Recognition: unknown
ActuBench: A Multi-Agent LLM Pipeline for Generation and Evaluation of Actuarial Reasoning Tasks
Pith reviewed 2026-05-10 00:32 UTC · model grok-4.3
The pith
A multi-agent LLM pipeline generates actuarial test items that professional standards require and shows which models handle them best.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The multi-agent pipeline separates drafting, distractor building, independent verification, and one-shot repair into four LLM roles. This produces items that support reliable model evaluation, where the verifier flags a majority of drafts and the repair loop fixes most, locally hosted open models compete on the Pareto front for cost versus performance, and MCQ scores inflate the apparent ceiling relative to LLM-judge open-ended scoring.
What carries the argument
The four-role multi-agent LLM pipeline with an independent verifier that drives bounded one-shot repair loops.
If this is right
- The independent verifier step makes automated generation of domain-specific items feasible without constant human oversight.
- Open-weights models running locally or on low-cost hosts achieve near-leaderboard results at minimal expense.
- MCQ formats alone give an incomplete picture of model capability, requiring open-ended evaluation to separate top performers.
- LLM judges can discriminate model performance on actuarial reasoning where multiple choice cannot.
Where Pith is reading between the lines
- This method of role-separated agents could be adapted to generate training materials in other expert domains like law or engineering.
- The finding that MCQ and judge rankings differ suggests many existing LLM benchmarks may overestimate practical skills.
- Iterating the pipeline with human feedback loops might further improve item quality over time without full manual creation.
Load-bearing premise
That an LLM judge provides reliable, unbiased scoring of open-ended actuarial responses and that the generated items accurately reflect the IAA syllabus without requiring human expert validation.
What would settle it
A study in which professional actuaries rate a sample of the generated items for accuracy and relevance, or compare LLM judge scores against human expert scores on the open-ended responses.
Figures



read the original abstract
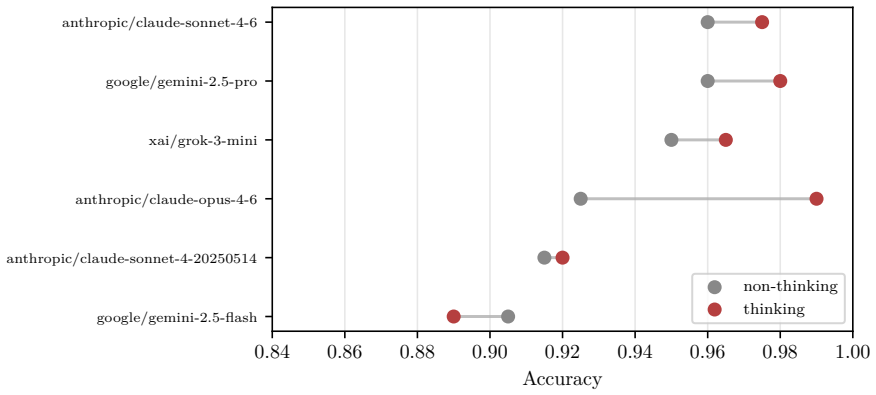
We present ActuBench, a multi-agent LLM pipeline for the automated generation and evaluation of advanced actuarial assessment items aligned with the International Actuarial Association (IAA) Education Syllabus. The pipeline separates four LLM roles by adapter: one agent drafts items, one constructs distractors, a third independently verifies both stages and drives bounded one-shot repair loops, and a cost-optimized auxiliary agent handles Wikipedia-note summarization and topic labelling. The items, per-model responses and complete leaderboard are published as a browsable web interface at https://actubench.de/en/, allowing readers and practitioners to inspect individual items without a repository checkout. We evaluate 50 language models from eight providers on two complementary benchmarks -- 100 empirically hardest multiple-choice items and 100 open-ended items scored by an LLM judge -- and report three headline findings. First, multi-agent verification is load-bearing: the independent verifier flags a majority of drafted items on first pass, most of which the one-shot repair loop resolves. Second, locally-hosted open-weights inference sits on the cost-performance Pareto front: a Gemma~4 model running on consumer hardware and a Cerebras-hosted 120B open-weights model dominate the near-zero-cost region, with the latter within one item of the top of the leaderboard. Third, MCQ and LLM-as-Judge rankings differ meaningfully: the MCQ scaffold inflates the performance ceiling, and Judge-mode evaluation is needed to discriminate at the frontier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActuBench, a multi-agent LLM pipeline that separates roles for drafting actuarial assessment items aligned with the IAA syllabus, constructing distractors, independent verification with bounded one-shot repair, and auxiliary summarization/labeling. It evaluates 50 models across eight providers on two benchmarks—100 empirically hardest MCQ items and 100 open-ended items scored by an LLM judge—reporting three headline findings: multi-agent verification flags and repairs most drafted items, locally-hosted open-weights models occupy the cost-performance Pareto front, and MCQ versus LLM-as-Judge rankings differ meaningfully with the latter needed to discriminate at the frontier. Items, responses, and the leaderboard are released via a public web interface.
