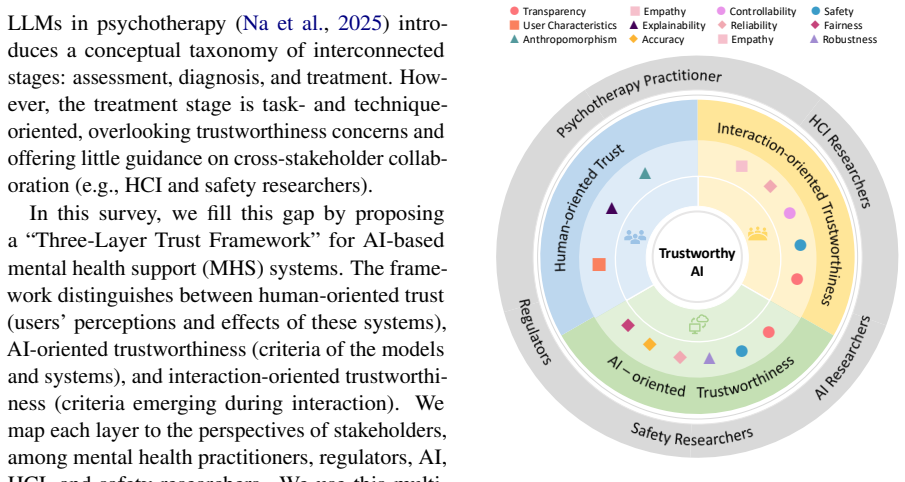
We propose a three-layer trust framework covering human-oriented, AI-oriented, and interaction-oriented trust that integrates the viewpoints of key stakeholders including practitioners, researchers, and regulators. Using this framework we systematically review AI-driven mental health research and examine evaluation practices for trustworthiness, highlighting critical gaps between NLP metrics and real-world mental health requirements while outlining a research agenda for building aligned and genuinely trustworthy AI.
What carries the argument
The three-layer trust framework that structures trust into human-oriented, AI-oriented, and interaction-oriented dimensions to reconcile differing stakeholder definitions and enable reorganization of existing literature.
If this is right
- Existing AI mental health studies can be reorganized under the three layers to clarify where technical and therapeutic priorities diverge.
- Evaluation of AI trustworthiness must combine automatic metrics with clinically validated approaches to address identified gaps.
- A concrete research agenda follows for developing AI systems that satisfy both technical criteria and therapeutic outcomes.
- Multi-stakeholder alignment becomes feasible by using the shared framework as a common reference point for design and regulation.
Where Pith is reading between the lines
- Regulators could require new AI mental health tools to demonstrate measurable performance across all three trust layers before deployment.
- Interface designers might prioritize features that strengthen interaction-oriented trust, such as sustained conversation quality over time.
- Longitudinal studies could test whether tools built under this framework produce better retention and outcome rates than current systems.
Load-bearing premise
The three-layer structure comprehensively captures all relevant dimensions of trust without significant overlaps or missing factors, and existing literature can be meaningfully reorganized under it.
What would settle it
A documented dimension of trust in AI mental health systems that cannot be placed into any of the three layers, or an empirical study showing that applying the framework fails to reduce inconsistencies in how stakeholders evaluate the same AI tools.
Figures


read the original abstract
Building trustworthy AI systems for mental health support is a shared priority across stakeholders from multiple disciplines. However, "trustworthy" remains loosely defined and inconsistently operationalized. AI research often focuses on technical criteria (e.g., robustness, explainability, and safety), while therapeutic practitioners emphasize therapeutic fidelity (e.g., appropriateness, empathy, and long-term user outcomes). To bridge the fragmented landscape, we propose a three-layer trust framework, covering human-oriented, AI-oriented, and interaction-oriented trust, integrating the viewpoints of key stakeholders (e.g., practitioners, researchers, regulators). Using this framework, we systematically review existing AI-driven research in mental health domain and examine evaluation practices for ``trustworthy'' ranging from automatic metrics to clinically validated approaches. We highlight critical gaps between what NLP currently measures and what real-world mental health contexts require, and outline a research agenda for building socio-technically aligned and genuinely trustworthy AI for mental health support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript surveys AI research in mental health support and proposes a three-layer trust framework (human-oriented, AI-oriented, and interaction-oriented trust) to integrate multi-stakeholder perspectives from practitioners, researchers, regulators, and others. It reviews evaluation practices ranging from automatic NLP metrics to clinically validated approaches, identifies gaps between current technical measures and real-world clinical needs, and outlines a research agenda for socio-technically aligned trustworthy AI.
