Recognition: unknown
Scaling Self-Play with Self-Guidance
Pith reviewed 2026-05-10 01:26 UTC · model grok-4.3
The pith
Self-guided self-play prevents language models from generating useless problems during training, allowing continued improvement on theorem proving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a language model can itself act as a Guide that evaluates synthetic problems by their relevance to unsolved target problems and by how clean and natural they are. This guidance steers the Conjecturer away from reward-hacking degeneracy, so that both the Conjecturer and Solver keep improving together over long training runs. When applied to Lean4 theorem proving, the resulting self-play surpasses the best reinforcement-learning baseline's asymptotic solve rate in fewer than 80 rounds and produces a 7B model that, after 200 rounds, solves more problems than a 671B model evaluated with pass@4.
What carries the argument
The Guide role, in which the language model scores each conjectured problem by its relevance to unsolved targets and its naturalness, supplying the signal that keeps the Conjecturer from collapsing into unhelpful complexity.
If this is right
- SGS surpasses the asymptotic solve rate of the strongest RL baseline in fewer than 80 rounds of self-play.
- After 200 rounds a 7B model solves more Lean4 problems than a 671B model using pass@4.
- Cumulative solve-rate curves fit scaling laws that show continued improvement rather than early plateaus.
- The same three-role loop can be run for significantly longer training horizons than prior self-play methods.
Where Pith is reading between the lines
- The same guidance mechanism could be tested on open-ended code generation or informal mathematical reasoning where naturalness of subproblems is also hard to define externally.
- If the Guide's judgments remain reliable at larger scales, the amount of human-curated seed problems needed for high performance could drop substantially.
- The approach suggests a general pattern for keeping any self-improving loop from drifting into reward-hacking regimes by adding an internal consistency check.
Load-bearing premise
The language model can reliably judge whether a proposed subproblem will actually help solve real unsolved goals.
What would settle it
Run the same self-play loop but replace the Guide's scores with random numbers; if the solve-rate curves then plateau at the same level as the plain RL baseline, the claimed benefit of guidance is falsified.
Figures


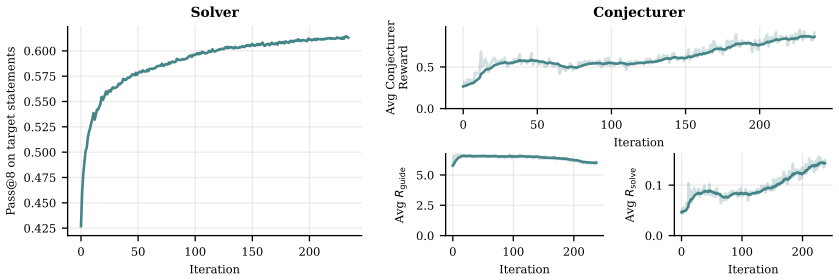

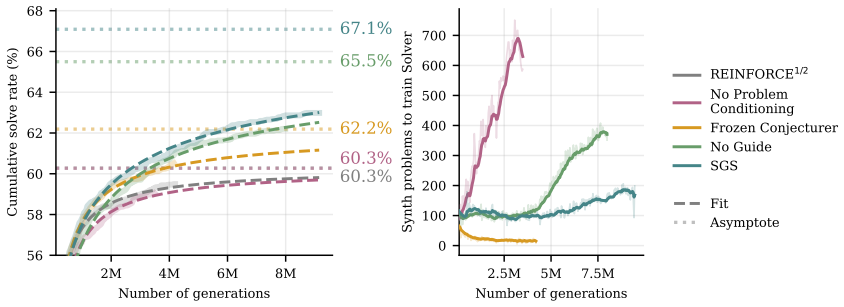







read the original abstract
LLM self-play algorithms are notable in that, in principle, nothing bounds their learning: a Conjecturer model creates problems for a Solver, and both improve together. However, in practice, existing LLM self-play methods do not scale well with large amounts of compute, instead hitting learning plateaus. We argue this is because over long training runs, the Conjecturer learns to hack its reward, collapsing to artificially complex problems that do not help the Solver improve. To overcome this, we introduce Self-Guided Self-Play (SGS), a self-play algorithm in which the language model itself guides the Conjecturer away from degeneracy. In SGS, the model takes on three roles: Solver, Conjecturer, and a Guide that scores synthetic problems by their relevance to unsolved target problems and how clean and natural they are, providing supervision against Conjecturer collapse. Our core hypothesis is that language models can assess whether a subproblem is useful for achieving a goal. We evaluate the scaling properties of SGS by running training for significantly longer than prior works and by fitting scaling laws to cumulative solve rate curves. Applying SGS to formal theorem proving in Lean4, we find that it surpasses the asymptotic solve rate of our strongest RL baseline in fewer than 80 rounds of self-play and enables a 7B parameter model, after 200 rounds of self-play, to solve more problems than a 671B parameter model pass@4.