Significance. If the central claims hold after validation, the work supplies a scalable, reproducible framework for automated generation of domain-specific actuarial benchmarks, with the public interface enabling direct item inspection and supporting transparency. It usefully demonstrates the limitations of MCQ scaffolding for frontier models and positions consumer-hardware open-weights inference as competitive, while publishing the full set of items and scores aids follow-on research in actuarial AI evaluation.
major comments (3)
- [Abstract and Evaluation Results] The third headline finding (MCQ vs. Judge rankings differ meaningfully) and the overall leaderboard rest on the LLM-as-Judge producing reliable, unbiased scores for open-ended actuarial responses, yet no correlation to human actuarial expert judgments or inter-rater reliability metrics is reported. This is load-bearing for the claim that Judge-mode evaluation is required to discriminate at the frontier and for the Pareto-front conclusion.
- [Pipeline Description and Headline Findings] The assertion that generated items accurately reflect the IAA syllabus and that multi-agent verification is load-bearing relies entirely on internal LLM processes (verifier flagging and one-shot repair), with no human domain-expert validation of item correctness, syllabus alignment, or distractor quality described. This affects the first headline finding and the benchmark's claimed utility.
- [Model Evaluation and Results] The selection of the '100 empirically hardest' MCQ items lacks reported details on the initial generation pool size, the precise statistical or empirical criteria used to identify hardness, and any error-rate or inter-item consistency measures across the 50-model evaluations. Without these, the robustness of the cost-performance Pareto front and cross-mode ranking differences cannot be fully assessed.
minor comments (2)
- [Abstract] The public web interface is a strength for usability; the manuscript could add a brief description of how the complete dataset and generation code can be obtained for full reproducibility.
- [Pipeline Description] Clarify the exact adapter or prompting distinctions among the four LLM roles to avoid any ambiguity in the pipeline architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of validation and methodological transparency. We address each major comment below and will incorporate revisions to strengthen the manuscript, including expanded limitations discussions and additional details on item selection.
read point-by-point responses
-
Referee: [Abstract and Evaluation Results] The third headline finding (MCQ vs. Judge rankings differ meaningfully) and the overall leaderboard rest on the LLM-as-Judge producing reliable, unbiased scores for open-ended actuarial responses, yet no correlation to human actuarial expert judgments or inter-rater reliability metrics is reported. This is load-bearing for the claim that Judge-mode evaluation is required to discriminate at the frontier and for the Pareto-front conclusion.
Authors: We agree that the lack of reported correlation with human actuarial expert judgments is a substantive limitation for the third headline finding. The LLM judge was prompted with detailed actuarial criteria drawn from the IAA syllabus and produced empirically distinct rankings from MCQ, but without human inter-rater data the absolute reliability remains unquantified. In the revised manuscript we will add a dedicated limitations subsection that (a) explicitly states the absence of human correlation metrics, (b) reports any available prompt-level consistency checks we performed, and (c) qualifies the claim that Judge-mode evaluation is needed to discriminate at the frontier as an empirical observation pending external human validation. This revision will not alter the reported ranking differences but will improve interpretability. revision: yes
-
Referee: [Pipeline Description and Headline Findings] The assertion that generated items accurately reflect the IAA syllabus and that multi-agent verification is load-bearing relies entirely on internal LLM processes (verifier flagging and one-shot repair), with no human domain-expert validation of item correctness, syllabus alignment, or distractor quality described. This affects the first headline finding and the benchmark's claimed utility.