Significance. If adopted, the framework could help bridge disciplinary divides by providing a shared organizing structure for trust in mental health AI, surfacing actionable discrepancies between NLP evaluation practices and therapeutic requirements. The position paper's value lies in its constructive synthesis rather than new data or formal derivations; credit is due for explicitly framing the work as a starting point for multi-stakeholder alignment rather than a complete model.
major comments (1)
- [Abstract] Abstract and review description: the claim of a 'systematic review' of AI-driven mental health research is central to identifying gaps, yet no details are provided on search strategy, databases, inclusion/exclusion criteria, or the process used to map literature onto the three-layer framework. This limits assessment of whether the highlighted gaps are comprehensive or selective.
minor comments (2)
- [Framework proposal] The three layers are introduced as a synthesis of stakeholder viewpoints, but the manuscript would benefit from a brief explicit discussion of boundary cases or potential overlaps (e.g., where interaction-oriented trust intersects with human- or AI-oriented dimensions) to clarify the framework's structure.
- [Research agenda] As a position paper without new empirical validation, the research agenda section could more clearly distinguish between recommendations that follow directly from the reviewed literature and those that are forward-looking proposals.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive recommendation for minor revision. We address the single major comment below and will update the manuscript to improve transparency around our literature review process.
read point-by-point responses
-
Referee: [Abstract] Abstract and review description: the claim of a 'systematic review' of AI-driven mental health research is central to identifying gaps, yet no details are provided on search strategy, databases, inclusion/exclusion criteria, or the process used to map literature onto the three-layer framework. This limits assessment of whether the highlighted gaps are comprehensive or selective.
Authors: We agree that the phrasing 'we systematically review' in the abstract and introduction implies a formal systematic review with explicit methodology, which is not provided. Our review is a structured, framework-guided synthesis of representative literature rather than a comprehensive PRISMA-style systematic review. To address this, we will (1) revise the abstract and relevant sections to state 'we review' or 'we conduct a structured review', (2) add a brief methods subsection describing the search strategy (databases such as ACL Anthology, PubMed, arXiv, Google Scholar; keywords combining 'AI', 'mental health', 'trust', 'evaluation'; time frame 2015-2024), inclusion criteria (peer-reviewed or preprint works on AI for mental health support), and the mapping process to the three trust layers, and (3) note the review's illustrative rather than exhaustive scope. These changes will make the process transparent while preserving the position-paper focus. revision: yes
Circularity Check
No significant circularity in proposed framework
full rationale
The paper is a survey and position piece whose central contribution is the proposal of a three-layer trust framework (human-oriented, AI-oriented, and interaction-oriented) as an organizing synthesis drawn from stakeholder viewpoints and literature gaps. No derivation chain, equations, fitted parameters, or formal predictions are presented; the framework is explicitly constructive rather than derived from first principles or self-referential definitions. No load-bearing step reduces to its own inputs by construction, and the paper does not invoke self-citation chains, uniqueness theorems, or ansatzes from prior author work to justify its structure. The assumption that existing literature can be reorganized under the layers serves only to surface gaps between NLP metrics and clinical needs, leaving the paper self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Trust in AI for mental health support is best understood through multiple layers (human-oriented, AI-oriented, interaction-oriented) and the viewpoints of multiple stakeholders.