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Self-Guided Self-Play (SGS), an extension of LLM self-play in which the model assumes three roles—Solver, Conjecturer, and Guide—to generate synthetic problems for formal theorem proving in Lean4. The Guide scores conjectures by relevance to unsolved targets plus cleanliness/naturalness to prevent the Conjecturer from collapsing into degenerate problems that do not improve the Solver. The central empirical claims are that SGS surpasses the asymptotic solve rate of the strongest RL baseline in fewer than 80 rounds and that a 7B model trained for 200 rounds solves more problems than a 671B model at pass@4; scaling laws are fitted to cumulative solve-rate curves.
Significance. If the results hold, SGS would represent a meaningful advance in scaling self-improvement for formal reasoning by providing an internal mechanism against reward hacking, a known failure mode in prior self-play work. The use of the model itself as Guide, the explicit hypothesis that LMs can judge subproblem utility, and the fitting of scaling laws to long training runs are strengths that could influence subsequent work on self-play and synthetic data generation.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the claims that SGS surpasses the RL baseline in <80 rounds and that the 7B model exceeds 671B pass@4 after 200 rounds are presented without reported dataset sizes, exact solve-rate metrics, error bars, baseline implementation details, or controls for training length and problem distribution. These omissions make it impossible to verify whether the gains are attributable to the Guide or to longer training and different data.
- [Section 3 / Results] Section 3 (SGS description) and Results: the core hypothesis that the Guide can assess subproblem usefulness is load-bearing for the anti-collapse claim, yet no direct validation is provided—e.g., correlation between Guide scores and downstream solve-rate gains, inter-rater agreement with human experts, or an ablation that removes the Guide while keeping other factors fixed. Without such evidence, it remains possible that observed improvements stem from other factors.
- [Scaling-laws subsection] Scaling-laws subsection: the fitted curves are used to support the claim of improved scaling, but the manuscript does not report the functional form, the number of data points used for fitting, or goodness-of-fit statistics, making it difficult to assess whether the claimed superiority over RL baselines is robust.
minor comments (2)
- [Section 3] Notation for the three roles (Solver, Conjecturer, Guide) and the scoring function should be introduced with explicit equations or pseudocode for reproducibility.
- [Abstract] The abstract states 'surpasses the asymptotic solve rate' without defining the precise metric or the point at which asymptote is declared; this should be clarified with a figure or table reference.
Simulated Author's Rebuttal
Thank you for your detailed and constructive review. We appreciate the feedback highlighting areas where additional details and validations would strengthen the manuscript. We address each major comment below and commit to revisions that improve clarity and evidence without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claims that SGS surpasses the RL baseline in <80 rounds and that the 7B model exceeds 671B pass@4 after 200 rounds are presented without reported dataset sizes, exact solve-rate metrics, error bars, baseline implementation details, or controls for training length and problem distribution. These omissions make it impossible to verify whether the gains are attributable to the Guide or to longer training and different data.