Authors: The referee is correct that all validation steps described are internal to the LLM pipeline. The independent verifier and bounded repair loop demonstrably reduce flagged errors, and the public web interface releases every item for external inspection. Nevertheless, we did not conduct human actuarial-expert review of syllabus alignment or distractor quality. We will revise the pipeline description and first headline finding to (i) state this limitation explicitly, (ii) emphasize that the released items enable community expert validation, and (iii) add any quantitative repair-success statistics already computed during generation. These changes will temper the claim of syllabus fidelity while preserving the utility of the automated pipeline as a scalable starting point. revision: yes
-
Referee: [Model Evaluation and Results] The selection of the '100 empirically hardest' MCQ items lacks reported details on the initial generation pool size, the precise statistical or empirical criteria used to identify hardness, and any error-rate or inter-item consistency measures across the 50-model evaluations. Without these, the robustness of the cost-performance Pareto front and cross-mode ranking differences cannot be fully assessed.
Authors: We will expand the Model Evaluation section with the requested details. The initial generation pool comprised 312 items; hardness was defined as the lowest mean accuracy across all 50 models, with ties broken by variance. We will report the exact pool size, the hardness formula, per-item standard deviations across models, and any observed inter-item consistency metrics. These additions will allow readers to evaluate the stability of the Pareto front and the MCQ-versus-Judge ranking divergence. revision: yes
Circularity Check
No significant circularity: purely empirical benchmark construction and evaluation
full rationale
The paper presents an empirical multi-agent LLM pipeline for generating actuarial items aligned to the IAA syllabus and evaluates 50 models on MCQ and open-ended benchmarks. No derivation chain, equations, fitted parameters, or predictions exist that could reduce to self-definition or self-citation. Headline findings (multi-agent verification load-bearing, local models on Pareto front, MCQ vs. Judge ranking differences) are direct experimental observations, not tautological outputs of the pipeline inputs. The work is self-contained against external model evaluations and requires no external uniqueness theorems or ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can reliably perform distinct roles (drafting, distractor creation, independent verification) when prompted via adapters
- domain assumption An LLM judge can produce accurate scores for open-ended actuarial reasoning responses
Reference graph
Works this paper leans on
-
[1]
ActuaryGPT: Applications of Large Language Models to Insurance and Actuarial Work
Caesar Balona. “ActuaryGPT: Applications of Large Language Models to Insurance and Actuarial Work”.British Actuarial Journal2024. SSRN 4543652, first posted 17 Aug 2023. url:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4543652
2023
-
[2]
arXiv preprint arXiv:2308.10848 , year=
Weize Chen et al. “AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors” 2023. arXiv:2308.10848.url: https://arxiv.org/abs/2308. 10848
-
[3]
arXiv preprint arXiv:2109.00122 , year=
Zhiyu Chen et al. “FinQA: A Dataset of Numerical Reasoning over Financial Data” 2021. arXiv:2109.00122.url:https://arxiv.org/abs/2109.00122
-
[4]
arXiv preprint arXiv:2311.09783 , year =
Chunyuan Deng et al. “Investigating Data Contamination in Modern Benchmarks for Large Language Models” 2023. arXiv:2311.09783.url: https://arxiv.org/abs/2311.09783
-
[5]
Learning to Ask: Neural Question Generation for Reading Comprehension
Xinya Du, Junru Shao, and Claire Cardie. “Learning to Ask: Neural Question Generation for Reading Comprehension” 2017. arXiv:1705.00106.url: https://arxiv.org/abs/ 1705.00106
-
[6]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du et al. “Improving Factuality and Reasoning in Language Models through Multia- gent Debate” 2023. arXiv:2305.14325.url:https://arxiv.org/abs/2305.14325
work page internal anchor Pith review arXiv 2023
-
[7]
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Dheeru Dua et al. “DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs” 2019. arXiv:1903.00161.url: https://arxiv.org/abs/ 1903.00161
work page Pith review arXiv 2019
-
[8]
How Useful are Educational Questions Generated by Large Language Models?