invented entities (3)
-
human-oriented trust layer
no independent evidence
-
AI-oriented trust layer
no independent evidence
-
interaction-oriented trust layer
no independent evidence
Reference graph
Works this paper leans on
-
[2]
and Masoud, Reem and Alnuhait, Deema and Alomairi, Afnan Y
Alghamdi, Emad A. and Masoud, Reem and Alnuhait, Deema and Alomairi, Afnan Y. and Ashraf, Ahmed and Zaytoon, Mohamed. A ra T rust: An Evaluation of Trustworthiness for LLM s in A rabic. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[8]
Mishra, Kshitij and Priya, Priyanshu and Ekbal, Asif. PAL to Lend a Helping Hand: Towards Building an Emotion Adaptive Polite and Empathetic Counseling Conversational Agent. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.685
-
[11]
Enhancing Emotional Support Conversations: A Framework for Dynamic Knowledge Filtering and Persona Extraction
Hao, Jiawang and Kong, Fang. Enhancing Emotional Support Conversations: A Framework for Dynamic Knowledge Filtering and Persona Extraction. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[12]
and Krahmer, Emiel
Basar, Erkan and Sun, Xin and Hendrickx, Iris and de Wit, Jan and Bosse, Tibor and De Bruijn, Gert-Jan and Bosch, Jos A. and Krahmer, Emiel. How Well Can Large Language Models Reflect? A Human Evaluation of LLM -generated Reflections for Motivational Interviewing Dialogues. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[13]
Kang, Dongjin and Kim, Sunghwan and Kwon, Taeyoon and Moon, Seungjun and Cho, Hyunsouk and Yu, Youngjae and Lee, Dongha and Yeo, Jinyoung. Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lo...
-
[15]
Huang, Yue and Sun, Lichao and Wang, Haoran and Wu, Siyuan and Zhang, Qihui and Li, Yuan and Gao, Chujie and Huang, Yixin and Lyu, Wenhan and Zhang, Yixuan and Li, Xiner and Sun, Hanchi and Liu, Zhengliang and Liu, Yixin and Wang, Yijue and Zhang, Zhikun and Vidgen, Bertie and Kailkhura, Bhavya and Xiong, Caiming and Xiao, Chaowei and Li, Chunyuan and Xin...
2024
-
[23]
and Arora, Simran and Mazeika, Manias and Hendrycks, Dan and Lin, Zinan and Cheng, Yu and Koyejo, Sanmi and Song, Dawn and Li, Bo , title =
Wang, Boxin and Chen, Weixin and Pei, Hengzhi and Xie, Chulin and Kang, Mintong and Zhang, Chenhui and Xu, Chejian and Xiong, Zidi and Dutta, Ritik and Schaeffer, Rylan and Truong, Sang T. and Arora, Simran and Mazeika, Manias and Hendrycks, Dan and Lin, Zinan and Cheng, Yu and Koyejo, Sanmi and Song, Dawn and Li, Bo , title =. Proceedings of the 37th Int...
2023
-
[24]
Trustworthy
Yang Liu and Yuanshun Yao and Jean-Francois Ton and Xiaoying Zhang and Ruocheng Guo and Hao Cheng and Yegor Klochkov and Muhammad Faaiz Taufiq and Hang Li , booktitle=. Trustworthy. 2023 , url=
2023
-
[25]
Proceedings of the 34th USENIX Conference on Security Symposium , articleno =
Kwesi, Jabari and Cao, Jiaxun and Manchanda, Riya and Emami-Naeini, Pardis , title =. Proceedings of the 34th USENIX Conference on Security Symposium , articleno =. 2025 , isbn =
2025
-
[26]
Position: Beyond Assistance
Abeer Badawi and Md Tahmid Rahman Laskar and Jimmy Huang and Shaina Raza and Elham Dolatabadi , booktitle=. Position: Beyond Assistance. 2025 , url=
2025
-
[30]
Artificial Intelligence Act , url =
EPEUCO , month =. Artificial Intelligence Act , url =
-
[31]
Augmented Intelligence Development, Deployment, and Use in Health Care , url =
AMA , journal =. Augmented Intelligence Development, Deployment, and Use in Health Care , url =
-
[32]
Ethical Decision-Making Guidelines for Mental Health Clinicians in the Artificial Intelligence (AI) Era , volume =
Yegan Pillay , doi =. Ethical Decision-Making Guidelines for Mental Health Clinicians in the Artificial Intelligence (AI) Era , volume =. Healthcare 2025, Vol. 13, , keywords =
2025
-
[33]
Ethical Guidance for AI in the Professional Practice of Health Service Psychology , year =
APA , month =. Ethical Guidance for AI in the Professional Practice of Health Service Psychology , year =
-
[34]
Ethics Guidelines for Trustworthy
AIHLEG , month =. Ethics Guidelines for Trustworthy
-
[35]
Designing human-centered
Thieme, Anja and Hanratty, Maryann and Lyons, Maria and Palacios, Jorge and Marques, Rita Faia and Morrison, Cecily and Doherty, Gavin , journal=. Designing human-centered. 2023 , publisher=
2023
-
[36]
Uncovering contradictions in human-
Namvarpour, Mohammad and Razi, Afsaneh , booktitle=. Uncovering contradictions in human-
-
[37]
Understanding Attitudes and Trust of Generative
Wang, Yimeng and Wang, Yinzhou and Crace, Kelly and Zhang, Yixuan , booktitle=. Understanding Attitudes and Trust of Generative
-
[38]
Understanding Adolescents' Perceptions of Benefits and Risks in Health
Lee, Jamie and Jung, Kyuha and Newman, Erin Gregg and Chow, Emilie and Chen, Yunan , booktitle=. Understanding Adolescents' Perceptions of Benefits and Risks in Health
-
[39]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Private Yet Social: How LLM Chatbots Support and Challenge Eating Disorder Recovery , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[40]
Can I have my friend attending with me?