Authors: We agree these details are necessary for full reproducibility and to attribute gains specifically to the Guide component. The full manuscript reports dataset sizes (e.g., the Lean4 problem corpus split) and baseline hyperparameters in the Experiments and Appendix sections, but we acknowledge they are not sufficiently prominent or cross-referenced in the main results. In the revision we will add a dedicated reproducibility subsection with exact solve-rate tables including standard errors from 5 independent runs, explicit training-length and problem-distribution controls (same seed problems and compute budget for all methods), and baseline implementation code references. revision: yes
-
Referee: [Section 3 / Results] Section 3 (SGS description) and Results: the core hypothesis that the Guide can assess subproblem usefulness is load-bearing for the anti-collapse claim, yet no direct validation is provided—e.g., correlation between Guide scores and downstream solve-rate gains, inter-rater agreement with human experts, or an ablation that removes the Guide while keeping other factors fixed. Without such evidence, it remains possible that observed improvements stem from other factors.
Authors: The primary evidence in the manuscript is the controlled comparison showing that SGS avoids the collapse and plateau exhibited by standard self-play under identical compute, which indirectly supports the Guide's role. We concede that direct ablations and correlations would provide stronger causal evidence. In the revision we will insert an ablation experiment that disables the Guide (reverting to unguided self-play) while holding all other factors fixed, and we will report the Pearson correlation between Guide scores and subsequent per-problem solve-rate gains on a held-out set. Human inter-rater agreement was not collected in the original study; we will note this as a limitation and outline a protocol for future validation. revision: partial
-
Referee: [Scaling-laws subsection] Scaling-laws subsection: the fitted curves are used to support the claim of improved scaling, but the manuscript does not report the functional form, the number of data points used for fitting, or goodness-of-fit statistics, making it difficult to assess whether the claimed superiority over RL baselines is robust.
Authors: We will expand the scaling-laws subsection to state the exact functional form (power-law plus offset: solve_rate = a * rounds^b + c), the number of fitting points (cumulative solve rates evaluated at every round from 1 to 200), and quantitative goodness-of-fit measures (R^2 and mean squared residual). These additions will allow readers to directly compare the robustness of the SGS scaling curve against the RL baseline. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external Lean4 benchmarks
full rationale
The paper introduces SGS as an algorithmic intervention against conjecturer collapse and evaluates it via direct training runs on Lean4 theorem-proving tasks. Solve-rate comparisons to RL baselines and larger models are reported from observed performance after fixed numbers of self-play rounds; scaling laws are fitted post-hoc to cumulative curves but are not used to derive the primary claims. No equations, self-citations, or uniqueness theorems reduce the reported gains to fitted inputs or prior author results by construction. The core hypothesis is an empirical premise whose validity is assessed indirectly through downstream solve rates rather than being smuggled into the measurement itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models can assess whether a subproblem is useful for achieving a goal.
invented entities (1)
-
Self-Guided Self-Play (SGS) with Guide role
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In Forty-first International Conference on Machine Learning, 2024
2024
-
[2]
Justin Yang Chae, Md Tanvirul Alam, and Nidhi Rastogi
Justin Yang Chae, Md Tanvirul Alam, and Nidhi Rastogi. Towards understanding self-play for llm reasoning. arXiv preprint arXiv:2510.27072, 2025
-
[3]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention. arXiv preprint arXiv:2506.13585, 2025 a