Sabina Elkins et al. “How Useful are Educational Questions Generated by Large Language Models?” 2023. arXiv:2304.06638.url:https://arxiv.org/abs/2304.06638
-
[9]
Yilin Hao et al. “Utilizing Large Language Models (LLMs) for Quantitative Reasoning- Intensive Tasks within the (Re)Insurance Sector”.Annals of Actuarial Science2025.doi: 10.1017/S1748499525100079.url:https://doi.org/10.1017/S1748499525100079
work page doi:10.1017/s1748499525100079.url:https://doi.org/10.1017/s1748499525100079
-
[10]
Good Question! Statistical Ranking for Question Generation
Michael Heilman and Noah A. Smith. “Good Question! Statistical Ranking for Question Generation”.Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT). Asso- ciation for Computational Linguistics, 2010, pp. 609–617.url:https://aclanthology. org/N10-1086/
2010
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks et al. “Measuring Mathematical Problem Solving With the MATH Dataset”
-
[12]
arXiv:2103.03874.url:https://arxiv.org/abs/2103.03874
work page internal anchor Pith review arXiv
-
[13]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong et al. “MetaGPT: Meta Programming for a Multi-Agent Collaborative Frame- work” 2023. arXiv:2308.00352.url:https://arxiv.org/abs/2308.00352
work page internal anchor Pith review arXiv 2023
-
[14]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim et al. “Prometheus: Inducing Fine-grained Evaluation Capability in Lan- guage Models” 2023. arXiv:2310.08491.url:https://arxiv.org/abs/2310.08491
-
[15]
Parker, Caitlin Anderson, Claire Stone, and YeaRim Oh
Ghader Kurdi et al. “A Systematic Review of Automatic Question Generation for Educa- tional Purposes”.International Journal of Artificial Intelligence in Education30.1 2020, pp. 121–204.doi: 10.1007/s40593- 019- 00186- y.url: https://doi.org/10.1007/ s40593-019-00186-y
-
[16]
A comprehensive overview of large language models,
Humza Naveed et al. “A Comprehensive Overview of Large Language Models” 2024. arXiv: 2307.06435.url:https://arxiv.org/abs/2307.06435
-
[17]
Long Phan, Alice Gatti, Ziwen Han, et al. “Humanity’s Last Exam” 2025. arXiv:2501. 14249.url:https://arxiv.org/abs/2501.14249
work page internal anchor Pith review arXiv 2025
-
[18]
AI in Actuarial Science
Ronald Richman. “AI in Actuarial Science”.SSRN Electronic Journal2018.doi:10. 2139/ssrn.3218082.url: https://papers.ssrn.com/sol3/papers.cfm?abstract_ id=3218082. 16
-
[19]
An AI Vision for the Actuarial Profession
Ronald Richman. “An AI Vision for the Actuarial Profession”.Casualty Actuarial Society E-Forum (Summer 2024)2024. SSRN 4758296, prize-winning essay.url:https://papers. ssrn.com/sol3/papers.cfm?abstract_id=4758296
2024
-
[20]
NLP Evaluation in Trouble: On the Need to Measure LLM Data Contamination for Each Benchmark
Oscar Sainz et al. “NLP Evaluation in Trouble: On the Need to Measure LLM Data Contamination for Each Benchmark” 2023. arXiv:2310.18018.url: https://arxiv. org/abs/2310.18018
-
[21]
Andreas Troxler and Jürg Schelldorfer. “Actuarial Applications of Natural Language Processing Using Transformers: Case Studies for Using Text Features in an Actuarial Context” 2022. arXiv:2206.02014.url:https://arxiv.org/abs/2206.02014
-
[22]
Large language models are not fair evaluators
Peiyi Wang et al. “Large Language Models are not Fair Evaluators” 2023. arXiv:2305. 17926.url:https://arxiv.org/abs/2305.17926
-
[23]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu et al. “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework” 2023. arXiv:2308.08155.url: https://arxiv.org/abs/2308. 08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Mario V. Wüthrich and Michael Merz.Statistical Foundations of Actuarial Learning and its Applications. 1st ed. Springer Actuarial. Springer Cham, 2023.doi:10.1007/978-3- 031-12409-9.url:https://link.springer.com/book/10.1007/978-3-031-12409-9
-
[25]
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu et al. “Benchmark Data Contamination of Large Language Models: A Survey”
- [26]
-
[27]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng et al. “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena” 2023. arXiv:2306.05685.url:https://arxiv.org/abs/2306.05685
work page internal anchor Pith review arXiv 2023
-
[28]
Hua Zhou et al. “Design, Results and Industry Implications of the World’s First Insurance Large Language Model Evaluation Benchmark (CUFEInse)” 2025. arXiv:2511.07794. url:https://arxiv.org/abs/2511.07794
-
[29]
Don’t make your llm an evaluation benchmark cheater
Kun Zhou et al. “Don’t Make Your LLM an Evaluation Benchmark Cheater” 2023. arXiv: 2311.01964.url:https://arxiv.org/abs/2311.01964. A Key Prompts This appendix reproduces the core prompts used by Agents A, B and C, and by the auxiliary agent. All prompts request JSON-only output; validation and caching are handled by the pipeline. For space, we quote the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.