" Can I have my friend attending with me?": Design Implications for Using Virtual Supporters in Remote Psychotherapy , author=. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
-
[41]
Extended abstracts of the 2023 CHI conference on human factors in computing systems , pages=
Trust and perceived control in burnout support chatbots , author=. Extended abstracts of the 2023 CHI conference on human factors in computing systems , pages=
2023
-
[42]
Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
Evaluating the experience of LGBTQ+ people using large language model based chatbots for mental health support , author=. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
2024
-
[43]
Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
Tailored Virtual Agent Guidance for Stress Management: Comparing Directive and Non-Directive Approaches by Alexithymia Status , author=. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
-
[44]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Customizing emotional support: How do individuals construct and interact with LLM-powered chatbots , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[48]
Haque, Md Romael and Rubya, Sabirat , title =. 2022 , issue_date =. doi:10.1145/3555146 , journal =
-
[50]
and Moray, Neville , title =
Lee, John D. and Moray, Neville , title =. Ergonomics , year =
-
[51]
Hurley and John Herrington and Eric Alan Storch and Casey J
Ansh Rai and Meghan E. Hurley and John Herrington and Eric Alan Storch and Casey J. Zampella and Julia Parish-Morris and Anika Sonig and Gabriel Lázaro-Muñoz and Kristin Kostick-Quenet , doi =. Stakeholder Criteria for Trust in Artificial Intelligence–Based Computer Perception Tools in Health Care: Qualitative Interview Study , volume =. Journal of Medica...
-
[52]
In A.I. we trust?
Seounmi Youn and S. Venus Jin , doi =. “In A.I. we trust?” The effects of parasocial interaction and technopian versus luddite ideological views on chatbot-based customer relationship management in the emerging “feeling economy” , volume =. Computers in Human Behavior , keywords =
-
[53]
Journal of Cognitive Engineering and Decision Making , year =
Manzey, Dietrich and Reichenbach, Julian and Onnasch, Linda , title =. Journal of Cognitive Engineering and Decision Making , year =
-
[69]
Peter , doi =
Christine Jacob and Noé Brasier and Emanuele Laurenzi and Sabina Heuss and Stavroula Georgia Mougiakakou and Arzu Cöltekin and Marc K. Peter , doi =. AI for IMPACTS Framework for Evaluating the Long-Term Real-World Impacts of AI-Powered Clinician Tools: Systematic Review and Narrative Synthesis , volume =. Journal of Medical Internet Research , keywords =
-
[71]
Proceedings of the ACM SIGIR Asia-Pacific Conference on Information Retrieval , year=
Investigating Variability in Large Language Model-Based Personalized Conversational Information Retrieval , author=. Proceedings of the ACM SIGIR Asia-Pacific Conference on Information Retrieval , year=
-
[72]
Proceedings of the ACM International Conference on Web Search and Data Mining (WSDM) , year=
Writing Style Matters: An Examination of Bias and Fairness in Text Embedding Models , author=. Proceedings of the ACM International Conference on Web Search and Data Mining (WSDM) , year=
-
[73]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Tutorial) , year=
Robust Information Retrieval , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Tutorial) , year=
-
[74]
Proceedings of the ACM SIGIR International Conference on the Theory of Information Retrieval (ICTIR) , year=
Correctness is Not Faithfulness in Retrieval-Augmented Generation Attributions , author=. Proceedings of the ACM SIGIR International Conference on the Theory of Information Retrieval (ICTIR) , year=