work page internal anchor Pith review arXiv 2025
-
[4]
Jiangjie Chen, Wenxiang Chen, Jiacheng Du, Jinyi Hu, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Wenlei Shi, et al. Seed-prover 1.5: Mastering undergraduate-level theorem proving via learning from experience. arXiv preprint arXiv:2512.17260, 2025 b
-
[5]
Self- questioning language models.arXiv preprint arXiv:2508.03682,
Lili Chen, Mihir Prabhudesai, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Self-questioning language models. arXiv preprint arXiv:2508.03682, 2025 c
-
[6]
Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, et al. Seed-prover: Deep and broad reasoning for automated theorem proving. arXiv preprint arXiv:2507.23726, 2025 d
-
[7]
Anchored self-play for code repair
Caroline Choi, Zeyneb N Kaya, Shirley Wu, Tengyu Ma, Tatsunori Hashimoto, and Ludwig Schmidt. Anchored self-play for code repair
-
[8]
The lean theorem prover (system description)
Leonardo De Moura, Soonho Kong, Jeremy Avigad, Floris Van Doorn, and Jakob von Raumer. The lean theorem prover (system description). In International Conference on Automated Deduction, pp.\ 378--388. Springer, 2015
2015
-
[9]
Kefan Dong and Tengyu Ma. Stp: Self-play llm theorem provers with iterative conjecturing and proving. arXiv preprint arXiv:2502.00212, 2025
-
[10]
Automatic goal generation for reinforcement learning agents
Carlos Florensa, David Held, Xinyang Geng, and Pieter Abbeel. Automatic goal generation for reinforcement learning agents. In International conference on machine learning, pp.\ 1515--1528. PMLR, 2018
2018
-
[11]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Olympiad-level formal mathematical reasoning with reinforcement learning
Thomas Hubert, Rishi Mehta, Laurent Sartran, Mikl \'o s Z Horv \'a th, Goran Z u z i \'c , Eric Wieser, Aja Huang, Julian Schrittwieser, Yannick Schroecker, Hussain Masoom, et al. Olympiad-level formal mathematical reasoning with reinforcement learning. Nature, pp.\ 1--3, 2025
2025
-
[13]
Gasp: Guided asymmetric self-play for coding llms
Swadesh Jana, Cansu Sancaktar, Tom \'a s Dani s , Georg Martius, Antonio Orvieto, and Pavel Kolev. Gasp: Guided asymmetric self-play for coding llms. arXiv preprint arXiv:2603.15957, 2026
-
[14]
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms. arXiv preprint arXiv:2510.13786, 2025
-
[15]
10 Hisham Abdullah Alyahya, Haidar Khan, Yazeed Alnumay, M Saiful Bari, and Bulent Yener
Jakub Grudzien Kuba, Mengting Gu, Qi Ma, Yuandong Tian, Vijai Mohan, and Jason Chen. Language self-play for data-free training. arXiv preprint arXiv:2509.07414, 2025
-
[16]
R-diverse: Mitigating diversity illusion in self-play llm training
Gengsheng Li, Jinghan He, Shijie Wang, Dan Zhang, Ruiqi Liu, Renrui Zhang, Zijun Yao, Junfeng Fang, Haiyun Guo, and Jinqiao Wang. R-diverse: Mitigating diversity illusion in self-play llm training. arXiv preprint arXiv:2602.13103, 2026
-
[17]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. Hugging Face repository, 13 0 (9): 0 9, 2024
2024
-
[18]
(mis) fitting: A survey of scaling laws
Margaret Li, Sneha Kudugunta, and Luke Zettlemoyer. (mis) fitting: A survey of scaling laws. arXiv preprint arXiv:2502.18969, 2025
-
[19]
Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, et al. Goedel-prover: A frontier model for open-source automated theorem proving. arXiv preprint arXiv:2502.07640, 2025 a
-
[20]
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, et al. Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction. arXiv preprint arXiv:2508.03613, 2025 b
-
[21]
Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. Spice: Self-play in corpus environments improves reasoning. arXiv preprint arXiv:2510.24684, 2025
-
[22]
Towards robust mathematical reasoning
Minh-Thang Luong, Dawsen Hwang, Hoang H Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, et al. Towards robust mathematical reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 35406--35430, 2025
2025
-
[23]
The lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language. In International Conference on Automated Deduction, pp.\ 625--635. Springer, 2021
2021
-
[24]