-
[75]
Towards Trustworthy
Amatya, Saurav , booktitle=. Towards Trustworthy. 2025 , publisher=
2025
-
[76]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , year=
Rankers, Judges, and Assistants: On the Interaction Between Retrieval Models and Large Language Model-Based Evaluation , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , year=
-
[77]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (Short/Abstract Track) , year=
Towards Explainable and Safe Systems for Health Data , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (Short/Abstract Track) , year=
-
[78]
Proceedings of the ACM SIGIR Asia-Pacific Conference on Information Retrieval (Tutorial) , year=
Trustworthy Information Retrieval in the Era of Large Language Models , author=. Proceedings of the ACM SIGIR Asia-Pacific Conference on Information Retrieval (Tutorial) , year=
-
[79]
Mayer and James H
Roger C. Mayer and James H. Davis and F. David Schoorman , journal =. An Integrative Model of Organizational Trust , urldate =
-
[81]
The PRISMA 2020 statement: an updated guideline for reporting systematic reviews , volume =
Page, Matthew J and McKenzie, Joanne E and Bossuyt, Patrick M and Boutron, Isabelle and Hoffmann, Tammy C and Mulrow, Cynthia D and Shamseer, Larissa and Tetzlaff, Jennifer M and Akl, Elie A and Brennan, Sue E and Chou, Roger and Glanville, Julie and Grimshaw, Jeremy M and Hr. The PRISMA 2020 statement: an updated guideline for reporting systematic review...
2020
-
[91]
Liu, Siyang and Brie, Bianca and Li, Wenda and Biester, Laura and Lee, Andrew and Pennebaker, James and Mihalcea, Rada. Eeyore: Realistic Depression Simulation via Expert-in-the-Loop Supervised and Preference Optimization. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.707
-
[94]
Yang, Qisen and Wang, Zekun and Chen, Honghui and Wang, Shenzhi and Pu, Yifan and Gao, Xin and Huang, Wenhao and Song, Shiji and Huang, Gao. P sycho GAT : A Novel Psychological Measurement Paradigm through Interactive Fiction Games with LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pape...
-
[95]
Cactus: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory
Lee, Suyeon and Kim, Sunghwan and Kim, Minju and Kang, Dongjin and Yang, Dongil and Kim, Harim and Kang, Minseok and Jung, Dayi and Kim, Min Hee and Lee, Seungbeen and Chung, Kyong-Mee and Yu, Youngjae and Lee, Dongha and Yeo, Jinyoung. Cactus: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory. Findings of the Association fo...
-
[97]
Depression Detection on Social Media with Large Language Models
Lan, Xiaochong and Han, Zhiguang and Cheng, Yiming and Sheng, Li and Feng, Jie and Gao, Chen and Li, Yong. Depression Detection on Social Media with Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2025. doi:10.18653/v1/2025.emnlp-industry.151
-
[98]
AIHLEG. 2019. https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai Ethics guidelines for trustworthy AI . Technical report
2019
-
[99]
Mehmet Emin Aktan, Zeynep Turhan, and İlknur Dolu. 2022. https://doi.org/10.1016/j.chb.2022.107273 Attitudes and perspectives towards the preferences for artificial intelligence in psychotherapy . Computers in Human Behavior, 133:107273
-
[100]
Alghamdi, Reem Masoud, Deema Alnuhait, Afnan Y
Emad A. Alghamdi, Reem Masoud, Deema Alnuhait, Afnan Y. Alomairi, Ahmed Ashraf, and Mohamed Zaytoon. 2025. https://aclanthology.org/2025.coling-main.579/ A ra T rust: An evaluation of trustworthiness for LLM s in A rabic . In Proceedings of the 31st International Conference on Computational Linguistics, pages 8664--8679, Abu Dhabi, UAE. Association for Co...
2025
-
[101]
AMA. 2024. https://www.ama-assn.org/system/files/ama-ai-principles.pdf Augmented intelligence development, deployment, and use in health care . Technical report
2024
-
[102]
humans are still in the decision loop
Naomi Aoki. 2021. https://doi.org/10.1016/j.chb.2020.106572 The importance of the assurance that “humans are still in the decision loop” for public trust in artificial intelligence: Evidence from an online experiment . Computers in Human Behavior, 114:106572
-
[103]
APA. 2025. Ethical guidance for ai in the professional practice of health service psychology
2025
-
[104]
Abeer Badawi, Md Tahmid Rahman Laskar, Jimmy Huang, Shaina Raza, and Elham Dolatabadi. 2025. https://openreview.net/forum?id=j3totqf8xW Position: Beyond assistance reimagining LLM s as ethical and adaptive co-creators in mental health care . In Forty-second International Conference on Machine Learning Position Paper Track
2025
-
[105]
Miguel Baidal, Erik Derner, and Nuria Oliver. 2025. https://doi.org/10.18653/v1/2025.nlp4pi-1.2 Guardians of trust: Risks and opportunities for LLM s in mental health . In Proceedings of the Fourth Workshop on NLP for Positive Impact (NLP4PI), pages 11--22, Vienna, Austria. Association for Computational Linguistics
-
[106]
Krisztian Balog, Donald Metzler, and Tao Qin. 2025. Rankers, judges, and assistants: On the interaction between retrieval models and large language model-based evaluation. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM
2025
-
[107]
Guanqun Bi, Zhuang Chen, Zhoufu Liu, Hongkai Wang, Xiyao Xiao, Yuqiang Xie, Wen Zhang, Yongkang Huang, Yuxuan Chen, Libiao Peng, and Minlie Huang. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1278 MAGI : Multi-agent guided interview for psychiatric assessment . In Findings of the Association for Computational Linguistics: ACL 2025, pages 24898--249...
-
[108]
Sabine Brunswicker, Yifan Zhang, Christopher Rashidian, and Daniel W. Linna. 2025. https://doi.org/10.1016/j.chb.2024.108516 Trust through words: The systemize-empathize-effect of language in task-oriented conversational agents . Computers in Human Behavior, 165:108516
-
[109]
Daniel Cabrera Lozoya, Eloy Hernandez Lua, Juan Alberto Barajas Perches, Mike Conway, and Simon D ' Alfonso. 2025. https://doi.org/10.18653/v1/2025.clpsych-1.13 Synthetic empathy: Generating and evaluating artificial psychotherapy dialogues to detect empathy in counseling sessions . In Proceedings of the 10th Workshop on Computational Linguistics and Clin...
-
[110]
can i have my friend attending with me?
Jiashuo Cao, Yun Suen Pai, Chen Li, Simon Hoermann, and Mark Billinghurst. 2025. " can i have my friend attending with me?": Design implications for using virtual supporters in remote psychotherapy. In Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1--7
2025
-
[111]
Yang Cao and et al. 2025. Writing style matters: An examination of bias and fairness in text embedding models. In Proceedings of the ACM International Conference on Web Search and Data Mining (WSDM). ACM
2025
-
[112]
Yirong Chen, Xiaofen Xing, Jingkai Lin, Huimin Zheng, Zhenyu Wang, Qi Liu, and Xiangmin Xu. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.83 S oul C hat: Improving LLM s' empathy, listening, and comfort abilities through fine-tuning with multi-turn empathy conversations . In Findings of the Association for Computational Linguistics: EMNLP 2023, pa...
-
[113]
Oscar Hengxuan Chi, Shizhen Jia, Yafang Li, and Dogan Gursoy. 2021. https://doi.org/10.1016/j.chb.2021.106700 Developing a formative scale to measure consumers’ trust toward interaction with artificially intelligent ( AI ) social robots in service delivery . Computers in Human Behavior, 118:106700
-
[114]
Young Min Cho, Sunny Rai, Lyle Ungar, Jo \ a o Sedoc, and Sharath Guntuku. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.698 An integrative survey on mental health conversational agents to bridge computer science and medical perspectives . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11346--11369, Si...
-
[115]
Ryuhaerang Choi, Taehan Kim, Subin Park, Jennifer G Kim, and Sung-Ju Lee. 2025. Private yet social: How llm chatbots support and challenge eating disorder recovery. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1--19
2025
-
[116]
Shehzaad Dhuliawala, Vil \'e m Zouhar, Mennatallah El-Assady, and Mrinmaya Sachan. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.339 A diachronic perspective on user trust in AI under uncertainty . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5567--5580, Singapore. Association for Computational Linguistics
-
[117]
EPEUCO. 2024. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689 Artificial intelligence act
2024
-
[118]
FDA. 2021. www.fda.gov Artificial intelligence/machine learning (ai/ml)-based software as a medical device (samd) action plan
2021
-
[119]
Saadia Gabriel, Isha Puri, Xuhai Xu, Matteo Malgaroli, and Marzyeh Ghassemi. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.120 Can AI relate: Testing large language model response for mental health support . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 2206--2221, Miami, Florida, USA. Association for Computationa...