Learning formal mathematics from intrinsic motivation
Gabriel Poesia, David Broman, Nick Haber, and Noah Goodman. Learning formal mathematics from intrinsic motivation. Advances in Neural Information Processing Systems, 37: 0 43032--43057, 2024
2024
-
[25]
What can you do when you have zero rewards during rl?, 2025
Jatin Prakash and Anirudh Buvanesh. What can you do when you have zero rewards during rl? arXiv preprint arXiv:2510.03971, 2025
-
[26]
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. Pope: Learning to reason on hard problems via privileged on-policy exploration. arXiv preprint arXiv:2601.18779, 2026
-
[27]
ZZ Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, et al. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition. arXiv preprint arXiv:2504.21801, 2025
-
[28]
Observational scaling laws and the predictability of langauge model performance
Yangjun Ruan, Chris J Maddison, and Tatsunori Hashimoto. Observational scaling laws and the predictability of langauge model performance. Advances in Neural Information Processing Systems, 37: 0 15841--15892, 2024
2024
-
[29]
Some studies in machine learning using the game of checkers
Arthur L Samuel. Some studies in machine learning using the game of checkers. IBM Journal of research and development, 3 0 (3): 0 210--229, 1959
1959
-
[30]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Mastering the game of go with deep neural networks and tree search
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529 0 (7587): 0 484--489, 2016
2016
-
[33]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv preprint arXiv:1712.01815, 2017
work page Pith review arXiv 2017
-
[34]
Intrinsic motivation and automatic curricula via asymmetric self-play
Sainbayar Sukhbaatar, Zeming Lin, Ilya Kostrikov, Gabriel Synnaeve, Arthur Szlam, and Rob Fergus. Intrinsic motivation and automatic curricula via asymmetric self-play. arXiv preprint arXiv:1703.05407, 2017
-
[35]
Shobhita Sundaram, John Quan, Ariel Kwiatkowski, Kartik Ahuja, Yann Ollivier, and Julia Kempe. Teaching models to teach themselves: Reasoning at the edge of learnability. arXiv preprint arXiv:2601.18778, 2026
-
[36]
Temporal difference learning and td-gammon
Gerald Tesauro et al. Temporal difference learning and td-gammon. Communications of the ACM, 38 0 (3): 0 58--68, 1995
1995
-
[37]
Learning to play the game of chess
Sebastian Thrun. Learning to play the game of chess. Advances in neural information processing systems, 7, 1994
1994
-
[38]
Hilbert: Recursively building formal proofs with informal reasoning.CoRR, abs/2509.22819, 2025
Sumanth Varambally, Thomas Voice, Yanchao Sun, Zhifeng Chen, Rose Yu, and Ke Ye. Hilbert: Recursively building formal proofs with informal reasoning. arXiv preprint arXiv:2509.22819, 2025
-
[39]
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, et al. Kimina-prover preview: Towards large formal reasoning models with reinforcement learning. arXiv preprint arXiv:2504.11354, 2025
-
[40]
Peng Xia, Kaide Zeng, Jiaqi Liu, Can Qin, Fang Wu, Yiyang Zhou, Caiming Xiong, and Huaxiu Yao. Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning. arXiv preprint arXiv:2511.16043, 2025
-
[41]
Ttcs: Test-time curriculum synthesis for self-evolving
Chengyi Yang, Zhishang Xiang, Yunbo Tang, Zongpei Teng, Chengsong Huang, Fei Long, Yuhan Liu, and Jinsong Su. Ttcs: Test-time curriculum synthesis for self-evolving. arXiv preprint arXiv:2601.22628, 2026
-
[42]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale, 2025. URL https://arxiv. org/abs/2503.14476, 1: 0 2, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Guided self-evolving llms with minimal human supervision.arXiv preprint arXiv:2512.02472,
Wenhao Yu, Zhenwen Liang, Chengsong Huang, Kishan Panaganti, Tianqing Fang, Haitao Mi, and Dong Yu. Guided self-evolving llms with minimal human supervision. arXiv preprint arXiv:2512.02472, 2025 b
-
[44]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, M Lin, S Wang, Q Wu, Z Zheng, and G Huang. Absolute zero: Reinforced self-play reasoning with zero data, 2025. URL https://arxiv. org/abs/2505.03335
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.