-
[120]
Felix Gille, Laura Maaß, Benjamin Ho, and Divya Srivastava. 2025. https://doi.org/10.2196/59111 From theory to practice: Viewpoint on economic indicators for trust in digital health . Journal of Medical Internet Research, 27
-
[121]
Melanie Goisauf, M \'o nica Cano Abad \'i a, Kaya Aky \"u z, Maciej Bobowicz, Alena Buyx, Ilaria Colussi, Marie-Christine Fritzsche, Karim Lekadir, Pekka Marttinen, Michaela Th Mayrhofer, and Janos Meszaros. 2025. https://doi.org/10.2196/71236 Trust, trustworthiness, and the future of medical ai: Outcomes of an interdisciplinary expert workshop
-
[122]
Sujatha Gollapalli, Beng Ang, and See-Kiong Ng. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.792 Identifying Early Maladaptive Schemas from mental health question texts . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11832--11843, Singapore. Association for Computational Linguistics
-
[123]
Wenyue Hua, Xianjun Yang, Mingyu Jin, Zelong Li, Wei Cheng, Ruixiang Tang, and Yongfeng Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.585 T rust A gent: Towards safe and trustworthy LLM -based agents . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 10000--10016, Miami, Florida, USA. Association for Computati...
-
[124]
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, Hanchi Sun, Zhengliang Liu, Yixin Liu, Yijue Wang, Zhikun Zhang, Bertie Vidgen, Bhavya Kailkhura, Caiming Xiong, and 52 others. 2024. Position: Trustllm: trustworthiness in large language models. In Proceedings of the 41st Inte...
2024
-
[125]
Weiwei Huo, Guanghui Zheng, Jiaqi Yan, Le Sun, and Liuyi Han. 2022. https://doi.org/10.1016/j.chb.2022.107253 Interacting with medical artificial intelligence: Integrating self-responsibility attribution, human–computer trust, and personality . Computers in Human Behavior, 132:107253
-
[126]
Migyeong Kang, Goun Choi, Hyolim Jeon, Ji Hyun An, Daejin Choi, and Jinyoung Han. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.994 CURE : Context- and uncertainty-aware mental disorder detection . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17924--17940, Miami, Florida, USA. Association for Computa...
-
[127]
Janne Kauttonen, Rebekah Rousi, and Ari Alamäki. 2025. https://doi.org/10.2196/65567 Trust and acceptance challenges in the adoption of AI applications in health care: Quantitative survey analysis . Journal of Medical Internet Research, 27
-
[128]
Jabari Kwesi, Jiaxun Cao, Riya Manchanda, and Pardis Emami-Naeini. 2025. Exploring user security and privacy attitudes and concerns toward the use of general-purpose llm chatbots for mental health. In Proceedings of the 34th USENIX Conference on Security Symposium, SEC '25, USA. USENIX Association
2025
-
[129]
Jamie Lee, Kyuha Jung, Erin Gregg Newman, Emilie Chow, and Yunan Chen. 2025. Understanding adolescents' perceptions of benefits and risks in health AI technologies through design fiction. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1--20
2025
-
[130]
John D. Lee and Neville Moray. 1992. https://doi.org/10.1080/00140139208967392 Trust, control strategies and allocation of function in human--machine systems . Ergonomics, 35(10):1243--1270
-
[131]
Benedikt Leichtmann, Christina Humer, Andreas Hinterreiter, Marc Streit, and Martina Mara. 2023. https://doi.org/10.1016/j.chb.2022.107539 Effects of explainable artificial intelligence on trust and human behavior in a high-risk decision task . Computers in Human Behavior, 139:107539
-
[132]
Anqi Li, Yu Lu, Nirui Song, Shuai Zhang, Lizhi Ma, and Zhenzhong Lan. 2024 a . https://doi.org/10.18653/v1/2024.findings-emnlp.69 Understanding the therapeutic relationship between counselors and clients in online text-based counseling using LLM s . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1280--1303, Miami, Florida,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.